포스팅 개요
이번 포스팅은 자연어처리(nlp) 논문 중 ELECTRA : Pre-training Text Encoders as Discriminators Rather Than Generators 라는 논문을 리뷰하는 포스팅입니다. 본 논문은 ELECTRA 라고 많이 알려진 논문인데요. 앞서 GPT와 BERT 시리즈 등 리뷰에 이어서 진행하는 자연어처리 논문 포스팅 시리즈 여섯 번 째 포스팅입니다.
자연어처리 논문 리뷰는 아래와 같은 순서로 진행할 예정입니다. 오늘은 그 마지막 글인 여섯 번째 ELECTRA 입니다.
GPT-1 (https://lsjsj92.tistory.com/617 )
BERT (https://lsjsj92.tistory.com/618 ) GPT-2 (https://lsjsj92.tistory.com/620 )
RoBERTa ( https://lsjsj92.tistory.com/626 ) ALBERT ( https://lsjsj92.tistory.com/628 )
ELECTRA
참고한 자료는 아래와 같습니다.
포스팅 본문
ELECTRA 논문 리뷰는 아래와 같은 순서로 진행합니다.
1. ELECTRA 핵심 요약
2. ELECTRA 논문 리뷰
ELECTRA 핵심 요약
Pre-training 에 focus 를 맞춤
• Replaced token detection 방법으로 효율적인 pre-training 진행 제안
마치 GAN 과 비슷한 구조
• Generator
• MLM 에서 나온 단어를 replace 시킴
• Discriminator
• 모든 단어를 보면서 원본인지 아닌지 식별
• 그러나 GAN 과는 다른 구조
• Generator 는 Maximum likelihood 로 학습함
• Adversarial( 적대적 ) 하게 학습하지 않음
• Text 는 Adversarial 이 쉽지 않음
• G < D 구조임
• 같은 사이즈의 경우 B
Weight sharing
• Embedding layer 만 공유함
• 모든 layer 를 공유하려면 G, D 가 같은 size 여야 함
• BERT 의 2 배급 이므로 메모리 등에서 좀 비효율 적
• 본 논문에서는
• G < D ( ¼ ~ ½ ) 하고 Embedding 층만 sharing
더욱 효과적인 구조
• Model learns from all input tokens rather than just small subset that was masked out
• 컴퓨팅도 적고 성능이 좋게 나옴
와 같이 ELECTRA는 요약할 수 있습니다. 이제 논문을 리뷰해봅니다!
ELECTRA 논문 리뷰
Introduction
기존의 Masked Language Model
• Compute cost 가 발생함
• 15% 만 학습하기 때문에
본 논문은 Replaced Token Detection 도입
• MASK 대신 replacing some token 으로 대체
• Pre-train 과 fine-tuned 의 [MASK] mismatch 해결
• Discriminator
• 모든 token 을 original 인지 아닌지 Predict 수행
• Generator
• Predicts the original identites 를 수행
• 즉 , replacing some token 을 제대로 수행하도록 진행
• Original 로 replacing 될 수 있도록
효율성 증대
• 모든 토큰을 학습하므로 computational 효율 획득
• Model learns from all input tokens instead of small masked out subset
GAN 과 비슷한 구조
• 하지만 , GAN 은 아님
• Adversarial 하게 학습하지 않음
• Generator 는 Maximum-likelihood 로 학습함
• GAN 을 Text 에 적용시키는게 쉽지 않기 때문
이러한 방법을 ELECTRA 라고 함
• 성능 뿐만 아니라 compute efficiency 를 고려
• Same size, data, compute 를 가지고도 기존 모델 능가
• ELECTRA-SMALL 은 1 GPU 로 4 일이면 끝남
• SMALL 은 BERT-small, GPT 보다 좋음
Method Generator 와 Discriminator 구조
• Transformer Encoder 구조를 가지고 있음
• G 는 xt 의 probability 를 softmax layer 로 도출
• D 는 G 에서 넘어온 xt 가 fake 인지 예측
• Sigmoid
이 구조는 마치 GAN 처럼 보임
• Generator 는 Maximum likelihood 를 학습함
• 적대적 ( Adversarially ) 방법이 아님
• Text 는 GAN 적용이 쉽지 않기 때문
• Pre- trianing 후에는 Generator 는 버림
• Only fine tune discriminator on downstream task
Generator
• Masked Language Modeling(MLM) 수행
• Random position(1 ~ n) 을 선택
• 선택된 position 은 [MASK]
• MASK 된 것을 예측
Discriminator
• Replaced by generator sample 을 구분하는 것을 학습
• Original input 과 match
GAN 과의 차이점
• Generator 가 생성한 것을 real 로 간주
• Fake 로 간주하는 것이 아님
• Generator 는 maximum likelihood 로 학습함
• Descriminator 를 속이는 것이 아님
• Adversarially 하게 학습하는 것은 backpropagate 가 어려움
• Noise vector 를 input 으로 Generator 에 넣지 않음
Experiments 실험에서는 총 5가지의 하위 섹션으로 나뉘어집니다. 그 하위 섹션 목록은 다음과 같습니다.
