

포스팅 개요
이번 포스팅은 지난 포스팅에 이어서 파이썬(Python) BentoML에 대해서 작성하는 2번째 글입니다. BentoML은 머신러닝(machine learning) 혹은 딥러닝(deep learning) 모델을 API 형태로 서빙할 수 있도록 기능을 제공해주는 파이썬(Python) 라이브러리 입니다.
지난 포스팅에서는 Machine Learning model API serving BentoML에 대해서 소개 및 기본 예제를 소개했는데요.
이번 포스팅에서는 BentoML 예제 위주로 아래와 같은 내용을 간단하게 소개하고자 합니다.
- Tensorflow 2.X 기반의 딥러닝 모델 BentoML 적용하기
- Dockerfile을 이용해서 Docker image 생성 후 API serving 적용하기
- 다중 predict 만들기 등 기타 예제
지난 BentoML 첫 번째 글은 아래와 같습니다.
이수진의 블로그
안녕하세요. 이수진이라고 합니다. 이 블로그는 AI(인공지능), Data Science(데이터 사이언스), Machine Learning, Deep Learning 등의 IT를 주제로 운영하고 있는 블로그입니다.
lsjsj92.tistory.com
제 블로그에 올린 관련 코드는 아래 제 github에 코드를 전부 업로드 했습니다.
GitHub - lsjsj92/python_bentoml_example: Python bentoML(API serving for machine learning model) example & tutorial code
Python bentoML(API serving for machine learning model) example & tutorial code - GitHub - lsjsj92/python_bentoml_example: Python bentoML(API serving for machine learning model) example & tu...
github.com
이번 글에서 제가 참고한 자료는 아래와 같습니다.
- https://github.com/bentoml/gallery
- https://github.com/bentoml/BentoML
- https://docs.bentoml.org/en/latest/index.html
Model Serving Made Easy — BentoML documentation
© Copyright 2021, bentoml.org. Revision 1648a294.
docs.bentoml.org
포스팅 본문
포스팅 개요에서도 말씀드렸듯이 이번 포스팅은 Python BentoML의 예제 위주로 간단하게 살펴봅니다. 따라서 본문은 각 예제마다 성격을 나누어서 작성합니다.
이번 예제에서는 아래와 같은 데이터와 환경을 사용합니다.
- 캐글(kaggle)의 titanic 데이터 활용
- python3.7 or python3.8
- tensorflow 2.2.0
1. Tensorflow 2.X 딥러닝(deep learning) 모델 BentoML 적용하기
먼저 deep learning model을 BentoML에서 사용하는 예제를 정리합니다. 저는 Tensorflow2를 사용했습니다. 딥러닝 모델 적용을 위해서는 지난 번과 동일하게 3가지 요소가 필요합니다.
- 딥러닝(Tensorflow) model training
- API serving 환경을 제공해주는 classifier
- model packing
또한, 전체 프로세스는 아래와 같이 흘러가게 됩니다.
- 타이타닉 csv load 및 전처리
- tensorflow model training
- training 된 모델 return
- BentoML로 model packing
- BentoML serving
- 결과 확인
여기서는 BentoML과 관련된 코드만 작성해두었습니다. 전체 코드는 개요에 소개해드린 github를 참고해주세요.
model.py
가장 먼저 tensorflow model에 해당하는 부분의 코드입니다. 단순히 tensorflow keras를 이용해서 모델을 구성하고, 훈련한 뒤 모델을 가져옵니다.
