
포스팅 개요
본 포스팅은 머신러닝(machine learning)의 라이프 사이클을 관리해주는 mlflow에 대해서 정리하는 포스팅입니다. mlflow란 무엇이고 어떻게 사용하는지 예제(example)와 함께 정리하고자 합니다.
MLflow와 관련된 포스팅은 2번에 걸쳐서 작성할 예정입니다.
- 첫 번째 포스팅 ( 이번 글 )
- MLflow란 무엇인가?
- MLflow Tracking 간단한 사용 방법과 예제 코드
- 두 번째 포스팅
- MLflow Projects 관리 및 재배포 & Package
- MLflow Model API Serving
- MLflow 실험 환경 설정 (experiment setting)
제가 mlflow를 정리하고 공부하면서 참고했던 자료는 아래와 같습니다.
Quickstart — MLflow 1.19.0 documentation
Downloading the Quickstart Download the quickstart code by cloning MLflow via git clone https://github.com/mlflow/mlflow, and cd into the examples subdirectory of the repository. We’ll use this working directory for running the quickstart. We avoid runni
mlflow.org
본 포스팅에 올라와있는 mlflow 전체 코드는 제 아래 github에서 관리하고 있습니다.
GitHub - lsjsj92/python_mlflow_example: Python MLflow(management machine learning life-cycle) example & tutorial code
Python MLflow(management machine learning life-cycle) example & tutorial code - GitHub - lsjsj92/python_mlflow_example: Python MLflow(management machine learning life-cycle) example & tutor...
github.com
포스팅 본문
MLFlow란 무엇인가?
MLflow는 A Machine Learning Lifecycle Platform이라는 컨셉을 가지고 있습니다.

MLflow는 머신러닝(Machine learning) 모델의 실험을 tracking하고 model을 공유 및 deploy 할 수 있도록 지원하는 라이브러리 입니다. 즉, 머신러닝 학습과 관련된 전반적인 lifecycle을 지원해주는 라이브러리 라고 볼 수 있습니다.
MLflow 주요 기능 및 특징
mlflow는 아래와 같은 주요 기능들이 있습니다.
- MLflow Tracking
- 머신러닝 모델( Machine Learning model)을 학습시킬 때 생기는 각종 파라미터, 그리고 머신러닝 모델 training이 끝난 후 metric의 결과 등을 logging하고 그 기록 결과를 web ui로도 확인할 수 있습니다.
- MLflow Projects
- Anaconda나 (Anaconda 없이도 사용 가능) docker 등을 사용해서 만들어 둔 모델을 reproducible 하고 실행할 수 있도록 코드 패키지 형식으로 지원해줍니다. 이러한 형식으로 만들어진 환경을 재사용할 수 있습니다.
- MLflow Models
- 동일한 모델을 Docker, Apache Spark, AWS 등에서 쉽게 배치할 수 있도록 지원
- MLflow Model Registry
- MLflow 모델의 전체 라이브사이클을 공동으로 관리하기 위한 centralized model store, set of API, UI
MLflow 사용법과 예제
이제 MLflow를 어떻게 사용할 수 있는지 알아보겠습니다. 위 특징 중 제 개인적으로 MLflow의 가장 큰 기능으로 느껴지는 부분은 MLflow tracking 부분입니다. 머신러닝이나 딥러닝(deep learning) 모델을 훈련시키고 나서 이 모델이 어떤 결과 값을 도출하였고 어떤 파라미터를 가지고 훈련했는지 히스토리를 관리하는 것은 매우 중요한데요. 이러한 모델의 logging 값들을 관리해주는 역할을 Tracking이 담당하고 있습니다.
또한, 이 모델을 어떻게 reproduce 할 지도 중요한 부분입니다. 이 부분은 MLflow Projects가 담당해주고 있습니다.
따라서 MLflow 포스팅의 MLflow 사용법은 아래 주제로 포커싱해 작성합니다. 또한, 개요에서도 말씀드렸듯이 MLflow 글은 두 번 나뉘어서 글을 작성할 예정입니다. 다음 포스팅에서 작성하는 MLflow 내용은 괄호 안에 명시하였으니 참고해주세요.
