
포스팅 개요
이번 포스팅은 추천 시스템(recommender system, recsys) 논문 중 MAML : User Diverse Preference Modeling by Multimodal Attentive Metric Learning 이라는 논문을 리뷰라는 포스팅입니다. MAML은 추천 시스템 방법중 metric learning을 활용하며 이와 더불어서 multimodal 정보를 attention을 활용해 사용하는 추천 시스템입니다. 본 포스팅은 해당 논문의 전반적인 내용을 리뷰해봅니다.
또한, 본 포스팅은 제가 작성하고 있는 추천 시스템 시리즈 글 입니다. 추천 시스템 시리즈 논문 리뷰는 아래와 같은 순서로 진행할 예정입니다. 오늘은 그 두 번째 포스팅입니다.
- DeepFM (https://lsjsj92.tistory.com/636)
- MAML
- VECF (https://lsjsj92.tistory.com/638)
- FDSA (https://lsjsj92.tistory.com/639)
- PMN (https://lsjsj92.tistory.com/640)
- GAU (https://lsjsj92.tistory.com/641)
- A3NCF(https://lsjsj92.tistory.com/642)
- MIAN (https://lsjsj92.tistory.com/643)
- CCANN (https://lsjsj92.tistory.com/644)
본 포스팅에서 참고한 자료는 다음과 같습니다.
포스팅 본문

추천 시스템 논문 User Diverse Preference Modeling by Multimodal Attentive Metric Learning (MAML) 논문의 리뷰는 다음과 같은 순서로 진행됩니다.
1. MAML 핵심 요약
2. MAML 논문 리뷰
MAML 핵심 요약
Considering user diverse preference for various items
• Various item에 있는 다양한 특성을 고려해 사용자의 다양한 선호도를 반영
• 이를 위해 attention neural network를 사용자의 multimodal feature 추정을 위해 사용
• 사용자의 item에 대한 다양한 aspect에서 specific attention을 estimate하기 위하여
추가적인 feature를 반영
• Side information에는 user preferences가 있음
• Feature level에서 fine-grained user preference를 반영하기 위함
Metric-based learning을 활용
• MF 기반의 모델은 fine-grained user preference를 캡처할 수 없음
• Dot product similarity를 활용한 기존 연구와 다르게 접근
• Dot product는 not satisfy the triangle inequality하기 때문
• Can capture fine-grained user preference 하는데 도움을 줌
MAML 논문 리뷰
User Diverse Preference Modeling by Multimodal Attentive Metric Learning (MAML) 논문에 대한 리뷰를 본격적으로 진행합니다. 해당 리뷰는 논문에 나와있는 순서대로 진행합니다.
Introduction
추천 시스템 기술의 중요성 증가
Online platform(Amazon), streaming service(Youtube), social platform(Pinterest) 등에서 추천 시스템 기술의 중요성이 증가되고 있다고 합니다. 초기에는 MF와 같은 기술 발전이 이루어졌고 이 기술은 User-item interaction을 latent feature space에 mapping합니다. 즉, 각 사용자와 item을 feature vector로 표현하는 것이죠.
User와 item의 preference
사용자와 아이템의 선호도는 Dot product of the feature vector로 예측 되었었습니다. 아래 사진과 같이 말이죠.
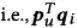
BPR 등도 결국 이런 아이디어입니다. 최근에는 Deep Neural network의 발전으로 크게 진전이 되었습니다. 그 예시로 NCF 같은 모델이 있습니다.
MF는 simple and effective한 아이디어로 큰 기여를 함
그렇다고 MF자체가 무조건적인 안 좋다고 말할 수 없습니다. simple하면서도 effective하니까요. 하지만, relying on the interaction information하다는 것은 단점입니다. 이는 Feature-level 또는 aspect-level에서 Fine-grained user preference를 캡처하지 못하게 됩니다. 즉, User와 item이 불충분할 경우 성능 저하가 일어나게 됩니다.
Side information
MF 등에서 나오는 위 문제를 완화하기 위한 다양한 연구가 진행되어 왔습니다. 그 중 하나가 side information입니다. Side information은 사용자의 아이템에 대한 선호도를 반영하고 있습니다. Image는 visual preference를 그리고 Review는 사용자의 아이템에 대한 다양한 측면에서 의견이 들어가 있습니다.