def run_keras_modeling(self, X, y):
model = self._get_keras_model()
model.fit(X, y)
predictions = model.predict(X)
print('keras prediction : ', predictions[:5])
return model
def _get_keras_model(self):
inp = Input(shape=(3, ), name='inp_layer')
dense_layer_1 = Dense(32, activation='relu', name="dense_1")
dense_layer_2 = Dense(16, activation='relu', name="dense_2")
predict_layer = Dense(1, activation = 'sigmoid', name='predict_layer')
dense_vector_1 = dense_layer_1(inp)
dense_vector_2 = dense_layer_2(dense_vector_1)
predict_vector = predict_layer(dense_vector_2)
model = Model(inputs=inp, outputs=predict_vector)
model.compile(loss = 'binary_crossentropy', optimizer='adam', metrics=['acc'])
return model
classifier.py
다음은 classifier 부분의 코드입니다. 저는 Tensorflow를 적용한 classifier 클래스의 이름을 TitanicTFClassifier로 지정했습니다. 이는 나중에 packing 후 BentoML 환경을 저장할 때 상위 디렉토리로 생성이 됩니다. 해당 classifier의 특징을 요약하면 아래와 같습니다.
- Class 명은 TitanicTFClassifier ( BentoML 저장 시 상위 디렉토리로 지정 )
- @env는 requirements_txt_file 매개값을 이용해서 requirements.txt 파일을 불러와서 진행
- @artifacts로 KerasModelArtifact를 사용하며 모델 명은 tf_model로 지정
관련 코드는 아래와 같습니다. 여기서 PickleArtifact로 mapping이 있는데요. 이 mapping과 관련된 예제는 4번에 작성하였으니 참고 부탁드립니다.
from bentoml import env, artifacts, api, BentoService
from bentoml.adapters import DataframeInput
from bentoml.service.artifacts.common import PickleArtifact
from bentoml.frameworks.keras import KerasModelArtifact
@env(
requirements_txt_file="./requirements.txt"
)
@artifacts([KerasModelArtifact('tf_model'), PickleArtifact('mapping')])
class TitanicTFClassifier(BentoService):
def mapping_df(self, df):
df['Gender'] = df['Gender'].map(self.artifacts.mapping)
return df
@api(
input = DataframeInput( columns=EnvConfig().get_column_list() ),
batch = True
)
def predict(self, df: pd.DataFrame):
print(df.head())
print(self.artifacts.mapping)
df = self.mapping_df(df)
print(df.head())
return self.artifacts.tf_model.predict(df)bentoml_process.py
이제 tensorflow 모델을 packing하는 부분입니다. 이 부분의 특징은 다음과 같이 정리할 수 있습니다.
- 머신러닝(machine learning) 혹은 딥러닝(deep learning) 모델을 입력으로 받음
- bentoml classifier를 생성하고 모델을 packing
- packing 결과 저장
여기에는 mapping이라는 값 또한 packing을 진행하는데요. 관련한 글은 4번에 작성되어 있으니 참고 부탁드립니다.
from classifier import TitanicTFClassifier
classifier_service = TitanicTFClassifier()
classifier_service.pack('mapping', EnvConfig().get_gender_mapping_code())
classifier_service.pack('tf_model', model)
이렇게 하고 main.py를 실행시켜주면 됩니다. main을 실행시키면 딥러닝 모델을 학습시키고 해당 모델을 packing 및 결과를 생성해줍니다. 만들어진 bentoml service를 이제 serving 하면 됩니다. 아래와 같은 명령어로 실핼할 수 있습니다.
bentoml serve {classifier}:{version}
-> bentoml serve TitanicTFClassifier:latest위와 같이 실행하면 running on ~이 나오면서 url 주소가 나옵니다. 해당 주소에 들어가게 되면 아래와 같은 swagger ui를 확인할 수 있습니다.

그럼 API 호출을 통해 결과를 확인해봐야겠죠? 아래와 같은 명령어로 API 호출을 진행합니다.
curl -i \
--header "Content-Type: application/json" \
--request POST \
--data '[["male", 2, 1]]' \
localhost:5000/predict
== JsonInput으로 받을 경우 ==
curl -i \
--header "Content-Type: application/json" \
--request POST \
--data '[{"Gender": "male", "Age_band": 2, "Pclass": 1}]' \
localhost:5000/predict
그 결과는 타이타닉에 탑승한 male, 2, 1 탑승객의 생존 확률 값이 나오게 됩니다. 이제 저 확률을 적절히 치환해서 1, 0으로 바꿔주면 되겠죠?
