
포스팅 개요
이번 포스팅은 추천 시스템 방법 중 추천(Recommendation)을 위해 개인화를 고려한 LLM 모델 및 방법을 소개한 PALR: Personalization Aware LLMs for Recommendation 논문을 리뷰하고 정리하는 포스팅입니다.
대규모 언어 모델(Large Language models, LLM)을 활용한 다양한 추천 시스템 방법들이 소개되고 있는데요. 본 논문은 LLM을 통해 사용자 정보를 추출하고 LLM에서 발생할 수 있는 할루시네이션 등을 방지할 수 있도록 후보 셋을 제공하는 등의 방법론을 제시합니다. 또한, 저자들은 추천 시스템을 수행하기 위한 LLM 파인튜닝(fine-tuning) 방법도 소개합니다. 본 논문은 저자들이 아마존 알렉사(Amazon Alexa) 소속인 것이 큰 특징이며 본 논문을 통해 해당 조직에서 고민하고 있는 추천 시스템과 LLM의 결합에 대해서 간접적으로나마 살펴볼 수도 있습니다. 본 논문은 아래 링크에서 확인할 수 있습니다.

포스팅 본문
본 포스팅은 추천 시스템을 위해 개인화를 고려한 LLM 모델 및 방법을 소개한 논문, PALR(Personalization Aware LLMs for Recommendation)을 리뷰하는 포스팅입니다. 먼저, 논문의 핵심 요약부터 정리한 후 논문이 진행되는 순서대로 Introduction부터 실험 결과까지 살펴보겠습니다.
논문 핵심 요약
본 논문은 클릭, 구매, 평점과 같은 사용자 행동 이력을 대규모 언어 모델(Large Language Models, LLM)과 통합하여 사용자가 선호하는 아이템 리스트를 생성하는 PALR(Personalization Awareness LLMs for Recommendation)을 소개합니다. 이때, 사용자 아이템 상호 작용을 사용해서 후보 검색(candidate retrieval)을 검색하기 위한 가이드로 사용하고 그 다음 LLM 모델 기반 랭킹 모델을 사용해 추천 리스트를 생성하도록 제안합니다. 이때 저자들은 llama 7b 모델을 사용해서 파인 튜닝(fine-tuning)을 진행해서 랭킹 모델을 구성합니다.
이때, 아래와 같이 3가지 핵심 과정을 수행합니다. 1) Natural Language user profile 과정은 사용자의 선호도를 추출하는 프로세스이며, 사용자의 과거 히스토리를 활용해 추출합니다. 2) Candidate retrieval 과정은 할루시네이션 등의 LLM의 불완전성을 해결하기 위해 LLM 모델에게 후보 셋을 제공해주는 것입니다. 이때, retrieval model로는 다양한 모델을 사용할 수 있습니다. 3) Item recommendation 과정은 사용자 interaction과 프로필, candidate set(후보셋)에 기반해서 prompt를 생성해 LLM에 넣어줘 랭킹을 수행하게 합니다.
논문의 핵심 요약은 위와 같습니다. 이제 본 논문의 주요 내용을 상세하게 살펴보겠습니다.
Introduction
저자들은 LLM을 추천 시스템에 사용하면 몇 가지 장점을 보인다고 말합니다.
1) LLM을 사용하면 아이템에 대해 사전에 훈련된 임베딩(pre-trained embeddings)의 필요성을 무효화할 수 있고 아이템을 텍스트로 표시할 수 있습니다. 이 장점은 특히, 새로운 아이템이 지속적으로 등장하는 industry에서 중요하다고 합니다.
2) LLM을 사용하면 메타데이터, 컨텍스트와 같은 다양한 데이터를 모델의 프롬프트(prompt)에 활용해서 recommendation process에 쉽게 통합할 수 있다고 합니다.
3) LLM은 광범위한 사전 훈련(extensive pre-training)을 통해 가지고 있는 방대한 지식과 우수한 추론(reasoning) 능력을 보유하고 있습니다. 이에 사람이 읽을 수 있는 설명으로 추천을 제공해서 사용자의 신뢰(trust)와 참여(engagement)를 향상 시킬 수 있다고 합니다.
그러나 저자들은 범용 목적(general purpose) LLM에 저장된 지식을 직접 활용해 추천 아이템을 생성하는 것은 어렵다고 하는데요. 그 이유는 아래와 같습니다.
1) LLM과 추천 해야할 아이템 사이의 지식 차이(knowledge gap)이 있을 수 있습니다. 예를 들어서 새로 출시된 아이템은 LLM이 모를 수 있죠.