- kaggle의 Titanic data를 활용
- scikit-learn(sklearn)의 머신러닝 모델(machine learnnig model) 활용
- tensorflow 2.x keras의 딥러닝 모델(deep learning model) 활용
- MLflow Tracking
- MLflow Projects & Package( 다음 포스팅에서 작성 )
- MLflow Model API Serving ( model 배포 및 API 셋팅, 다음 포스팅에서 작성)
- MLflow experiments setting (실험 환경 셋팅, 다음 포스팅에서 작성)
먼저, MLflow를 설치해야겠죠? 설치는 간단합니다.
pip install mlflow
MLflow 예제 코드 - mlflow tracking
타이타닉 데이터 전처리하고 machine learning model을 training 하고 deep learninng model을 training 하는 부분의 코드는 생략하겠습니다. 이미 캐글 등에 많이 나와 있으니 참고해주세요. 제가 만든 코드가 궁금하시다면 제 전체 코드(https://github.com/lsjsj92/python_mlflow_example)를 참고해주세요.
main.py
main.py에서는 MLflow와 함께 전체 코드를 실행하는 main을 담당합니다. model.py에서 넘겨온 model 정보 등을 받아서 mlflow에서 제공해주는 log_metric, log_param, log_model 등에 정보를 주입시키고 관련 정보들이 mlflow에서 관리될 수 있도록 저장해줍니다.
titanic = TitanicMain()
if is_keras:
#ml_tf.autolog(log_models=True) # 이렇게도 저장 가능
tf_model, model_info = titanic.run(is_keras)
log_metrics(model_info['score'])
log_params(model_info['params'])
ml_keras.log_model(tf_model, 'tf_keras_model')
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
else:
model, model_info = titanic.run(is_keras, args.n_estimator)
'''log metric을 하나하나 등록할 때는 아래와 같이 진행
#log_metric("rf_score", score_info['rf_model_score'])
#log_metric("lgbm_score", score_info['lgbm_model_score'])
'''
# metrics를 한 번에 등록 -> json 형태가 되어야 함
log_metrics(model_info['score'])
log_params(model_info['params'])
ml_sklearn.log_model(model, 'ml_model')
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
model.py
model.py에서는 텐서플로(tensorflow2.X)의 딥러닝 모델과 사이킷런(scikit-learn) 라이브러리의 머신러닝 모델을 가지고 타이타닉 데이터를 훈련합니다. 그리고 training된 model과 이 model의 하이퍼파라미터(hyperparameter) 정보를 main.py에 return 해줍니다.
def run_sklearn_modeling(self, X, y, n_estimator):
model = self._get_rf_model(n_estimator)
#lgbm_model = self._get_lgbm_model(n_estimator)
model.fit(X, y)
#lgbm_model.fit(X, y)
model_info = {
'score' : {
'model_score' : model.score(X, y)
},
'params' : model.get_params()
}
return model, model_info
def run_keras_modeling(self, X, y):
model = self._get_keras_model()
model.fit(X, y, epochs=20, batch_size=10)
#predictions = model.predict(X)
#print('keras prediction : ', predictions[:5])
model_info = {
'score' : {
'model_score' : np.float64( round(model.evaluate(X, y)[1], 2) )
},
'params' : {'epochs':20, 'batch_size':10}
}
return model, model_infoMLflow - Tracking
본 코드에서 MLflow Tracking은 machine learning 혹은 deep learning model을 training하고 그 결과 값등에 대해서 logging 처리를 한 후 관리해준다고 했습니다. 제가 작성한 코드에서 MLflow Tracking을 하는 부분은 다음과 같습니다.
- log_metric (혹은 log_metrics)
- 머신러닝 혹은 딥러닝 모델의 metric(평가 지표)를 logging
- metric이라고 하면 정확도(accuarcy), f1-score, precision, recall 등임
- log_param(혹은 log_params)
- 모델에서 사용되는 파라미터 값을 저장
- log_param은 하나하나 저장할 때 사용하며 json 형태로 한 번에 저장하고 싶으면 log_params를 사용
- log_model
- machine learnnig model이나 deep learnnig model을 저장
- 본 포스팅에서는 tensorflow2.X keras 딥러닝 모델과 scikit-learn의 머신러닝 모델을 저장함
실행 결과
본 코드를 실행하면 아래와 같은 결과들을 확인할 수 있습니다. 제 코드에서 실행은 아래와 같이 실행합니다.
python main.py --is_keras 0 --n_estimator 110
mlflow가 있는 프로그램을 실행 하게 되면 model save in run ~ 이 나오면서 별 다른 메세지 없이 프로그램이 종료됩니다. 이때 저장된 mlflow 정보는 mlruns 라는 디렉토리에 저장됩니다. mlruns는 mlflow를 실행시킨 디렉토리에 생성이 되어 있을겁니다.