이렇게 API 호출을 진행하면 API server에서는 아래와 같이 결과가 나오게 됩니다.

위에서는 1명의 탑승객 정보를 API 호출로 보냈는데요. 이렇게 하나의 input data가 아니라 여러 개의 input data를 보내려면 아래와 같이 API call을 하시면 됩니다.
curl -i \
--header "Content-Type: application/json" \
--request POST \
--data '[["male", 2, 1], ["female", 1, 3]]' \
localhost:5000/predict
== Json일 경우 ==
curl -i \
--header "Content-Type: application/json" \
--request POST \
--data '[{"Gender": "male", "Age_band": 2, "Pclass": 1}, {"Gender": "female", "Age_band": 1, "Pclass": 3}]' \
localhost:5000/predict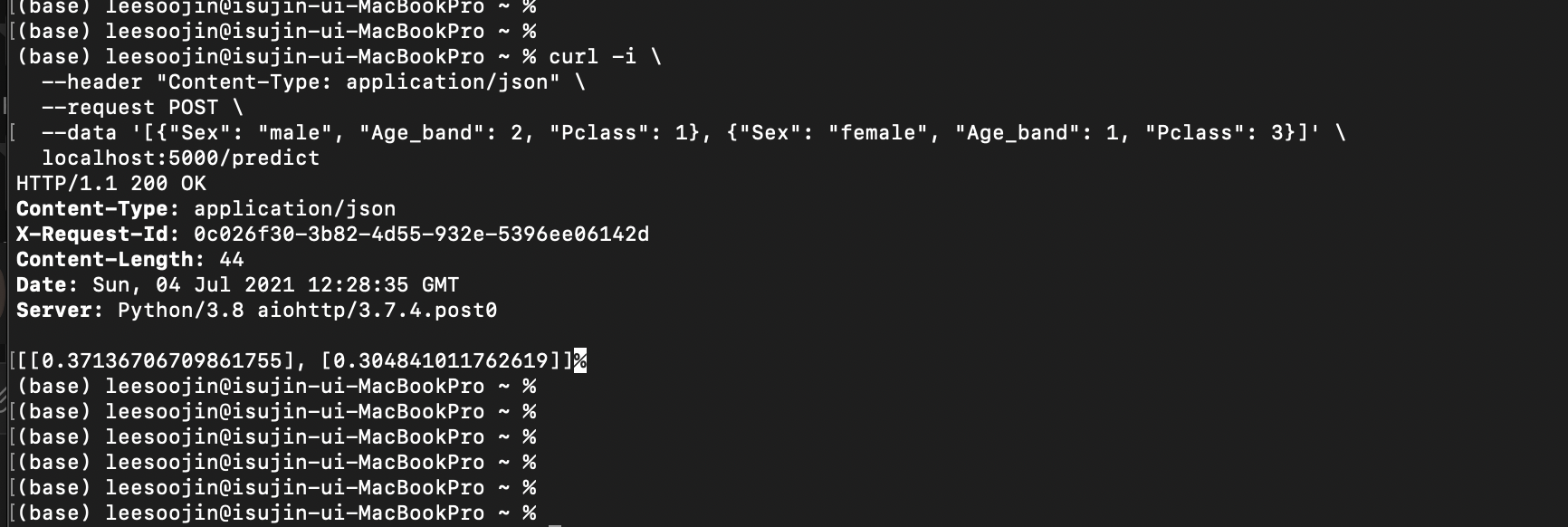

그러면 위 사진과 같이 결과 확률 값이 2개로 나오는 것을 확인할 수 있습니다.
2. BentoML Dockerfile을 이용한 Docker image 생성 및 API 배포
개인적으로 BentoML의 가장 큰 장점은 Machine Learning model을 API로 Serving 할 수 있는 것과 Docker image를 만들어 줄 수 있는 Dockerfile 환경 파일도 같이 제공해주는 것입니다.
