
포스팅 개요
이번 포스팅은 추천시스템(RecSys, recommender system) 논문 중 PMN : An Attention-Based User Preference Matching Network for Recommender System이라는 논문을 리뷰한 포스팅입니다. 본 논문은 추천 시스템에서 CTR prediction에 focus하며 time-series 문제에 접근, 그 중 user feedback information을 결합한 방법을 소개하는 추천 시스템 논문입니다. 본 포스팅은 해당 recommender system paper를 review 합니다.
또한, 본 포스팅은 제가 작성하고 있는 추천 시스템 시리즈 글 입니다. 추천 시스템 시리즈 논문 리뷰는 아래와 같은 순서로 진행할 예정입니다. 오늘은 그 다섯 번째 포스팅입니다.
- DeepFM (https://lsjsj92.tistory.com/636)
- MAML (https://lsjsj92.tistory.com/637)
- VECF (https://lsjsj92.tistory.com/638)
- FDSA (https://lsjsj92.tistory.com/639)
- PMN
- GAU (https://lsjsj92.tistory.com/641)
- A3NCF (https://lsjsj92.tistory.com/642)
- MIAN (https://lsjsj92.tistory.com/643)
- CCANN (https://lsjsj92.tistory.com/644)
본 포스팅에서 참고한 자료는 다음과 같습니다.
An Attention-Based User Preference Matching Network for Recommender System
Click-through rate prediction (CTR) is an essential task in recommender system. The existing methods of CTR prediction are generally divided into two classes. The first class is focused on modeling feature interactions, the second class is focused on solvi
ieeexplore.ieee.org

포스팅 본문
추천 시스템 논문 PMN : An Attention-Based User Preference Matching Network for Recommender System 논문 리뷰는 다음 순서로 진행합니다!
1. PMN 핵심 요약
2. PMN 논문 리뷰
PMN 핵심 요약
CTR prediction 방법은 일반적으로 크게 두 가지로 나뉨
1. focused on modeling feature interaction
2. solving time-series problem
두 번째 방법 중에서 기존 모델의 문제점
• Not able to handle time-series problems with user feedback information
PMN
• User feedback information을 활용하여 위의 문제를 해결하고자 함
• User historical behavior with user feedback을 최대한 활용하고자 함
• 이를 위해 attention mechanism을 활용함
• user historical behavior representation을 가져옴
• Original input에서 user preference representation을 가져옴
• User preference representation은 user feedback에서 나오게 되는데 이는 candidate video에 대한 사용자의 attitude를 보여줄 수 있음
• 사용자마다 scoring standard가 다르기 때문에 user preference baseline을 도입
PMN 논문 리뷰
PMN : An Attention-Based User Preference Matching Network for Recommender System 추천 시스템 논문에 대한 리뷰와 정리를 시작합니다. 논문에 나와 있는 순서대로 진행하겠습니다.
Introduction
Recommender system
추천 시스템은 User preference를 모델링하기 위해 browsing history, view history 등 사용자의 다양한 행동을 track합니다. 일반적인 추천 시스템은 candidate generation과 candidate ranking에 순서를 따른다고 하며 본 논문의 추천 시스템은 candidate ranking에 집중합니다.
Ranking model in CTR research 분야에서는 대략 2개의 mainstream이 있음
본 논문에서 말하기를 ctr ranking model 분야에서는 아래와 같은 2개의 main stream이 있다고 합니다.
1. class developed from FM(Factorization Machine)
• Focused on modeling feature interactions
2. Focused on processing time-series data
FM type model 모델에서 Input feature는 original viewing records나 click record 등에서 추출되는 경우가 많습니다. 이러한 feature들은 사람에 의해 설계되거나 생성 된다고 합니다. Time-series type에서는 Users browsing records를 직접 처리된다고 하며 FM type보다 원시적이고 포괄적인 정보를 담고 있지만, 그만큼 noise도 많다고 합니다.