위에서 mlflow tracking을 했을 때 web ui로 확인할 수 있다고 말씀드렸습니다. 이를 확인하기 위해 또 다른 터미널을 열어서 mlflow ui를 입력합니다.

그러면 http://127.0.0.1:5000 지점에서 listening을 하고 있다고 정보가 나오는 것을 확인할 수 있습니다. 해당 web을 들어가보면 결과를 확인할 수 있습니다.

즉, 위와 같이 mlflow를 이용해서 실행한 machine learning logging 기록이 기록되어져 있음을 확인할 수 있습니다. main에서 확인할 수 있는 정보는 다음과 같은 정보들이 있습니다.
- start time
- user, source, version
- models
- metrics
- parameters
- 등
그리고 start time에 나와있는 파란색 글씨를 클릭하면 더 자세한 정보를 확인할 수 있습니다.

들어가보면 파라미터가 무엇이고 어떠한 값을 사용했는지 확인할 수 있습니다. 즉, 해당 코드는 titanic dataset을 이용해서 랜덤포레스트(random forest) model을 사용했는데요. 이 랜덤포레스트 모델의 하이퍼파라미터 값을 확인할 수 있습니다.
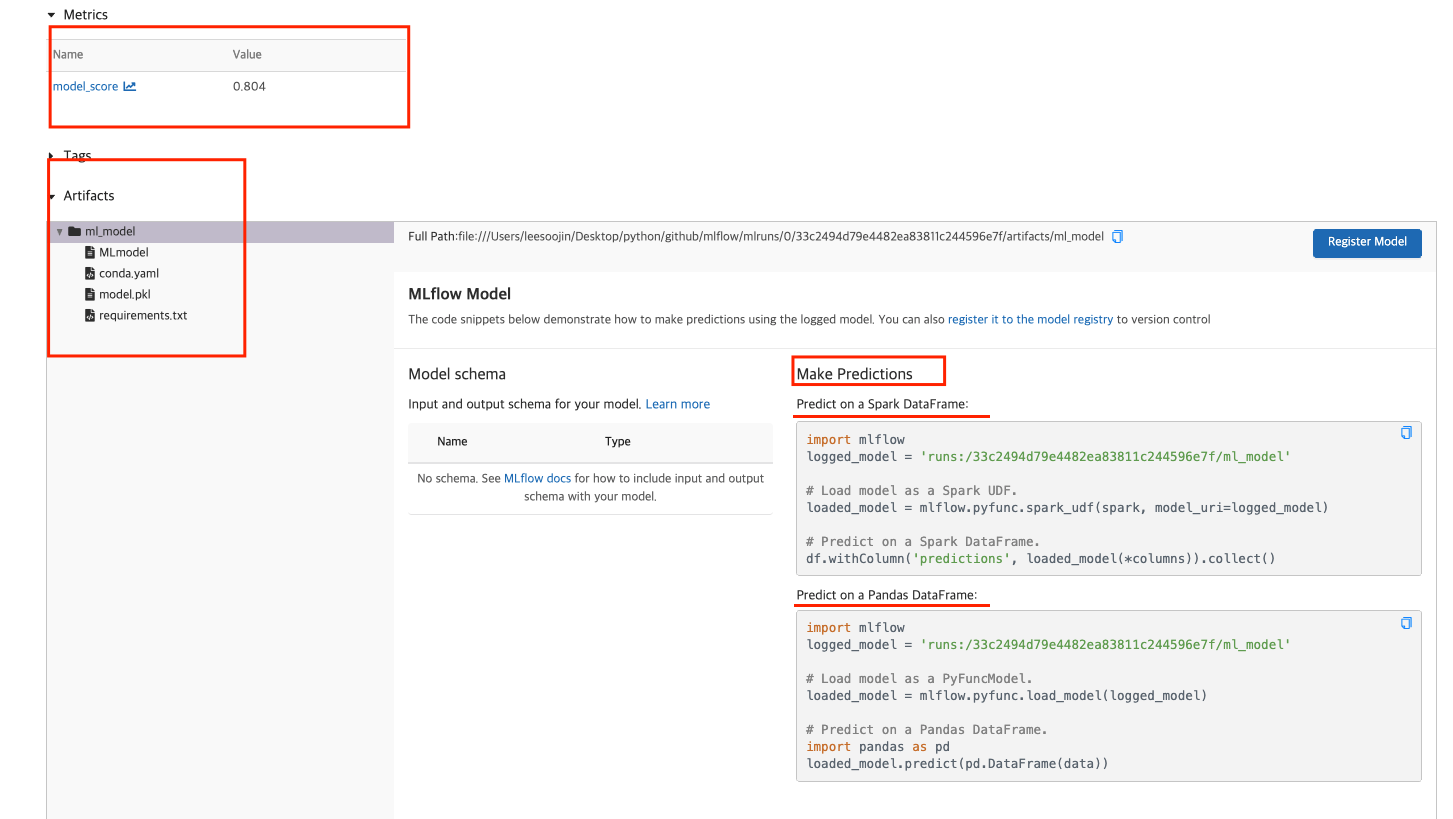
그리고 조금 더 내려다보면 이 모델의 metric이 어떠한지 나옵니다.
또한, 이 모델의 artifacts를 확인할 수 있습니다. 이 artifacts에는 prediction으로 만들 수 있는 방법에 대한 설명과 MLmodel 파일 내용, conda.yaml의 내용이 있음을 확인할 수 있습니다. 이 MLmodel과 conda.yaml을 활용해서 MLflow Projects를 생성할 수 있습니다. ( 관련한 것은 다음 글에 작성합니다. )
