
포스팅 개요
이번 포스팅은 파이썬(Python)에서 효율적인 벡터 유사도(vector similarity)를 구해주는 Faiss에 대해서 간단한 사용법을 정리합니다. 보통 벡터 유사도는 코사인 유사도(cosine similarity) 등이 구현된 라이브러리를 사용하는데요. 그 중 Faiss는 매우 빠르고 효율적입니다.
이러한 Faiss를 활용해서 vector similarity를 구하는 방법과 ID와 Vecotr를 Mapping하는 방법도 정리해보고자 합니다. 제가 참고한 자료는 아래와 같습니다.
포스팅 본문
Faiss는 facebook에서 만든 vector 유사도를 효율적으로 측정하는 라이브러리입니다. 굉장히 빠르고 강력하죠. 보통 벡터 유사도(vector similarity)를 구할 때는 numpy나 scikit-learn에서 제공해주는 cosine similarity(코사인 유사도)등을 많이 사용하는데요. Faiss를 사용하면 훨씬 빠르고 강력하게 유사도를 측정할 수 있습니다. 내부적으로 C++로 구현되어 있고 GPU도 지원해주기 때문입니다.
1. 설치 방법
설치 방법은 아래와 같습니다.
# CPU version only
conda install faiss-cpu -c pytorch
# GPU version
conda install faiss-gpu cudatoolkit=8.0 -c pytorch # For CUDA8
conda install faiss-gpu cudatoolkit=9.0 -c pytorch # For CUDA9
conda install faiss-gpu cudatoolkit=10.0 -c pytorch # For CUDA10글을 작성하는 시점인 2020.11.29 기준이구요, 자세한 것은 사이트에서 확인해주시면 됩니다!
2. 기본적인 사용 방법
먼저 기본적인 사용 방법에 대해서 알아봅니다. 개요에 올린 2번째 링크에 들어가면 매우 간단한 예시가 나와있는데요! 비슷하게 진행해보겠습니다. 먼저 faiss를 import하고 vector sample을 random으로 뽑아보겠습니다.

저는 20개의 vector sample을 32차원으로 뽑아냈습니다.
그리고 단순히 사용하는 방법은 faiss의 IndexFlatL2함수를 호출해서 벡터의 차원이 어떻게 되는지 알려줍니다. 이후에 해당 faiss의 객체에 대해서 add 함수로 vector 값을 넣어주면 됩니다.

자! 이렇게 하면 faiss 내부적으로 벡터 유사도를 계산하였습니다. 그럼 이제 faiss 내부에 계산된 값을 찾아봐야겠죠?
vector sample의 첫 번째 값을 (1, 32) 형태로 shape를 변경해 index.search 함수에 넣어줍니다. 그리고 3이라는 것은 가장 유사한 값 3개를 가지고 오는 것입니다.

그러면 return 값이 Distances, Indices (D, I)가 return 됩니다. Dinstance는 말 그대로 거리 값을 말하구요. indices는 가장 유사한 벡터가 있는 index 값을 나타냅니다.
하지만, 여기에 문제가 있죠. 만약에 ID 값이 있는 vector 값이면 어떻게 할까요?
즉, ID=100의 vector는 vector_sample[0]의 값이고 ID 123의 vector는 vector_sample[6]에 해당된다면 어떻게할까요? 단순히 indexflatl2를 사용하고 add를 사용하게 되면 첫 번째 값부터 0번으로 id 값이 들어가게 되고 그 다음 값은 1번, 2번 이렇게 번호가 들어가게 됩니다. 즉, ID=100은 0번으로, ID=123은 6번으로 들어가게 되는 것이죠!!
이것을 해결할 수 있는 방법에 대해 알아봅시다.
3. Python Faiss의 IndexIdMap2 함수를 사용하여 Index와 id를 mapping하기
자! 위에서 언급한 문제를 해결해봅시다. 처음에 제가 만든 vector sample이 20개의 vector 값이 32차원으로 있었는데요. 이 20개의 vector 값에 해당되는 ID 값을 넣어주겠습니다.

위처럼 ids 배열안에 100, 99 등의 숫자를 넣어줬습니다. 즉, id 값들을 순서대로 넣어준 것입니다. 아래처럼 데이터가 구성된 것이죠.