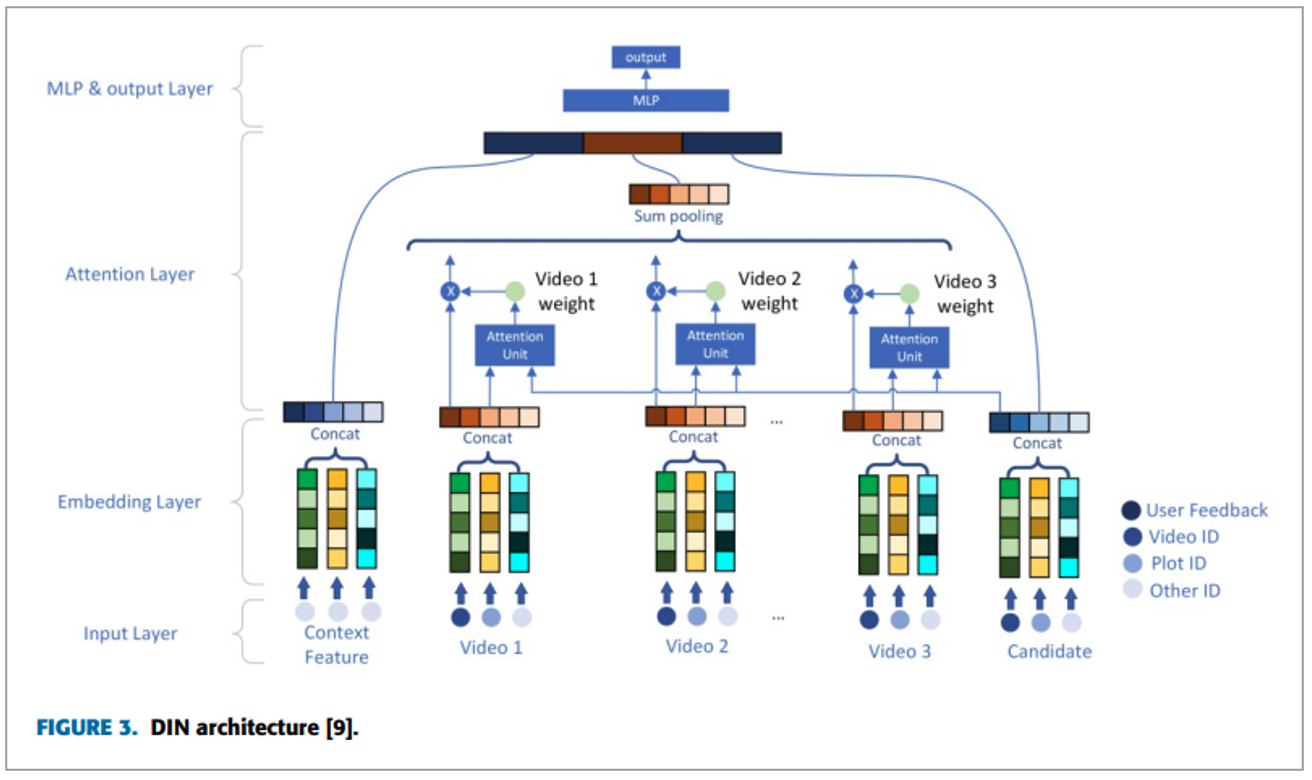
Deep Interest Network(DIN)
본 논문에서는 Deep Interest Network(DIN)이라는 추천 시스템 모델을 언급하는데요. E-commerce에서 time-series를 다루기 위해 Alibaba에서 고안한 모델이라고 합니다. 하지만, user provides feedback을 다루지 않다는 단점이 있습니다.
User feedback
Recommender system에서 중요한 요소라고 논문에선 주장하고 있습니다.
PMN ( in this paper )
본 논문에서 주장하는 PMN이라는 추천 시스템 모델은 아래와 같은 특징을 가지고 있습니다.
1. Candidate video에 대한 user preference를 explicit하게 나타내기 위해 vector를 사용
• Candidate video와 user watch history 사이의 similarity weight를 계산하기 위해 attention mechanism을 활용
2. similarity weight를 기반으로 user history feedback을 weighted sum함
• Candidate video에 대한 user preference를 이렇게 표현
위 접근 방식의 직관은 다음과 같이 설명할 수 있습니다.
