
목록파이썬 (147)
꿈 많은 사람의 이야기
 MLflow란? 머신러닝 라이프 사이클을 관리하는 mlflow 사용법 및 예제
MLflow란? 머신러닝 라이프 사이클을 관리하는 mlflow 사용법 및 예제
포스팅 개요 본 포스팅은 머신러닝(machine learning)의 라이프 사이클을 관리해주는 mlflow에 대해서 정리하는 포스팅입니다. mlflow란 무엇이고 어떻게 사용하는지 예제(example)와 함께 정리하고자 합니다. MLflow와 관련된 포스팅은 2번에 걸쳐서 작성할 예정입니다. 첫 번째 포스팅 ( 이번 글 ) MLflow란 무엇인가? MLflow Tracking 간단한 사용 방법과 예제 코드 두 번째 포스팅 MLflow Projects 관리 및 재배포 & Package MLflow Model API Serving MLflow 실험 환경 설정 (experiment setting) 제가 mlflow를 정리하고 공부하면서 참고했던 자료는 아래와 같습니다. https://github.com/mlf..
 Mac os에서 Python lightgbm 설치하는 방법 정리!
Mac os에서 Python lightgbm 설치하는 방법 정리!
포스팅 개요 이번 포스팅은 Mac os 환경에서 lightgbm을 설치하는 방법에 대해 정리합니다. 매번 lightgbm을 설치할 때마다 공식 문서대로 해도 설치가 잘 되지 않는 삽질을 하게 되는데 이번 기회에 정리를 해보고자 합니다. 제가 참고한 자료는 아래와 같습니다. https://lightgbm.readthedocs.io/en/latest/ 포스팅 본문 본 포스팅은 mac os Python 환경에서 머신러닝(machine learning) 알고리즘 중 강력한 알고리즘 중 하나인 lightgbm 라이브러리를 설치하는 방법에 대해 정리합니다. 본 포스팅은 아래와 같은 구성으로 작성합니다. MacOS에서 lightgbm 설치하기 각종 오류와 삽질들 1. MacOS에서 lightgbm 설치하기 먼저, 제..
 python(파이썬) jupyter notebook cell 너비(width) 크기 및 dataframe 크기 조절 방법 정리
python(파이썬) jupyter notebook cell 너비(width) 크기 및 dataframe 크기 조절 방법 정리
포스팅 개요 이번 포스팅은 파이썬(Python) 환경에서 아래와 같은 것을 조절할 수 있는 방법을 정리합니다. jupyter notebook(쥬피터 노트북)에서 cell(셀)의 너비 크기(width)를 조절하는 방법 DataFrame에서 width 크기 등을 조절하는 방법 에 대해 간단하게 정리합니다. 사실 매번 이 부분이 불편해서 검색으로 찾았었는데 반복되는 검색을 좀 줄이고자 블로그에 정리해둡니다. 아래는 참고한 자료입니다. https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.set_option.html pandas.set_option — pandas 1.2.4 documentation display.[chop_threshold, co..
 윈도우에서 파이썬 konlpy 형태소 분석기 및 Mecab(은전한닢) 설치하고 사용자 사전 적용하기 - Python install konlpy on windows
윈도우에서 파이썬 konlpy 형태소 분석기 및 Mecab(은전한닢) 설치하고 사용자 사전 적용하기 - Python install konlpy on windows
포스팅 개요 이번 포스팅은 윈도우에서 파이썬 형태소 분석기인 konlpy와 은전한닢(Mecab)을 설치하는 방법을 정리하는 포스팅입니다. 그리고 윈도우 환경 mecab에서 사용자 사전(user dictionary)을 적용하고 만드는 방법에 대해 정리합니다. 사실, 해당 내용은 2년전에 블로그에 올리긴 했습니다. (lsjsj92.tistory.com/442) 하지만, 시간이 지나 당시엔 Mecab 연동이 윈도우에서 되지 않았던 문제가 해결되어 현재는 windows 환경에서 mecab을 사용할 수 있게 되었습니다. 그래서 이미 글은 있지만, 업데이트 하는 차원에서 다시 한 번 정리해서 올려봅니다. 참고사항 제가 konlpy를 설치하는 윈도우 환경 및 파이썬 환경은 아래와 같습니다. - Python3.7 - ..
 파이썬(Python) 형태소 분석기를 활용한 한국어 원형 복원 분석기 설치 및 설정하기
파이썬(Python) 형태소 분석기를 활용한 한국어 원형 복원 분석기 설치 및 설정하기
포스팅 개요 본 포스팅은 파이썬(Python)을 활용한 텍스트 분석에서 사용할 수 있는 다양한 형태소 분석기(tokenizer)를 사용해 한국어 단어를 원형으로 복구, 복원해주는 원형 복원기(혹은 분석기)를 소개하려고 합니다. 기존에 어떤 훌륭하신 분께서 만들어주신 원형 복원 분석기를 사용하는데요. 이 원형 복원 분석기가 너무 오래되서 현재 파이썬 환경에선 잘 동작하지 않습니다. 따라서 본 포스팅에서는 해당 한국어 원형 복원 형태소 분석기를 활용할 수 있도록 설치하고 설정하는 과정을 소개하려고 합니다. 참고로 본 실습에 필요한 기본적인 파이썬 라이브러리는 아래와 같은 리스트가 설치되어 있어야 합니다. (Python 3.7 이상 기준입니다.) konlpy mecab hanja ( 기존에 만들어주신 한국어 ..