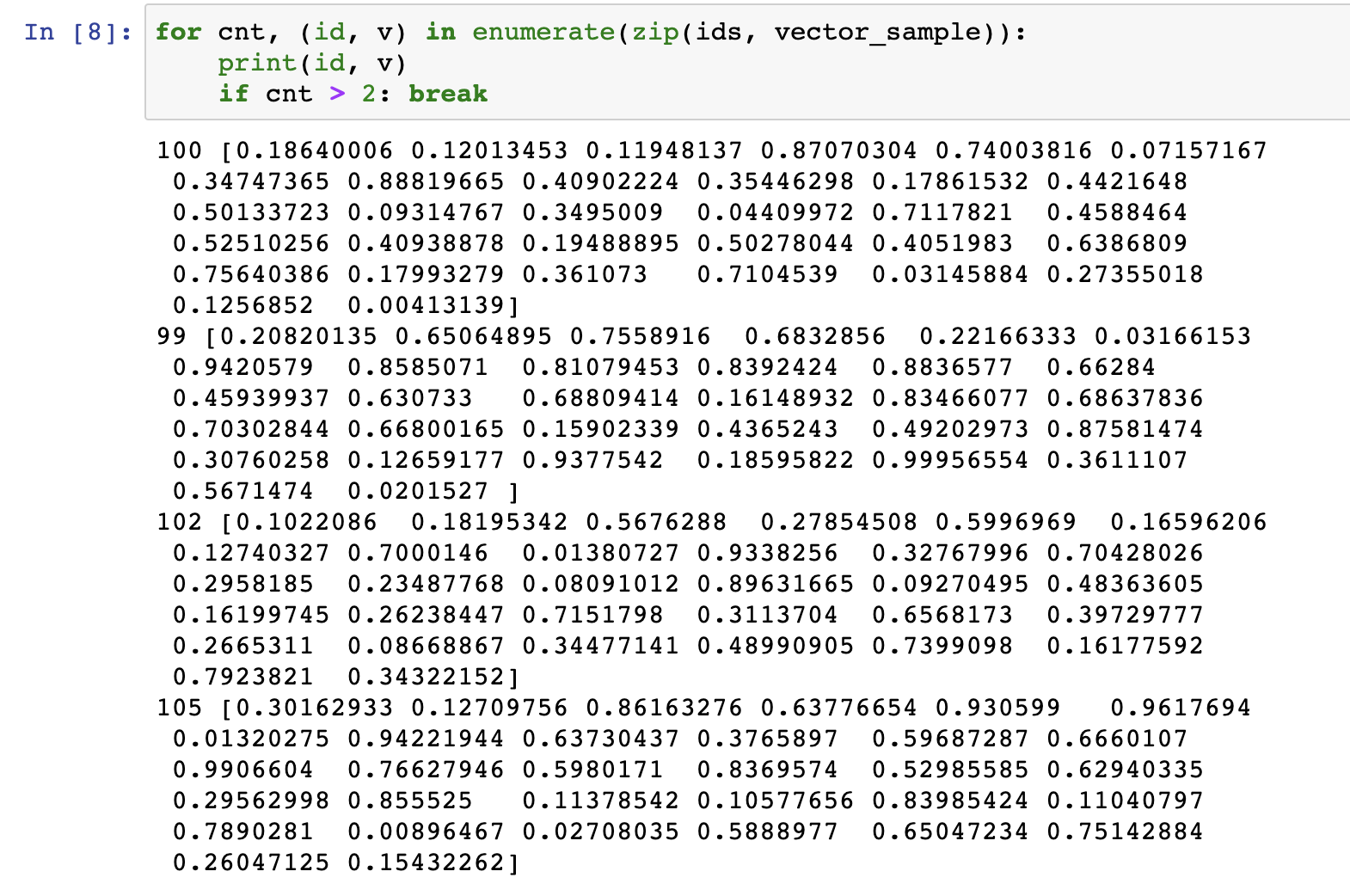
100번의 ID 값을 가진 것은 vector_sample의 0번째 값
99번의 ID 값을 가진 값은 vector_sample의 1번째 값을 가지도록 ID 값을 지정한 것입니다. 그러면 이제 Faiss에서 이 Id 값과 vector 값을 어떻게 mapping 시킬 수 있을까요? 아래와 같이 진행하면 됩니다.
index = faiss.IndexFlatL2(vector_sample.shape[1])
index = faiss.IndexIDMap2(index)
index.add_with_ids(vector_sample, ids)faiss.IndexFlatL2는 위에서 소개한 것과 동일합니다. L2 거리를 이용한 유사도를 측정하는 것이죠. 근데 원래 그 뒤에 add 함수로 넣었는데 뒷 부분이 조금 다릅니다!
faiss.IndexIDMap2 함수를 사용해서 다시 한 번 faiss 객체를 넣어줍니다. 이것은 Index를 ID와 Mapping할 수 있는 것으로 만들겠다! 라고 해석하시면 될 것 같습니다.
