
포스팅 개요
이번 포스팅은 추천 시스템(recommender system, recsys) 논문 중 FDSA : Feature-level Deeper Self-Attention Network for Sequential Recommendation 이라는 논문을 리뷰라는 포스팅입니다. FDSA는 추천 시스템 방법 중 sequential recommendation 방법을 소개하며 explicit과 implicit feature-level sequence는 full sequential pattern을 추출하는데 도움을 줄 수 있다고 주장하는 논문입니다. 본 포스팅은 해당 논문의 자세한 리뷰를 정리하는 포스팅입니다.
또한, 본 포스팅은 제가 작성하고 있는 추천 시스템 시리즈 글 입니다. 추천 시스템 시리즈 논문 리뷰는 아래와 같은 순서로 진행할 예정입니다. 오늘은 그 네 번째 포스팅입니다.
- DeepFM (https://lsjsj92.tistory.com/636)
- MAML (https://lsjsj92.tistory.com/637)
- VECF (https://lsjsj92.tistory.com/638)
- FDSA
- PMN (https://lsjsj92.tistory.com/640)
- GAU (https://lsjsj92.tistory.com/641)
- A3NCF(https://lsjsj92.tistory.com/642)
- MIAN (https://lsjsj92.tistory.com/643)
- CCANN (https://lsjsj92.tistory.com/644)
본 포스팅에서 참고한 자료는 다음과 같습니다.
포스팅 본문

추천 시스템 논문 FDSA : Feature-level Deeper Self-Attention Network for Sequential Recommendation 논문 리뷰는 다음과 같은 순서로 진행합니다~
1. FDSA 핵심 요약
2. FDSA 논문 리뷰
FDSA 핵심 요약
For sequential recommendation 추천 시스템 모델
• 기존의 방법은 item feature와의 패턴을 무시함
• Explicit과 implicit feature-level sequence는 full sequential pattern을 추출하는데 도움을 줄 수 있음
• 따라서, Feature-level Deeper Self-Attention Network(FDSA)를 제안함
FDSA
• Heterogeneous feature of items를 feature sequence로 통합시킴
• 이때 vanilla attention mechanism을 활용해서 서로 다른 weight를 부여
• Vanilla attention을 feature 쪽에 도입해서 assist feature-based self attention
• Self-Attention block을 두 군데에서 활용
• Item-level sequence
• Feature-level sequence
• 이를 통해 item-item 그리고 feature-feature간의 관계를 capture함
• 최종적으로 위 2개의 level을 fully-connected로 합침
이제 해당 논문의 상세한 리뷰를 진행해보겠습니다.
FDSA 논문 리뷰
Introduction
Sequential recommendation은 다양한 application에서 필수적인 요소가 됨
Ad click prediction, purchase recommendation, web page recommendation Sequential 한 추천 시스템은 application 영역에서 많이 활용되고 있습니다. 이는 사용자의 이전 활동의 발생 순서대로의 영향을 받아서 모델링합니다. Sequential recommendation의 목표는 사용자의 과거 행동에서 useful sequential patterns를 캡처해서 Next item 추천하는 것입니다.
Sequential recommendation에서 다양한 모델이 연구되고 제안 됨
기존에는 Markov Chain 기반 FPMC를 활용하기도 했습니다. 하지만, Factor들 사이의 effective relationship을 구성하기 쉽지 않다는 것이 이슈가 있씁니다. 최근들어서 Deep Learning의 성공으로 RNN기반 추천 시스템을 제공하고 연구가 되고 있습니다. RNN 기반 방법은 Last hidden state of RNN으로 user representation을 사용하고 next action을 예측합니다. 그러나, long-range dependencies를 보존하는 것이 어렵다는 단점이 있으며 이는 LSTM, GRU를 사용해도 마찬가지입니다. 또한, Step by step으로 접근하기 때문에 병렬화도 어렵다는 단점이 있습니다.
