
포스팅 개요
이번 포스팅은 파이썬(Python)의 케라스(Keras)를 이용한 간단한 추천 시스템을 구현하는 포스팅입니다. 최근에 제가 진행한 추천 시스템 스터디에서 공유한 코드인데 블로그에 올릴까 말까 하다가 그래도 공유하면 좋겠다 라고 생각해서 올리게 되었습니다. 이번 포스팅에 나온 추천 모델은 추천 시스템 모델 중에서도 kaggle에서 제공되고 있는 book 데이터을 활용해서 구현해봅니다. 고급스러운 기법을 활용하는 것이 아닌, 간단한 행렬 Dot 연산과 fully connected layer를 이용해서 기본적인 추천 모델을 구현하고 소개하고자 합니다.
해당 글에서 소개된 모든 코드는 아래 제 github의 8번에 올려두었습니다.
lsjsj92/recommender_system_with_Python
recommender system tutorial with Python. Contribute to lsjsj92/recommender_system_with_Python development by creating an account on GitHub.
github.com
참고한 자료는 아래와 같습니다.
포스팅 본문
데이터는 개요에 나와 있는 kaggle의 goodbooks 데이터를 사용했습니다. 해당 데이터에 존재하는 모든 feature를 활용하지 않고 단순히 사용자가 책을 보고 난 평가 데이터만 활용해보도록 합니다.
또한, 본문에서는 2가지 추천 시스템 모델을 소개합니다.
- Dot을 이용한 추천 시스템 모델
- Keras Dense layer를 이용한 추천 시스템 모델
그리고 위에서도 언급하였듯 Keras를 이용한 추천 시스템을 구현합니다. 따라서 모든 코드는 Python Keras 기반으로 이루어져 있습니다.
기본적인 데이터 구조
먼저 사용할 기본 데이터 구조를 살펴보겠습니다. 제가 사용한 데이터는 2가지만 사용했습니다. 정확히 말하면 사실상 사용자가 책에 남긴 평점 데이터만 사용합니다. 즉, user_id - book_id - rating의 데이터만 사용하게 됩니다. 그 데이터는 아래와 같습니다.

data라는 변수에는 book_id, user_id, rating이 담긴 사용자 별 책에 대한 평점 데이터가 존재합니다. 또한, books 데이터에는 book에 대한 정보가 담겨 있습니다. 이 데이터는 나중에 추천 결과를 뽑을 때 사용합니다.
데이터에 대한 정보를 보면

일단 null 값은 없습니다. 즉, 사용자가 남긴 평점 데이터만 존재합니다. (평점을 안남긴 데이터는 없다는 것이죠)
해당 포스팅은 간단한 추천 시스템 모델 구현에 포커싱이 되어 있기 때문에 저 데이터를 train_test_split으로 나눠줍니다. 이렇게 해서 train 데이터와 test 데이터로 데이터를 나눠주겠습니다. test 데이터는 나중에 평가할 때 사용하도록 하죠.

그리고 embedding에서 사용할 unique 사용자 숫자와 unique book의 숫자 값을 빼내줍니다.

unique user는 53424명, unique book은 1만개가 있네요.
모델1. Dot 모델을 이용한 추천 시스템 모델 구현
이제 추천 시스템 모델 구현을 하나하나 해봅니다. 가장 먼저 Dot을 이용한 모델 구현입니다. 단순히 내적 연산( dot product )를 이용한 추천 모델 구현이라고 생각하시면 됩니다.
먼저 layer들을 정의합니다. 제가 여기서 사용한 layer들은 굉장히 단순합니다.
- Input layer : input을 받기 위한 용도
- Embedding layer : embedding 용도
- Flatten layer: 차원을 하나 줄이고 벡터를 피는 용도
- Dot layer : 행렬곱 연산을 수행하는 용도
layer들을 정의 후 layer를 쌓아줍니다. 쌓는 것은 만들어진 layer에 function 기반으로 넣어주면 됩니다. 코드는 아래와 같습니다.

