
목록파이썬 (147)
꿈 많은 사람의 이야기
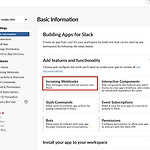 Python slack API 연동하기 - slack API 설정하기 with webhooks
Python slack API 연동하기 - slack API 설정하기 with webhooks
포스팅 개요 슬랙(slack)은 요즘 정말 많이 사용하는 메신저 중 하나입니다. 메신저라고 하기도 좀 그렇고 뭔가 협업 툴? 같은 느낌이 많이 드는 서비스입니다. 이 슬랙의 장점은 API가 쉽게 제공된다는 것인데요. 이 API를 이용해서 Slack을 다채롭게 이용할 수 있습니다. 오늘 포스팅은 파이썬(Python)과 Slack을 연동해서 API로 call을 보낼 수 있는 기본적인 방법을 정리하고자 합니다. 해당 포스팅을 작성하며 참고한 자료는 아래와 같습니다. https://api.slack.com/messaging/webhooks https://github.com/slackapi/python-slackclient 포스팅 본문 개요에서 말씀드렸다시피 이번 포스팅은 메신저 Slack과 Python을 연동하..
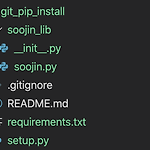 github repository로 python pip install 만드는 방법 정리
github repository로 python pip install 만드는 방법 정리
포스팅 개요 이번 포스팅은 Python의 패키지를 관리해주는 pip install에 대해서 정리합니다. 그 중 github(혹은 gitlab 등)를 이용해서 pip install을 하는 방법에 대해서 정리를 해보려고합니다. 이렇게 git을 이용해서 pip install을 할 수 있는 환경을 만들어주면 본인만의 라이브러리를 구축하고 편하게 사용할 수 있기 때문에 여러 방면으로 유용합니다. 그래서 이거를 나중에도 사용할 수 있도록 아주 간단한 예시로! 미리 정리해두려고 합니다. 포스팅 본문 Python의 pip는 파이썬으로 패키지를 관리해주는 시스템인데요. 보통은 사람들이 만들어 놓은 패키지를 pip install을 이용해서 패키지를 설치합니다. 예를 들어서 아래와 같죠 pip install tensorfl..
 파이썬 대용량 csv 파일 읽는 방법 정리 - Python read large size csv file
파이썬 대용량 csv 파일 읽는 방법 정리 - Python read large size csv file
포스팅 개요 이번 포스팅은 파이썬(Python)에서 용량이 큰 csv 파일을 읽고 처리할 수 있는 방법을 정리합니다. 파이썬을 활용해서 데이터 분석 혹은 모델링 등을 하다보면 대용량의 csv 파일을 많이 다루게 되는데요. 이때 메모리 부족으로 인해(memory error) 메모리 에러가 나오는게 일상입니다. 이러한 large size csv file을 python에서 다룰 수 있는 방법이 간단하게 있는데요. 그 방법을 정리하고자 합니다. 최근에 메모리 효율 및 속도를 빠르게 다루는 방법도 정리해두었습니다. lsjsj92.tistory.com/604 Python(파이썬)에서 데이터 메모리 효율, 처리 속도 향상 시키는 기본 방법 정리(feat. pandas, numpy) 포스팅 개요 이번 포스팅은 최근 회..
 Python 추천 시스템 - Session based recommendations with RNN 논문 삽질 후기
Python 추천 시스템 - Session based recommendations with RNN 논문 삽질 후기
포스팅 개요 이번 포스팅은 session based 추천 시스템(Recommender system)에 관해서 간단한 리뷰와 삽질 후기입니다. 최근 회사에서 sequential data에 대해서 recommender system을 진행하게 되었었는데요. 그때 여러 방면으로 조사하던 중 Session based recommendation 방법을 알게 되었습니다. 그리고 대표 논문 중 하나인 Session based recommendation with rnn 논문을 알게 되었고 이 논문에서 받은 아이디어를 기반으로 1주일 동안 개인적으로 시도해 보았던 것(결론은 삽질 ㅠ)들을 글로 정리해보고자 합니다. 논문과 해당 논문의 코드는 아래 URL에 있습니다. 논문 : https://arxiv.org/abs/1511..
 파이썬(Python) 라이브러리 소개 - Rich 라이브러리(텍스트 출력을 이쁘게 만들어보자)
파이썬(Python) 라이브러리 소개 - Rich 라이브러리(텍스트 출력을 이쁘게 만들어보자)
포스팅 개요 이번 포스팅은 파이썬(Python) 라이브러리 소개를 하는 글입니다. 파이썬에서 프로그래밍을 하다보면 터미널 화면에 로그를 찍거나, 텍스트를 출력하거나 하는 등의 작업을 빈번하게 수행합니다. 그러나, 일반적인 텍스트는 가독성이 좋지 않다는 단점이 있습니다. 이번 포스팅에서 소개해드릴 Python의 Rich library는 이러한 터미널 환경에서 텍스트 출력을 이쁘게(rich 하게) 꾸밀 수 있는 라이브러리 입니다. 굉장히 흥미롭고 재밌는 라이브러리이기에 소개하고자 합니다. 이번 포스팅은 아래 Rich 라이브러리 github에서 제공해주는 튜토리얼을 기반으로 진행해 보았습니다. https://github.com/willmcgugan/rich willmcgugan/rich Rich is a Py..