최근에는 Self-attention이 좋은 성능을 보여주고 있습니다. 이 방법은 Long-range dependencies를 캡처하는 강도를 each pair of items에서의 attention weights를 계산해 활용합니다. SASRec는 Self-Attention을 활용한 Sequential Recommendation model이며 좋은 성능을 보여줍니다. 그러나, only considers the sequential patterns between items하며 즉, 사용자의 fine-grained preferences를 캡처하기 위한 feature 사이의 sequential pattern은 무시합니다.
Item feature level
item feature는 일상 생활과 관련이 있습니다 ( 카테고리 등 ). 여기서 Explicit하고 implicit로 나뉠 수 있는데요. Explicit feature transition는 사용자의 structured attributes(예. Category)가 발전(변화)하는 것입니다. Implicit feature transition의미에 대해선 Item에는 some other unstructured attributes가 있습니다. Text, image 등 item을 더 디테일 하게 보여주는 것이죠. 따라서 사용자의 potential feature level patterns을 이러한 unstructured attributes를 활용해 마이닝 하고자 합니다. 그러나, 위 2개의 feature transition은 이전 연구에서 종종 간과 되어졌다는 것이 본 논문에서 이야기하는 바입니다.
Implicit and explicit feature transition
Only item-level sequences는 full sequential patterns를 반영할 수 없다고 본 저자들은 주장합니다. 반면, feature-level sequences는 이러한 목표를 달성하는데 도움을 줄 수 있을 거라고 이야기 합니다. For capturing explicit feature level transition patterns을 위해서 Combined representation of item and its feature하는 것 대신에 separated self-attention blocks를 활용합니다. Item sequences와 feature sequences에 활용하여 item-item, feature-feature 간의 관계를 캡처하고자 하는 것이죠. 이후 item level과 feature level을 combine해서 추천에 활용하고자 합니다. 이때 Vanilla attention을 활용하는데요. How to capture meaningful implicit feature-level transition patterns from heterogeneous attributes of item의 고민을 하면서 이를 위해 vanilla attention을 활용해서 feature-based self-attention을 assist했다고 합니다. Item 속성의 다양한 type으로부터 필수 feature를 adaptively하게 선택하게 하며 더 나아가 potential implicit feature transition patterns을 학습합니다.
Related Work
본 논문에서 이야기하는 관련 연구들입니다. 본 포스팅에서는 간단히 언급하고 넘어가겠습니다. 자세한 것은 논문을 참고해주세요!
Sequential recommendation
• Markov Chain based method
• FPMC
• RNN
• GRU4Rec
Attention mechanism
• ATRank
• CSAN
Feature-level Deeper Self Attention Network for Sequential Recommendation
이제 FDSA : Feature-level Deeper Self-Attention Network for Sequential Recommendation 논문에서 제안하는 추천 시스템 모델에 대해서 자세히 설명합니다.
Problem Statement
본 논문에서 이야기 할 때 여러가지 정의들을 정리합니다.

The Network Architecture of Feature-level Deeper Self-Attention (FDSA)
FDSA는 Item-based self-attention block을 활용해 item-level sequence pattern을 학습합니다. Feature-based self-attention block을 활용해 feature-level transition pattern을 찾는 것이죠. 여기에는 5개의 component가 있습니다.
해당 제안하는 모델은 5개의 component가 있으며 이는 다음과 같습니다.
• Embedding, Vanilla Attention
• Item-based self-attention block, Feature-based self-attention block
• Fully-connected layer
모델의 input 등으로 활용하기 위해서 vector로 변환합니다. Sparse representation of item을 low-dim dense vector로 변환하는 등의 작업인 것이죠. Text는 topic model을 활용해 topical keywords를 뽑아낸 후 word2vector로 vector를 추출합니다. 또한, Heterogeneous하고 different data type이 있기 마련인데요. Vanilla attention을 활용해 self-attention network를 assist합니다.
