

포스팅 개요
이번 포스팅은 추천 시스템의 성능을 평가하는 방법인 평가 지표에 대해서 정리하는 포스팅입니다. 다양한 추천 시스템 평가 방법 중 본 포스팅은 NDCG(Normalized Discounted Cumulative Gain)와 MAP(Mean Average Precision) 그리고 Hit Rate에 대해서 정리합니다. 더불어서, Recall@K와 Precision@K에 대해서도 같이 정리하겠습니다.
포스팅 본문
추천 시스템은 온라인 쇼핑몰과 같은 이커머스 서비스 등에서 사용자와 서비스에 긍정적인 영향력을 제공할 수 있는 강력한 시스템입니다. 이러한 추천 시스템은 다양한 평가 방법이 있습니다. 비즈니스와 서비스에 따라 평가 방법이 다를 수 있고 흔히 정확도와 같은 오프라인 메트릭(offline metric)도 어떤 관점으로 보느냐에 따라 다양한 지표를 측정할 수 있습니다. 예를 들어서 상품을 클릭하는게 구매와 연관성이 높은 서비스 같은 경우에는 online metric으로 클릭률(Click Through Rate, CTR)이 중요한 지표일 것입니다.
이번 포스팅은 다양한 추천 시스템 평가 방법 중 모델의 평가 지표, 오프라인 지표(offline metric)에 대해서 살펴보도록 하겠습니다. 그리고 그 중 랭킹 기반 추천 시스템 성능 지표인 NDCG(Normalized Discounted Cumulative Gain)와 MAP(Mean Average Precision) 그리고 HitRate에 대해서 정리하도록 합니다. 또한, MAP를 계산할 때 필요한 Precision@K에 대해서도 같이 정리할 예정이며 Recall@K는 무엇이 다른지도 비교해봅니다.
@K
추천 시스템의 랭킹 기반 평가에서 '@K'라는 것이 자주 등장합니다. '@K'는 무엇일까요? 추천 시스템 평가 때(혹은 검색 성능 평가) 사용되는 이 @K는 '추천한 아이템의 개수'입니다. 예를 들어서 @2라고 표현하면 추천 시스템이 추천한 아이템 상위 2개로 볼 수 있는 것입니다. 왜 상위일까요? 추천 시스템은 당연하게도 사용자에게 상호작용할 확률이 높은 아이템을 제공해주겠죠? 즉, @2라는 것은 추천 시스템이 사용자에게 추천할 때 상호작용할 확률이 가장 높은 2개의 아이템을 추천한 것입니다. 만약 @5이면 5개를 추천한 것이죠. 즉, 추천 아이템 개수를 의미한다고 보시면 될 것 같습니다.
Hit Rate@K
가장 먼저 살펴볼 추천 시스템 평가 지표는 Hit Rate@K입니다. Hit Rate를 우리나라 말로 하면 무엇일까요? '적중률'이라고 표현될 수 있을 것 같습니다. Hit Rat는 비교적 단순한 평가 지표인데요. 아래와 같은 단계를 통해 Hit Rate를 구할 수 있습니다.
- 사용자가 선호한 아이템 중 1개를 제거
- 추천 시스템을 구성 및 모델 훈련
- 사용자 별로 추천 시스템이 제공한 추천 셋을 @K개만큼 추출
- 1에서 제거한 추천 아이템이 추천 셋 @K개 중에 있으면 Hit
- 전체 사용자 수 대비 Hit한 사용자 수 비율이 Hit Rate
아마 텍스트로만 보면 무슨 말씀인지 잘 이해가 되지 않을수도 있습니다. 아래 그림을 보면서 Hit Rate에 대해서 자세히 살펴보겠습니다.

위 그림에서는 총 3명의 사용자가 있습니다. 그리고 각각의 사용자는 3개의 선호 영화가 있다고 가정하겠습니다. Hit Rate를 구하기 위해서 위에서 구성한 순서대로 진행합시다.
- 사용자가 선호한 아이템 1개를 제거합니다. 사용자1은 영화1, 사용자2는 영화5 등이 제거되었습니다. 이는 주황색 박스로 표시해두었습니다.
- 이제 2단계인 추천 시스템을 구성합니다.
- 그리고 구성된 추천 시스템에서 @K개만큼 추천 아이템을 추출합니다. 위 그림에서는 @K를 3으로 가정했습니다. 즉, 추천 시스템에서 사용자별로 3개의 아이템을 추천한 것이죠.