그 다음으로 index.add_with_ids 함수를 사용해서 add_with_ids 함수 안에 vector 값과 아까 위에서 만든 id 값들을 넣어줍니다.
그러면 이제 search하면 어떤 결과가 나오는가?!

자! search를 이용하면 실제 id 값인 100, 1234, 234 값들이 나오는 것을 확인할 수 있습니다.
아~ 또한 Faiss index.search를 할 때 여러 벡터를 한 번에 넣어주면 그 값들을 한 번에 유사도를 구해줍니다.
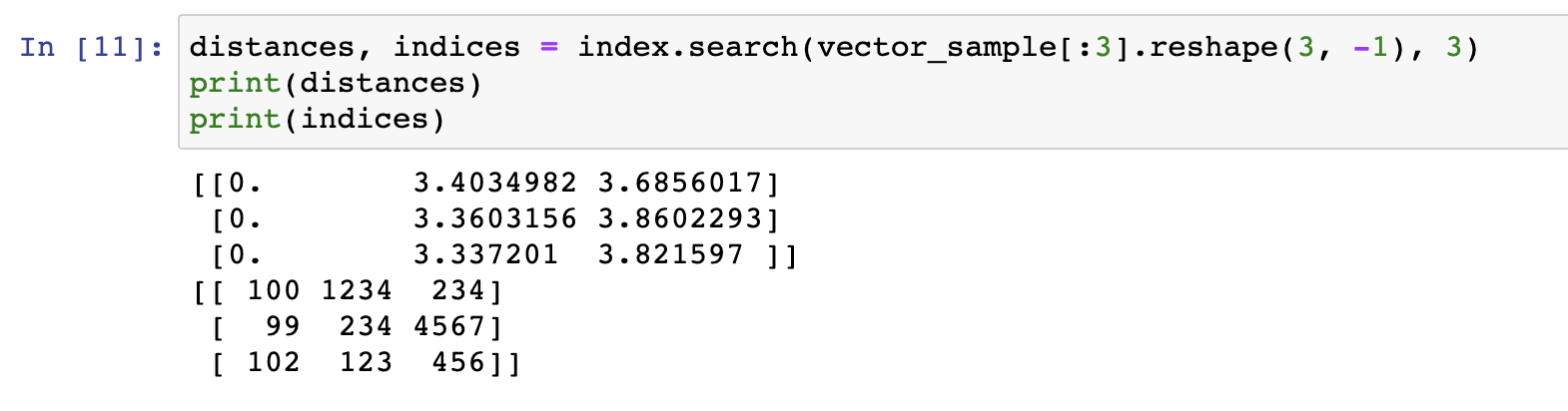
이렇게 3개를 한 번에 구할 수도 있습니다!
그러면 여기서 궁금한 점이 생길겁니다. Faiss로 구한 벡터 유사도(vector similarity)를 구했는데 그 역을 구할 수 있을까? 그니까 id 값을 넣으면 해당 id 값의 vector를 뽑을 수 있을까? 를 생각하게 됩니다.
