
목록분류 전체보기 (584)
꿈 많은 사람의 이야기
 왜 나는 자연어처리(NLP) 논문을 읽게 되었는가? - ELMO, Transformer, BERT부터 XLNet, ALBERT, RoBERTa, ELECTRA까지NLP 논문 후기
왜 나는 자연어처리(NLP) 논문을 읽게 되었는가? - ELMO, Transformer, BERT부터 XLNet, ALBERT, RoBERTa, ELECTRA까지NLP 논문 후기
포스팅 개요 이번 포스팅은 최근에 제가 읽게되었던 딥러닝 분야의 자연어 처리(NLP) 논문을 읽고난 후기입니다. 어떠한 계기로 자연어처리 논문을 읽게 되었는지, 무엇을 배울 수 있었고 목표를 달성한 지금 어떤 기분인지 등을 정리하고자 합니다. 비록 보잘것 없는 경험이지만, 이 경험이 자연어처리 공부에 관심 있으신 분들에게 도움이 되었으면 좋겠습니다. 본문 내용는 본인에 대한 후기 내용이어서 ~습니다 식으로 작성하지 않고 '다, 까' 형식으로 작성하였습니다. 포스팅 본문 2020년 7월 말. 나는 하나의 결정을 하게되었다. 가뜩이나 여러가지 일로 힘든 상황이었고 바쁘기도 했지만 그래도 해야한다 라는 생각이 들었다. 그건 바로 자연어처리(Natural Language Processing; NLP) 논문 읽기..
 Python 자연어처리 서브워드(subword) sentencepiece와 huggingface tokenzier 사용법 정리
Python 자연어처리 서브워드(subword) sentencepiece와 huggingface tokenzier 사용법 정리
포스팅 개요 이번 포스팅은 자연어 처리에서 최근 많이 사용하는 subword 분절 방식인 sentencepiece와 huggingface sentencepiece 사용 방법을 정리합니다. 최근에 자연어처리쪽 모델을 다룰 일이 있어서 형태소 분석기를 사용할 까 하다가 sentnecepiece를 사용해 봤는데 너무 좋은 경험이 되어서 이를 정리하고자 합니다. 제가 참고한 자료는 아래와 같습니다. github.com/google/sentencepiece google/sentencepiece Unsupervised text tokenizer for Neural Network-based text generation. - google/sentencepiece github.com github.com/huggingfa..
포스팅 개요 이번 포스팅은 Tensorflow 2.x 버전을 사용하면서 발견한 에러와 그 해결 방법에 대해서 정리합니다. 저의 환경은 아래와 같습니다. python 3.7 tensorflow 2.3 포스팅 본문 포스팅 개요에서도 말씀드렸듯이 이번 포스팅은 Python의 tensorflow 2.x 버전에서 겪을 수 있는 에러에 대해 정리합니다. 제가 구성한 tensorflow 버전은 2.3이고 에러는 NotImplementedError: Layer has arguments in `__init__` and therefore must override `get_config`. 라는 에러입니다. 위 에러가 나오게 된 배경 저는 아래와 같은 상황에서 위 에러를 경험할 수 있었습니다. Open되어 있는 Tensorf..
 Python 추천 시스템(Recommeder System) 구현하기 - Wide & Deep learning for Recommender System
Python 추천 시스템(Recommeder System) 구현하기 - Wide & Deep learning for Recommender System
포스팅 개요 이번 포스팅은 Python으로 구현하는 추천 시스템(Recommender System with Python) 시리즈 중 하나입니다. 그 중 이번 포스팅은 Google Play store에도 적용된 방법인 Wide & Deep Learning for Recommender System 논문을 기준으로 진행합니다. 따라서 본 포스팅에서는 Wide & Deep Learning for RecSys 논문을 간략하게 정리하고 참고한 코드를 보면서 어떻게 추천이 진행되는지 정리하고자 합니다. 해당 추천 시스템 Python 구현 코드는 아래 제 github에 올려두었습니다. (해당 코드는 논문과 100% 일치하지 않음을 말씀드립니다.) https://github.com/lsjsj92/recommender_s..
 Mac OS 환경에서 Git 설치하기 - Mac git, github 셋팅 방법
Mac OS 환경에서 Git 설치하기 - Mac git, github 셋팅 방법
포스팅 개요 이번 포스팅은 Mac OS에서 초기 git 환경을 셋팅하는 방법에 대해 작성합니다. Mac에 git 초기 설정을 하게 되면 github 등도 비밀번호 요구 없이 바로바로 이용할 수 있는 장점이 있습니다. mac의 이러한 git 환경 설정은 아무래도 mac 사용 초기에 개발 환경 셋팅에서 많이 활용할 수 있는 방법입니다. 포스팅 본문 이번에 Mac을 초기화 하면서 다시 한 번 개발환경 셋팅을 해줘야 하는 상황이 있었습니다. 그 중 아무래도 혼자서 공부할 때 github을 많이 이용하다보니 git에 대한 초기 환경설정을 해주었는데요. 이렇게 mac 환경에서 git을 초기 설정해주면 비밀번호 요구 등을 하지 않고 쉽게 이용할 수 있는 장점이 있습니다. mac 환경에서 git을 설정하는 방법은 아래..