논문에서 소개하는 모델은 2개의 self-attention block이 있습니다.
• Item-based self attention : learn item level sequence patterns
• Feature-based self attention : feature level transition patterns을 캡처
마지막에는 Fully connected layer로 integrate한 후 final prediction합니다.
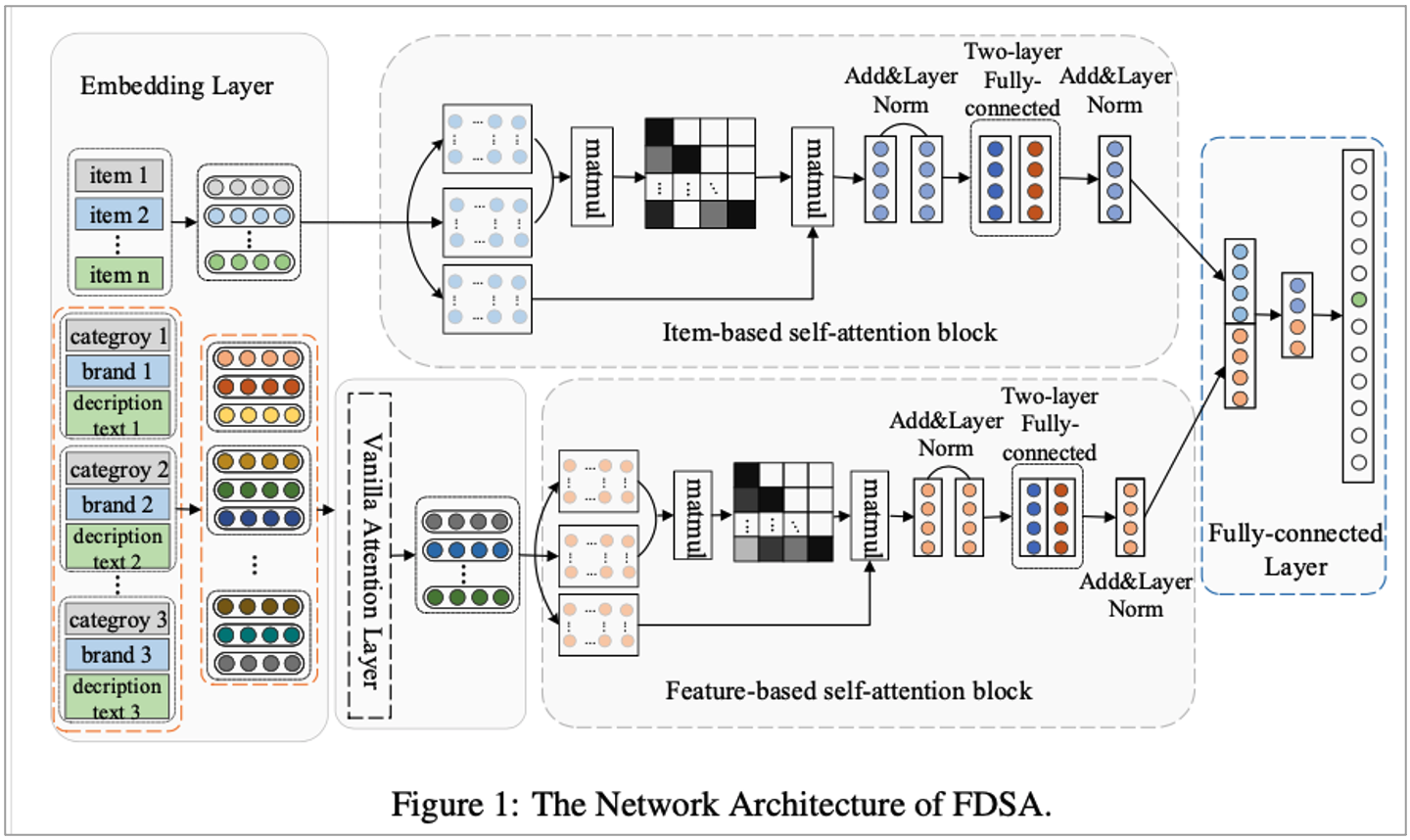
이제 논문에서 소개한 5개 layer에 대해서 자세히 소개합니다.
