
포스팅 개요
이번 포스팅은 자연어처리(NLP) 논문 중 A Lite BERT for Self-supervised Learning of Language Representations라는 논문을 리뷰하는 포스팅입니다. 본 논문은 NLP논문에서 ALBERT라고 많이 알려진 논문입니다. 앞서 GPT, BERT, RoBERTa 논문 리뷰에 이어서 진행하는 자연어처리 논문 시리즈 다섯 번 째 포스팅입니다.
추가로 해당 포스팅의 내용은 제가 진행하는 사내 자연어처리 스터디에서 발표한 자료를 블로그로 정리한 자료임을 알려드립니다.
자연어처리 논문 리뷰는 아래와 같은 순서로 할 예정이며 이번 포스팅은 그 다섯 번 째 ALBERT 논문입니다.
- GPT-1 (https://lsjsj92.tistory.com/617)
- BERT (https://lsjsj92.tistory.com/618)
- GPT-2 (https://lsjsj92.tistory.com/620)
- RoBERTa ( https://lsjsj92.tistory.com/626 )
- ALBERT
- ELECTRA ( https://lsjsj92.tistory.com/629 )
참고한 자료는 아래와 같습니다.
- ALBERT 논문

포스팅 본문
ALBERT 논문 리뷰는 아래와 같은 순서로 진행합니다.
1. ALBERT 핵심 요약
2. ALBERT 논문 리뷰
ALBERT 핵심 요약
Network pretraining
• Language representation learning에서 큰 발전을 이룸
• 성능 개선을 위해 했던 방법은 Model Distill
• Large network로 training 하고 distill them down to smaller ones for real applications
Large Network의 문제점
• Memory Limitation
• 모델의 크기가 커짐에 따라서 Out of Memory(OOM)이 발생
• Training time
• 학습하는데 시간이 오래 걸림
ALBERT에서 제시하고자 하는 것
• Factorized Embedding Parameterization
• 기존 BERT : Vocab Embedding X Hidden Embedding. => E(또는 V) x H
• ALBERT : Vocab Embedding x E, E x Hidden 의 2가지 matrix로 decomposing을 진행
• ALBERT에서는 Input Embedding를 H보다 작게 설정
• Input embedding은 token의 정보를 담고 있음
• Hidden output은 transformer에서 학습된 contextualized representation 결과
• Cross layer parameter sharing
• Transformer layer끼리 parameter 공유
• Shared-attention, all-shared 등의 방법
• Sentence Order Prediction(SOP)
• BERT에서는 Next Sentence Prediction(NSP)
• 너무 쉽다
• Sentence 간에 연관 관계를 학습하는 것이 아닌 같은 topic인지 보는 topic prediction에 가까움
• 이를 보완하기 위해 SOP 도입
• 두 문장의 순서를 바꿈
• 문장의 순서가 올바른지 예측
ALBERT는 이렇게 요약할 수 있습니다. 이제 논문을 리뷰합니다.
ALBERT 논문 리뷰
Introduction
Pre-training network
• Language representation 효과 검증
• Large network는 SOTA performance에 중요
Distillation
• Pre-train large model을 진행
• 이후 distill down to smaller ones
의문 제기
• 큰 모델을 사용하면 더 좋은 NLP 모델을 만들 수 있나?
• Training speed와 memory limitation 문제가 장애물로 걸림

ALBERT의 문제 접근
• memory limitation problem
• Training time
Two parameter reduction 접근
• Factorized embedding parameterization
• Decomposing large vocab embedding
-> two small matrices
• Cross-layer parameter sharing
• Parameter를 보호
• 이 두 방법은 아래와 같은 장점
• reduce the number of parameter
• Without seriously hurting performance
• Improving parameter-efficiency
• More faster
Sentence Order Prediction(SOP) 접근
• Sentence Ordering Objectives
• 두 문장의 연속 순서를 결정하기 위한 학습
• BERT보다 더 어렵고 downstream task에서 더 유용함
Related work
지난 모델들이 특정 Size에서 멈춘 이유
• 계산 비용이 비쌈(computation cost problem)
• 메모리 한계(Easily hit memory limit)
SOP에 대한 설명도 있으나 위에 작성한 관계로 넘어갑니다.
The Elements of ALBERT