• 사용자가 좋아하는 비디오와 후보 비디오가 유사할수록 사용자가 후보 비디오를 시청할 가능성이 높음
• 사용자가 싫어하는 비디오와 후보 비디오가 유사할수록 시청할 가능성이 낮음
사용자마다 score에 대한 기준이 다름
0~10점에서 어떤 사용자는 평균적으로 7점을 많이 주고 어떤 사용자는 4점을 많이 주는 경향이 있습니다. 이는 즉, 사용자가 특정 비디오를 좋아하는지 판단하는데 uniform standard를 사용해서 결정하는 것은 unreasonable하다는 것입니다. 따라서, 본 논문에서는 user preference baseline을 제공하여 이를 보완합니다. 이는 Average of user historical feedback이며 Current preference와 preference baseline과 비교를 함으로써 PMN 모델은 보다 정확한 판단을 내릴 수 있다고 합니다.
요약하자면, 본 논문은 아래와 같은 기여를 제공합니다!
• PMN 모델 제안
• Address the case where user provides feedback in a time-series problem
• 후보 비디오에 대한 사용자의 historical behavior와 user preference를 포함해 CTR 예측
• 사용자의 scoring standard가 달라서 generalized 할 수 없음
• 때문에 user preference baseline 소개
• 사용자의 현재 선호도와 baseline의 차이를 측정해서 truly preference를 보다 정확하게 반영할 수 있음
• 다양한 dataset에서 실험을 제공해 효과를 검증하고 explainability도 제공
Related work
본 논문과 연관된 다양한 추천 시스템 논문들이 있습니다.
더 좋은 성능을 내기 위해 feature interaction을 효과적으로 모델링하는 것에 대한 연구가 진행 중
Higher-order feature의 combination은 좋은 성능을 보여줍니다. 예를 들면 다음과 같습니다.
• Ex) 20살, male, sci-fi action movie를 봄
• < gender=male, genre=[Action, science fiction], age=20>
• 3-order feature임
대표적인 것이 FM, FNN, DeepFM, Wide&Deep 등이 그 연구 사항입니다. Original input에서 High-order feature interaction을 모델링 하려는 시도를 하며 FM-type이라고 본 논문에서 지칭합니다.
Time-series
FM-type은 user watch history 등을 반영할 수 없습니다. User browsing records 등은 original data에 가깝고 포괄적인 정보가 담겨있지만, 그만큼 noise도 있다고 합니다. 이러한 정보를 얼만큼 마이닝할 수 있는지가 핵심 이슈이며 DIN (알리바바에서 내놓은 모델 )이 대표적인 모델이라고 합니다.
Attention mechanism
Attention is all you need에서 나온 방법을 소개합니다. Query, Key, Value(QKV) 어텐션을 진행하며 본 논문에서도 다루는 video recommendation에서의 QKV는 다음과 같습니다.
• Query : candidate video
• Key, Value : users watch history

Preference Matching Network
Model Overview
본 논문에서 소개하는 추천 시스템 모델인 PMN은 candidate set에 ranking 문제를 해결하기 위해 만들어진 모델입니다. 본 모델의 직관적인 디자인은 'Candidate video가 사용자가 좋아하는 비디오라면, 비디오를 볼 가능성이 높아진다는 것!'입니다. 이러한 가정을 기반으로 attention mechanism을 활용하며 이는 Candidate video와 historical viewing video 사이의 similarity weights를 계산하기 위해 사용됩니다.