4. Faiss index에 id를 넣어서 원래 vector 구하기
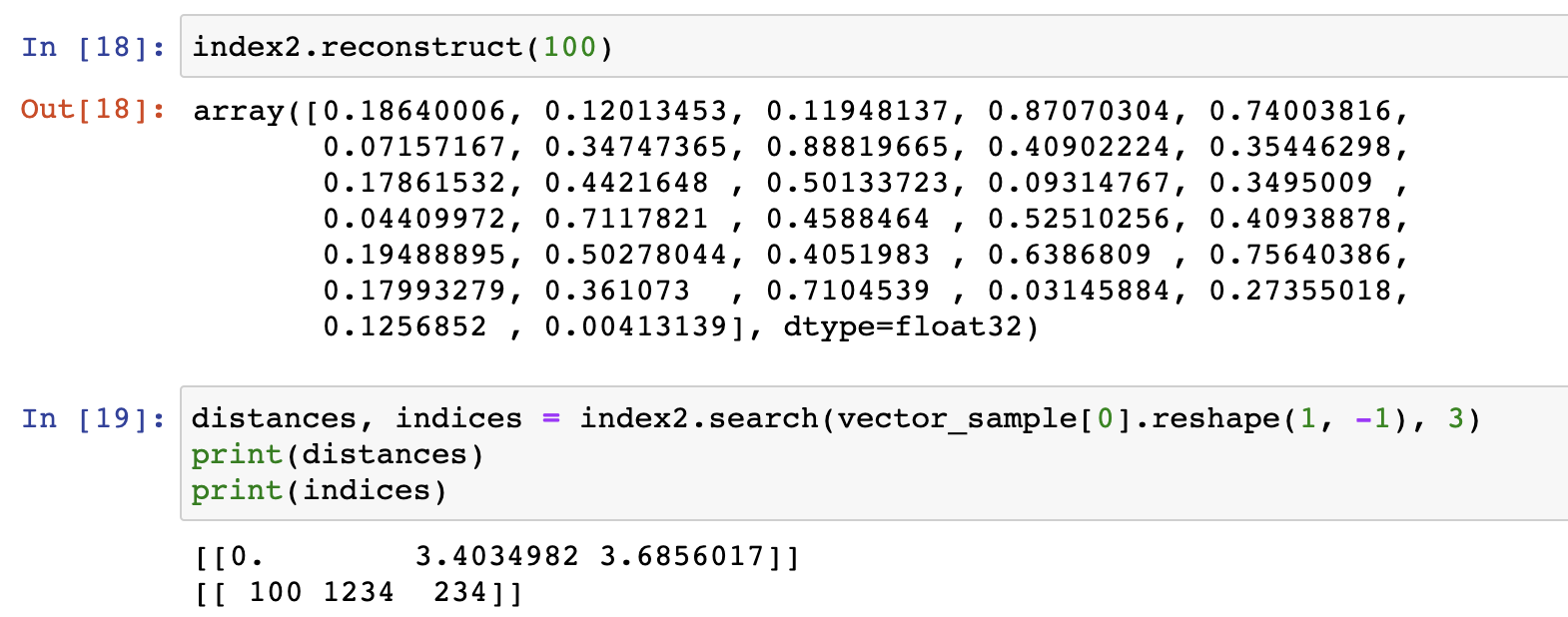
Faiss 객체를 사용해서 id 값을 넣으면 faiss에 넣었던 벡터를 구할 수 있습니다. 바로 faiss의 reconstruct를 사용하면 됩니다.
reconstruct(:id)를 해주면 됩니다. 그러면 벡터 값이 나오게 되고 실제로 벡터 값이 같은 것을 확인할 수 있습니다.

5. Faiss 저장 및 가져오기(Faiss save and load)
또한, faiss 객체를 저장하고 가져올 수도 있습니다.
faiss.write_index를 사용해서 저장하고 faiss.read_index를 사용하면 불러올 수 있습니다.
자세한 것은 아래 사진을 보시면 됩니다!

Faiss 에러 정리
Faiss를 사용하다보면 다양한 에러가 나오는데요. 그 에러들을 정리해보고자 합니다.
1. Type Error swigfaiss.py와 관련된 에러
첫 번째로 많이 겪는 에러는 다음과 같은 에러입니다.
TypeError: in method 'IndexIDMap2_add_with_ids', argument 4 of type 'faiss::IndexIDMap2Template< faiss::Index >::idx_t const *'
TypeError IndexIDMap2_add_with_ids와 같은 에러 문구가 나오면서 return _swigfaiss.IndexIDMap2_add_with_ids(self, n, x, xids)과 같은 에러 명이 나옵니다.