그러나, 기존 연구들은 사용자의 다른 아이템에 대한 다양한 선호도를 특징 짓는 것을 잘 고려하지 않다고 본 논문에선 주장하고 있습니다. 사용자는 다른 아이템에 대해서 동일한 관점으로 접근하지 않습니다. 그러나 기존 추천 방법은 use same vector to represent a user’s preference for all items이었습니다. 이는 사양한 아이템에 대한 다양한 선호도를 정확히 예측할 수 없게 되는 것입니다. 이것을 해결하려는 연구 ANCF, MARS 등이 있었으나 이 연구들은 dot product based MF에 의존적이었습니다.
Dot product based MF에 의존적
결국 본질적인 problem이 dot product에도 있습니다. Metric-based distance learning이 아니므로 not satisfy the triangle inequality하다는 단점도 있구요. 이러한 문제는 표현성을 제한하고 fine-grained user preference를 캡처하지 못하게 합니다.
CML(metric collaborative filtering)은 이런 문제를 해결하고자 한 연구입니다. 그러나, 이것도 문제가 있습니다. 그 문제들은 아래와 같습니다.
• geometric inflexible for large dataset
• Try to fit a user and all the interaction items into same point
Dot product의 문제점을 해결하기 위해 metric-based learning이 나왔지만 Not well modeled user diverse preference for various items하였습니다.
그래서 우리는! MAML 모델 제안
따라서 본 논문에서 제안하는 추천 시스템 모델은 Item의 Multimodal information을 활용하여 사용자의 다양한 선호도를 반영합니다. 이 선호도 반영을 위해 User attention을 표현하는 Weight vector를 활용합니다 ( attention neural network 활용 ). 이때 Attention vector는 user, item vector와 결합하여 user와 item의 distance를 계산합니다.
본 논문에서 제안하는 모델은 아래와 같은 관점으로 가치가 있는 모델이라고 주장합니다.
• Metric based learning으로 dot product sim 문제를 피해 Satisfies inequality property 함
• Weight vector는 user와 item을 distinct space로 투영하는 transformation vector로 작용하기 때문
• User-item pair에서 weight vector는 unique하기 때문
• 유클리드 거리를 통한 근사한 계산을 수행
• 기하학적으로 유연하고 모델링 능력을 가지고 있음
Related work
본 논문에서 주장한 연구와 관련된 연구들입니다. 본 포스팅에서는 간단하게만 정리하고 넘어갑니다. 자세한 것은 논문을 참고해주세요!
Diverse Preference Modeling
• User와 item의 유사도를 추정하기 위해 Dot product를 사용하는 MF 기반 framework 사용
• 본 논문에서는 기존과 다르게 user diverse modeling을 위해 metric learning method를 사용
• Avoid limitation of dot product
Metric-based Learning
• 본 논문에서는 adaptive weight vector를 사용함
• Each user-item pair를 unique space에 두기 위해서
• 사용자의 다양한 선호도를 캡처할 수 있음
Multimodal User Preference Modeling
• Text review, item image, other metadata를 활용
• 본 논문에서는 2가지 관점으로 접근
• 기존에는 fixed user and item representation을 jointly하게 활용
• 본 논문에선 다양한 item aspects에 대해서 사용자의 다양한 attention을 배우기 위해 multimodal feature를 활용
• Metric learning 활용
Our proposed model
이제 본 논문에서 제안한 추천 시스템 모델을 살펴봅니다. 먼저, 본 논문에서 사용한 기호 notation을 정리합니다.

Background
본 논문에서는 background 지식으로 Matrix Factorization(MF)와 weighted regularized matrix factorzation(WRMF), Pairwise learning(BPR), Metric learning에 대해서 언급하고 있습니다.
자세한 설명은 본 논문에도 나와있지 않으며 간략하게만 언급되어져 있습니다.
1. MF

2. WRMF (MF의 확장버전으로 implicit feedback prediction 수행)
3. BPR(pairwise)
사용자와 아이템의 벡터가 있고 어떤 아이템을 더 선호하는지 학습하는 것

4. Metric based learning
dot product의 한계를 벗어나도록 학습하며 user와 item의 latent vector는 shared space에 위치함

Proposed model
따라서, 본 논문에서 제안한 모델은 아래와 같습니다.