 글쓰는 개발자 - 글또 4기를 마무리하며
글쓰는 개발자 - 글또 4기를 마무리하며
포스팅 개요 이번 포스팅은 2020년 02월 말. 글또 4기를 시작하고, 2020년 08월 글또 4기를 활동을 마무리 지으며 작성하는 회고 글입니다. 2020.02.27 글또 4기 참여하는 다짐글을 작성한 이후에 제가 어떤 글을 작성했는지, 그 목표는 이루었는지, 반성사항은 무엇인지, 앞으로 어떤 글을 작성하고 싶은지를 정리합니다. 저의 글또 4기 다짐글은 아래와 같습니다. https://lsjsj92.tistory.com/576 글 쓰는 또라이가 세상을 바꾼다 - 글또 4기를 참여하며 포스팅 개요 이번 포스팅은 글또 4기를 참여하며 어떤 목적으로 글또를 참여하게 되었고 어떻게 활동할 것인지에 대한 다짐글입니다. 글또란 무엇인지, 제가 어떠한 다짐을 가지고 참여를 신청� lsjsj92.tistory.co..
 Python slack API 연동하기 - slack API 설정하기 with webhooks
Python slack API 연동하기 - slack API 설정하기 with webhooks
포스팅 개요 슬랙(slack)은 요즘 정말 많이 사용하는 메신저 중 하나입니다. 메신저라고 하기도 좀 그렇고 뭔가 협업 툴? 같은 느낌이 많이 드는 서비스입니다. 이 슬랙의 장점은 API가 쉽게 제공된다는 것인데요. 이 API를 이용해서 Slack을 다채롭게 이용할 수 있습니다. 오늘 포스팅은 파이썬(Python)과 Slack을 연동해서 API로 call을 보낼 수 있는 기본적인 방법을 정리하고자 합니다. 해당 포스팅을 작성하며 참고한 자료는 아래와 같습니다. https://api.slack.com/messaging/webhooks https://github.com/slackapi/python-slackclient 포스팅 본문 개요에서 말씀드렸다시피 이번 포스팅은 메신저 Slack과 Python을 연동하..
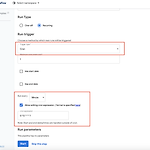 kubeflow pipeline cron job(batch) 설정하기 - kubeflow recurring job(scheduled workflows)
kubeflow pipeline cron job(batch) 설정하기 - kubeflow recurring job(scheduled workflows)
포스팅 개요 이번 포스팅은 kubeflow pipeline을 cron job(batch job)으로 반복 실행시키는 방법에 대해서 작성합니다. kubeflow cron job은 내부적으로 recurring job으로 보이고 이를 설정했을 때 scheduled workflows로 설정되는데요. 이를 설정하면 특정 시간, 혹은 특정 기간 마다 kubeflow pipeline을 반복적으로 실행합니다. 이번 포스팅은 이와 같은 방법에 대해 정리합니다. kubeflow 설치와 기본적인 설명은 지난 포스팅에서 작성했던 내용을 기반으로 설명합니다. 지난 포스팅은 아래 링크이므로 글을 읽다가 잘 모르시겠으면 참고해주세요. https://lsjsj92.tistory.com/580 kubeflow 설치하기 - Machin..
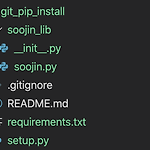 github repository로 python pip install 만드는 방법 정리
github repository로 python pip install 만드는 방법 정리
포스팅 개요 이번 포스팅은 Python의 패키지를 관리해주는 pip install에 대해서 정리합니다. 그 중 github(혹은 gitlab 등)를 이용해서 pip install을 하는 방법에 대해서 정리를 해보려고합니다. 이렇게 git을 이용해서 pip install을 할 수 있는 환경을 만들어주면 본인만의 라이브러리를 구축하고 편하게 사용할 수 있기 때문에 여러 방면으로 유용합니다. 그래서 이거를 나중에도 사용할 수 있도록 아주 간단한 예시로! 미리 정리해두려고 합니다. 포스팅 본문 Python의 pip는 파이썬으로 패키지를 관리해주는 시스템인데요. 보통은 사람들이 만들어 놓은 패키지를 pip install을 이용해서 패키지를 설치합니다. 예를 들어서 아래와 같죠 pip install tensorfl..
 파이썬 대용량 csv 파일 읽는 방법 정리 - Python read large size csv file
파이썬 대용량 csv 파일 읽는 방법 정리 - Python read large size csv file
포스팅 개요 이번 포스팅은 파이썬(Python)에서 용량이 큰 csv 파일을 읽고 처리할 수 있는 방법을 정리합니다. 파이썬을 활용해서 데이터 분석 혹은 모델링 등을 하다보면 대용량의 csv 파일을 많이 다루게 되는데요. 이때 메모리 부족으로 인해(memory error) 메모리 에러가 나오는게 일상입니다. 이러한 large size csv file을 python에서 다룰 수 있는 방법이 간단하게 있는데요. 그 방법을 정리하고자 합니다. 최근에 메모리 효율 및 속도를 빠르게 다루는 방법도 정리해두었습니다. lsjsj92.tistory.com/604 Python(파이썬)에서 데이터 메모리 효율, 처리 속도 향상 시키는 기본 방법 정리(feat. pandas, numpy) 포스팅 개요 이번 포스팅은 최근 회..