2) LLM은 불완전하고 할루시네이션 결과를 생성하는 경향이 있습니다.
3) LLM은 입력 토큰 길이와 더불어 효율성에 대한 제한이 있습니다. 그렇기 때문에 최근 연구들에서는 LLM을 recommendation system의 시나리오 지식 기반이 아닌, 요약(summary) 및 추론 엔진(reasoning engine)으로 다루고 있었다고 합니다.
따라서, 저자들은 본 논문에서 사용자 행동과 LLM을 결합한 개인화 된 추천 방법인 PALR을 제안합니다. 처음에는 사용자 행동(user behavior)을 LLM의 입력으로 넣어 사용자 프로필 키워드를 생성하고 이후 검색 모듈을 사용해 사용자 프로필을 기반으로 아이템 풀에서 후보 아이템(candidate item)을 필터링합니다. 최종적으로 LLM을 사용해 사용자 행동 히스토리를 기반으로 candidate로부터 추천을 제공하게 됩니다. 이때 사용되는 LLM은 일반적으로 범용적으로 사용되는 LLM(general-purpose LLM)을 recommendation에 맞게 조절하기 위해서 파인튜닝(fine-tuning) 작업을 진행합니다. 이를 통해 사용자 행동 데이터를 LLM의 reasoning process에 통합하고 사용자와 unseen item에 대해 효과적으로 일반화 할 수 있다고 말합니다.
방법론
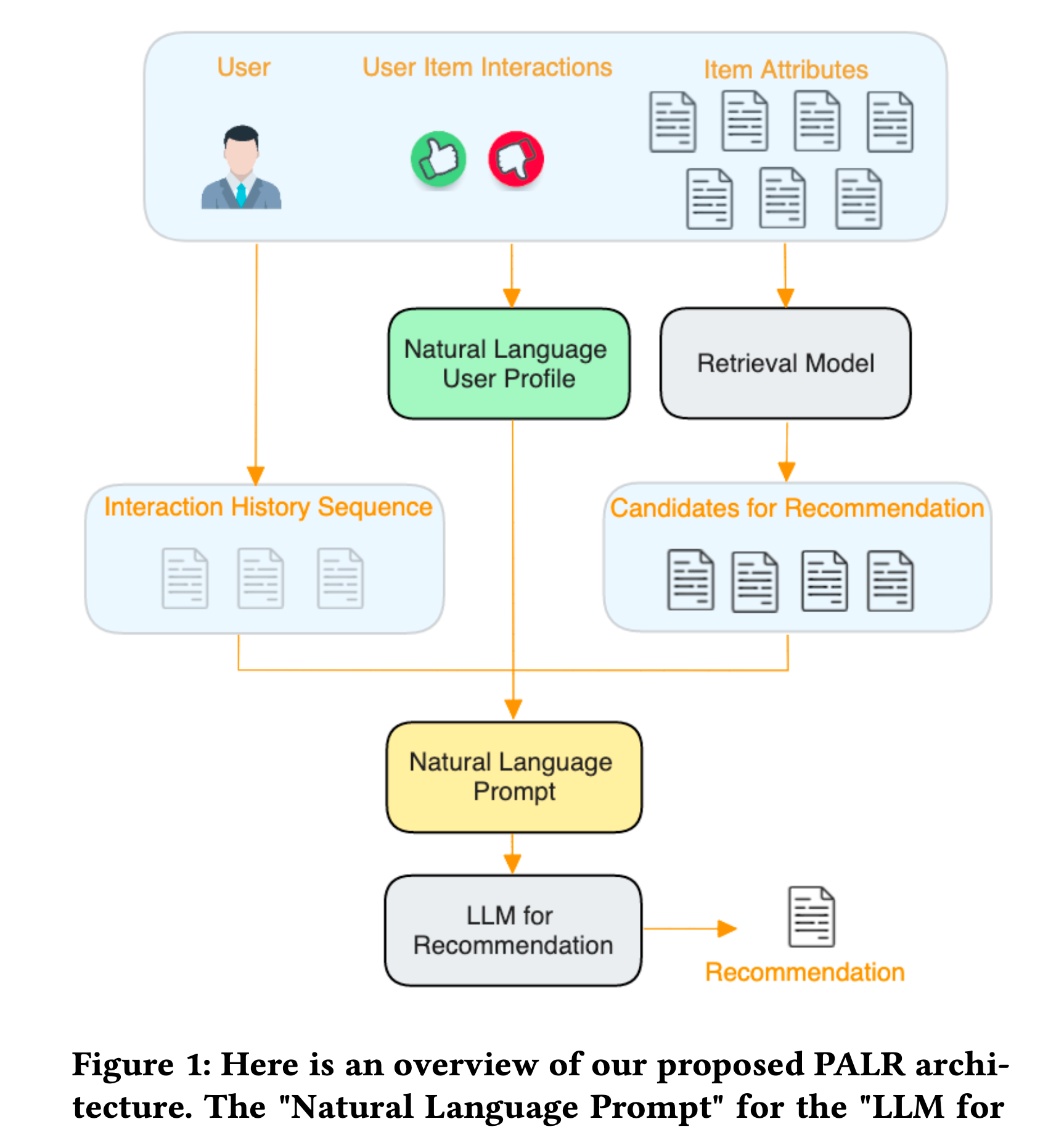
PALR Framework
Figure 1은 저자들이 제시한 PALR 프레임워크입니다. 저자들이 제시한 추천 시스템을 위한 LLM 프레임워크를 보면, 중요한 3개의 스텝이 있는데요. 하나는 Natural Language User Profile이라고 칭하는 초록색 박스 부분입니다. 두 번째는 Candidate retrieval이며, 마지막 세 번째는 아이템을 추천하는 Item recommendation 파트입니다. 각 기능이 무엇인지 하나하나 살펴보겠습니다.
Nature Language user profile generation(자연어로 생성하는 사용자 프로필)