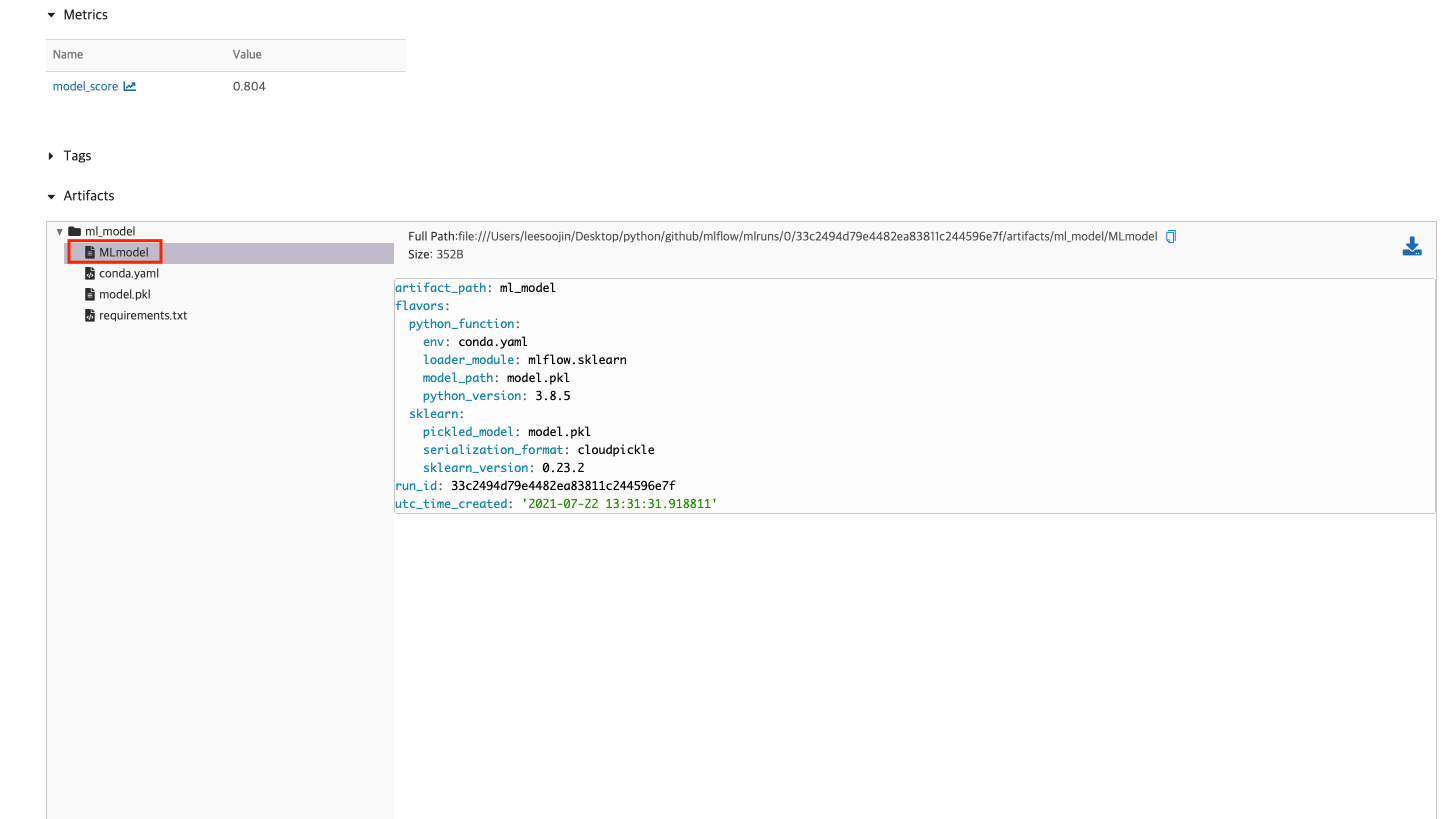
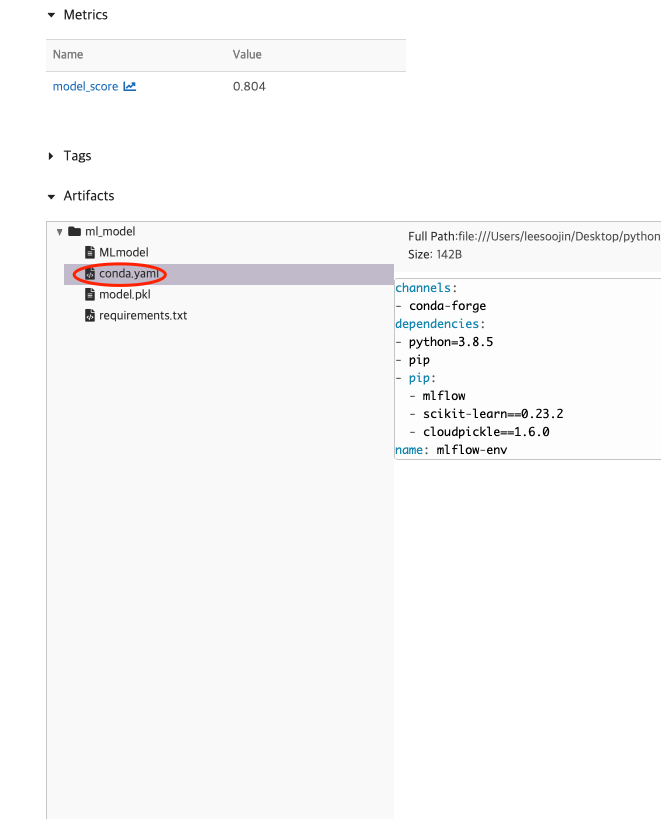
이렇듯 mlflow가 지원해주는 model tracking을 활용하면 해당 머신러닝(machine learning) 모델이 어떠한 결과와 어떠한 값을 사용했는지의 logging 정보를 쉽게 확인할 수 있습니다!
Tensorflow2.X 사용 결과
위에서는 사이킷런(scikit-learn, sklearn)을 사용해서 머신러닝 모델을 tracking한 결과를 보여주었는데요. 이번엔 tensorflow2.X의 keras를 사용해서 딥러닝 모델을 tracking 한 결과만 보여드리겠습니다.