BentoML을 실행시키면 save 경로가 나오는 것을 실행하셨을 때 확인할 수 있으셨을겁니다. 이 경로는 기본적으로 이 경로는 다음과 같습니다.
- ~/bentoml/repository/{name}/{version}
해당 경로에 있는 repository에 들어가서 tree 명령어를 입력해보면 아래와 같은 결과를 확인할 수 있습니다.
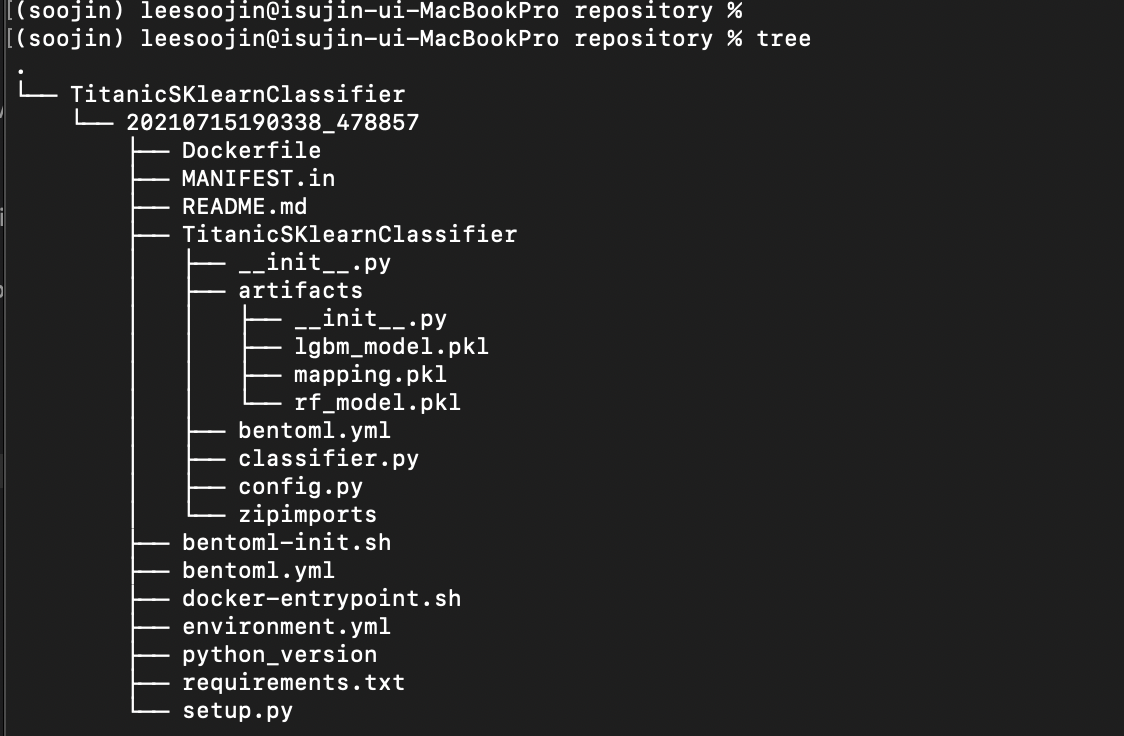
위 예시에서는 지난 포스팅에서 보여드렸던 TitanicSKlearnClassifier가 나와있습니다. 이는 classifier.py에 있는 class 이름에 따라서생성됩니다. 그 아래에 버전에 따라 디렉토리가 생성되고 다시 그 안에 다양한 파일들이 있는데요. 그 중에 Dockerfile이 보이실겁니다.
Dockerfile을 이용해서 해당 BentoML model을 docker image 형태로 만드려면 아래와 같이 docker image를 build하면 됩니다.
docker build -t lsjsj92/titanic_bentoml ./TitanicSKlearnClassifier/20210715190338_478857
그러면 위 사진과 같이 docker image가 생성되는 과정을 확인할 수 있습니다. 이 docker build 작업이 끝나면 docker images 명령어로 생성된 docker image를 확인할 수 있습니다.