사용자가 다양한 아이템들과 상호작용하고 복잡해지면 사용자 행동 데이터만을 사용해 정확한 추천을 제공하는 것이 어려울 수 있습니다. 이런 상황에서는 어찌보면 사용자 선호도를 요약(summarization)하는 것이 나을 수 있죠. 저자들은 대규모 언어 모델(LLM)을 활용해서 사용자의 선호도를 요약하는 방법을 제시합니다. 예를 들어서, 사용자의 음악 및 TV 시청 기록을 분석해 '팝 음악'을 선호한다던가, '판타지 영화'를 선호한다던가 등의 요약을 생성할 수 있죠. 사용자 선호 프로필은 아래와 같은 prompt를 사용해 추출했다고 저자들은 말합니다.

Candidate retrieval(후보 검색)
LLM이 가지고 있는 본질적인 문제인 할루시네이션(환각)과 불완정성 문제를 해결하기 위해 검색 모듈을 사용합니다. LLM이 가지고 있는 지식을 사용하되, 후보 기반으로 필터링해서 관련이 없는 결과가 나오지 않도록 하는 것이죠. 이때 사용되는 후보 모델은 sequential recommendation model과 같은 다양한 모델을 사용할 수 있습니다.
Item recommendation(아이템 추천)
사용자의 아이템 상호작용 히스토리와 LLM이 생성한 사용자 프로필(Natural Language user profile) 그리고 검색된 후보 셋(retrieved candidates)를 결합해 추천을 위해 LLM에 제공할 수 있는 프롬프트(prompt)를 생성할 수 있습니다. LLM 모델은 reasoning 능력을 기반해서 후보 풀ㄹ에서 사용자 프로필에 가장 잘 맞는 아이템을 선택해 추천을 진행하게 됩니다. 사용자 프로필을 LLM으로 생성하는 프로세스와 마찬가지로 아이템 추천 단계에서도 LLM에 들어갈 prompt 설계가 필요하게 됩니다. 이 프롬프트 디자인은 다음, 파인튜닝 단계에서 살펴보겠습니다.
파인튜닝(Fine-tuning)
저자들은 1) 합리적으로 좋은 성능을 획득할 수 있고 2) 우리가 예상한대로 검색을 수행하게 하려면 파인튜닝(fine-tuning) 과정이 필요하다고 말합니다. 저자들은 그 중 instruction-base fine-tuning을 진행했다고 합니다. 저자들은 이 파인튜닝 단계에서 Recommend와 Recommend_Retrieval 두 가지 유형의 instruction을 만들었습니다.
Recommend
Recommend 작업에는 사용자가 과거에 interaction한 아이템 목록이 최대 20개까지 표현되며, 이 작업에서의 모델의 목표는 사용자가 interaction할 'future' 아이템 리스트를 생성하는 것입니다.