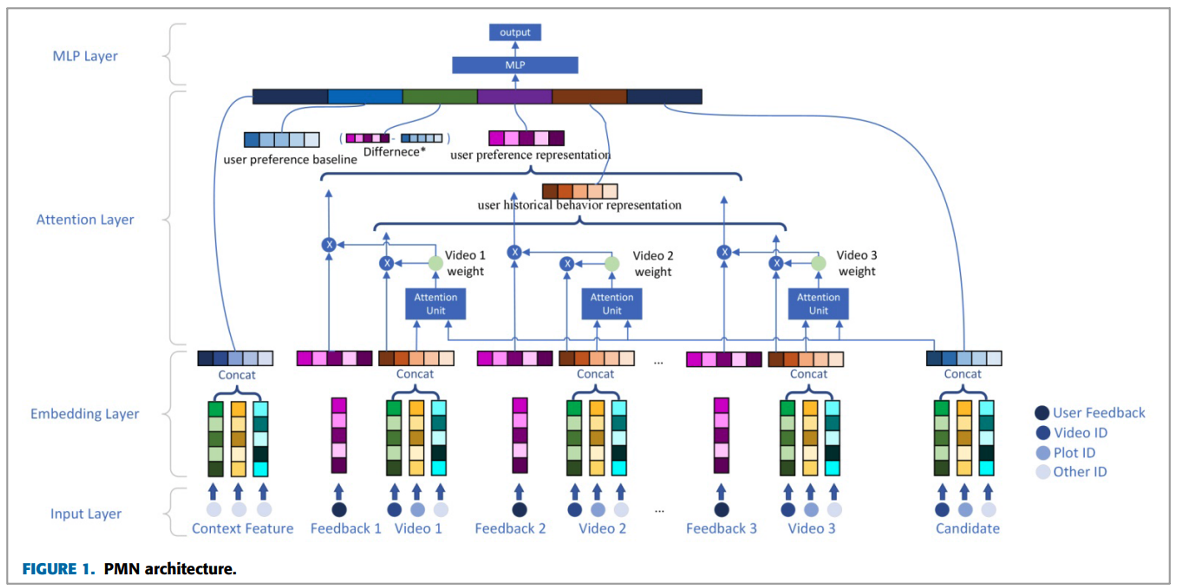
여기서 similarity weights는 사용자가 본 video에서 어떤 것이 중요하고 덜 중요한 지 알 수 있다고 합니다. 이러한 Similarity weights를 바탕으로 두 가지 vector를 가져올 수 있다고 합니다.
1. user historical behavior representation
• User watch history에 있는 candidate와 유사한 elements의 representation vector
2. user preference representation
• User watch history와 candidate video 사이의 관련성을 고려해 user가 candidate에 대한 선호도를 나타내는 벡터
위 2가지 벡터로 사용자의 historical feedback과 historical behavior에 숨겨진 attitude를 정확하게 표현할 수 있으며 마지막에는 attention layer의 output feature를 concat해서 MLP layer에 태운 다음 predict합니다.
1. Input Layer
먼저 input layer입니다. 해당 layer에서는 User watch history, candidate video, label이 들어옵니다. 여기서 feature에 관한 것은 Categorical이면 one-hot 또는 multi-hot, Numerical이면 scalar value로 처리합니다.

2. Embedding layer
Embedding layer에서는 Categorical feature에 대한 feature representation을 진행합니다. 해당 layer는 Sparse하고 high-dimensional하며 Embedding layer를 통해 low-dimensional space로 매핑합니다. 이때 Different types of features에 따라 mapping 방법이 다르다고 합니다.
• One-hot categorical variables
• Multi hot categorical variables ( genre = {action, crime} )
• Numerical variable

3. Attention layer
attention layer에서는 4개의 output이 있습니다.
• User historical behavior representation (Eh)
• User preference representation ( Ef )
• User preference baseline (Eaf)
• Difference between Ef and Eaf
각각 attention layer에 대해서 설명하겠습니다.
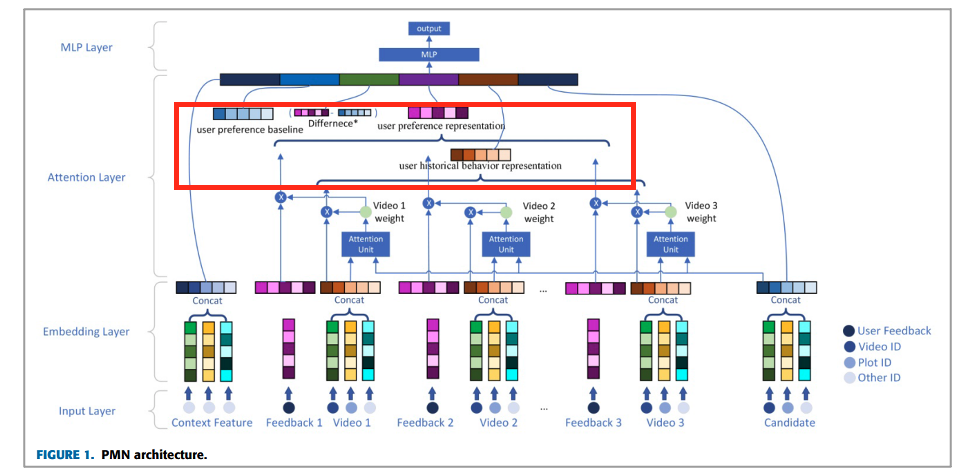
3-1. Attention layer – user historical behavior representation
Candidate video를 클릭할 것인지의 여부는 사용자의 이력과 관련성이 있습니다. 이때 사용자의 watch history를 fixed-length vector로 나타내는 방법은 2가지 방법이 있다고 합니다.