1. Embedding layer
사용자의 과거 선호도를 계산하기 위해 user history sequence로부터 fixed-length sequence를 가져옵니다. 이때 S = (s1, s2, … sn)형태이며 N보다 적으면 zero-padding, 크면 recent n만 잘라서 활용합니다. Feature sequence도 같은 방법으로 가져옵니다. Category로 예시를 들면 다음과 같으며 category sequence를 dense vector로 변환합니다.
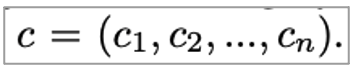
Text는 topic model을 활용해 topical keywords를 뽑아낸 후 word2vector로 vector를 추출한다고 논문에서는 이야기하고 있습니다.
2. Vanilla attention layer
vanilla attention layer에서는 어떤 feature가 사용자의 선택에 기여하는가?의 관점으로 바라봅니다. 즉, item 특성 (category, brand 등)에서 사용자의 다양한 선호를 캡처하기 위함입니다. Item i가 주어졌을 때 각 attribute는 다음과 같이 embedding 됩니다.
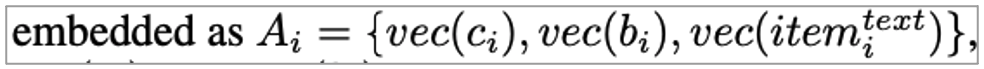
• Vec(ci) : dense representation of category of i
• Vec(bi) : dense representation of brand of i
• Vec(item_text) : textual feature representation
Attention network는 아래와 같습니다.

3. Feature based self attention block
해당 block에서는 Vanilla attention layer에서 나온 것을 활용합니다.

이때 Sequence정보 이므로 position 값을 넣어 주는 형태를 가지고 있습니다.

본 논문에서 SDPA라고 줄여서 이야기하는 Scaled dot-product attention(SDPA)는 Query, key, value에 맞는 linear transformation을 하고 SDPA에 넣어줍니다.
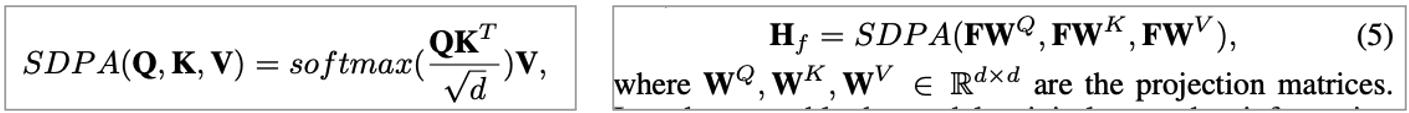
또한, Multi head attention은 다음과 같습니다.

이후 step은 layer norm과 2개의 fully connected layer를 거치게 됩니다.

간단하게 정리하자면! 다음과 같습니다.

4. Item based self attention block
해당 블록에서는 Item level transition patterns을 학습하는 것이 목표입니다. Item action sequence가 주어졌을 때 아래와 같은 식으로 표현될 수 있습니다.
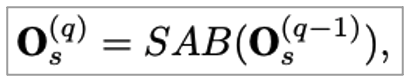
5. Fully connected layer
해당 layer에서는 Concatenate the output of item based self attention and output of feature based self attention합니다. 이후 Dot product를 이용해 calculate user preference for items합니다.

해당 식에서 Y는 이전 t시점까지의 item에 대한 next item(i)과의 relevance라고 보면 됩니다.
Loss function은 Binary cross entropy를 사용합니다.