- 이제, 사용자 별로 선호한 제거한 아이템이 추천 셋에 있는지 확인합니다. 확인한 결과 사용자1은 영화1이 제거되었는데 추천 시스템이 영화1을 추천해주었습니다. 즉, Hit가 된 것이죠. 사용자2도 영화5가 제거 되었는데 추천 시스템이 추천한 @3개 안에 영화5가 존재합니다. 마찬가지로 Hit가 되었습니다. 하지만, 사용자3은 영화3이 제거되었는데 추천 시스템이 추천한 @3안에는 영화3이 존재하지 않습니다. 즉, Hit가 되지 않았죠.
- 따라서, Hit Rate@3은 2/3이 되는 것입니다.
MAP@K ( Mean Average Precision )
추천 시스템 평가 방법을 보다보면 MAP@K라는 것이 종종 보입니다. 이 MAP란 무엇일까요? MAP를 이해하려면 각 단어를 이해해야합니다. MAP는 Mean Average Precision의 약자로, Average Precision의 평균이라고 볼 수 있을 것 같습니다. 그러면, Average Precision을 구해야겠죠? Average Precision은 Precision의 평균입니다. 즉, Precision을 먼저 이해하고 계산해야 이것들을 평균을 하고 어떤어떤 계산을 통해서 추천 시스템 MAP 평가 지표를 계산할 수 있는 것입니다.
Precision@K 그리고 Recall@K
자, 그러면 먼저 Precision@K부터 이해해보겠습니다. 아마 여러분들은 머신러닝이나 딥러닝을 공부하시다보면 Precision을 많이 들어보셨을 것입니다. 우리나라말로 정밀도라는 뜻을 가지고 있죠. 그러면 또, 많이 듣는 단어가 Recall이라는 단어도 있을겁니다. 우리나라 말로 재현율이라고도 많이 불리우죠. 추천 시스템에서도 이 Precision(정밀도)와 Recall(재현율)을 통해서 평가를 진행할 수 있습니다. 그리고 이 Precision과 Recall을 이해하면 Mean Average Precision(MAP)를 더 쉽게 이해할 수 있죠
Recall@K
먼저 Recall부터 살펴봅시다. 추천 시스템에서 Recall@K는 "사용자가 관심있는 아이템 중 추천 시스템이 추천한 아이템 K개 얼마나 포함되어 있는가?"의 의미로 해석될 수 있습니다. 마찬가지로 단순히 텍스트만 보면 잘 이해가 가지 않으실겁니다. 예시를 통해 살펴보죠

위 예시의 그림은 Recall@5를 구하는 예시입니다. 먼저, 전체 아이템은 총 10개가 있습니다. 즉, 영화1부터 영화10까지 있는 것이죠. 이때 추천 시스템은 사용자에게 영화1, 영화2, 영화3, 영화4, 영화9를 추천해주었습니다. 사용자는 영화1, 영화2, 영화3, 영화5, 영화7, 영화8을 선호한 상황입니다. 그러면 Recall@5는 어떻게 구할 수 있을까요?
Recall은 사용자가 관심있는 아이템 중 추천 시스템이 추천한 아이템 K개가 얼마나 포함되어 있는가?로 해석될 수 있다고 했는데요. 위 예시에서 계산을 해보면, 사용자가 관심있는 아이템은 6개이고 그 중에서 추천 시스템이 추천한 아이템 3개가 포함이 되었습니다. 따라서, Recall@5는 3/6이 되는 것이죠.
Precision@K
정밀도라고 불리우는 Precision은 추천 시스템에서도 활용될 수 있습니다. 추천 시스템에서 Precision@K는 "추천 시스템이 추천한 아이템 K개 중 실제 사용자가 관심있는 아이템의 비율은?"의 의미를 가지고 있습니다. 마찬가지로 예시를 통해 쉽게 이해해보겠습니다.
