
포스팅 개요
이번 포스팅은 파이썬(Python) MLflow 예제(example) 정리 두 번째 포스팅이며 지난 번 MLflow 첫 번째 글 이후로 작성하는 두 번째 MLflow 글입니다. MLflow는 머신러닝(machine learning) 혹은 딥러닝 (deep learning)과 같은 모델들의 라이프 사이클을 관리해주는 라이브러리인데요. 이번 MLflow 포스팅은 아래와 같은 내용을 다룹니다.
- MLflow Project 관리 및 재배포 & Package
- Mlflow 머신러닝 모델 API serving
- MLflow 실험 환경 설정 (experiment setting)
지난 번 mlflow 1탄 글은 아래와 같습니다.
이수진의 블로그
안녕하세요. 이수진이라고 합니다. 이 블로그는 AI(인공지능), Data Science(데이터 사이언스), Machine Learning, Deep Learning 등의 IT를 주제로 운영하고 있는 블로그입니다.
lsjsj92.tistory.com
제가 mlflow를 정리하면서 참고했던 자료는 아래와 같습니다.
Quickstart — MLflow 1.19.0 documentation
Downloading the Quickstart Download the quickstart code by cloning MLflow via git clone https://github.com/mlflow/mlflow, and cd into the examples subdirectory of the repository. We’ll use this working directory for running the quickstart. We avoid runni
mlflow.org
본 포스팅에서 사용한 mlflow 코드는 아래 제 github에 올려두었습니다.
GitHub - lsjsj92/python_mlflow_example: Python MLflow(management machine learning life-cycle) example & tutorial code
Python MLflow(management machine learning life-cycle) example & tutorial code - GitHub - lsjsj92/python_mlflow_example: Python MLflow(management machine learning life-cycle) example & tutor...
github.com
포스팅 본문
본 포스팅에서는 Python mlflow 예제로 바로 들어갑니다. 각 주제는 다음과 같습니다.
- MLflow project & Package
- Mlflow 머신러닝 model API serving
- MLflow Experiment 환경 셋팅
MLflow Project & Package
MLflow에서 Project & Package 기능은 만들어둔 머신러닝 모델을 reproduct하고 실행할 수 있도록 코드 패키지 형식으로 지원해주는 기능입니다. 즉, 지난 포스팅에서 봤던 MLflow tracking은 머신러닝 라이프 사이클 관리 중 machine learning model training 한 것을 logging 하고 관리하는 것이었다면 Package는 그렇게 만들수 있는 모델(혹은 만들어진 모델)을 재생산하고 배포할 수 있도록 지원해주는 것입니다.
Tracking 결과로 Artifact쪽을 보시면 conda.yaml이 존재하는 것을 확인할 수 있는데요. 이 파일도 함께 활용합니다.

먼저 저는 mlflow-env라는 디렉토리를 하나 생성하고 여기에서 MLflow project & package 작업을 진행하였습니다. 그리고 해당 디렉토리에 앞서 진행했던 파일을 전부 이동시켜 주겠습니다. 비록 이전 작업을 이동시켜주어지만, 새롭게 시작하는 mlflow project라고 생각하시면 되겠습니다.(즉, 새로운 환경이라고 생각하시면 됩니다.) 단, 여기에 아래 2개의 파일이 새로 추가됩니다.
- conda.yaml
- default가 conda에 dependency걸려있음
- 파일은 생성하되 conda를 사용하고 싶지 않으면 실행할 때 --no-conda를 넣어주면 됌
- MLproject
- MLflow를 실행시키는 파일과 해당 파일에 들어가는 각종 파라미터, 커맨드 명령어 등을 정의
- test와 같은 entry point 지정도 가능