Multimodal Attentive Metric Learning
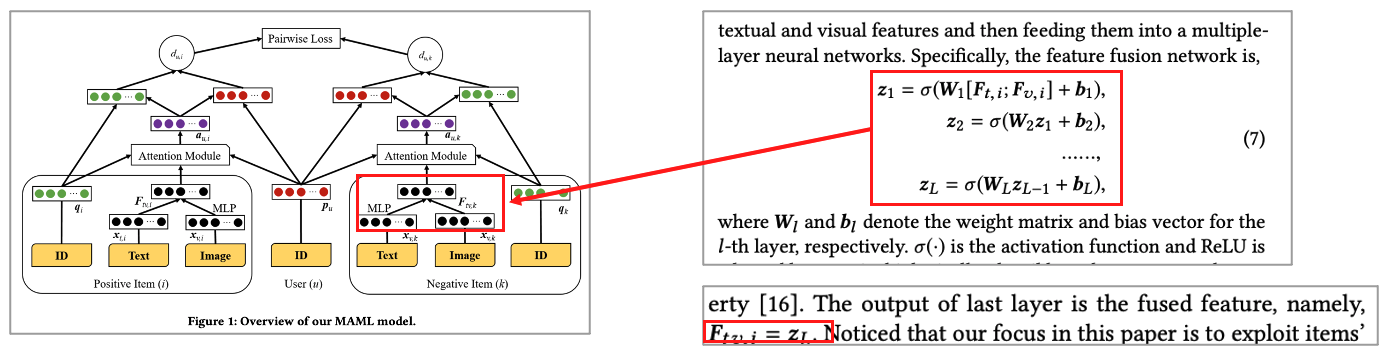
Real scenario에서 same user vector(p_u)는 모든 아이템의 사용자 선호도를 예측하는 것은 최적이 아닐 수 있다고 이야기하고 있습니다. 왜냐하면 Preference of a user on the aspects of different items is varying 이기 때문입니다. 사용자 u가 item i에 대한 선호도를 예측할 때 사용자가 i에 대해 더 선호(attention)하는 부분이 item i에 대한 사용자 선호도를 지배해야 합니다.
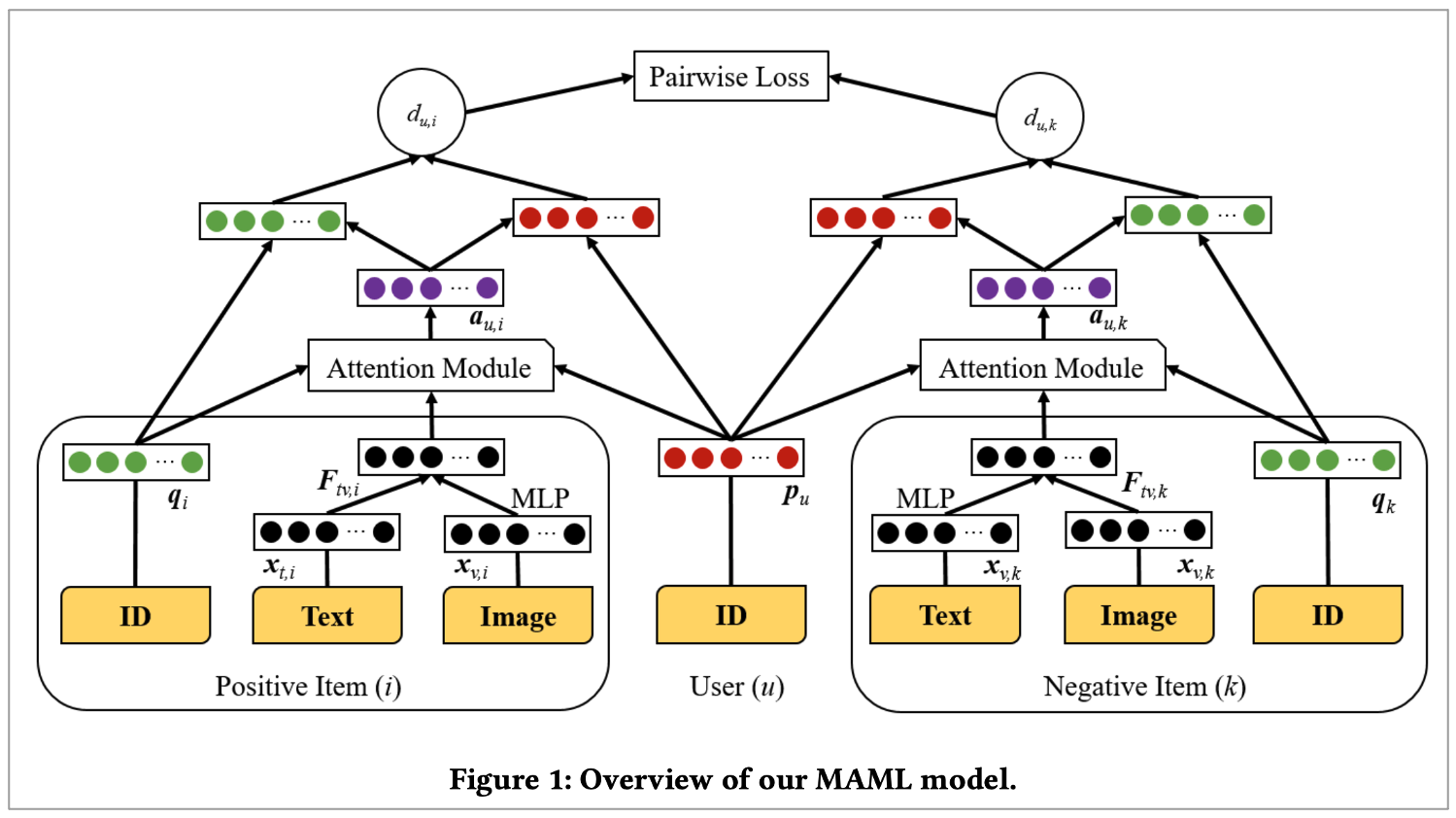
이에 본 논문에서는 Each user-item pair(u, i)에서 weight vector a_u,i \include R^f 를 활용하며 이는 사용자가 item i에 대한 중요성을 나타냅니다. 그리고 Weight vector를 추정하기 위해 Item의 Side information을 활용하고 Attention vector를 추정하기 위해 Attention mechanism 활용합니다. 본 모델에서 Attention(weight) vector를 활용해 u와 I 사이의 유클리디언 거리 측정은 다음과 같습니다.
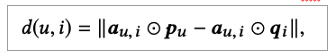
여기서 Attention vector는 사용자의 다양한 선호도를 정확하게 캡처할 뿐만 아니라 앞서 나온 기하학적 한계를 해결합니다. 선행 연구 격인 CML에서는 user and all the interacted item을 same point로 fit하는데요. 각 item은 interacted한 user가 많으므로 기하학적 문제가 발생하게 됩니다. 본 논문에서 제안한 추천 모델에서는 weight vector가 each user-item에 대해 unique합니다. 이때 사용자와 item의 거리 계산을 위한 new space으로 transform해주는 transformation vector로 적용 됩니다. 또한, Pairwise loss 활용하기도 하구요.