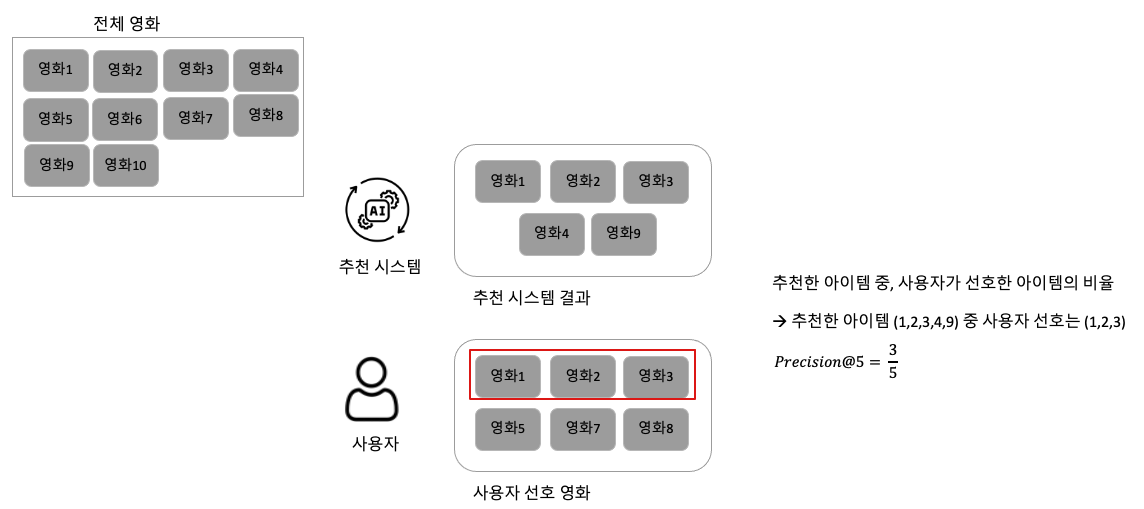
위 예시는 Precision@5에 대한 예시입니다. 앞선 예제와 마찬가지로 전체 콘텐츠는 10개 즉, 영화1~10까지 있다고 가정합니다. 이때 추천 시스템은 사용자에게 영화1, 영화2, 영화3, 영화4, 영화9를 추천해주었습니다. 사용자는 영화1, 영화2, 영화3, 영화5, 영화7, 영화8을 선호하고 있구요. 이 상태에서 Precision은 추천 시스템이 추천한 아이템 K개 중 실제 사용자가 관심있는 아이템의 비율이므로 추천 시스템이 추천한 5개 중, 실제 사용자가 관심있는 것은 3개라서 3/5로 계산되는 것입니다.
자, 어떤가요? 추천 시스템에서 Precision@K와 Recall@K에 대해서 조금은 이해가 가실까요? 이제 위 내용의 이해를 바탕으로 Mean Average Precision(MAP)를 이해해봅시다.
Average Precision(AP)와 MAP
MAP를 구하는 과정에서는 Average Precision(AP)를 구해야합니다. Average Precision은 영어 그대로 Precision의 평균이죠. 이때 Precision은 위에서 구해봤던 Precision 방법으로 볼 수 있습니다. 그리고 Average Precision은 한 가지 더 필요한 수식이 들어갑니다. 바로 Relevance(관련성)이라는 값이죠. 따라서, Average Precision의 수식은 다음과 같습니다.
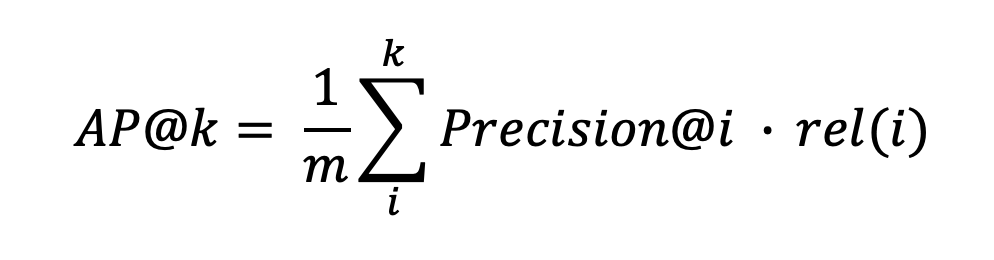
즉, Average Precision@K는 Precision@K에 대한 값에다가 rel(i) 관련성을 곱해주고 m을 나눠준 값을 취하게 됩니다. 이때 m은 모든 아이템 중에서(예를 들어 우리 서비스가 가지고 있는 모든 아이템 중에서) 사용자가 좋아한(또는 상호작용한) 아이템 수를 의미합니다. 그리고 rel(i)는 relevence(관련성) 값으로서 관련이 있으면 1, 아니면 0의 값을 취하게 합니다. 즉, 관련성이 있는 것만 영향도를 줄 수 있도록 셋팅한 것이죠. 왜냐하면, 0을 곱하게 된다면 그 값 자체가 의미가 없어지기 때문입니다.
