
포스팅 개요
이번 포스팅은 추천 시스템 논문 중 sequential base 기반 추천 시스템에 관하여 정리하는 포스팅입니다. 다양한 sequential base recommender system 논문이 있는데 이번 포스팅은 그 중 self-attentive sequential recommendation 이라는 논문을 정리합니다. 논문 제목 그대로 sequential based recommendation(recommender system) 추천과 관련한 추천 시스템입니다.
본 포스팅은 풀잎스쿨 12기 퍼실을 진행하며, 발표했던 자료를 기반으로(PPT를 기반으로) 구성되어서 사진 중간중간에 PPT 요소가 있음을 미리 알립니다.
또한, 해당 논문은 nlp 논문 attention is all you need에 나온 transformer 구조 중 self-attentiion 구조를 사용하므로 transformer에 대한 기본 배경 지식이 있어야 함을 미리 알려드립니다.
참고 자료
- arxiv.org/pdf/1808.09781.pdf
- 트랜스포머 : wikidocs.net/31379
- 트랜스포머 : jalammar.github.io/illustrated-transformer/
포스팅 본문
개요에서도 언급하였듯 이번 포스팅은 self attentive sequential recommendation 논문을 다룹니다. 해당 추천 시스템 논문을 읽고 이해하려면 먼저 attention is all you need라는 transformer에 대한 배경 지식이 있어야 이해할 수 있습니다.
따라서 논문을 정리하기에 앞서 먼저 transformer를 매우 간략히! 정리합니다. 자세한 transformer 내용은 다른 좋은 블로그 자료가 많으니 참고부탁드립니다.
Attention is all you need - Transformer
Transformer는 nlp 분야에서 일종의 혁신을 일으킨 구조입니다. 현재 BERT, GPT 등도 해당 Transformer의 encoder 부분이나 decoder 부분을 사용하고 있습니다. transformer의 구조는 아래와 같습니다.

해당 구조의 특징은 아래와 같습니다.
- encoder, decoder 구조로 되어있다.
- self attention을 사용한다. (Query, Key, Value가 들어온다.)
- multi head attention가 있다
- residual connection과 layer normalization을 사용한다.
- decoder에서는 masked multi head attention을 사용한다.
여기서 scaled dot product attention 부분이 있는데요. 여기 input으로 Query, Key, Value가 들어오게 됩니다. 이때, Q, K, V가 같은 value로 들어오면 이것을 self attention이라고 부릅니다.

scaled dot product는 위 사진과 같이 Q, K의 곱에 softmax를 취하고 이것을 value에 matmul하는 방식으로 진행됩니다. 이것에 대한 예제는 아래와 같습니다. (해당 사진들은 jallammar의 블로그에서 인용하였으며, 해당 블로그는 개요에 링크를 달아두었습니다.)
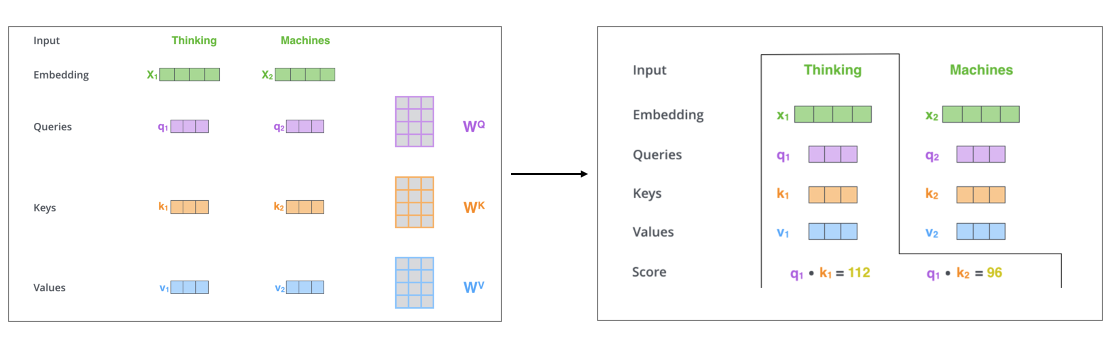
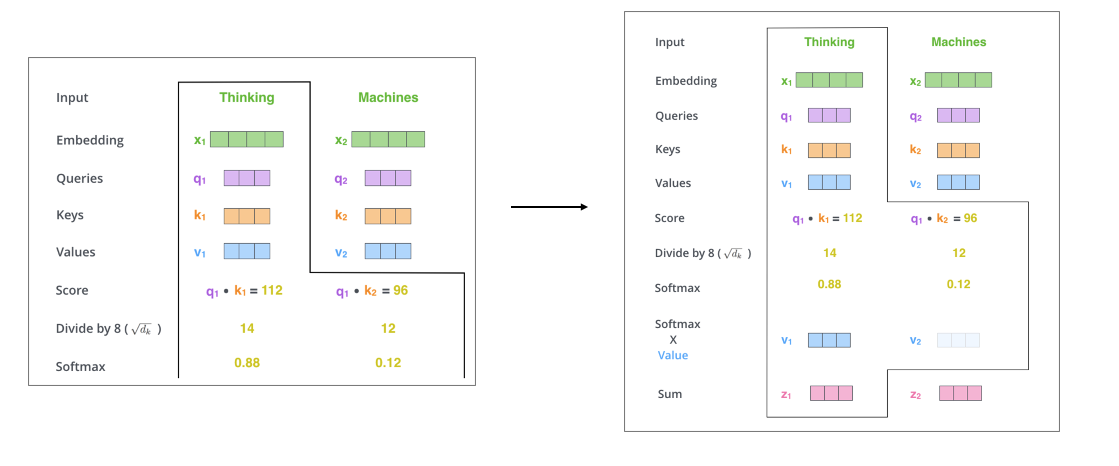
위 그림을 보면 scaled dot product attention이 어떻게 동작되는지 직관적으로 이해가 되실겁니다. divide by 8이라는 부분은 너무 값이 커서 softmax가 한 쪽에 치우치지 않도록 scaled를 해주는 역할을 합니다.
이렇게 하면 Thinking이라는 단어의 attnetion은 어디에 더 score를 많이 두는지(weight를 더 두는지) 알 수 있게 됩니다.
해당 프로세스를 행렬 연산으로 표현하면 아래와 같습니다.