즉, 여기에서는 Attention Mechanism을 적극적으로 활용하는데요. 사용자의 item i에 대한 구체적인 attention을 캡처하기 위해 사용합니다. 이때 User와 item 그리고 textual feature image feature의 fusion을 concat하고 이를 어텐션으로 태워줍니다.
태워준 다음으로 a^_u,i를 softmax 함수를 사용해 normalize 해야 합니다. 단, 논문에서는 standard한 것이 잘 작동이 되지 않았다고 이야기 하고 있습니다. 본 논문의 모델에선 attention weight가 element-wise product with the Euclidean Distance에 directly use되기 때문이라고 주장하고 있습니다. 즉, Softmax를 거치면 weight의 값은 매우 작아지기 때문이죠. ( 예를 들어 d가 100이면 mean value weight가 0.01 ) 이렇게 되면 사용자 벡터와 아이템 벡터의 각 차원 사이의 거리는 이미 작은 상태에서 더 작아지게 되는 현상이 나오게 됩니다. 이는 모델의 distinguishing power를 약화시키고 성능 저하를 일으키게 되는 것이죠. 따라서, 본 논문에서는 이를 위해 다음과 같이 Normalized weight를 확대시키는 완화 방법을 사용합니다.

item feature에 해당되는 Attention Mechanism 설명도 있습니다. 여기서는 Text feature와 visual feature를 사용합니다. Text는 PV-DM 방법으로, image는 pre-trained model을 활용했다고 합니다. 이 2개를 widely used strategy 방법으로 통합해서 사용했다고 이야기 하고 있으며 그 방법은 다음과 같은 것이 있습니다.
1. concat feature
2. feeding them into a multiple layer neural network
그리고 본 논문에서는 Ranking loss weight를 사용합니다. 이는 Weighted Approximate rank pairse loss를 활용하는 것인데요. 낮은 rank에 더 큰 패널티를 부여하는 것입니다.