이렇게 쌓게 되면 최종적으로 dot_result라는 값이 나오게 되고 이게 output 값이 됩니다. 이 dot product 결과는 스칼라 값(값 1개)가 나오게 되고 이 값을 통해 rating을 예측하는 형태로 구성하게 됩니다.
즉, 사용자가 책을 본 rating을 예측하는 모델을 만들어서 이를 추천 시스템 모델로 활용하는 것이죠. 사용자가 어떤 책을 선호할 지 안할지를 예측할 수 있기 때문입니다.
그럼 모델 구성을 그림으로 잠깐 봐볼까요?
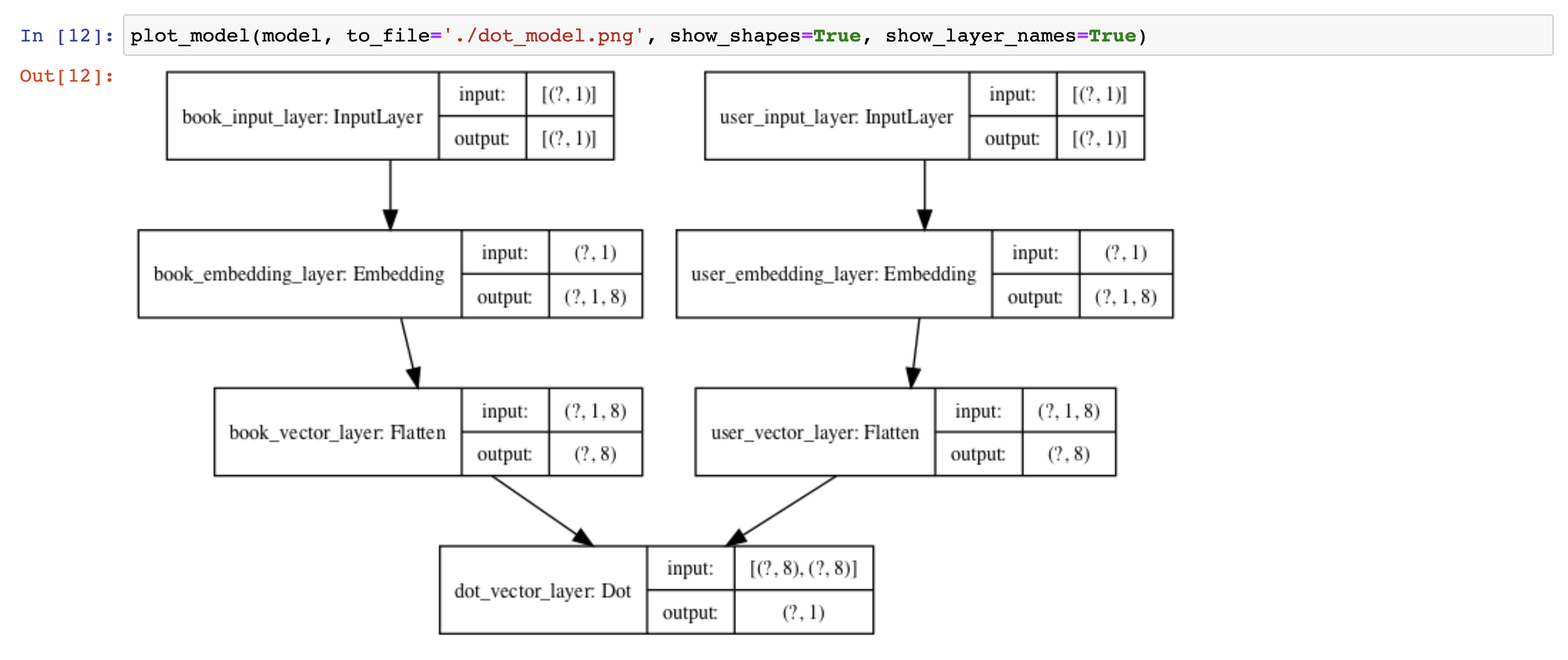
모델 구성을 보면 위 사진과 같습니다. 처음에 input은 (?, 1)이 들어오게 되고 embedding은 8차원, flatten을 거쳐서 output은 (?, 1)이 나오게 됩니다.
이제 모델을 훈련시켜줍니다. 모델 훈련의 loss는 Mean Squared Error (MSE)로 측정합니다.
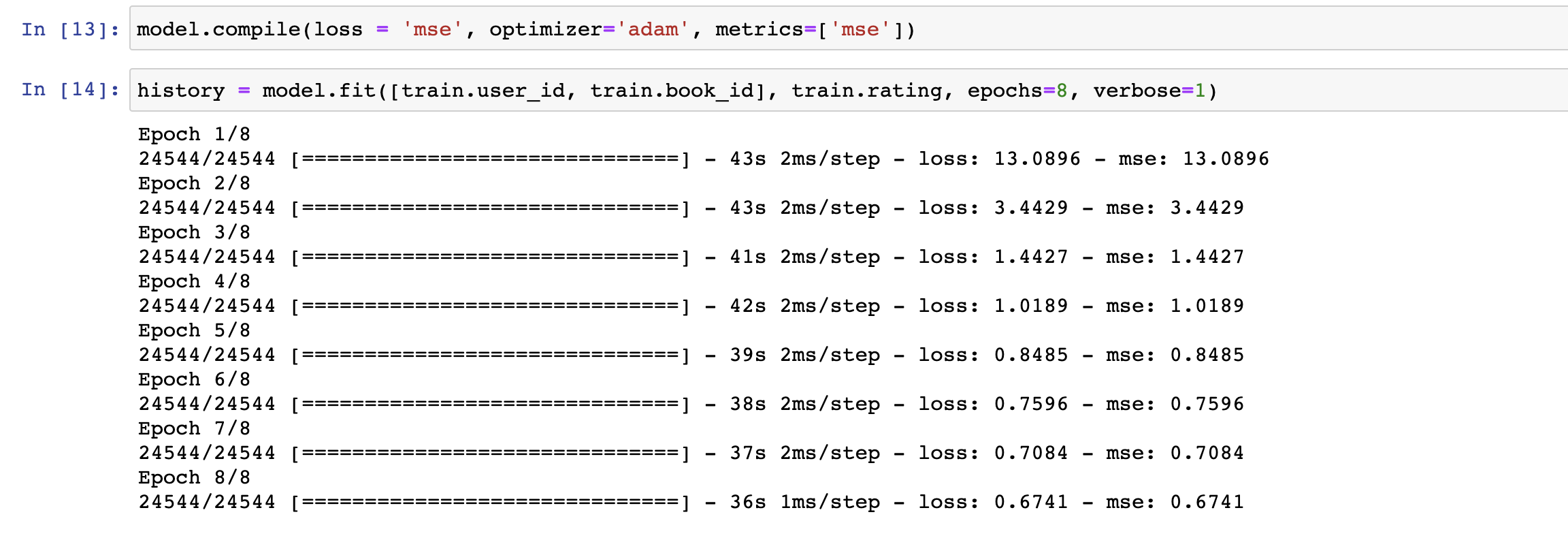
처음에는 모델 loss가 13이나 되었지만 점차 줄어들어 결국 0.6까지 떨어지는 것을 확인할 수 있습니다.
여기서 다양한 parameter 튜닝을 진행하게 되면 더욱 고도화 된 추천 시스템 모델을 만들 수 있겠죠?