이렇게 생성된 docker image를 활용해서 BentoML API serving이 가능합니다. docker run 명령어로 실행시켜주고 port만 열어주면 됩니다. 아래는 그 예시입니다.
docker run -p 5000:5000 lsjsj92/titanic_bentoml
그러면 Python 환경에서 BentoML을 serving 했던 것과 똑같이 Machine Learning model serving API 서버가 실행되는 모습을 확인할 수 있습니다.

API 호출을 하면 그 결과도 똑같이 확인할 수 있습니다.
이번 포스팅에 있었던 Tensorflow 모델도 마찬가지로 docker image로 만들어서 docker를 활용해 model serving이 가능합니다.
docker build -t lsjsj92/titanic_bentoml_tf ./TitanicTFClassifier/20210726074854_702723
docker run -p 5000:5000 lsjsj92/titanic_bentoml_tf
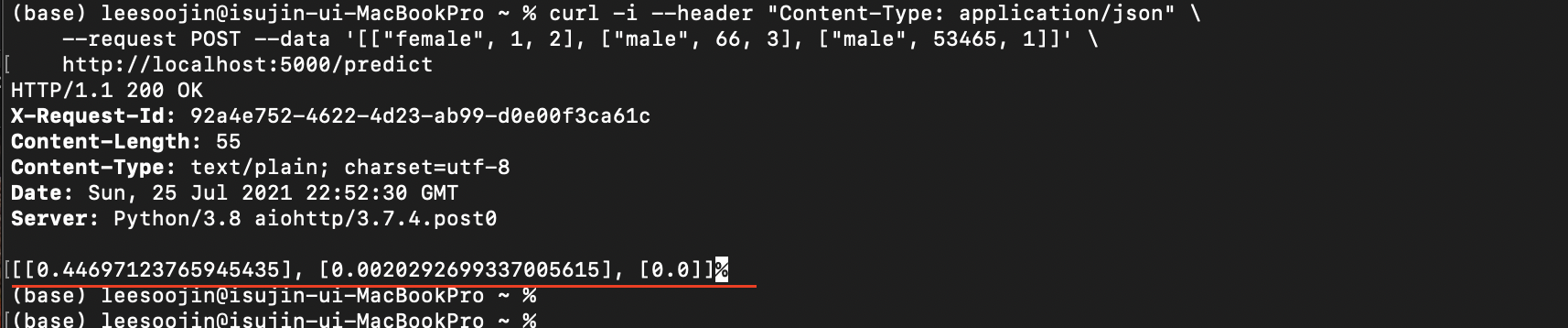
이렇게 docker를 활용하면 간단하게 API로 머신러닝 모델을 serving 할 수 있습니다.
3. BentoML multi predict 만들기
지난 예제들에서는 BentoML classifier에서 하나의 머신러닝 혹은 딥러닝 모델을 가지고 predict하였습니다. 하지만 상황에 따라서는 여러개의 모델을 predict 할 필요가 있습니다. 이번 예시는 이러한 상황에서 BentoML classifier를 어떻게 구성하면 되는지 간단하게 예제를 작성합니다.
classifier.py
사용 방법은 간단합니다. 하나의 classifier안에 2개의 predict 함수를 만들어주면 됩니다. 단, 함수의 이름이 둘다 동일하게 predict이면 두 모델이 같은 url ( 127.0.0.1/predict )를 보게 되는 엉뚱한 상황이 발생합니다. 따라서 함수의 이름을 다르게 구성해줍니다. 아래 예시와 같이 classifier.py의 predict 부분을 구성해주면 됩니다.