단일 값에서 행렬로만 변했을 뿐 과정은 동일합니다. 그래서 마지막에 나오는 Z가 scaled dot product attention결과로 나오게 됩니다.
이제 multi head attention이 나오게 되는데요. 이 multi head attention은 scaled dot product attention을 여러개 둔 것입니다. 아래 사진과 같습니다.

식에서도 직관적으로 볼 수 있지만 scaled dot product attention을 concat해서 하나로 합친 것입니다. 그러면 최종적으로 여러개의 Z가 나오게 되겠죠? ( scaled dot product attention에서는 하나의 Z가 나왔으니까요! )
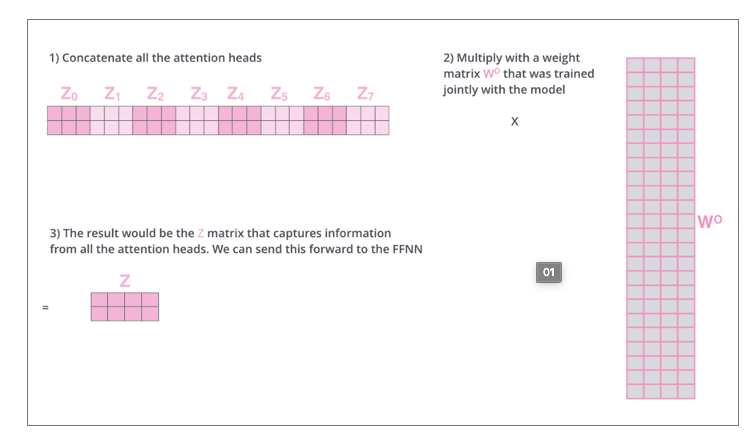
이 multi-head attention으로 나온 Z들에 shape가 일치한 weight를 두어서 최종 Z를 뽑아냅니다. 그리고 이 Z는 최초 input인 X의 shape와 동일합니다.
즉! 요약하자면 아래 그림과 같습니다.