 파이썬 케라스(Python Keras)를 활용한 간단한 책 추천 시스템(recommender system) 구현하기
파이썬 케라스(Python Keras)를 활용한 간단한 책 추천 시스템(recommender system) 구현하기
포스팅 개요 이번 포스팅은 파이썬(Python)의 케라스(Keras)를 이용한 간단한 추천 시스템을 구현하는 포스팅입니다. 최근에 제가 진행한 추천 시스템 스터디에서 공유한 코드인데 블로그에 올릴까 말까 하다가 그래도 공유하면 좋겠다 라고 생각해서 올리게 되었습니다. 이번 포스팅에 나온 추천 모델은 추천 시스템 모델 중에서도 kaggle에서 제공되고 있는 book 데이터을 활용해서 구현해봅니다. 고급스러운 기법을 활용하는 것이 아닌, 간단한 행렬 Dot 연산과 fully connected layer를 이용해서 기본적인 추천 모델을 구현하고 소개하고자 합니다. 해당 글에서 소개된 모든 코드는 아래 제 github의 8번에 올려두었습니다. github.com/lsjsj92/recommender_system_..
 Python(파이썬)에서 데이터 메모리 효율, 처리 속도 향상 시키는 기본 방법 정리(feat. pandas, numpy)
Python(파이썬)에서 데이터 메모리 효율, 처리 속도 향상 시키는 기본 방법 정리(feat. pandas, numpy)
포스팅 개요 이번 포스팅은 최근 회사에서 프로젝트를 진행하며 겪은 파이썬(Python)에서 메모리 효율, 데이터 처리 속도 향상 등의 기본적인 처리 방법을 정리하는 포스팅입니다. 파이썬(Python)을 활용해서 데이터 분석이나 머신러닝 모델 작업을 진행할 때 csv와 같은 데이터를 pandas dataframe으로 불러오는데 이때 데이터 처리 하는 방법에 따라 효율적으로 용량을 줄이고, 속도도 향상시킬 수 있습니다. 이에 대한 간단한 방법을 정리하고자 합니다. 본 포스팅을 작성하면서 참고한 참고자료는 아래와 같습니다. stackoverflow.com/questions/9619199/best-way-to-preserve-numpy-arrays-on-disk www.w3resource.com/numpy/da..
 Python EDA 자동화 도구 Sweetviz 라이브러리란? - Sweetviz 사용법 정리
Python EDA 자동화 도구 Sweetviz 라이브러리란? - Sweetviz 사용법 정리
포스팅 개요 최근 머신러닝(Machine Learning)과 딥러닝(Deep Learning) 시장에 자동화 열풍이 점점 더 세게 불어오고 있습니다. AutoML은 주어진 Dataset에 맞게 Machine Learning 알고리즘을 돌려서 가장 적합한 머신러닝 모델을 찾아주는 등 점점 더 Auto와 관련된 키워드가 Data Science, AI 시장에 불러오고 있습니다. 이번 포스팅은 그 자동화 시스템 중 Exploratory Data Analysis (EDA)를 자동화해주는 라이브러리를 소개해주는 포스팅입니다. 원래 Dataset에 대해서 다양한 분석을 진행합니다. EDA는 그 중 한 방법이며 시간을 어느정도 투자해야 하는 과정입니다. 이 자동화 라이브러리는 그것을 간단하게 제공해줍니다. 그 라이브러..
포스팅 개요 이번 포스팅은 Tensorflow 2.x 버전을 사용하면서 발견한 에러와 그 해결 방법에 대해서 정리합니다. 저의 환경은 아래와 같습니다. python 3.7 tensorflow 2.3 포스팅 본문 포스팅 개요에서도 말씀드렸듯이 이번 포스팅은 Python의 tensorflow 2.x 버전에서 겪을 수 있는 에러에 대해 정리합니다. 제가 구성한 tensorflow 버전은 2.3이고 에러는 NotImplementedError: Layer has arguments in `__init__` and therefore must override `get_config`. 라는 에러입니다. 위 에러가 나오게 된 배경 저는 아래와 같은 상황에서 위 에러를 경험할 수 있었습니다. Open되어 있는 Tensorf..
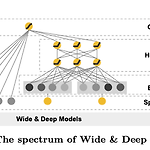 Python 추천 시스템(Recommeder System) 구현하기 - Wide & Deep learning for Recommender System
Python 추천 시스템(Recommeder System) 구현하기 - Wide & Deep learning for Recommender System
포스팅 개요 이번 포스팅은 Python으로 구현하는 추천 시스템(Recommender System with Python) 시리즈 중 하나입니다. 그 중 이번 포스팅은 Google Play store에도 적용된 방법인 Wide & Deep Learning for Recommender System 논문을 기준으로 진행합니다. 따라서 본 포스팅에서는 Wide & Deep Learning for RecSys 논문을 간략하게 정리하고 참고한 코드를 보면서 어떻게 추천이 진행되는지 정리하고자 합니다. 해당 추천 시스템 Python 구현 코드는 아래 제 github에 올려두었습니다. (해당 코드는 논문과 100% 일치하지 않음을 말씀드립니다.) https://github.com/lsjsj92/recommender_s..