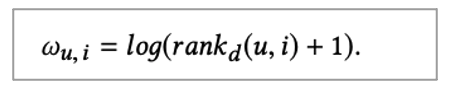
또한, Regularization으로 L2 loss function ( feature에서 추출된 특징에서 벗어나면 패널티 부여 )를 사용하며 Covariance regularization ( feature space에서 각 차원의 중복을 방지, 상관관계를 줄이기 위해서)도 활용했다고 합니다.
Optimization은 SGD를 활용했고 구현에서는 learning rate 조절을 위해 Adam을 채택했다고 하네요.
Experimental setup
본 논문에서 제안한 추천 시스템 모델을 테스트 해보기 위한 여러 실험을 진행합니다.
Dataset
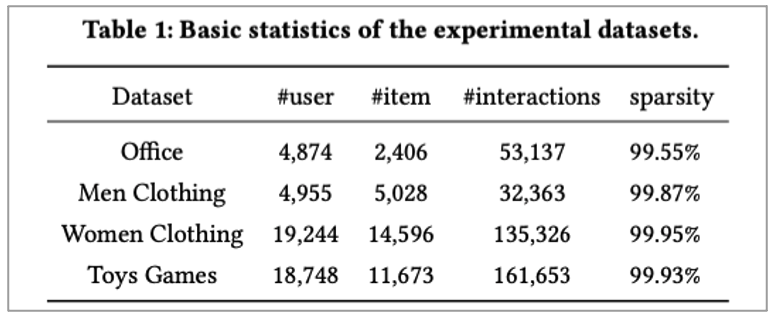
본 논문에서 사용한 데이터 셋은 4개의 데이터 셋입니다. 이때 다음과 같은 특징에 focus합니다.
• Text나 image가 없는 경우 제거
• 최소 5개의 interaction
• Top-n recommendation에 focus
• Aims to recommend a set of n top ranked item
Baseline and Evaluation Metrics
baseline과 evaluation metric은 다음과 같습니다.
• Shallow : BPR, VBPR
• Deep : DeepCoNN, NeuCF, JRL
• ML base
• Metric learning : CML
• Evaluation metric for top-n recommendation
• Precision, recall, NDCG, hit ratio
Experimental setting