실제 그래프로 그렸을 때도 loss가 떨어지는 것을 볼 수 있으며 model.evaluate의 결과로 확인하였을 때는 train보다는 살짝 높지만 어쨌건 0.9 정도의 error가 나오는 것을 확인할 수 있습니다.
그럼 그 결과를 test dataset을 이용해서 확인해볼까요? model.predict에 결과를 넣어봅니다. 그리고 실제 rating 결과와 확인해보죠.
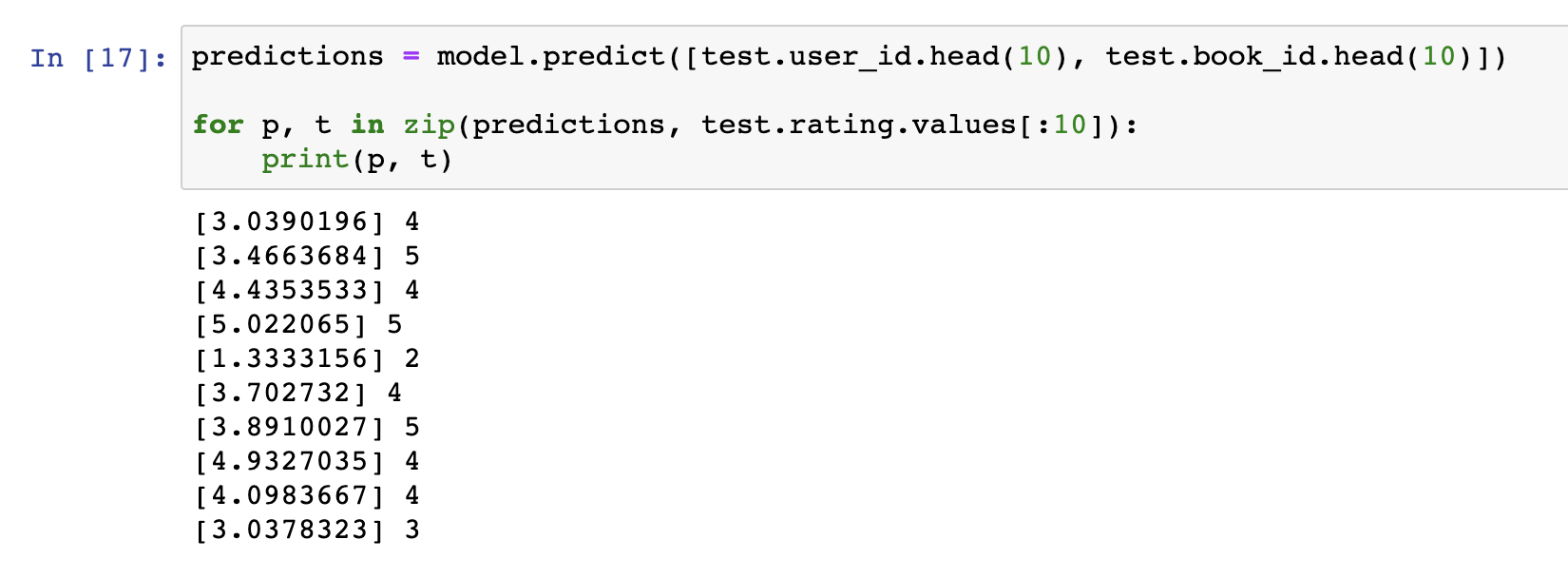
그 결과입니다. print로 출력된 왼쪽은 model의 predict 값이고 오른쪽은 실제 rating 값입니다. 실제로 근사한 결과를 보여주는 것을 볼 수 있습니다. 물론, 4짜리가 3으로 나오고 5가 3.4로 나오는 것도 있지만 그래도 나름 근사한 값을 보여주고 있네요.
여기서는 기본적인 데이터만 사용했습니다. 다양한 데이터 feature를 사용하면 더 좋은 결과가 나올 수 있을겁니다.
모델2. Fully connected layer (Keras Dense layer)를 이용한 추천 시스템 모델 구현
두 번째 모델입니다. 위 모델에선 dot product 연산으로 rating을 예측해서 선호하는 책을 추천하는 추천 시스템 모델이었습니다. 이번 모델은 dot product가 아닌 흔히 뉴럴넷(Neural Net)이라고 말할 수 있는 layer 형태로 구축해서 사용해보려고 합니다. 굳이 따지자면 딥러닝(Deep Learning) 모델입니다. 그러나 그 만큼 깊지는 않아서 딥러닝 모델이라고 부르기도 좀 어색하네요 ㅎㅎㅎ 아무튼! 케라스(Keras)에 있는 Dense layer를 적극적으로 활용한 모델입니다.
여기서도 마찬가지로 layer를 먼저 정의하고 쌓아줍니다. 여기서 사용한 layer는 아래와 같습니다.
- Input layer : input을 받기 위한 용도
- Embedding : Embedding 용도
- Faltten : 벡터 차원을 하나 낮춰주어 쭉 피는 용도
- Concatenate : 책(book) 벡터와 사용자 벡터(user vector)를 하나로 합쳐주기 위한 용도
- Dense : Dense layer 통과 용도