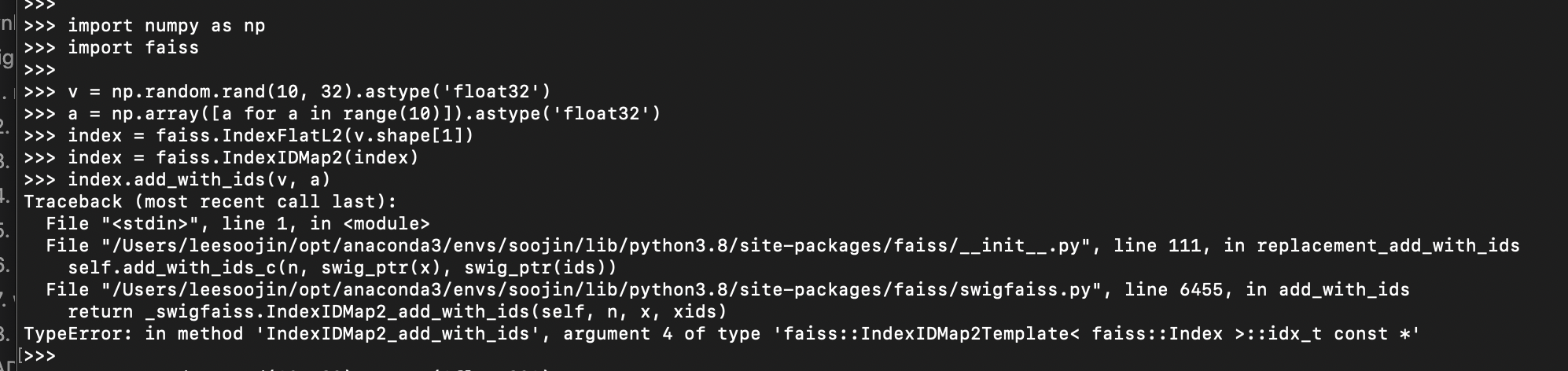
이 에러는 faiss에서 add_with_ids를 넣을 때 발생하는 에러인데요. 해결하는 방법은 아래와 같이 진행하시면 됩니다.
faiss 에러나는 코드
import numpy as np
import faiss
v = np.random.rand(10, 32).astype('float32')
a = np.array([a for a in range(10)]).astype('float32')
index = faiss.IndexFlatL2(v.shape[1])
index = faiss.IndexIDMap2(index)
index.add_with_ids(v, a)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/leesoojin/opt/anaconda3/envs/soojin/lib/python3.8/site-packages/faiss/__init__.py", line 111, in replacement_add_with_ids
self.add_with_ids_c(n, swig_ptr(x), swig_ptr(ids))
File "/Users/leesoojin/opt/anaconda3/envs/soojin/lib/python3.8/site-packages/faiss/swigfaiss.py", line 6455, in add_with_ids
return _swigfaiss.IndexIDMap2_add_with_ids(self, n, x, xids)
TypeError: in method 'IndexIDMap2_add_with_ids', argument 4 of type 'faiss::IndexIDMap2Template< faiss::Index >::idx_t const *'
에러 해결한 코드
a = a.astype('int64')
index.add_with_ids(v, a)즉, add_with_ids를 넣는 2번째 인자 값을 int64로 바꿔주면 됩니다.
맺음말
이번 포스팅은 Python에서 벡터 유사도를 효율적으로 계산하기 위해 사용되는 Faiss에 대해서 알아보았습니다.
Faiss는 vector similarity를 간단하게 사용할 수 있으면서도 매우 강력하고 빠르게 사용될 수 있는 효율적인 라이브러리입니다.
부디 도움이 되시길 바랍니다.
저에게 연락을 주시고 싶으신 것이 있으시다면
- Linkedin : https://www.linkedin.com/in/lsjsj92/
- github : https://github.com/lsjsj92
- 블로그 댓글 또는 방명록
으로 연락주시면 감사하겠습니다.
'python' 카테고리의 다른 글
| 윈도우에서 파이썬 konlpy 형태소 분석기 및 Mecab(은전한닢) 설치하고 사용자 사전 적용하기 - Python install konlpy on windows (10) | 2021.03.22 |
|---|---|
| 파이썬(Python) 형태소 분석기를 활용한 한국어 원형 복원 분석기 설치 및 설정하기 (2) | 2021.03.13 |
| Python(파이썬)에서 데이터 메모리 효율, 처리 속도 향상 시키는 기본 방법 정리(feat. pandas, numpy) (4) | 2020.11.23 |
| Python EDA 자동화 도구 Sweetviz 라이브러리란? - Sweetviz 사용법 정리 (2) | 2020.10.26 |
| Python slack API 연동하기 - slack API 설정하기 with webhooks (2) | 2020.07.30 |



