

포스팅 개요
이번 포스팅은 최근 회사에서 프로젝트를 진행하며 겪은 파이썬(Python)에서 메모리 효율, 데이터 처리 속도 향상 등의 기본적인 처리 방법을 정리하는 포스팅입니다. 파이썬(Python)을 활용해서 데이터 분석이나 머신러닝 모델 작업을 진행할 때 csv와 같은 데이터를 pandas dataframe으로 불러오는데 이때 데이터 처리 하는 방법에 따라 효율적으로 용량을 줄이고, 속도도 향상시킬 수 있습니다. 이에 대한 간단한 방법을 정리하고자 합니다.
본 포스팅을 작성하면서 참고한 참고자료는 아래와 같습니다.
- stackoverflow.com/questions/9619199/best-way-to-preserve-numpy-arrays-on-disk
- www.w3resource.com/numpy/data-types.php
사용한 데이터는 kaggle의 homecredit 데이터(www.kaggle.com/c/home-credit-default-risk/data)중 installments_payment.csv를 사용했습니다.
포스팅 본문
본 포스팅에서는 Python에서 csv 데이터를 pandas dataframe으로 불러와서 아래와 같은 처리 방법에 따라 효율성이 어떻게 증대되는지 보여드리겠습니다.
- Python pandas dataframe에서 메모리 크기 감소시키기
- pandas dataframe에서 데이터 처리 속도(데이터 접근 속도) 빠르게 향상 시키기
- 파이썬에서 데이터 저장 시 저장 용량 감소시키기
pandas에서 메모리 감소시키기
가장 먼저 파이썬 dataframe에서 메모리를 감소시키는 방법을 소개해드리겠습니다. 굉장히 간단한 방법인데 생각보다 자주 놓치는 부분입니다. dataframe은 기본적으로 64bit를 사용합니다. (실수면 float64, 정수면 int64 등) 이를 데이터 범위에 맞춰서 줄여주면 되는데요. 아래 사진을 보시죠

위와 같이 데이터 범위에 따라서 64bit냐 32bit냐, 16bit냐 다양하게 사용할 수 있습니다. 즉, 데이터 범위가 32bit나 16bit로도 충분히 커버가 가능한데 64bit를 사용하는 것은 굉장히 메모리 효율이 좋지 않은 것이죠. 사용하지도 않는 영역까지 변수가 잡고 있는 것이니까요.
예시를 봐봅니다.
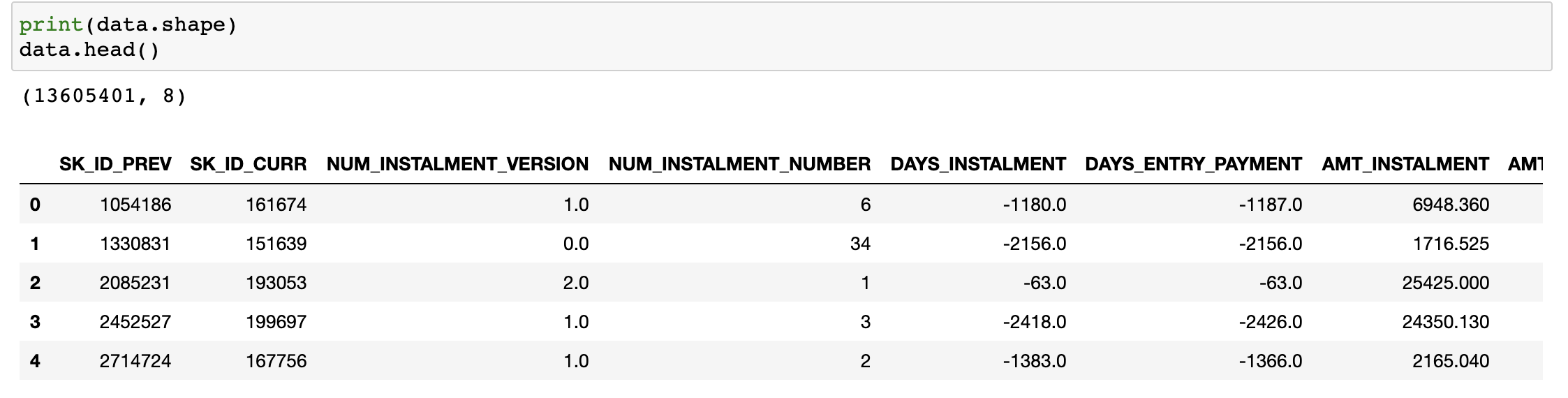
위 사진은 오리지널 데이터입니다. 1300만개의 row가 있고 8개의 컬럼을 가지고 있습니다.