Factorized Embedding Parameterization
• 기존 방법들은 E와 H 같음
• E : input token embedding
• H : Hidden size
• Model 관점에서 E와 H
• E
• Token에 대한 Embedding
• Context independent함
• H
• Hidden layer에 대한 output
• Token의 주변 관계까지 파악된 Embedding
• Context Dependent함
• 따라서 H가 E보다 큰 것이 의미가 있음
• Vocabulary size (V)에 따라 matrix 크기가 커짐
• V x E
• 30000 * 768 = 23,040,000
• 그래서 factorization embedding parameter를 이용
• Decomposing two smaller matrices
• (VxE) + (ExH) 형태
• 파라미터 수를 줄일 수 있음
• (30000 * 128) + (128 * 768)= 3,938,304
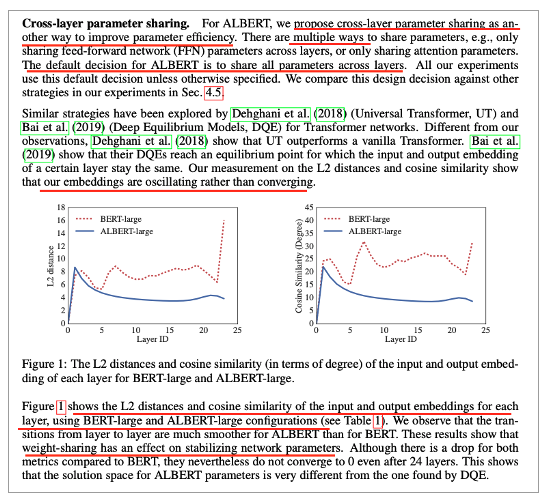
Cross-layer parameter sharing
• Factorization 보다 더 많은 parameter 감소에 기여
• Transformer layer간 parameter를 공유
• 성능이 크게 저하되지 않으면서 parameter는 크게 감소
• All parameters share를 default로 가지고 감
• BERT와 ALBERT의 L2 distance, cosine similarity 비교
• 각 layer의 input, output 유사도
• BERT는 진동함
• ALBERT는 수렴하는 모습
• 즉, weight sharing은 network 안정화에 기여


Inter-sentence coherence loss
• BERT
• Masked Language Model(MLM)
• Next Sentence Prediction(NSP) 사용
• 후속 연구
• NSP를 신뢰할 수 없다고 판단하고 제거하기 시작
• NSP는 어렵지 않은 task이기 때문
• NSP
• Topic prediction과 일관성(결합성, coherence) 예측 반영
• Topic prediction은 coherence 보다 쉬움
• MLM loss와 겹침
• 따라서!
• Topic prediction을 피하고 inter-sentence coherence에 focus
• Positive : 순서가 일치한 연속 문장
• Negative: 순서를 swap
• NSP는 SOP를 풀 수 없음
• SOP는 NSP를 풀 수 있음