본 논문에서 진행한 실험 환경 셋팅은 다음과 같습니다.

Performance Comparison
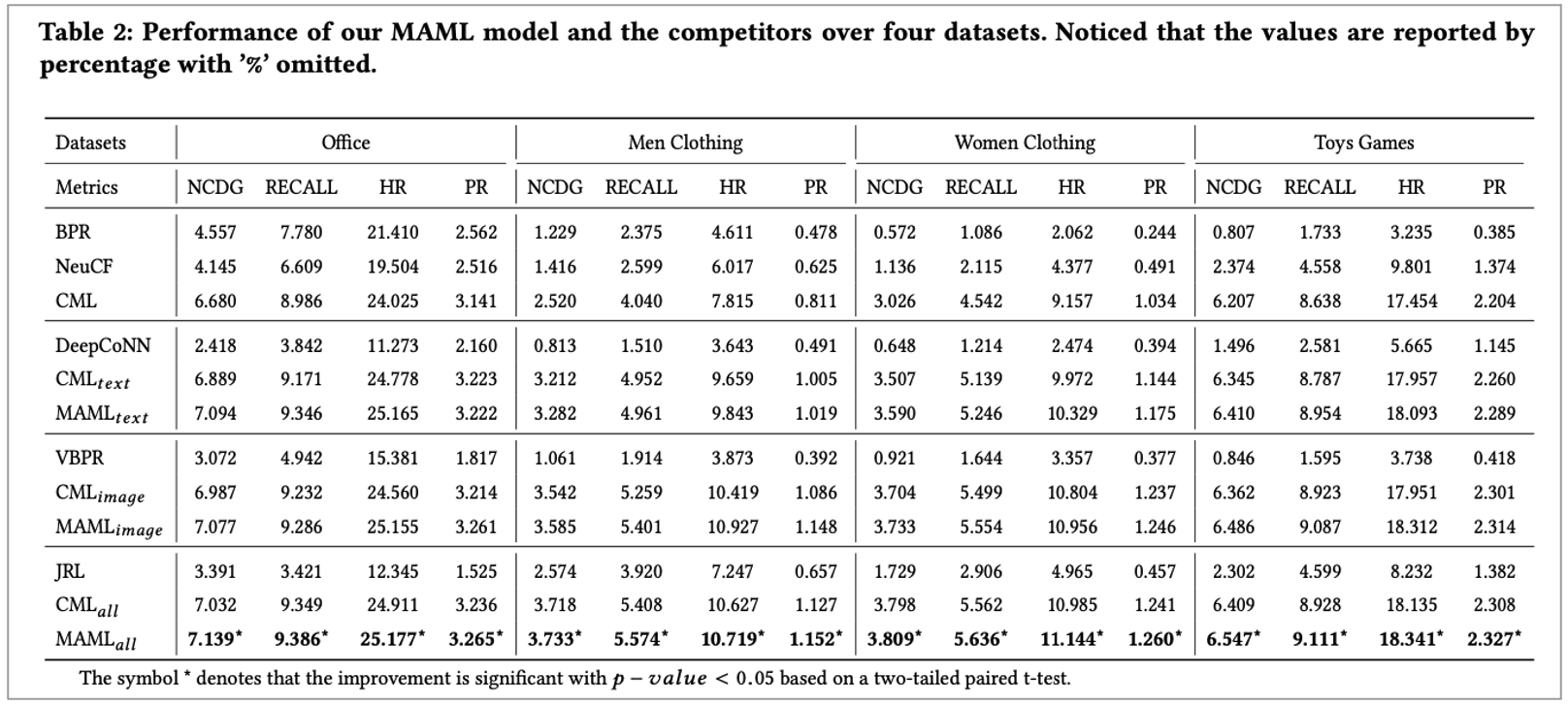
본 논문에서 제안한 모델을 평가하기 위해서 4개의 구분점으로 둬서 평가를 진행합니다. 그 구분은 다음과 같습니다.
1. only use user-item interaction information
2~3. Exploiting one type of side information
여기서는 Text, image를 더하는 것입니다. 그리고 Additional item feature를 하니 좋은 성능을 보여 줬다고 하며 Text보다 image에서 더 좋은 결과를 얻었다고 하네요. 반면, DeepCoNN은 만족스럽지 못한 결과를 보여줬다고 합니다. 왜냐하면, Real scenario에서는 사용자 reivew가 item을 구입하기 전까지 나올 수 없기 때문입니다. 따라서 본 논문에서는 testing stage에서는 text review를 활용하지 않았다고 합니다.
4. Text와 image를 동시에 활용
text와 image를 동시에 활용하니까 항상 좋은 성능 향상을 보여 줬다고 합니다.
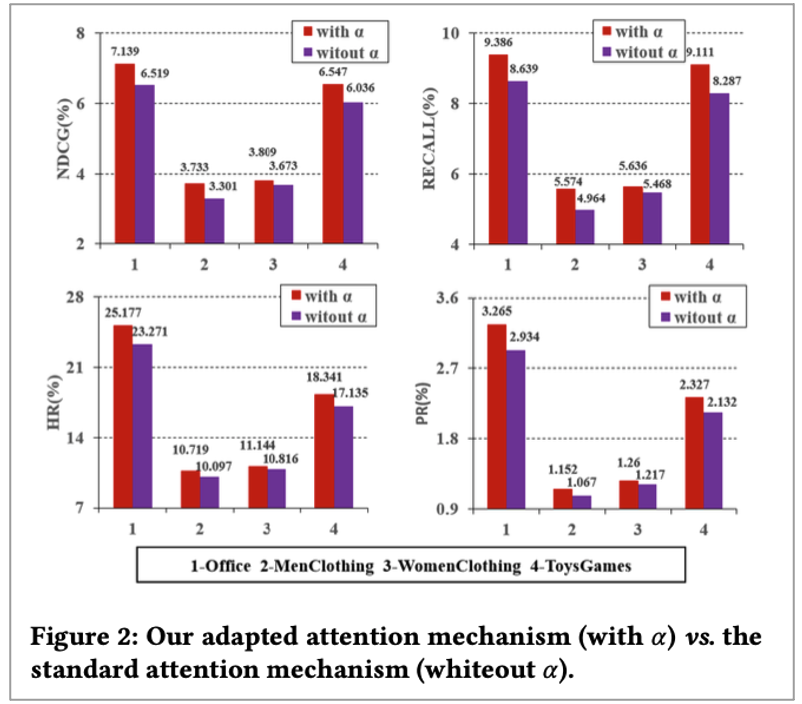
Effects of our attention mechanism
다음으로 attention mechanism의 효과를 보여주는 실험입니다. Standard attention mechanism에서 확대하는 요소 factor alpha를 부여했었는데요. 이것에 대한 비교를 했습니다. 그리고 실험 결과 일관성 있게 개선된 모습을 보여줬다고 하네요.