- Experimental Setup
- Model Extension
- Small Models
- Large Models
- Efficiency analysis
3-1. Experimental Setup
Data
• XLNet data 를 활용
• BERT 에서 ClueWeb , CommonCrawl , Gigaword 추가
3-2. Model Extensions
Weight Sharing
• Generator 와 Deiscriminator 사이에 weight sharing
• pre- trianing 의 efficiency 를 증가시키기 위해
• Small generator + only share embedding 이 효과적
• All weight 가 제일 성능이 좋았음
• 단 , same size 로 해야하는 불이익
• ELECTRA 는 tied token embedding 에서 효과를 얻음
• MLM 은 이러한 표현을 학습하는데 효과적
• Generator 는 모든 token embedding 을 densely 하게 update
• ( 제 생각 ) G 는 모든 단어에 대해서 바라봄
• MLM 으로 15% 선택되는데 이 선택된 것만 D 는 바라봄
• 즉 , 공평하게 튜닝할 기회는 MLM 뿐
• 그래서 Embedding 을 공유
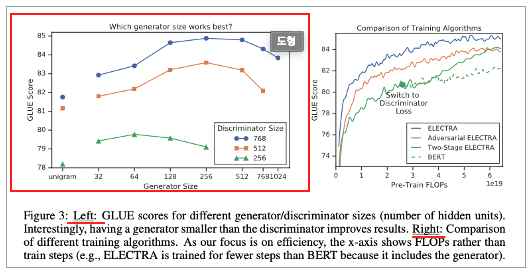
Smaller Generators
• 만약 G, D 가 같은 사이즈일 경우
• ELECTRA 는 2 배의 compute 가 들어감
• Smaller Generator 가 이런 factor 를 줄일 수 있음
• Layer 사이즈만 줄이고 다른 하이퍼 파라미터는 유지
• Smaller Generator 의 불리함 ?
• 500K 로 전부 학습
• Smaller Generator 는 less compute 가 요구 됌
• 따라서 compute 측면에서 불리함
• 실제 결과는 ?
• Generator 가 Discriminator 의 ¼ ~ ½ 정도에서 가장 좋음
• 왜일까 ?
• Generator 가 너무 강하면 Discriminator 에게 매우 어려운 과제
• 너무 어려워서 오히려 효과적인 학습을 방해한다고 추측함
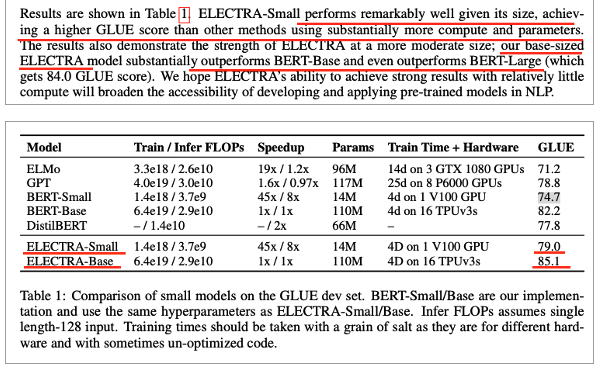
Training Algorithms
• 기본은 Generator 와 Discriminator 를 joint training
• 다른 알고리즘 제안
• 하나는 Two-stage 방법
• 1. Generator 만 훈련시킨 후
• 2. Discriminator 의 weight 를 Generator 것으로 초기화 이후 , Generator weight 는 frozen 하고 D 를 training
• 초기화 후 성능이 쭉 올라감
• 다른 하나는 Adversarial ELECTRA
• 강화학습 (reinforcement learning) 적용
• 안 좋음
• 이러한 Weight initialization 은
• generator 와 discriminator same size 요구
• Weight initialization 이 없으면
• Discriminator 는 때때로 다수 계층을 넘어서는 학습에 실패
• Generator 가 이미 훨씬 앞서가 있기 때문
3-3. Small Models
Small model 비교
• 본 연구의 목적 !