@env(infer_pip_packages=True)
@artifacts([PickleArtifact('rf_model'), PickleArtifact('lgbm_model'), PickleArtifact('mapping')])
class TitanicSKlearnClassifier(BentoService):
def mapping_df(self, df):
df['Gender'] = df['Gender'].map(self.artifacts.mapping)
return df
@api(input=DataframeInput(), batch=True)
def rf_predict(self, df: pd.DataFrame):
df.columns = EnvConfig().get_column_list()
df = self.mapping_df(df)
return self.artifacts.rf_model.predict(df)
@api(input=DataframeInput(), batch=True)
def lgbm_predict(self, df: pd.DataFrame):
df.columns = EnvConfig().get_column_list()
df = self.mapping_df(df)
return self.artifacts.lgbm_model.predict(df)@api 데코레이터로 해당 함수가 api라는 것을 명시해주되 함수 이름을 다르게 해서 경로를 다르게 받도록 합니다. random forest모델은 rf_predict로 받아오도록 하였으며 lightgbm model은 lgbm_predict로 받아오도록 하였습니다.
그리고 해당 모델을 packing하기 위해서 아래와 같이 2개의 machine learning 모델을 전부 packing 해줍니다.
classifier_service = TitanicSKlearnClassifier()
classifier_service.pack('rf_model', model1)
classifier_service.pack('lgbm_model', model2)
saved_path = classifier_service.save()model1은 머신러닝 랜덤 포레스트 모델이며 model2는 lightgbm 모델입니다. 각각의 모델을 packing 해주고 이를 저장합니다. 해당 코드를 실행하고 bentoml serve classifier:latest를 하면 아래와 같은 결과를 확인할 수 있습니다.

기존 BentoML serving swagger web ui 화면에서는 app에 /predict 하나만 존재하였었습니다. 하지만 이번 코드는 random forest용 predict 하나와 lightgbm용 predict를 나누어서 구성하였기 때문에 /lgbm_predict와 /rf_predict 2개로 구성되어 있음을 확인할 수 있습니다.
따라서 해당 머신러닝 모델을 API 호출 할 때도 아래와 같이 각각 다르게 호출해야 합니다.
curl -i --header "Content-Type: application/json" \
--request POST --data '[["female", 1, 2], ["male", 66, 3], ["male", 53465, 1]]' \
http://localhost:5000/rf_predict
curl -i --header "Content-Type: application/json" \
--request POST --data '[["female", 1, 2], ["male", 66, 3], ["male", 53465, 1]]' \
http://localhost:5000/lgbm_predict
그러면 위와 같이 각각 모델에 따라서 결과가 도출되는 것을 확인할 수 있습니다.
4. 원본 데이터를 input으로 받고 모델 training 형태로 치환(mapping)하기
이번 예제는 단순한 예제입니다. 바로 API 호출 시 넘어온 데이터를 머신러닝 혹은 딥러닝의 input으로 넣을 때와 동일하게 mapping 한 후 predict를 해주는 예제입니다. 예를 들어서 titanic 예제의 경우 아래와 같은 과정으로 진행하게 됩니다.
- 원본 데이터 load
- 데이터를 전처리 및 mapping
- mapping 과정은 예를 들어 성별 값인 male은 0, female은 1로 변환해주는 작업
- 위 데이터를 머신러닝 혹은 딥러닝 model input으로 넣어주고 model training
즉, 성별이 female, male로 되어 있는데 머신러닝 모델에 넣을 때는 0과 1로 mapping 한 후 데이터를 넣어줍니다. 여기서 API 호출을 할 때 문제가 하나 발생합니다.
machine learning model API를 호출할 때 단순히 [0, 1]와 같이 값을 넣어줄 수도 있지만 호출하는 입장에서는 저 0, 1이 무슨 값인지 알 수가 없습니다. 따라서 clinet 측에서는 아래와 같이 데이터를 호출할 수 있을겁니다.
- [["female", 'B', 2], ["male", 'A', 3], ["male", 'C', 1]]
아무래도 clinet 측에서는 위와 같은 호출이 더 편하겠죠? 따라서 해당 데이터가 model input으로 들어갈 수 있도록 우리는 mapping 과정을 진행해줘야 합니다. bentoml에서 이러한 작업을 진행하기 위해선 아래와 같이 mapping 데이터를 함께 packing 해주면 됩니다.