MLproject 파일
MLproject에는 MLflow를 실행시키는 환경을 정의할 수 있습니다. 들어가는 내용은 아래와 같은 특징을 가지고 있습니다.
- entry_points
- MLflow project를 실행시키는 일종의 환경 요소
- parameters
- 해당 entry point의 MLflow project를 실행할 때 필요한 파라미터 요소들
- command
- 해당 entry point의 MLflow project를 실행시키는 커맨드 명령어
MLproject 파일 안에 내용은 아래와 같습니다.
name: mlflow-env
conda_env: conda.yaml
entry_points:
main:
parameters:
is_keras: {type: int, default: 0}
n_estimator: {type: int, default: 100}
command: "python main.py --is_keras={is_keras} --n_estimator={n_estimator}"
test:
parameters:
is_keras: {type: int, default: 0}
n_estimator: {type: int, default: 50}
command: "python main.py --is_keras={is_keras} --n_estimator={n_estimator}"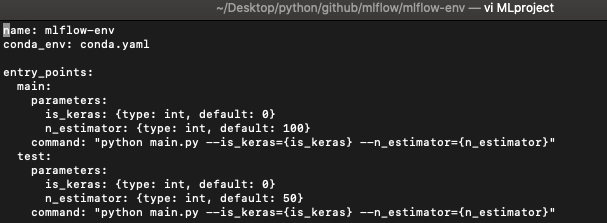
conda.yaml
다음은 conda.yaml 파일입니다. MLflow의 디폴트 설정의 디펜더시가 conda에 있기 때문에 해당 파일을 생성해둡니다. 하지만, conda를 실행시키지 않고 동작하고 싶으면 --no-conda를 명령어에 추가하시면 됩니다. 저는 conda를 사용해보도록 하겠습니다.
conda.yaml에는 dependecy에 pip 요소와 python 버전등을 명시해줍니다.
아래 예시는 mlflow tracking에 있던 conda.yaml 파일의 내용을 거의 그대로 가져온 예시입니다. 만약, 더 필요한 패키지가 있다면 여기에 추가해주시면 됩니다.
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
- tensorflow==2.3.0
name: mlflow-env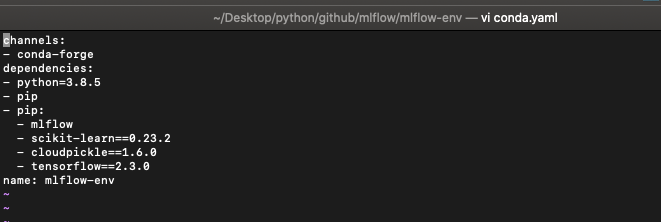
이제 이렇게 만들어진 파일들을 활용해 mlflow를 실행시켜주면 됩니다. 앞서 mlflow-env 디렉토리를 만들어서 해당 디렉토리를 새로운 mlflow project라 생각하고 진행한다고 언급했는데요. 이 mlflow-env 디렉토리를 mlflow run으로 실행시켜주면 MLproject 등을 참고해 mlflow를 실행시켜줍니다. 만약 conda를 활용하고 싶지 않다면 여기에 --no-conda를 추가해주시면 됩니다.
mlflow run mlflow-env
# conda 사용을 안 할 때
mlflow run mlflow-env --no-conda
또한, MLProject에서 entry point에 test 환경도 설정해 두었었는데요. 해당 entry point를 실행시키기 위해서는 -e 옵션을 추가해서 entry point를 명시해주시면 됩니다.
mlflow run mlflow-env -e test
그리고 mlflow ui에서 확인하시면 방금 실행시킨 env 요소들을 확인할 수 있습니다.

MLflow machine learning model API serving
MLflow의 가장 큰 특징 중 하나는 머신러닝 모델을 API 형태로 serving 할 수 있도록 지원해주는 것입니다. mlflow로 감싸진 파이썬 파일을 실행시키면 아래와 같이 mlruns 아래에 experiment id (여기서는 0이며, 설정할 수 있는 방법은 마지막 섹션에 소개) 값을 가진 숫자 디렉토리 아래에 mlflow를 실행시켰던 정보가 담긴 디렉토리가 생성된 것을 확인할 수 있을겁니다. mlflow는 mlruns라는 디렉토리 아래에서 이러한 mlflow experiment를 관리합니다.