Average Precision을 구하는 이부분도 좀 더 명확한 예시를 통해 살펴보도록 하겠습니다.
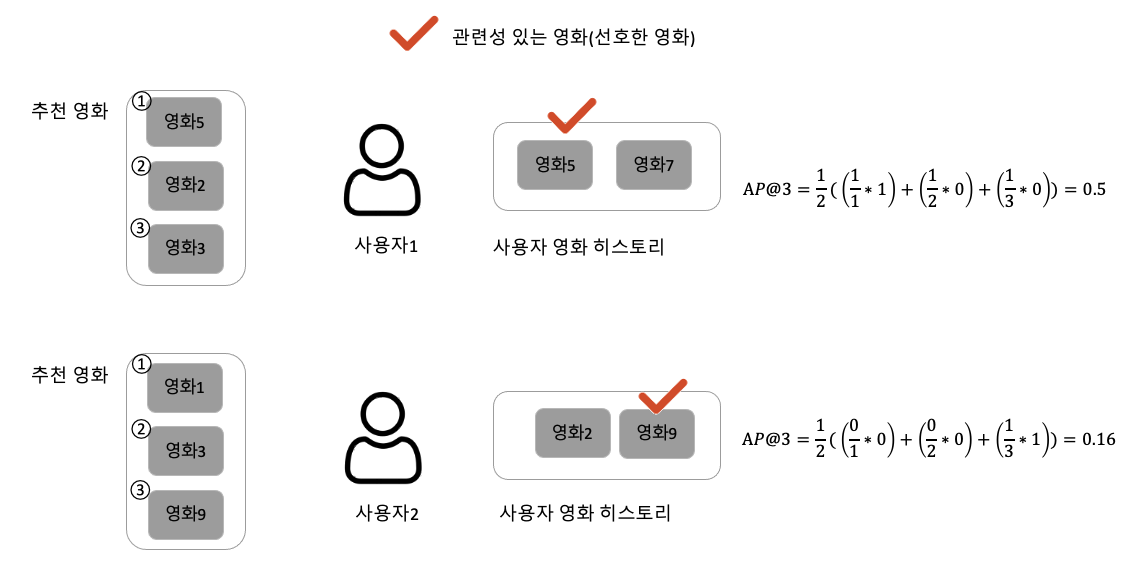
[사용자1]
위 예시에서는 2명의 사용자가 있습니다. 사용자1은 추천 시스템에게 영화5, 영화2, 영화3을 추천 받았습니다. 사용자 1은 영화5, 영화7을 보았던 히스토리가 있고 그 중 영화 5를 선호하였습니다. 만약, Average Precision@2을 구해야한다면, Precision@1 * rel(1) + Precision@2*rel(2)를 구해야합니다. 그렇기에 사용자1의 AP3을 구해보면, 먼저 사용자 히스토리가 2개이니 m=2가 됩니다. Precision@1일 때 영화를 보면 추천 시스템은 영화5를 추천해줬는데 사용자가 상호작용한 것에 포함됩니다. 따라서, Precision@1에서 보면 1/1이고 또한, 관련성도 있기에 1까지 곱해집니다. 하지만, 추천 시스템이 제공한 영화2, 영화3은 사용자 히스토리에도 매칭이 되지 않고 관련성도 없으므로 각각 (1/2 *0), (1/3 * 0)이 되어 최종적으로 0.5라는 값이 나오게 됩니다.
[사용자2]
사용자 2는 영화 히스토리가 영화2, 영화9가 있습니다. Precision@1의 관점에서 봤을 때 추천 시스템이 추천한 영화1은 사용자2의 상호작용 히스토리에 없습니다. 따라서 Precision@1은 0/1이 되고 관련성도 없기에 0이 곱해집니다. Precision@2도 마찬가지입니다. 추천 시스템이 추천한 영화3은 사용자 히스토리에 없기 때문이죠. 하지만, 마지막 3번째 영화9는 사용자 히스토리에 존재합니다. 선호도도 있어 (1/3 *1)의 값이 나오게 되고 최종 Average Precision은 0.16이 나오게 됩니다.