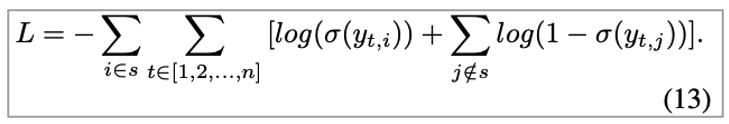
Experiments
본 논문의 실험 환경입니다. 가장 먼저 데이터 셋에 대해서 소개하고 이후 평가 방법과 baseline을 소개합니다.
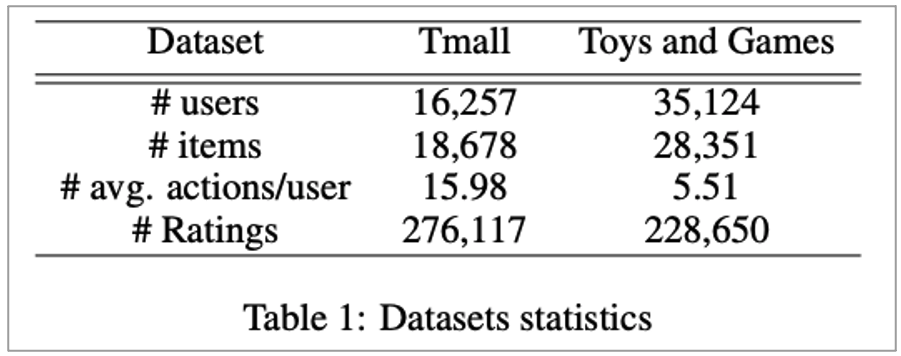
Dataset
• Toys and Games
• Amazon dataset
• Rate 횟수가 5번 미만인 사용자 제거
• 사용자에 의해 10번 미만으로 평가된 아이템 제거
• Tmall
• B2C platform in China
• 관찰 횟수가 30번 미만인 사용자 제거
• 사용자에 의해 15번 미만으로 평가된 아이템 제거
Evaluation metric and Implementation Detail
• Hit ratio @ K
• NDCG @ K
• K = {5, 10}
• Maximum sequence length : 50
• Embedding size : 100
• Batch size : 10
Baseline Methods
| Baseline 모델 | 특징 |
| PopRec |
-Popularity base
|
| BPR |
-Pair-wise
|
| FPMC |
-Markov chain base
|
| TransRec |
-Relational vector acting as the junction between user and items
|
| GRU4Rec |
-GRU for session based recommendation
|
| CSAN |
-Multi-type actions and multi-modal contents based on self attention network
|
| SASRec |
-Self attention based sequential model
|
| SASRec+ |
-SASRec + concatenates item vector and category vector
|
| SASRec++ |
-SASRec + item representations and various heterogeneous feature of items
|
| CFSA |
-Simplified version of our proposed method
-Only considers a category feature
|
Performance Comparison
실험 결과에 따른 성능 비교입니다.
BPR and GRU4Rec vs PopRec의 결과로는 BPR, GRU4Rec이 이겼습니다. 이를 통해 개인화 추천의 효과를 보여줬다고 합니다.
또한, FPMC 등의 sequential model이 non-sequential 보다 좋은 성능을 보여줬습니다. 이는 Next item 추천에서 Importance of considering sequential information한 것이라고 합니다. SASRec의 성능은 FPMC, TransRec보다 좋았습니다. 그 이유는 Advantages of using a self attention mechanism라고 언급합니다.

SASRec+와 SASRec++는 SASRec보다 toy and games에선 좋고 tmall에선 안 좋은 결과가 나왔습니다. 이는 Concatenating items representations and items feature representations하는 것은 안정적인 모델링이 안될 수도 있다는 것을 암시한다고 하네요.
즉, 위 concate한 것을 self attention input vector로 넣는 것이 안정적이지 않을 수 있다는 것입니다.