이제 여기에서 실행한 하나의 experiment를 활용해서 머신러닝 모델을 API 서빙해보겠습니다. 간단한 파이썬 스크립트를 하나 만들어서 아래와 같이 작성할게요.
import mlflow
logged_model = 'runs:/33c2494d79e4482ea83811c244596e7f/ml_model'
# Load model as a PyFuncModel.
loaded_model = mlflow.pyfunc.load_model(logged_model)
# Predict on a Pandas DataFrame.
import pandas as pd
data = {
'Col1' : [1,0], 'Col2':[1, 2], 'Col3' : [1, 3]
}
print(loaded_model.predict(pd.DataFrame(data)))저는 타이타닉 데이터를 기준으로 했기 때문에 타이타닉 데이터에 맞는 input example을 구성했습니다. 그리고 logged_model에 mlflow 디렉토리를 하나 지정하고 mlflow에서 제공해주는 load_model을 이용해서 해당 machine learning model을 가지고 오도록 합니다.
이후 해당 머신러닝 모델의 predict를 이용해서 결과를 예측하도록 하고 그 값을 출력하도록 합니다. 이 python 파일을 실행시키면 아래와 같은 결과를 받을 수 있습니다.

이렇게 MLflow는 머신러닝 모델을 API 형태로 배포할 수 있는 기능을 제공해줍니다. 단순하게 이렇게 파이썬 스크립트를 작성해서 머신러닝이나 딥러닝 모델을 load해서 사용할 수도 있겠지만, mlflow의 serve 명령어로 바로 배포할 수도 있습니다. 아래와 같이 명령어를 입력하면 됩니다.