• Improve the efficiency of pre-training
• Single GPU 에서 빠른 학습이 되는 small model 개발
• 결과
• ELECTRA small 은 higher score 달성
• More compute, parameter 모델보다 더 높게
• BASE 모델은 BERT-BASE, LARGE 도 이김
3-4. Large Models
Large model 비교
• Pre-trained Transformer SOTA 모델과 비교
• ELECTRA-Large
• BERT-LARGE 와 같은 크기
• 단 , trained much longer
• (400k step, 2048 batch size, XLNet data)
• 결과
• 현 SOTA RoBERTa 와 match 가능
• RoBERTa 때와 마찬가지로 compute 가 ¼ 소요
• 100K RoBERTa 보다 더 좋고 XLNet 능가
• Compute 양이 비슷함
• 기본 BERT 모델은 RoBERTa-100k 보다 안 좋음
• 아래와 같은 이점을 얻을 수 있음을 시사
• 더 많은 hyperparameter tuning
• 또는 , RoBERTa training data
3-5. Efficiency Analysis
Efficiency analysis
• 저자들이 주장한 것
• Small subset of tokens masked language modeling 이 비효율적
• 하지만 , 이것이 사실인지 불명확함
• 소수만 예측하더라도 많은 수의 input tokens 를 받기 때문
• ELECTRA 의 이점이 어디에서 오는지 다른 pre-training objective 와 비교
• 다른 pre-training object
• ELECTRA 15%
• ELECTRA 와 동일
• 단 , Discriminator loss 가 only 15% masked out input token 에서 발생
• 토큰 학습 효율 때문에 성능 차이가 생겼는가 ? 를 확인
• 기존에는 D 가 100% 다 봤지만 여기선 15%
• Replace MLM
• MASK 토큰을 [MASK] 로 교체하는 대신 replaced with token from generator
• Pre-training 과 fine-tuning 의 불일치를 해결함으로써 ELECTRA 이득이 어느 정도인지 테스트
• ALL-Tokens MLM
• Replace MLM 과 마찬가지로 masked token 은 generator sample 로 대체
• 일부만 치환하는게 아니라 all tokens in the input 을 예측
• BERT + ELECTRA
• All input token 이 subset 보다 Greatly benefit 를 얻는 것을 확인
• ELECTRA 15% 는 ELECTRA 보다 좋지 않음
• Pre-train - fine-tune mismatch from [MASK] 로 약간의 손해가 발생함을 확인
• Replace MLM 이 BERT 를 약간 능가
• BERT 는 이미 8:1:1 로 pre-train, fine-tuning mismatch 해결 트릭을 사용 중
• 그러나 이런 휴리스틱은 문제를 완전히 해결하는데 충분하지 않음을 시사
• ALL-token MLM 이 BERT 와 ELECTRA 사이의 격차를 좁힘
• 이런 결과를 종합했을 때
• All tokens, 적은 양의 pre-train – fine-tune mismatch 가 ELECTRA 의 많은 개선을 이루게 함
• 다양한 모델 크기에서 BERT 와 비교
• 모델이 작아질수록 ELECTRA 이득이 높아 짐
• 작을수록 BERT 와 성능차이가 커짐
• 모델이 작아도 BERT 에 비해 빠르게 수렴
• Small model 은 trained fully to convergence
• ELECTRA 가 fully trained 했을 때 BERT 보다 더 높은 정확도 달성
결론 Replace Token Detection 구조 제안
Masked Language Model 과 비교
• Pre-training objective 가 더 효율적이고 downstream task 에서 더 좋은 성능을 보여 줌
비교적 적은 양의 컴퓨팅에도 잘 동작
• Access to computing resource 가 부족한 연구자와 실무자에게 도움이 될 수 있기를 !
맺음말
이번 포스팅은 자연어처리 논문 중 하나인 ELECTRA를 정리해봤습니다.
굉장히 독특한 아이디어로 좋은 퍼포먼스를 낸 논문입니다.
공부하시는 분들에게 도움이 되기를 바랍니다.