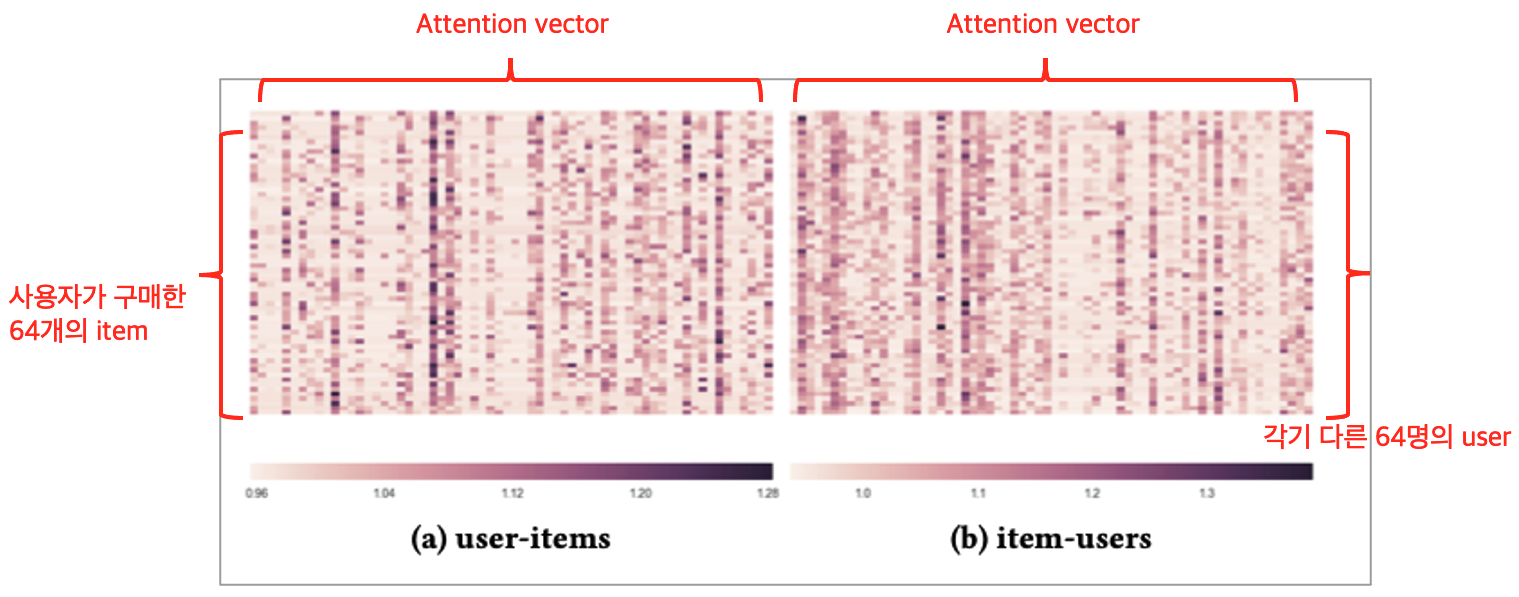
Visualization
다음으로 visualization입니다. 본 논문에서 제안한 방법은 We model user diverse preferences by capturing user attention to different aspects of items 입니다. 즉, 사용자의 선호도는 different items에 따라 different aspects를 가지고 있다는 것이죠! 그러므로 user-item pair에서 본 model은 unique attention weight for each aspect of the item해야 합니다.
따라서 이를 시각화를 통해 보고자 합니다. 시각화는 Attention weight를 통해 user varying preferences on different aspects of various items을 확인하고 User diverse preferences based on the purchased items을 확인합니다.
그 결과는 다음과 같습니다. 사용자 선호도가 아이템에 따라 다른 것을 확인할 수 있었으며 같은 item에 대해서도 사용자마다 aspect가 다르다는 것을 확인할 수 있었습니다.