1. averaging all user historical behaviors
가장 첫 번째 방법은 모든 사용자 이력을 평균내는 것입니다. 이 방법은 Simple하지만 합리적인 방법은 아니라고 합니다. 왜냐하면, 서로 다른 candidate video들에게 user preference를 same vector로 표현하는 꼴이기 때문입니다. 사용자가 video를 클릭하는 데는 많은 ‘Why’가 있습니다. 그렇기에 static vector는 different candidate video에 대해서 다른 interest preference를 반영하지 못합니다.
2. weighted sum with attention mechanism
두 번째 방법은 Attention mechanism을 활용하여 user history에서 weighted sum을 얻는 방법입니다. 이는 candidate video와 가장 관련되어 user history에 존재하는 element를 포함합니다. 이때 Attentinon Unit은 Query, Key, Value model을 사용합니다. 각각 Query는 candidate video를 Key는 embedded user watch history, Value는 video embedding vector를 의미하게 됩니다.
User historical behavior representation vector는 Query와 Key에서 similarity vector를 얻고 weighted sum하는 방법을 채택합니다. 이를 통해 User history record에서 candidate video와 관련된 가장 관련성 높은 정보를 표현할 수 있습니다.

3-2. Attention layer – user preference representation
다음은 attention layer에서 usre preference representation 입니다. 여기서는 User watch history의 feedback 정보에 앞서 구한 attention 정보 결합합니다. 사용자가 본 비디오가 candidate와 비슷하다면 feedback 정보는 더 중요해질 것이라고 가정합니다.

3-3. Attention layer – user preference baseline
일반적으로 사용자의 rating standard가 다릅니다. 이게 무엇을 의미하는 것이냐면 어떤 사용자는 5점을 좋아하는 비디오에 주면, 어떤 사용자는 4점 정도로도 매우 만족스러워합니다. 즉, user preference baseline은 User feedback embedding이 user preference에 정확하게 반영하기 위해서 Preference baseline vector를 도입합니다. 이는 User historical preference의 average level이며 즉, 사용자 피드백 시퀀스를 평균한 것입니다.

3-4. Attention layer - Difference
Difference는 User preference와 user preference baseline의 차이를 나타냅니다. 사용자의 current candidate movie에 대한 선호도와 user의 historical preference baseline을 비교하는 것이죠. 이렇게 함으로써 사용자 선호도를 더 정확하게 반영합니다.

4. MLP Layer
MLP layer는 Attention layer에서 나온 4개의 output을 포함한 feature vector set이 input으로 들어오게 됩니다. 이것들을 전부 concat하고 three-layer MLP를 적용합니다. Last layer는 user clicking probabilities를 output으로 내놓게 됩니다.
Training
• Log loss 사용
• Adam 사용

Experiment
본 논문에서 제시한 추천 시스템 모델에 다양한 실험을 진행합니다.
아래 3개에 대한 답에 focus
• Q1. PMN 모델이 CTR prediction에서 성능이 나오고 또한 feedback information이 성능 향상을 보여주는가?
• Q2. 다른 모델 구조의 영향은 어떠한가?
• Q3. specific sample에 대해서 성능이 보여주고 explainable한가?
Dataset
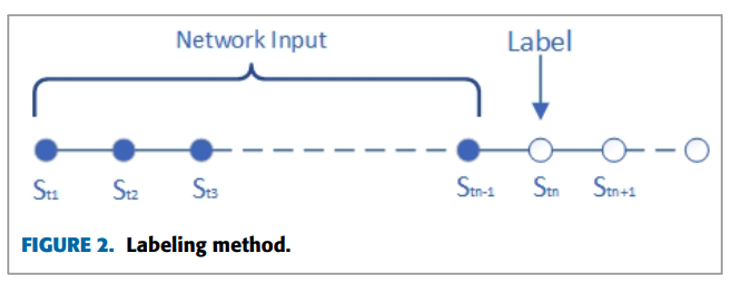
본 논문에서 활용한 Dataset을 구성할 때 chronological factor(시간적 요소)를 고려해야 했습니다. 따라서, 아래 그림과 같이 샘플을 구성했다고 합니다.