두 사용자의 특징은 무엇일까요? 똑같이 추천 시스템의 결과가 1개씩만 매칭되었는데, 순서에 따라 0.5 그리고 0.16이 되었습니다. 즉, Average Precision은 추천 시스템이 추천한 아이템의 랭킹에 따라 평가 메트릭(지표)에 영향을 주는 것을 볼 수 있습니다.
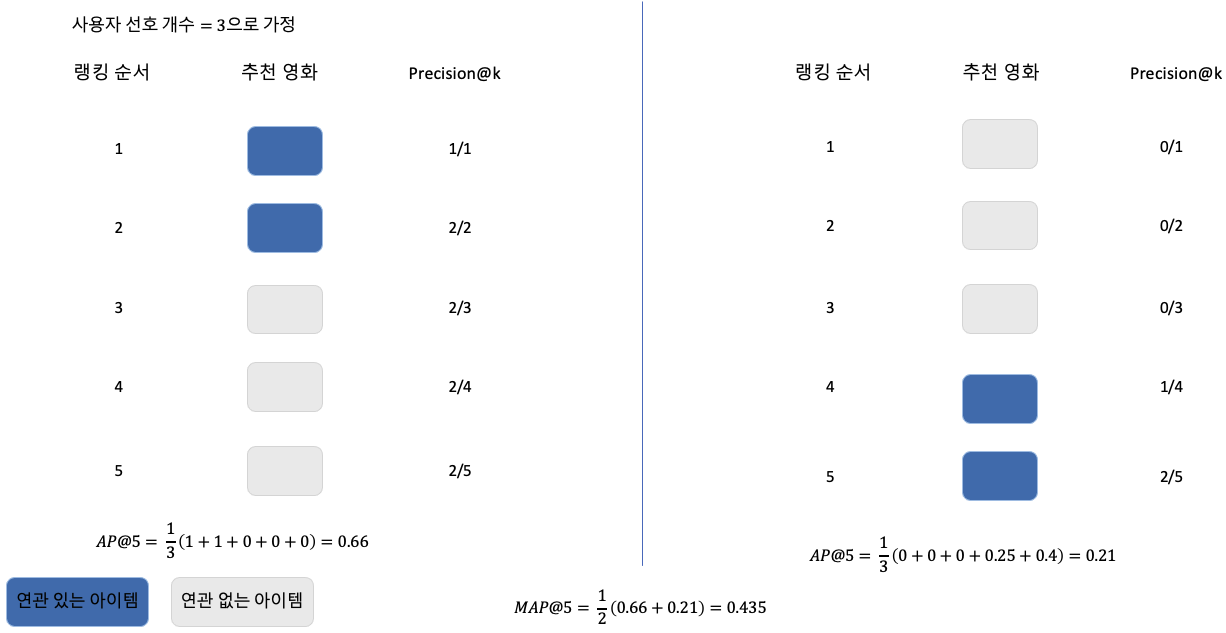
하나의 예시를 더 살펴보겠습니다. 위 예시에서는 사용자 선호 개수를 3으로 지정하겠습니다(m=3). 이때 2명의 사용자가 있는데, 둘 다 똑같이 추천 영화 중 2개를 선호했습니다. 다만, 왼쪽 사용자는 추천 시스템이 제공한 아이템 랭킹1, 랭킹2를 선호했고 오른쪽 사용자는 랭킹4, 랭킹5를 선호했습니다. 즉 추천 시스템은 2번 째 사용자에게 맞춤으로 잘 제공을 못 한 것이죠. 그렇기에 Average Precision 지표를 보면 왼쪽 사용자는 AP@5가 0.66이 나오게 되고 오른쪽 사용자는 0.21이 나오게 됩니다. 즉, 순서가 중요한 것이죠.
그러면 Mean Average Precision(MAP)는 어떻게 구할 수 있을까요? 바로 0.66 + 0.21을 더하고 사용자 수로 나눈 즉, 2로 나눈 값이 바로 추천 시스템 평가 MAP의 값입니다.
NDCG@K ( Normalized Discounted Cumulative Gain )
이제 본 포스팅에서 소개하는 마지막 추천 시스템 평가 지표 NDCG입니다. NDCG는 한 문장으로 요약하면 "가장 이상적으로 추천했응ㄹ 때 대비 랭킹 기반으로 추천이 잘 제공되었는가?"로 요약할 수 있습니다. NDCG도 MAP와 마찬가지로 이해하려면 각 단어 하나하나를 살펴보아야 합니다. 먼저, Cumulative Gain(CG)을 알아야하고 그 다음으로 Discounted CG(DCG) 그리고 IDCG를 알아야 NDCG를 이해할 수 있습니다.