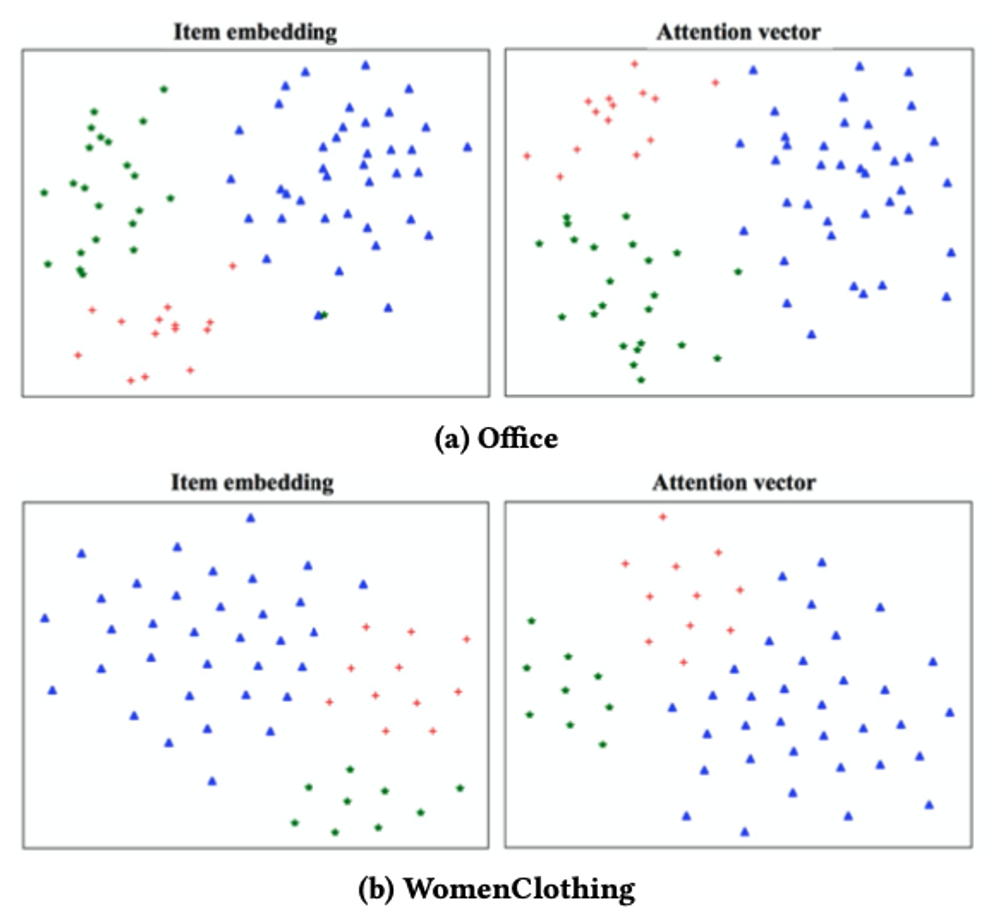
Visualization – user diverse preference visualization
본 논문에서 말하는 저자들의 주장을 따르면 다음과 같은 것들이 있습니다.
1. user likes items with diverse feature
2. user has different preferences on the aspects of various items
이를 위해 사용자가 구입한 아이템에 대한 선호도 클러스터링을 시각화해서 살펴봅니다. Item embedding과 user attention vector를 활용하였으며 T-sne를 활용했고 해당 그림에서 하나의 dot은 item입니다.
Vector의 특징을 살펴보면 다음과 같습니다.
• Item vector
• Learned based on its interactions with all the users
• Item의 모든 aspects를 잘 특징 지어 줌
• Clustering result는 user diverse preferences on items with different feature를 나타냄
• Attention vector
• Item의 다양한 aspects의 user attention을 잘 특징 지워 줌
• Clustering result는 user varying(변화) attention on different aspects of item을 입증해 줌
Conclusions
본 연구의 결론입니다.
본 추천 시스템 논문은 MAML 모델을 소개합니다. 이는 Top-n recommendation 모델이며 Metric learning base모델입니다. metric learning을 활용해 Avoids limitation of matrix factorization based method하였으며 Can capture fine-grained user preference하였습니다.
또한, 본 모델은 Designed to model user diverse preferences on different aspects of items하기 위해 제안되었습니다. 이를 위해서 attention neural network를 제안하였고 Multimodal feature를 활용해 User의specific attention on each aspect of item을 추정하였습니다.
결국은 다음과 같은 Potential을 확인할 수 있었습니다.
• User diverse preference of recommendation
• 다양한 실험에서 좋은 성능
• 결과 시각화
마무리
이번 포스팅은 추천 시스템 논문 중 MAML : User Diverse Preference Modeling by Multimodal Attentive Metric Learning 이라는 논문을 리뷰해보았습니다. 내용이 길지만, 부디 도움이 되길 바랍니다.
감사합니다.