fully connected layer(Dense)를 이용한 추천 시스템 모델 구조는 위와 같습니다. dot 모델 구조와 다르게 여기서 최종 output은 Dense(1)이 됩니다. rating 하나를 예측하니까요. 하지만 그 전에 concatenate 구조 이후 dense layer를 거쳐서 데이터를 표현해줍니다. 그리고 나서 Dense(1)을 거쳐 rating을 예측해 추천을 해주는 추천 모델 구조입니다.

모델 구조는 위 사진과 같습니다. 아까 Dot 보다는 모델이 깊어졌습니다. 하지만 어려운 모델이 아니죠! 그나마 중요하게 보아야 할 부분이 concatenate 부분일 것 같습니다. book vector와 user vector가 각각 8차원인데 concatenate를 거치면 16 vector가 됩니다.
그리고 마찬가지로 모델을 훈려시켜줍니다.

dot 보다 loss가 적게 시작하고 최종 loss도 더 적은 것을 확인할 수 있습니다.

실제 model.evaluate 결과도 dot보다 loss가 더 낮은 것을 볼 수 있습니다.
그러면 예측 결과는 어떨까요?

음 예측 결과는 dot보다 낫다고는 할 수 없을 것 같네요. 하지만 위 샘플은 10개의 샘플을 기준으로 보여주고, 전체 샘플에 맞춰서 평가한 mse가 dot 모델 보다 낮은 것 보니 dot 추천 시스템 모델 보다는 좋은 성능을 보여주는 것을 알 수 있습니다. (MSE 기준으로는요!)
마무리
이번 추천 시스템 모델은 제가 진행했던 추천 시스템 스터디에서 공유했던 자료를 블로그에도 올려두는 자료입니다. 워낙 간단한 내용이어서 올릴까 말까 하다가 공유를 하게 되었습니다. 누군가에게는 도움이 될 것이라고 생각하면서!
이번 포스팅은 파이썬 케라스(Python Keras)를 활용한 추천 시스템 (recommender system) 모델 구현이었습니다. 단순한 모델이지만 빠르고 하이퍼라라미터 튜닝을 하게 되면 좀 더 정확한 모델을 만들 수 있을겁니다.
부디 누군가에게 도움이 되길 바랍니다!