Config.py
config.py라는 파일 안에 성별의 mapping 값을 미리 설정해둡니다. 이 값은 male은 0, female은 1로 각각 값이 대입되어 있으며 이는 pandas dataframe에서 map 함수를 적용해 titanic 데이터의 성별 값을 치환할 수 있게 도와줍니다.
def get_gender_mapping_code(self):
gender_mapping_info = {
'male' : 0,
'female' : 1,
}
return gender_mapping_info
bentoml_process.py
이제 bentoml packing 작업을 진행해주는데요. 기존에는 model만 packing 해줬다면 이번 packing에서는 위에서 받아오는 gender_mapping 값도 패킹을 해줍니다. 여기서 패킹된 값을 사용하기 위해 classifier에서 aritfacts로 가져와야 합니다.
classifier_service = TitanicSKlearnClassifier()
classifier_service.pack('mapping', EnvConfig().get_gender_mapping_code())
classifier_service.pack('rf_model', model)
classifier.py
BentoML service를 구축하는 classifier에서는 mapping 값을 artifact로 가져와줍니다. 기존에는 모델을 KerasArtifact나 sklearn artifact 등으로 감싸주기만 했습니다. 그러나 이번 예제에서는 모델의 artifact와 더불어 앞서 설정한 mapping 값을 pickleartifact로 가져와줍니다.
이후 API가 predict로 요청 되었을 때 해당 데이터가 dataframe으로 받아져서 올 것입니다. 이렇게 받아와진 pandas dataframe에서 map 함수를 이용해 model input으로 넣을 수 있는 형태로 mapping 해줍니다. 최종적으로 해당 값을 return 해준 뒤 model predict를 해주면 호출한 clinet쪽으로 올바른 예측 결과 값이 response 됩니다.
@env(infer_pip_packages=True)
@artifacts([PickleArtifact('rf_model'), PickleArtifact('mapping')])
class TitanicSKlearnClassifier(BentoService):
def mapping_df(self, df):
df['Gender'] = df['Gender'].map(self.artifacts.mapping)
return df
@api(input=DataframeInput(), batch=True)
def predict(self, df: pd.DataFrame):
df = self.mapping_df(df)
print(df.head())
return self.artifacts.rf_model.predict(df)
실제 API 호출 결과를 확인하면 아래 사진과 같습니다.


위 사진에서 보시다시피 female, male 값으로 API 호출이 일어났습니다. 그리고 처음 이 API 호출을 받은 pandas dataframe에서는 성별에 female, male 값이 있는 것을 확인할 수 있습니다. 그러나, mapping 작업을 거친 뒤 1, 0, 0으로 바뀐 것을 확인할 수 있고 이제 이 값이 머신러닝 모델 predict로 들어가 예측 결과값을 뽑아내 return 해주게 됩니다.
마무리
이번 포스팅은 파이썬에서 머신러닝 모델을 API 형식으로 제공해주는 BentoML 예제 2탄을 작성해보았습니다. 어떤 화려한 테크닉을 소개한 것은 아니지만, 간단하게 사용할 수 있는 것들을 정리해보았습니다. 특히 machine learning model API를 docker로 만드는 형태는 참 유용한 것 같습니다.
부족한 글이지만 도움이 되시면 좋겠습니다. 감사합니다.
'Data Engineering 및 Infra' 카테고리의 다른 글
| Python MLflow example 정리 - machine learning lifecycle 관리 (2) | 2021.10.11 |
|---|---|
| Ubuntu20.04 텐서플로(tensorflow) GPU 설치 및 설정(setting) 방법 - AWS EC2 GPU 인스턴스 (0) | 2021.09.27 |
| MLflow란? 머신러닝 라이프 사이클을 관리하는 mlflow 사용법 및 예제 (8) | 2021.08.16 |
| BentoML이란? 사용법과 example 정리 - 머신러닝(machine learning) 모델을 API로 serving하기 (0) | 2021.08.02 |
| Metabase 사용법 - dashboard(대시보드) 구축하기 (feat. Metabase collection) (2) | 2021.02.24 |