이 pandas dataframe의 info() 함수를 통해 정보를 봐보면 실수는 float64, 정수는 int64로 되어있습니다. 그에 따른 메모리는 830.4MB입니다. 거의 1G이죠. 이제 이거를 불필요한 메모리를 사용하지 않고 제대로 사용하기 위해 줄여봅니다.

이 데이터의 범위를 보면 큰 값은 큰데, 작은 값은 최대가 277밖에 안되는 범위가 각각 다 다릅니다. 즉, 16bit정도면 해결할 수 있는 영역입니다. 이제 이러한 데이터의 type을 바꿔줍니다.

Python Pandas에서 데이터의 type을 바꿔줄 때는 컬럼명을 지정하고 astype으로 데이터 타입을 바꿔주면 됩니다. 저는 각각 범위에 따라 np.int32, np.float16 등으로 바꿔주었습니다. 바꿔준 후와 전의 데이터 형태가 똑같은 것을 확인할 수 있습니다.
여기서 주의하셔야 할 점이, bit의 범위를 바꿔주면 데이터에 따라 데이터의 정보를 잃을 수도 있습니다. 이를 꼭 유의하시고 진행하셔야 합니다.

그래서 그 결과는 거의 메모리 용량이 절반이 줄어든 것을 확인할 수 있습니다. 이게 단순히 840MB 정도라서 크게 변화된 것이 없는데? 라고 생각할 수도 있지만 무려 50% 정도 감소한 것입니다. 만약, 16GB 메모리를 사용하고 있었다면 8GB로 줄어든 것이죠.
이렇게 하면 Python 환경 내에서 메모리를 더욱 효율적으로 사용할 수 있고 그에따른 PC가 다른 곳에 자원을 사용할 수 있도록 할 수 있을겁니다.
pandas에서 데이터 처리 속도 증가시키기
파이썬을 활용해 데이터를 분석할 때 Python pandas를 많이 사용합니다. 그 중 DataFrame 구조를 통해 데이터를 불러오고 이 데이터를 활용하죠. 근데 이 DataFrame을 더 빠르게 처리할 수 있는 방법이 있습니다. 각각 비교해보죠.
참고
저의 local PC 성능은 아래와 같습니다.
- MacBook Pro
- 16GB
- Intel Core i7 6코어
1. 단순히 dataframe을 iloc로 접근하는 경우
python pandas dataframe에서는 iloc, loc와 같은 인덱스 기반 접근, 위치 기반 접근으로 데이터를 row나 column 단위로 불러올 수 있습니다. 이때 시간 효율은 어떻게 할까요?