 Python Mecab 사용자 사전 추가 에러(no such file or directory: /../dicrc) 해결하기
Python Mecab 사용자 사전 추가 에러(no such file or directory: /../dicrc) 해결하기
포스팅 목적 이번 포스팅은 Python 형태소 분석기 중 하나인 Mecab(은전한닢)에서 나오는 에러를 해결하는 방법에 대해 정리합니다. 해당 에러는 Mecab에서 사용자 사전(user dictionary)를 추가할 때 ./tools/add-userdic.sh을 실행 했을 때 나는 오류입니다. 포스팅 본문 Python으로 텍스트 데이터 특히, 자연어 처리를 할 때 형태소 분석기를 많이 사용합니다. 그리고 다양한 형태소 분석기 중 인기 있는 형태소 분석기 Mecab(은전한닢 이라고도 불리웁니다.)이 있습니다. Mecab은 속도도 빠르고, 다른 konlpy 형태소 분석기보다 정확하여 많이 사용합니다. 또한, 사용자 단어(user dictionary)를 쉽게 추가할 수 있기 때문에 매우 유용합니다. Mecab..
 시계열 분석 - 공적분 분석이란? with Python (Time series analysis cointegration with Python)
시계열 분석 - 공적분 분석이란? with Python (Time series analysis cointegration with Python)
포스팅 개요 이번 포스팅은 시계열 데이터 분석(Time series data)에서 활용되는 공적분 분석(cointegration analysis)에 대해서 정리하는 포스팅입니다. 간단한 이론적 설명과 더불어 파이썬(Python)에서 이를 어떻게 활용할 수 있는지 예시로 알아봅니다. 본 포스팅 작성 시 참고 했던 자료들은 아래와 같습니다. https://datascienceschool.net/view-notebook/d5478c5ed2044cb9b88fa2ef015eb3a4/ https://www.statsmodels.org/stable/generated/statsmodels.tsa.stattools.coint.html https://namu.wiki/w/%EA%B3%B5%EC%A0%81%EB%B6%84 ..
 Keras를 활용한 딥러닝 추천 시스템(deep learning recommender system) 구현하기
Keras를 활용한 딥러닝 추천 시스템(deep learning recommender system) 구현하기
포스팅 개요 이번 포스팅은 딥러닝(Deep Learning)을 활용해 추천 시스템(Recommender system)을 구현하는 포스팅입니다. 그 중 개인화 된 추천 시스템(personalized recommendation system)을 한 번 만들어보겠습니다. 파이썬(Python)을 활용했으며 라이브러리는 케라스(Keras)를 사용했습니다. 고급진 기술보다 기초적인 수준에 가까운 글이니 참고 부탁드리겠습니다. 이번 추천 시스템의 목적은 뉴스 추천 시스템입니다. ==참고 사항== 본 글에 나오는 Dataset은 제가 임의로 만든 Dataset입니다. 그래서 현실적인 면에서 조금 동떨어질 수 있습니다. 부디 참고 부탁드리며 Insight만 얻어 가시길 바랍니다. 또한, 본 포스팅 글은 지난 번에 작성한 ..
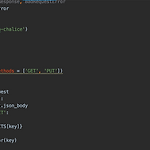 AWS Chalice란? Python 기반 serverless framework chalice 사용하기
AWS Chalice란? Python 기반 serverless framework chalice 사용하기
포스팅 개요 이번 포스팅은 AWS Chalice에 대해서 알아보려고합니다. AWS Chalice는 파이썬(Python) 기반의 serverless microframework로 알려져 있는데요~ serverless? 이게 뭘까요? 이 서버리스(serverless)가 무엇인지도 알아봅니다. 그리고 AWS lambda를 쉽게 사용할 수 있게 지원해주므로 AWS lambda에 대해서도 알아볼거에요. 나아가, AWS Chalice 설치하는 방법, 어떻게 사용하는지도 간단하게 작성하려고 합니다. 해당 포스팅은 아래 글들을 참조하였습니다. 핵심 내용을 정말 잘 설명해준 블로그 : https://jangseongwoo.github.io/lambda/chalice_tutorial/ https://github.com/aw..
 test code coverage(코드 커버리지)란? Python test code coverage 방법
test code coverage(코드 커버리지)란? Python test code coverage 방법
포스팅 개요 이번 포스팅은 test code coverage에 대해서 알아봅니다. 그냥 코드 커버리지(code coverage)라고도 불리우는 방법입니다. 그리고 파이썬(Python)에서 test code coverage를 하는 방법에 대해서도 함께 알아봅니다. test code 작성은 이전 포스팅(https://lsjsj92.tistory.com/572)내용을 기반으로 진행됩니다. 포스팅 본문 코드 커버리지(code coverage)란 무엇일까요? code coverage는 소프트웨어 프로그램에서 테스트 케이스가 얼마나 충족되었나? 정도로 생각할 수 있습니다. 즉, 코드에서 테스트가 얼마나 충족이 되었나? 입니다. 흔히, test code를 작성하게 되면 coverage도 같이 측정하게 되는데요. 이때..