mlflow models serve -m ./mlruns/0/33c2494d79e4482ea83811c244596e7f/artifacts/ml_model -p 5001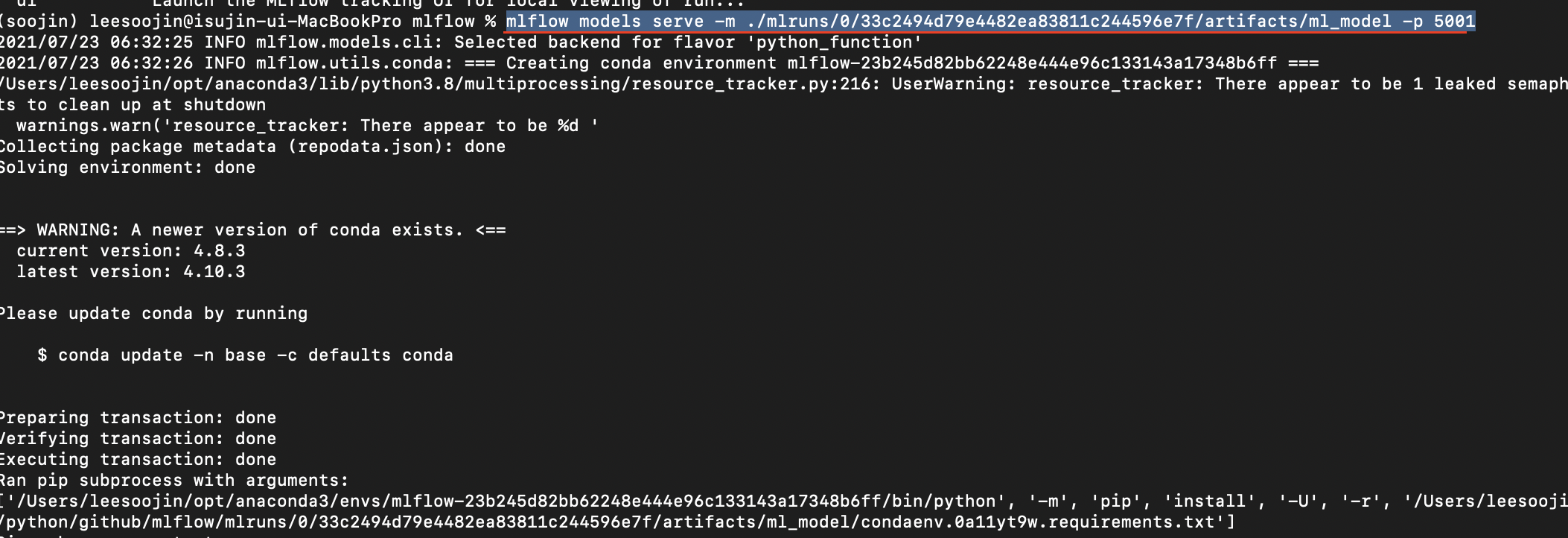
위와 같이 mlflow models serve 명령어를 이용하면 해당 mlruns에 있는 모델을 serving 합니다. 저는 5001번 포트를 -p 옵션으로 지정해주었습니다.
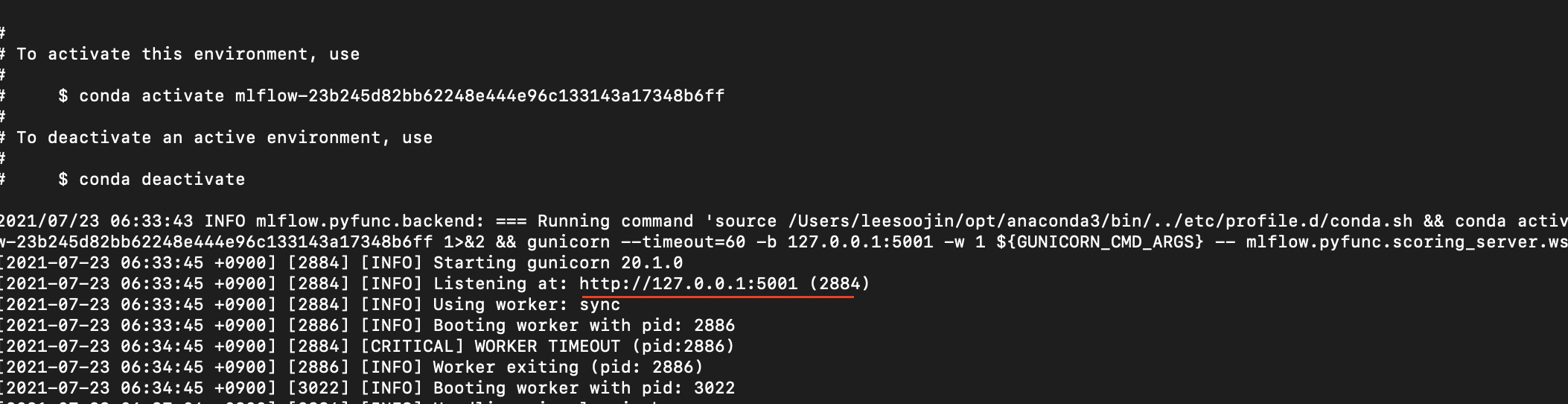
이렇게 실행하면 위 사진처럼 127.0.0.1:5001에서 실행되고 있다는 것을 확인할 수 있습니다. 이제 아래와 같이 POST request를 날려보면
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["A", "B", "C"],"data":[[1, 1, 2],[0,2,1]]}' http://127.0.0.1:5001/invocations
이렇게 API 호출 결과를 확인할 수 있습니다.
MLflow experiment 환경 setting
mlflow는 실험 환경(experiment env)에서 mlflow가 실행된 것들의 logging 및 history를 관리합니다. 이때 experiment id 값이 존재하는데요. mlruns를 보시면 처음에는 0으로 쓰여져 있는 디렉토리만 존재합니다. 이는 mlflow experiment id가 default로 0으로 지정되기 때문입니다.
그러나, 머신러닝 프로젝트를 진행하다보면 다양한 실험 환경이 필요할 수 있습니다. 프로젝트나 machine learning model에 따라 다양하게 나뉠 수 있겠죠. 이때 실험 환경을 셋팅할 필요가 있습니다.
mlflow의 기본 experiment는 default이며 id는 0으로 지정되어 있습니다. 새로운 mlflow experiment를 만들기 위해서는 mlflow.create_experiment를 활용하면 됩니다.