transformer에 대한 설명은 간단하게 여기서 마치겠습니다. 훨씬 더 좋은 블로그가 많으니 이해가 안가시는 분들은 꼭! 공부를 해오시면 좋습니다.
Self-attentive sequential recommendation 논문 요약
이제 본 포스팅의 메인인 self attentive sequential recommendation 논문을 요약해봅니다. 해당 논문은 사용자의 sequential한 데이터를 사용해서 사용자의 next action을 예측하는 추천 시스템입니다. 즉, 순서가 있는 데이터를 활용해 사용자의 다음 순서를 예측해 추천해주는 방법입니다.
해당 논문은 Transformer 구조를 사용한 추천 시스템(Recommender system) 모델입니다. 저자는 MC(Markov Chains) based와 RNN based의 balance를 조절해서 둘의 장점을 살렸다고 말하고 있습니다.
Markov Chains(MCs)
- classic한 방법
- previous action(or previous few)를 사용해서 next item 추측
- high-sparsity에서 잘 동작함
- 복잡한 것에서는 잘 동작하지 못함
RNN 방법
- summarize all previous action -> Hidden state를 사용
- Dense data에 적합함
Transformer는 self-attention mechanism을 사용하고 현재 NLP task에서 굉장히 핫하다고 저자는 이야기하고 있습니다. 해당 논문이 2018년도 논문이라 더더욱 핫했던 시기입니다. 따라서 저자는 Transformer에서 아이디어를 따와서 추천 시스템을 적용했다고 합니다.
- self-attention mechansim을 적용해서 sequential recommender system을 제안
- all action에도 잘 동작하고 small number of actions에서도 잘 동작한다
- 즉, RNN based와 Markov Chains 모델의 장점을 전부 수용할 수 있다.
- Self Attention based Sequential Recommendation model이라고 해서 SASRec라고 부른다
- 병렬처리에도 잘 맞다
- 여러 task에서 SOTA를 달성
이 논문에서 주장하는 추천 시스템과 비슷한 연구는 Temporal Recommendation과 Sequential Recommendation이 있습니다. 하지만 몇가지 단점과 차이점이 존재하죠.
- Temporal Recommendation
- 시간적 feature에 영향을 받는 추천 시스템
- TimeSVD++가 대표적
- temporal recommendation은 sequential recommendation과 차이점이 존재함
- Sequential recommender system은 사용자의 order of actions만 고려함
- 시간에 독립적인 패턴을 학습함
- 즉, context of users action을 기반으로 모델ㄹㅇ
- Sequential Recommendation
- context of users action을 바라보는 모델링
- first-order markov chain은 이전의 여러 action에 관련해 next action을 추측
- GRU4Rec와 같은 RNN 기반 추천 시스템이 대표적 예시
- RNN의 한계를 가지고 있음
- Attention Mechanism(어텐션 메커니즘)
- 기존에 어텐션 메커니즘을 적용한 추천 시스템 모델이 존재하긴 했음
- 그러나 attention + RNN과 같이 component를 original model에 그냥 더하는 수준임
따라서 본 논문에서 제시하는 것은 위의 것들과 다르고, 장점을 수용한 추천 시스템 모델이라고 할 수 있습니다.
아래 사진은 본 논문에서 나오는 수식들을 정리한 테이블입니다.

본 논문에서 주장하는 모델 구조 (방법론)
해당 모델은 user action sequence를 제공해서 predict the next item을 수행합니다. 순서대로 input이 들어와서 그 다음 action을 예측하는 것으로 진행하죠.

또한, Transformer에서 사용한 것과 같이 Embedding layer를 사용하며 positional embedding도 추가합니다.

이제 논문에서는 self attention block에 대해서 설명합니다. 해당 self attention 설명은 transformer에서 나온 방법과 거의 일치하기 때문에 transformer에 대한 이해가 있으시면 바로 이해하고 넘어갈 수 있습니다.

윗 부분의 causality영역에서 sequence 특성상 t+1 항목을 예측할 때 t 이전 것만 사용한다고해서 j > i인 데이터를 못보게 한다는 내용이 있는데 저는 MASK 처리하는 영역이라고 이해했습니다.

다음으로 point wise feed forward network를 사용하며 흔히 그냥 Dense layer에 relu activation function을 적용한 layer라고 생각하시면 될 것 같습니다. 그리고 정보 전달의 효율성 증가를 위해서 residual connection을 수행하고 layer의 안정성 증가를 위해서 layer normalization을 진행합니다.
다음은 predict layer입니다. predict layer에서는 next item을 예측합니다. 따라서 item embedding feed forward를 이용합니다.