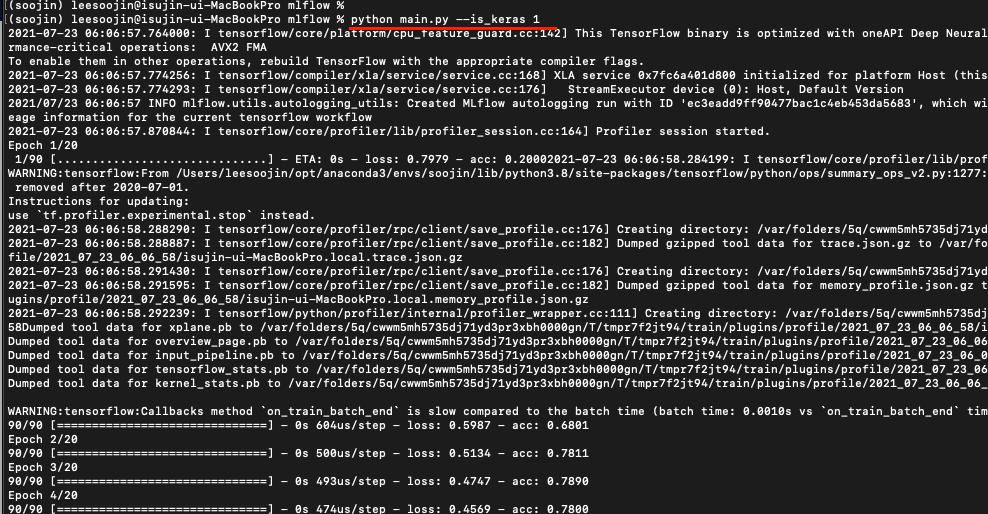
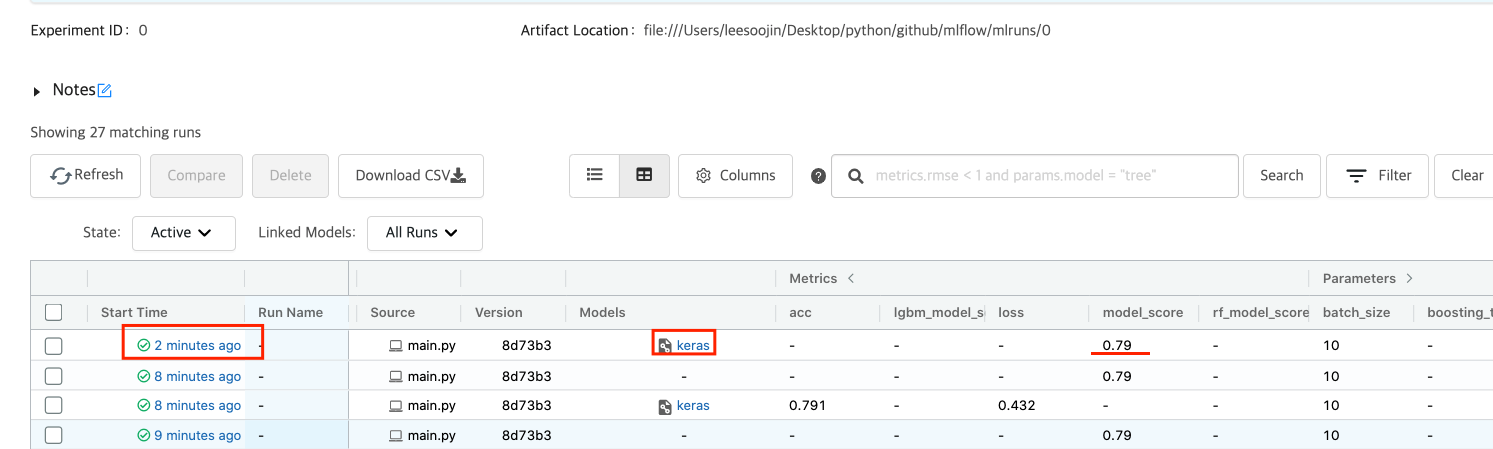
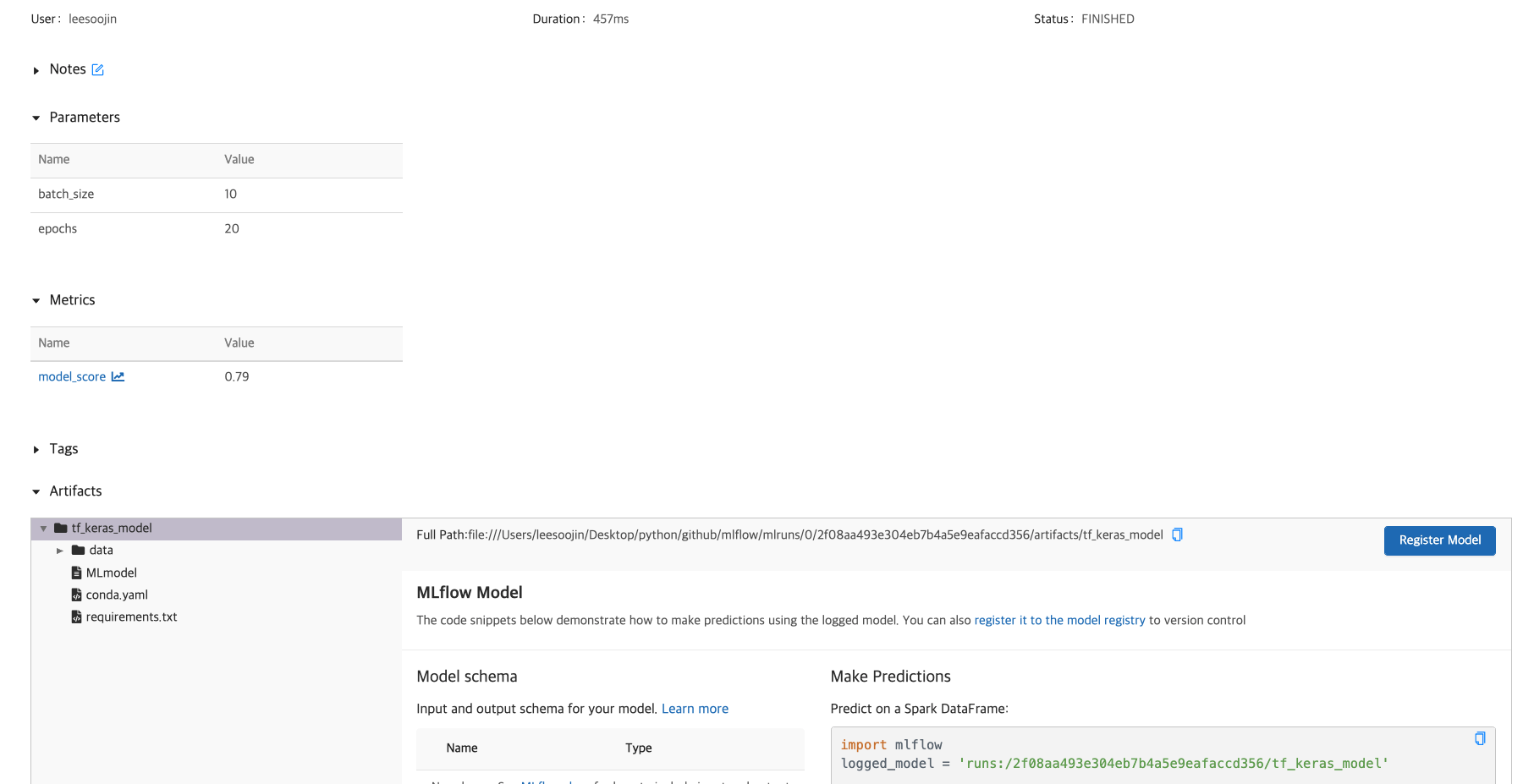
딥러닝으로 결과도 마찬가지로 똑같이 결과가 나오는 것을 확인할 수 있습니다. 다만, model에서 나오는 값이 keras로 바뀌었으며 model_score 뿐만 아니라 logging을 잘 하게 되면 loss가 어떻게 되는지까지 확인할 수 있습니다.
mlflow ui host 변경하기
위 예제에서 mlflow ui를 실행하면 127.0.0.1:5000으로 실행됩니다. 이는 localhost에서 접속이 가능한 주소인데요. 만약 mlflow을 외부에서도 볼 수 있게 하려면 아래와 같이 host를 변경할 수도 있습니다.
mlflow ui --host 0.0.0.0
또는
mlflow server --host 0.0.0.0마무리
이번 포스팅은 MLflow 글 중 MLflow란 무엇이고 MLflow의 다양한 기능 중 Tracking 기능을 어떻게 사용하는지 작성했습니다.
다음 포스팅에서는 MLflow 실험 환경 셋팅과 MLflow Project(MLModel) 관리, Machine Learning model을 API로 배포하는 글을 작성하겠습니다.
부족한 글이지만, 부디 도움이 되시기를 바랍니다.