아까 데이터를 볼 떄 1300만 row가 있는 데이터입니다. iloc 식으로 데이터를 접근하면 대략 23분이라는 시간이 걸립니다.
물론 PC에 따라 성능이 다르겠지만 저의 PC에서는 23분 정도의 시간이 걸렸습니다.
2. dataframe의 iterrows()를 사용하기

iterrows로 접근을 하면 시간이 훨씬 단축됩니다. 7분 정도의 시간으로 끝나네요! 이 정도만 해도 1300만개의 row를 처리하는데 빠른 시간이라고 볼 수도 있습니다. 하지만 더 빠른게 있다면 당연히 그걸 써야겠죠?
3. numpy로 접근하기

가장 최고의 성능을 보여줍니다. Pandas Dataframe을 to_numpy()로 numpy 형태로 바꿔준 뒤 데이터를 접근하면 굉장히 빠르게 접근할 수 있습니다. 무러 5.5초만에 다 접근이 되었네요. 가장 좋은 성능을 보여주죠? 즉, dataframe의 row단위로 데이터 접근할 때는 to_numpy()로 데이터를 접근하는 것이 굉장히 빠르게 처리할 수 있다는 것을 보여줍니다.
data 저장 시 용량 감소시키기
마지막으로 파이썬에서 데이터를 저장시킬 때 원본 데이터보다 더 작은 값으로 저장할 수 있는 방법을 간단하게 소개하고 글을 마무리 지으려고 합니다. 먼저 아래 사진을 보실까요?

위 사진을 보면 데이터 포멧에 따라 디스크 저장 공간, 참조 시간 등의 지표를 보여줍니다. 근데 흔히 우리가 사용하는 CSV, JSON보다 pickle 같은 데이터가 더 빠르게 데이터를 불러오는 것을 불러올 수 있습니다. 저는 여기서 추가적으로 npy(numpy) 파일로 저장하는 방법도 소개하려고 합니다. 왜냐하면 npy와 pickle을 비교해보면 numpy가 훨씬 더 적은 용량을 차지하고 더 빨리 읽어오기 때문입니다.
1. npz로 저장하기
npz로 저장하면 마치 key-value 형태로 데이터를 저장할 수 있습니다. key는 column, value는 그에 대한 값이 저장될 수 있도록 합니다. 아래와 같은 방법으로 적용할 수 있습니다.

먼저 dataframe에 있는 값들을 가져오고 아래와 같이

np.savez를 사용해서 저장하며 파일 이름은 npz형식으로 저장합니다. 그리고 그 이후의 값에 key=value 값을 넣어주면 됩니다. 이후에 데이터를 load할 때는 numpy의 load로 불러오고 변수['key']로 불러오면 됩니다.
2. pickle로 저장하기
pickle로 저장하는 방법은 워낙 유명하고 많이 하는 방법이어서 자세한 이야기는 생략하고 사진으로 대체하겠습니다.

결과 확인
이제 결과를 확인해볼까요?

npz나 pickle로 저장할 경우 둘 다 기존 데이터보다 감소한 값으로 저장된 것을 볼 수 있습니다. 그리고 처음 사진에서 보여드린 것처럼 npz는 불러오는 속도가 더 빠른 것도 확인할 수 있으실겁니다.
맺음말
이번 포스팅은 파이썬에서 데이터를 효율적으로 가져오고, 처리하고, 저장하는 방법에 대해서 정리해보았습니다. 이런식으로 데이터를 처리하면 조금이라도 더 빠르고, 저장 공간을 아끼면서 데이터 분석과 처리를 할 수 있을겁니다.
비론 이번 포스팅에서는 기본적인 내용만 다루었지만, 나중엔 좀 더 고급스런 내용을 담아보겠습니다.
'python' 카테고리의 다른 글
| 파이썬(Python) 형태소 분석기를 활용한 한국어 원형 복원 분석기 설치 및 설정하기 (2) | 2021.03.13 |
|---|---|
| Python faiss 사용법 간단 정리 - Faiss로 효율적인 vector 유사도(similarity) 구하기 (9) | 2020.11.30 |
| Python EDA 자동화 도구 Sweetviz 라이브러리란? - Sweetviz 사용법 정리 (2) | 2020.10.26 |
| Python slack API 연동하기 - slack API 설정하기 with webhooks (2) | 2020.07.30 |
| github repository로 python pip install 만드는 방법 정리 (2) | 2020.07.11 |