위처럼 mlflow 안에 있는 create_experiment를 활용해서 만들고 싶은 실험 이름을 지정해주면 됩니다. 위 파일을 실행시키면 mlruns에 아래와 같이 새로운 experiment_id에 따라 디렉토리가 생성된 것을 확인할 수 있습니다. 또한, 해당 디렉토리 안에는 meta.yaml 파일이 들어가 있는데요. meta.yaml 파일을 확인하면 방금 생성한 mlflow experiment에 대한 정보가 담겨져 있습니다.

또한, 생성된 mlflow experiment는 mlflow ui에서도 똑같이 확인할 수 있습니다.

그럼 mlflow를 실행할 때 생성한 experiment를 활용하고 싶다면 어떻게 할까요? mlflow에서 제공해주는 set_experiment 함수를 사용하면 됩니다. mlflow.set_experiment 함수안에 지정한 experiment name을 넣어주면 해당되는 experiment로 설정이 되고 mlflow를 동작시켜줍니다. 그러면 이렇게 설정되어져 있는 코드를 실행하면 이제 지정한 experiment에 logging이 쌓이게 됩니다.

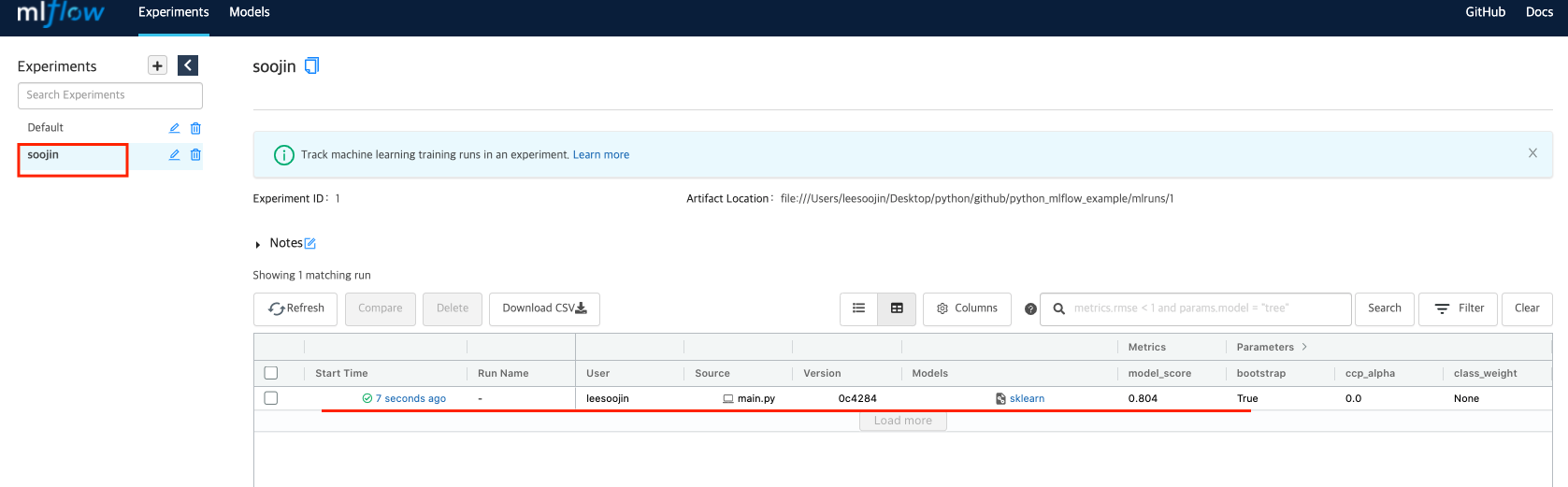
이렇게 지정된 실험 환경 안에 데이터가 쌓이는 것을 확인할 수 있습니다.
마무리
이번 포스팅은 머신러닝 라이프 사이클을 관리해주는 파이썬 mlflow 라이브러리에 대해서 알아보았습니다.
python mlflow는 잘만 활용한다면 machine learning 프로젝트 및 모델 관리에서 굉장히 유용한 라이브러리입니다.
부디 도움 되셨기를 바랍니다.
감사합니다.
'Data Engineering 및 Infra' 카테고리의 다른 글
| Apache 에어플로우(Airflow) - DAG branch(분기) 예제(example) 및 Python operator, XCom에 대해서 (0) | 2022.02.21 |
|---|---|
| Apache 에어플로우(Airflow) 시작하기 - Airflow란?, Airflow 설치 및 기본 예제 (16) | 2022.02.06 |
| Ubuntu20.04 텐서플로(tensorflow) GPU 설치 및 설정(setting) 방법 - AWS EC2 GPU 인스턴스 (0) | 2021.09.27 |
| BentoML 예제 정리 - 딥러닝(tensorflow) 모델 적용, docker image 생성, 다중 predict (2) | 2021.09.13 |
| MLflow란? 머신러닝 라이프 사이클을 관리하는 mlflow 사용법 및 예제 (8) | 2021.08.16 |