• Historical information을 사용하여 future item을 예측하는 방법을 사용
• Maximum length : 50
본 논문에서 사용한 데이터 셋은 다음과 같습니다.
| Dataset | 특징 |
| Kaggle Anime |
- 12,294 애니메이션
- 67,041 명의 사용자
- Missing data는 -1로
- Rating은 10점까지
- Positive, negative를 나누어야 하는데 사용자마다 rating의 표현이 다름
- 단순히 높은 것을 positive로 하는 것은 현명하지 않음
- 따라서, 각 user의 average score를 계산하고 그것보다 높으면 positive
- 이렇게 하면 보다 정확하게 사용자 선호도를 반영할 수 있음
|
| Movielens |
- 1,000,209의 rating
- 3,900개의 영화, 6,040의 사용자
- Rating은 5점까지
- Label 생성을 위해 anime 방법을 채택
|
| IPTV |
- IPTV provider와의 협력을 통해 얻어낸 데이터
- Rating은 5점까지
- Label 생성을 위해 anime 방법을 채택
|
Competing Models
본 논문에서 비교한 모델들은 다음과 같습니다.
| Competing Models | 특징 |
| Wide & Deep |
- Low and high order feature interaction 반영
- Wide part와 deep part로 나누어짐
|
| PNN |
- Product layer between embedding layer and first hidden layer
- User behavior에서 high order feature interaction을 가져온 first hidden layer
|
| DeepFM |
- Wide & Deep을 Factorization Machine을 wide part input feature에 사용하여 향상시킨 모델
|
| DIN |
- PMN과 다른점은 user feedback을 사용하는 여부
- PMN은 user feedback을 모델링
- DIN은 사용자의 과거 행동 시퀀스가 사용자 관심을 나타낸다고 가정
- DIN은 user feedback information을 사용하지 않음
- Candidate와 user historical 행동 사이의 유사도를 계산하기 위해 디자인
|
Experiment - Effectiveness Comparison ( Q1 )
첫 번째 실험 결과를 정리합니다.
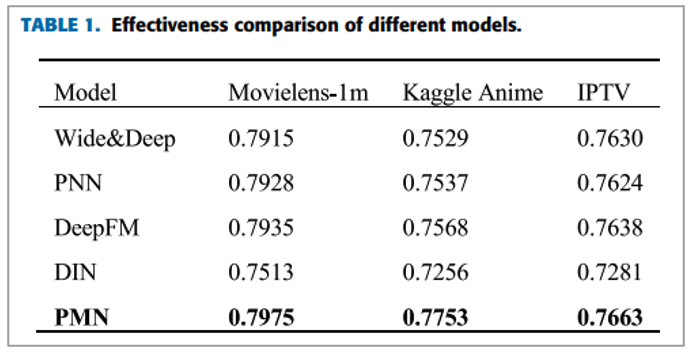
해당 실험 결과에서 다음과 같은 insight를 도출할 수 있었습니다.
1. user feedback information은 매우 중요함
• DIN은 user feedback을 반영한 모델보다 좋지 않은 성능을 보여줌
2. PMN은 time-series 문제를 위해 디자인 되어 짐
• 특히, user feedback을 반영한 시나리오며 좋은 성능을 보여줌
• User preference vector는 attention mechanism을 통해 계산
• 때문에 candidate에 대해서 사용자의 선호도를 정확하게 반영할 수 있음
• 다른 CTR 모델은 same fix-length vector를 MLP 전에 사용하였음
Experiment - Model Structure Analysis ( Q2 )
두 번째 실험 결과를 정리합니다.
5개의 part에 대해서 효과를 검증해 봄
각각 part에 대해서 효과를 검증해봅니다. 각 part는 다음과 같이 구성됩니다.