Cumulative Gain(CG)와 DCG(Discounted Cumulative Gain)
추천 시스템 평가 지표인 NDCG를 이해하기 위한 첫 스텝으로 Cumulative Gain(CG)를 이해해야합니다. CG는 누적된 획들을 가진 뜻으로 '순서를 고려하지 않은 추천한 아이템의 관련성 합'이라고 이해하시면 됩니다. 수식으로 표현하면 다음과 같습니다.
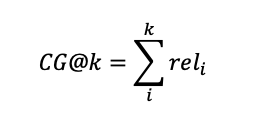
즉, Average Precision에서 살펴보았던 관련성의 값들을 합치는 것으로 이해할 수 있습니다.
그러면 DCG는 무엇일까요? DCG는 이 CG식에서 순서를 고려한 값으로 이해하면 됩니다. CG이 수식에 log 값을 넣어서 분모가 커지게 되면 값이 작아지므로 뒤에 나온 값에 대한 영향도를 줄이는 것을 반영해줍니다. 수식으로 표현하면 다음과 같습니다.
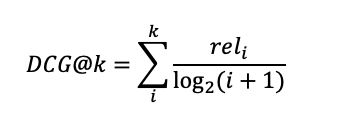
Ideal DCG(IDCG)와 NDCG
이제 NDCG를 구하기 위한 과정으로 IDCG를 이해하면 됩니다. IDCG는 최적의 추천을 했을 때 받는 DCG의 값을 의미합니다. 즉, 가장 최고의 추천이 되었을 때 받을 수 있는 DCG인 것이죠. 따라서, 다음과 같은 수식을 가지고 있습니다.
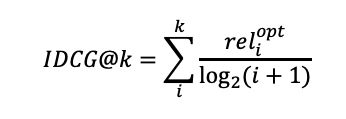
이 IDCG까지 구했으면 NDCG는 DCG/IDCG의 값으로 구할 수 있게 됩니다. 즉, 가장 최적의 추천일 때 대비 랭킹 기반으로 추천이 잘 이루어졌는지를 그 값을 뽑아내는 것이죠.
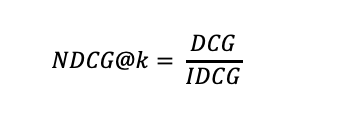
자, 그럼 여기까지 내용들을 살펴보았을 때 NDCG를 이해할 수 있으실까요? 아마도 부족하실 것 같습니다.