위 사진은 recommend fine-tuning 유형에서 사용하는 LLM의 prompt 예제입니다. Task Instruction에는 recommend 10 other movies base on user's watching history 즉, 사용자 히스토리 기반으로 10개의 영화를 추천하라는 instruction 문구가 있습니다. 입력 값으로는 사용자가 봤던 영화 히스토리를 넣어주고 그 결과로 사용자가 미래에 interaction 할 아이템 리스트를 추천하도록 프롬프트를 설계해뒀습니다. 저자들은 이를 PALR-v1이라고 칭합니다.
Recommend_Retrieval
Recommend_retrieval이라고 불리우는 작업은 candidate items 목록에서 사용자가 미래에 상호작용할 아이템을 검색(retrieval)하도록 프롬프트를 셋팅합니다. candiate items 목록에는 후보로 지정된 아이템과 더불어서 negative item도 넣어져 있습니다.

위 사진은 Recommend_retrieval 작업의 LLM 입력으로 넣는 prompt 예시입니다. 앞서 살펴본 Recommend와 차이가 있는 것을 알 수 있는데요. Task Instruction 메세지를 보면 Recommend 10 other movies based on user's watching history from the candidate list로 되어 있습니다. 즉, 사용자 히스톨 기반으로 10개의 영화를 추천하라는 것인데, 후보 리스트에 기반해서 추천하라는 것이죠. 그렇기에 Input에는 사용자가 과거에 interaction 했던 아이템 리스트 뿐만 아니라, candidates 리스트도 넣어주고 있습니다. output은 사용자가 interaction 할 아이템들을 추천하도록 리스트업 하는 것이죠. 저자들은 이를 PALR-v2라고 지정합니다.
저자들은, fine-tuning 과정이 retrieval-layer에 종속되지 않다는 것을 강조합니다. fine-tuning을 위한 목록의 구성은 retrieval layer와 바운딩 되어 있지 않는 것이죠. 또한, 사용자의 20%에 대해서만 파인튜닝을 진행했다고 저자들은 말합니다.
실험 결과
저자들은 개인화 추천 시스템을 구성하기 위해 개인화를 고려한 LLM 방법을 2개의 데이터 셋으로 평가를 진행합니다.
데이터 셋은 Amazon beauty 데이터 셋과 다른 하나는 MovieLens-1m 데이터 셋입니다. 저자들은 이 데이터를 리뷰나 평가가 있으면 1, 아니면 0의 형식으로 변환하고 사용자가 interaction 했던 아이템을 시간 순서대로 정렬해 사용했습니다. 또한, 5개 미만인 사용자나 아이템은 삭제하였다고 합니다.