• User historical behavior representation ( Eh )
• User preference representation ( Ef )
• User preference baseline ( Eaf )
• Difference ( between Ef and Eaf )
• Candidate video ( Et )
이를 위해 4개의 모델 디자인을 구성했다고 합니다. 그 구성 모델은 다음과 같습니다.
| Model Design | 특징 |
| PMN-1 |
- Eh와 Et를 포함한 구조
- User feedback을 고려하지 않음 ( DIN이라고 고려할 수 있음 )
|
| PMN-2 |
- Et, Ef, Eaf, (Ef – Eaf )를 고려
- User feedback information과 user scoring standard만 고려
- Historical behavior는 고려하지 않음
|
| PMN-3 |
- Eh, Et, Ef를 고려
- User historical behavior와 feedback을 고려하지만, scoring standard는 고려하지 않음
|
| PMN-4 |
- 전부 고려
|
구성한 모델을 실험해본 결과는 다음과 같이 정리될 수 있습니다.
• User feedback을 고려하니 더 나은 성능 ( PMN-1이 성능이 가장 안 좋음 )
• PMN2가 PMN1보다 좋은 것을 보아하니, user feedback information이 중요함
• PMN3는 PMN1, 2보다 좋은데 이는 user feedback과 historical behavior 정보가 CTR 예측에 중요한 요소라는 것을 의미
• PMN4는 PMN3보다 좋으며 특히 Kaggle Anime에서 더 큰 성능 차이가 보임
• Anime는 10점까지의 범위이고 나머지 두 데이터는 5점의 범위임
• 사용자가 매기는 점수의 정도가 Anime에서 더 뚜렷하게 보여줄 수 있기 때문에 Anime에서 더 큰 성능 차이
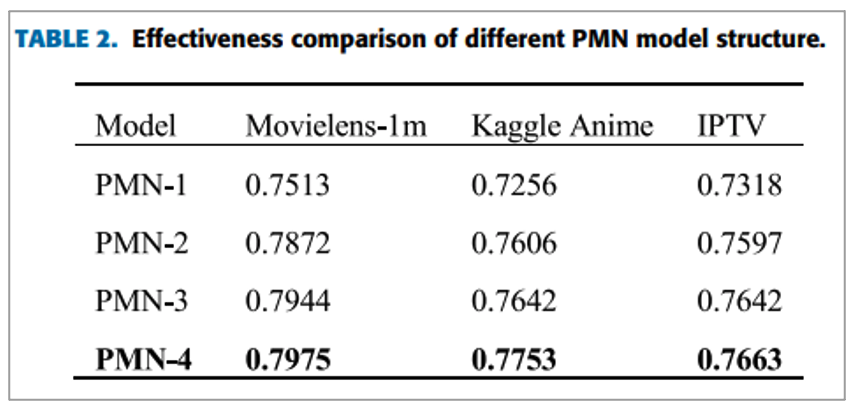
Experiment - Explainable Recommendations ( Q3 )
세 번째 실험 결과를 정리합니다.
1. 미녀와 야수
사용자 이력 중 toy story, chicken run과 관련성 있습니다. 하지만, 이 사용자는 애니메이션을 좋아하지 않구요. 즉, 평점이 낮습니다. 따라서, CTR estimate 결과는 0.224가 나오게 됩니다.
2. 인디아나존스
사용자는 인디아나존스, 매트릭스, star wars 등을 시청했다고 합니다. 또한, 관련 평점도 높습니다. 따라서, CTR estimate 결과는 0.910가 나왔다고 합니다.

Conclusion and future work
본 논문에서는 PMN이라는 추천 시스템 모델을 제시합니다. 해당 모델은 user feedback과 함께 CTR 측정 문제를 해결하고자 했습니다.
PMN 모델은 다음과 같은 특징을 가지게 됩니다.
• User feedback information을 모델링하기 위해 attention mechanism 사용
• Final weighted sum of user history feedback은 candidate item에 대한 사용자 선호도를 나타냄
• Different user rating standard를 구분하기 위해 user preference baseline을 도입
• 마지막에 다양한 실험에서 검증해봄으로써 효율성을 확인함
추후 연구
추후에는 다른 구조의 PMN 모델을 탐색하여 더 효율적인 NN 구조가 있을 것이고 이를 탐색한다고 합니다. 또한, Implicit feedback을 사용해볼 것이라고 합니다.
마무리
이번 포스팅은 추천시스템(RecSys, recommender system) 논문 중 PMN : An Attention-Based User Preference Matching Network for Recommender System이라는 논문을 리뷰한 포스팅입니다.
긴 글 읽어주셔서 감사합니다.