NDCG도 MAP 때와 마찬가지로 구체적인 예시를 통해 더 명확하게 이해해보도록 합시다.
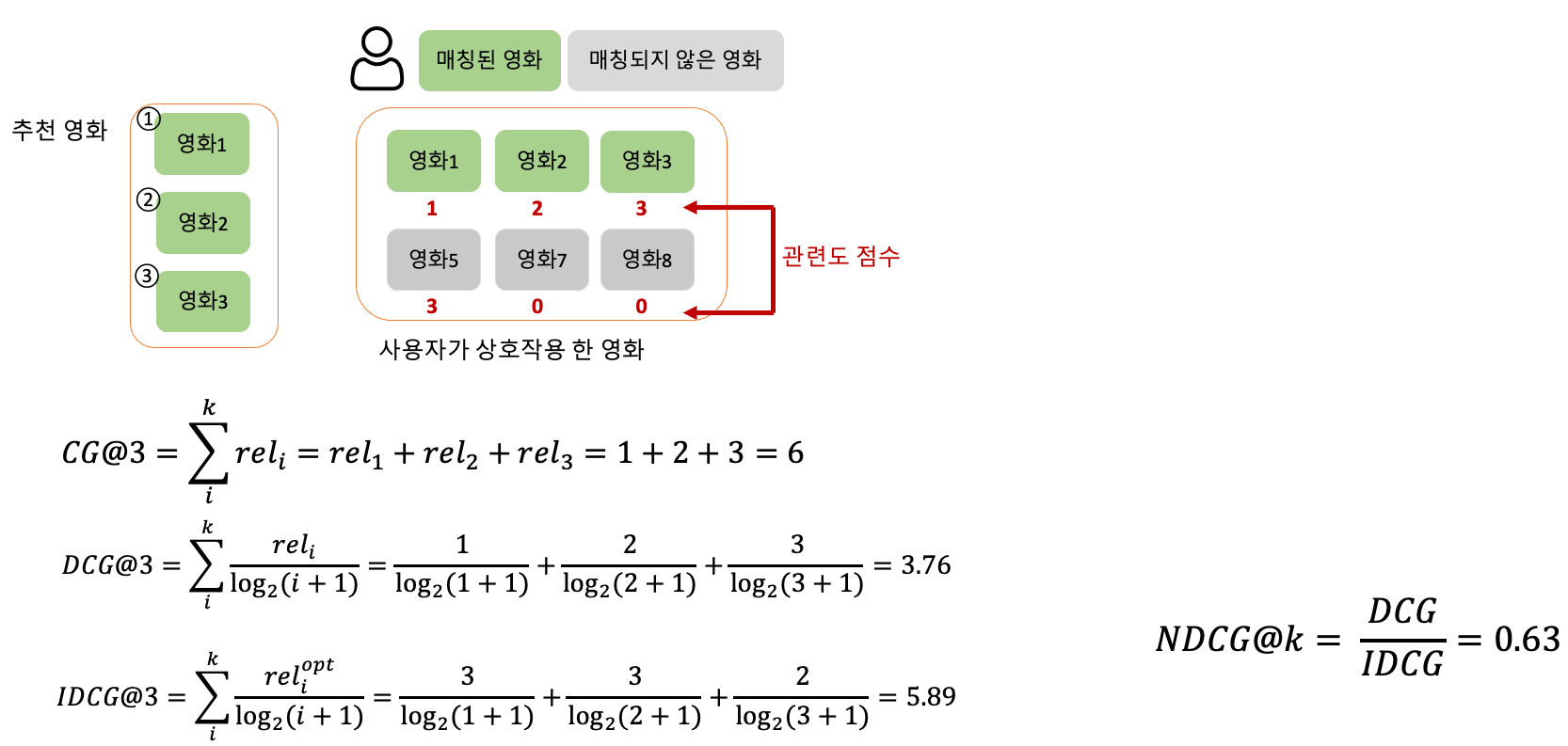
위 그림은 NDCG의 예시입니다. 먼저, 추천 시스템은 추천 영화를 3개(영화1, 영화2, 영화3) 제공해주었습니다. 사용자는 총 6개의 영화와 상호작용을 했고 각 영화에 대해 관련도 점수(선호도 점수 등)가 부여되어 있습니다. 이때 NDCG를 구해봅시다.
- Cumulative Gain(CG)를 먼저 구해야합니다. CG는 추천한 아이템의 관련도의 합이라고 설명드렸습니다. 즉, 추천 영화가 영화1, 영화2, 영화3이었고 각 관련도가 1, 2, 3이었으니 1+2+3 = 6의 값이 나오게 됩니다.
- 다음으로 Discounted CG(DCG)를 구합니다. DCG는 CG에 log를 취한 것으로 랭킹을 반영하게 됩니다. 또한, @K가 올라감에 따라 log의 값이 커지게 되죠. 따라서, 3.76이라는 값이 나오게 됩니다.
- 다음으로 Ideal DCG(IDCG)를 구합니다. IDCG는 최적의 추천을 했을 때 받는 DCG 값입니다. 최적의 추천을 이 사용자에게 하는 것은 무엇이었을까요? 바로 관련도 점수가 가장 높은 영화3, 영화5, 영화2를 추천하는 것이 최적이었겠죠? 따라서, 영화3, 영화5, 영화2의 관련되 점수를 기준으로 DCG를 구한 것이 IDCG이며 그 값은 5.89입니다.
- 마지막으로 NDCG를 구합니다. NDCG는 DCG/IDCG 이므로 0.63이 나오게 됩니다.
마무리
이번 포스팅에서는 추천 시스템 평가 지표를 정리해보았습니다. 다양한 추천 시스템 평가 지표 중에서 NDCG, MAP, Hit Rate에 대해서 정리하였고 이를 위해 Precision, Recall과 @K에 대한 설명도 정리하였습니다.
본 포스팅의 내용이 여러분들의 학습에 도움이 되길 바랍니다.
감사합니다.