여기서 r_i,t는 t 아이템 이후 next item의 타당성을 따지는 값입니다. 이 값이 높으면 high relevance합니다.
또한, 해당 논문에서는 저 item embedding 값을 공유해서 더 효과적인 예측을 수행한다고 말하고 있습니다. 이를 통해 model size를 줄이고 overfitting을 완화한다고 합니다.
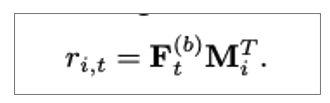
이제 network를 훈련하는데요. 다음과 같은 특징을 유지합니다.
- fixed length sequence
- 길면 truncation
- 짧으면 padding item을 더해줌

그 외에
- binary cross entropy를 사용
- adam optimizer 사용
- negative sampling 사용
등의 내용이 있습니다. 또한, transformer 구조의 장점으로 gpu 사용시 병렬처리가 가능하여 CNN, RNN 기반보다 빠르다고 이야기하고 있습니다.
Discussion에서는 모델을 이러쿵 저러쿵 바꾸면 Factorized Markov Chains나 Factorized Item Similarity models와 같은 모델로 reduce할 수 있다는 설명을 하고 있습니다. 어쨌든 이러한 model 구조로 MC-based recommendation 단점을 해결할 수 있으며 RNN 모델을 alternative할 수 있는 reasonable한 것이 있다고 합니다.
실험
해당 논문에서는 아래와 같은 데이터 셋을 사용했습니다.
- Amazon
- Steam
- MovieLens
또한, 아래와 같은 모델과 비교를 진행하였습니다.
- Feedback without considering the sequence order of actions
- PopRec
- Bayesian Personalized Ranking(BPR)
- Based on first order Markov chains
- Factorized Markov Chains(FMC)
- Factorized Personalized Markov Chains(FPMC)
- Deep learning based sequential Recommender system
- GRU4Rec
- GRU4Rec+
- Convolutional Sequence Embedding(Caser)


본 논문에서는 다양한 dataset(Dense하거나 Sparse한)에서 다른 모델들과 비교했을 때 저자들이 만든 SASRec 모델이 SOTA를 달성하며 더 우수한 성능을 보여준다고 이야기하고 있습니다. 또한, 그림2에서는 latent dim을 늘려도 성능이 유지되는 것을 보여주고 있습니다.
그리고 Ablation study를 아래와 같이 진행하였습니다.
- Positional Embedding 제거
- Item Embedding 공유 제거
- Residual Connections 제거
- Remove dropout
- number of blocks
- multi-head
- 늘리면 더 안좋음
- 해당 논문에서의 problem은 Transformer보다 적은 차원을 가지고 있기 때문에 그렇다고 추정
- Training Efficiency
그리고 그 ablation study 결과는 아래와 같습니다.


무엇보다 훈련 효율성이 다른 기타 모델보다 훨씬 좋은 모습을 보여주고 성능도 더 좋게 나오고 있음을 보여주고 있습니다.
아래 표에서는 maximum length n의 다른 길에 따라서 성능을 보여주고 있는데요. 다양한 길이에서 좋은 성능이 나온다고 이야기 하고 있습니다.

또한, 가장 흥미로웠던 내용인데요. Attention weight를 비교한 자료입니다. 이 비교는 아래와 같은 특징을 가집니다.
- (a) Sparse dataset에서는 더 최근것에 focus를 둔다
- (c)는 dense한 dataset이어서 a만큼 focus를 두지 않는다.
- (b)와 (d)는 계층적 효과를 보여준다.
- High layer는 최근 데이터에 focus를 둔다
- firt self attention block은 이미 all previous item을 고려했기 때문에 그렇다.

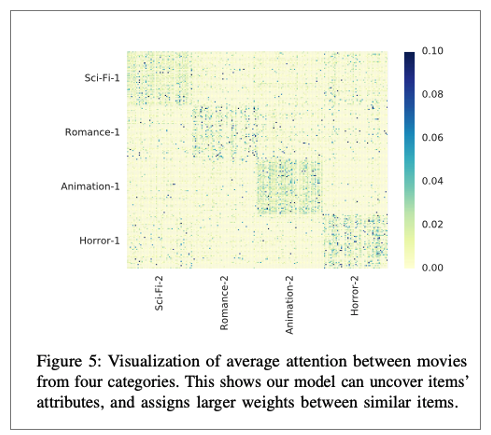
그리고 마지막으로 item 요소끼리의 attention을 보여줍니다. 비슷한 것들끼리 attention weight가 강하게 들어가는 것을 볼 수 있습니다.
마무리
이번 포스팅은 추천 시스템 중 sequentia based recommender system을 알아보았습니다. 특히 transformer에서 아이디어를 얻어 self-attention 구조를 적극적으로 활용한 방법입니다. 실제로 GRU4Rec 모델과 비교했을 때 성능 + 시간적 차이가 실감이 나도록 많이 나는 것을 보았었던 논문입니다.
부족한 글이지만 누군가에게 도움이 되길 바랍니다.