평가는 NDCG(Normalized Discounted Cumulative Gain)과 HR(Hit Ratio)를 사용했으며, baseline 모델들은 BPR-MF, NCF, GRU4Rec, Caser, SASRec과 비교하여 평가를 측정했습니다.
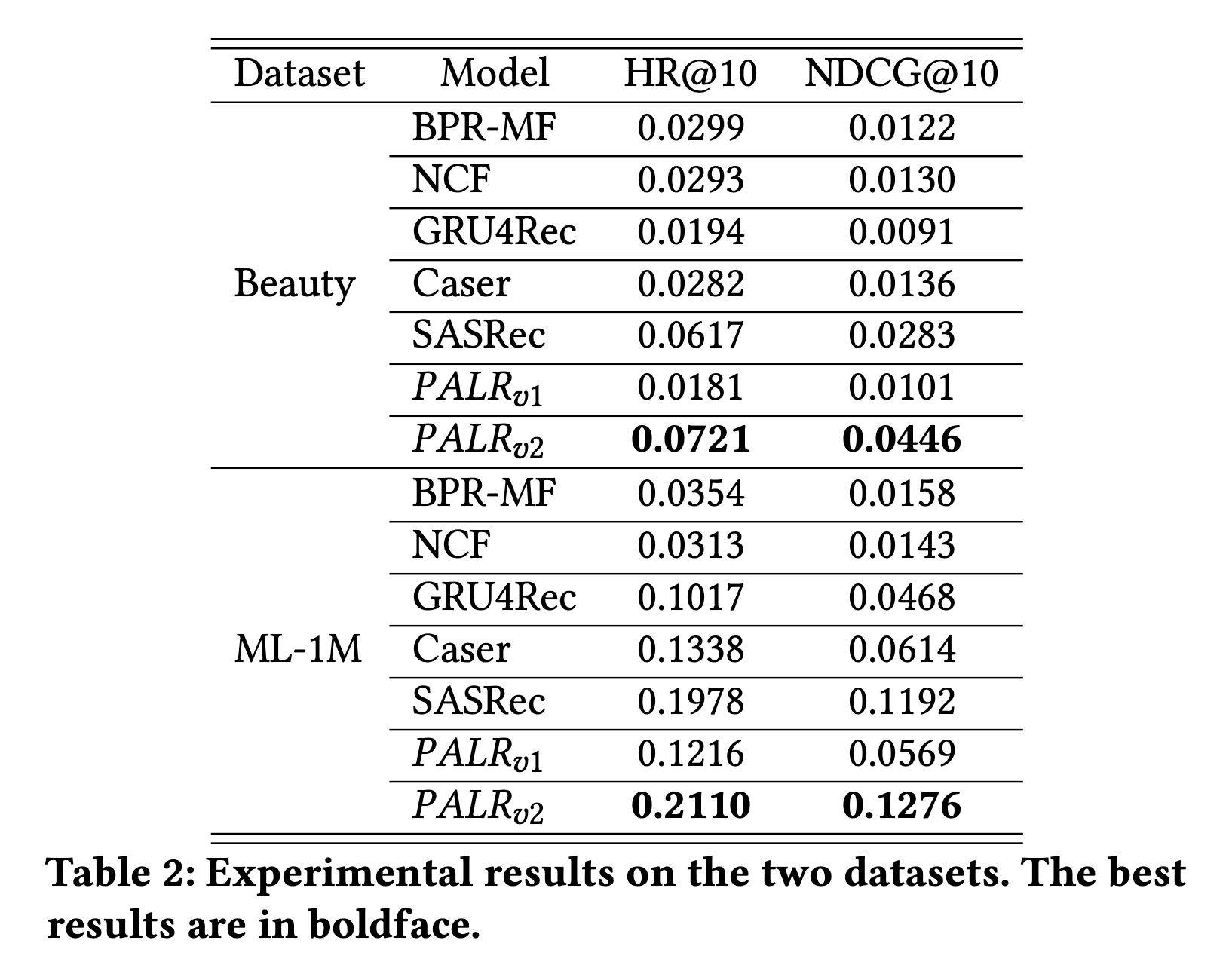
Table 2는 저자들이 실행한 실험의 결과를 보여줍니다. PALR-v2는 다른 모든 베이스라인 모델보다 두 개의 데이터 셋 모두에서 뛰어난 성능을 보여주는 것을 알 수 있습니다. PALR-v1과 v2를 비교해 봤을 때 후보 셋을 제공해주는 것이 중요하다는 것도 알 수 있죠. 저자들은 이상적으로 다양한 retrieval 방법과 PALR이 결합되어 효과적인 ranking model의 성능을 보여줄 수 있다고 하는데요. 저자들은 여기서 retrieval 모델을 SASRec를 사용했다고 합니다.
그렇다면 SASRec와 PALR-v2의 성능 비교는 어떨까요? PALR-v2가 성능이 더 좋게 나오는데 이는 SASRec에서 제공하는 추천 결과보다 LLM을 적용 했을 때 더 우수하게 나왔다는 것을 보여줍니다.
또한, 저자들은 fine-tuning에 대해서 중요한 고찰을 얻을 수 있었다고 하는데요. PALR-v1의 경우 fine-tuning 이전에는 추천 시스템 역할로써 인기 영화만 추천하는 경향이 있었다고 합니다. 하지만, fine-tuning 이후 LLM 모델은 사용자와 아이템 간의 미래에 상호 작용할 것을 고려해 추천을 해주는 것을 확인할 수 있었다고 합니다. 또한, PALR-v2는 additional instruction의 효과를 입증한 것도 보여줍니다.
결론 및 마무리
본 포스팅은 대규모 언어 모델(LLM)이 개인화된 추천을 생성하기 위한 프레임우크인 PALR 논문을 정리한 포스티입니다. 저자들은 추천 시스템 작업에서 LLM을 사용하는 이점을 1) 다양한 외부 지식을 쉽게 통합할 수 있다는 것 2) 복잡한 추천 시스템 시나리오에서 더 쉬운 경로(easier pathway)를 제공할 수 있다는 것입니다. 예를 들어서, 설명가능성(explainable)과 같은 것이 되겠죠.
저자들이 고민한 PALR 프레임워크를 기반으로 recommender system 영역에 LLM을 어떻게 통합하고 활용할 것인지에 대한 인사이트를 얻으셨으면 좋겠습니다.
긴 글 읽어주셔서 감사합니다.
저에게 연락을 원하신다면,
- 링크드인 : https://www.linkedin.com/in/lsjsj92/
- github : https://github.com/lsjsj92
- 댓글 또는 방명록
으로 연락주세요!