또한, CFSA는 SASRec+보다 좋고, FDSA는 SASRec++보다 좋은 결과가 나왔습니다. 이를 통해 Separated self attention blocks on item level and feature level하고 이를 self attention input으로 넣는 것의 효과를 보여줬다고 합니다. 즉, Item transition patterns와 feature transition patterns을 캡처 하는데의 효과가 나왔다고 합니다.
그리고 역시 제안한 추천 시스템 모델인 FDSA가 가장 좋은 성능을 보여줬다고 합니다.
Influence of Hyper-parameters
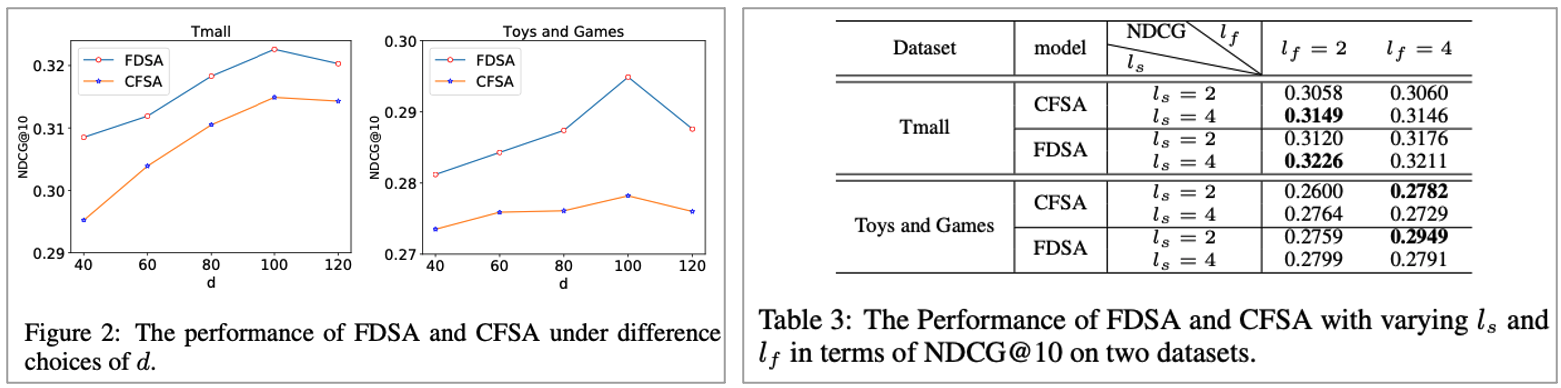
하이퍼 파라미터에 따른 영향도를 분석한 부분입니다. 먼저 Embedding size에서는 100까지는 성능이 올라가다가 이후에 떨어졌다고 하며 이는 overfitting이라고 합니다. 다음으로는 Number of head인데요. head 개수에 대한 성능은 다음과 같이 정리될 수 있습니다.
• Tmall : l_s : 4, l_f : 2가 베스트
• Toys and Game : l_s : 2, l_f : 4가 베스트
그 이유는 Tmall은 single data type이라서 복잡한 구조가 필요하지 않은 것으로 보여진다고 하며 Toys and Game dataset은 text, title 등이 있어서 더 많은 헤드가 필요했다고 합니다.
Conclusion
본 논문의 결론입니다. 본 논문에서는 추천 시스템 모델인 FDSA(Feature level Deeper Self Attention Network) 제안하였습니다. 본 논문에서 제안한 FDSA의 특징을 정리하자면 다음과 같습니다.
• Sequential recommendation을 위함
• Item based self attention block에서 Item, feature based self attention block에서 feature transition을 학습
• FDSA는 이 둘의 transition patterns을 모델링
• Output은 integrated into a fully connected layer for next item prediction
마무리
이번 포스팅은 FDSA : Feature-level Deeper Self-Attention Network for Sequential Recommendation 이라는 추천 시스템 논문을 리뷰하였습니다.
공부하시는 분들에게 조금이나마 도움이 되시길 바라겠습니다.
감사합니다.