Model setup
• ALBERT가 BERT보다 더 작은 파라미터
• ALBERT-xxlarge 이용
• 24layer가 아닌 12layer
• 24 layer와 12layer는 성능 차이가 크지 않음
• 그러나 24 layer는 계산 비용(computation cost)가 더 비쌈
Experimental result
Experimental setup
• 16GB 데이터
• Bookcorpus, English wikipedia
• Maximum 길이 512
• Vocab size 30,000
• Sentencepiece 사용
• N-gram mask 사용
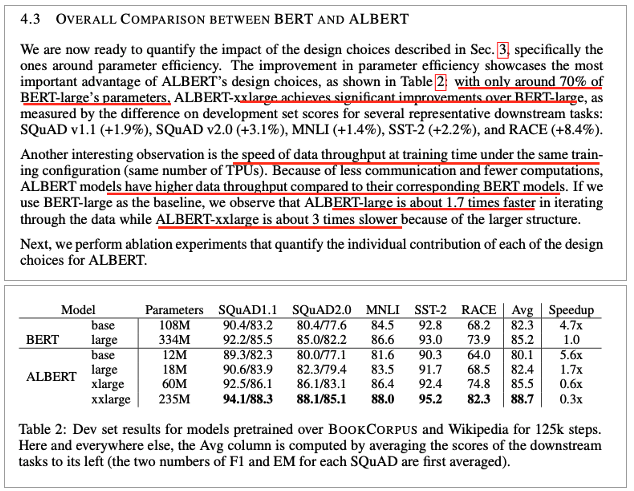
Comparison between BERT and ALBERT
• ALBERT-xxlarge
• BERT-large의 70%의 파라미터만 사용
• BERT-large보다 더 좋은 성능 달성
• Speed of Data Throughput
• Less communication and fewer computations
• ALBERT는 BERT보다 higher data throughput
• Large끼리 비교했을 때 1.7배 빠름
• xxlarge는 3배 더 느림
• Structure가 크기 때문
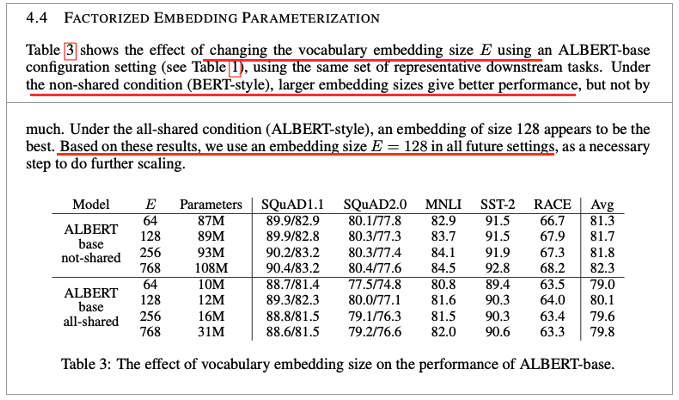
Factorized Embedding Parameterization
• Vocab Embedding size E에 따른 성능
• Non-shared condition(BERT)
• Larger embedding이 좋은 성능
• 그러나 크게 좋진 않음
• All-shared condition(ALBERT)
• 128 size가 best
• 이후 셋팅도 128 size
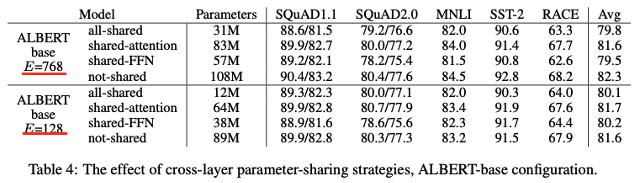
Cross layer parameter sharing
• E = 768, 128 2가지
• 4가지 전략
• All-shared strategy(ALBERT style)
• Not-sharing (BERT style)
• Only the attention
• Only FFN parameters share
• All shared 방법
• Hurts performance both condition
• 하지만, 크게 저하 되지 않음
• ALBERT Style
• FFN
• 성능 저하의 대부분은 여기서 나옴
• Attention
• 떨어지지 않거나 약간만 떨어짐
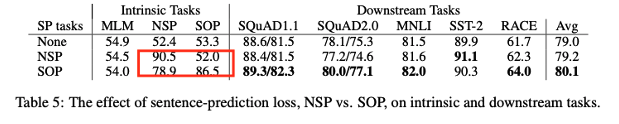
Sentence order prediction(SOP)
• 3가지 실험
• None(XLNet, RoBERTa style)
• NSP(BERT style)
• SOP(ALBERT-style)
• NSP
• SOP를 해결할 수 없음
• Topic shift를 모델링
• SOP
• NSP를 해결할 수 있음
• Downstream task performance에도 영향

Train with same amount of time
• Longer training은 좋은 성능을 이끌어 냄
• 데이터 처리량(number of training steps)을 제어하는 대신
• Actual training time을 control해 비교
• BERT large model
• 400k training step은 34시간
• ALBERT-xxlarge model
• 125k training step은 32시간
• 대략 비슷함
• BERT보다 더 좋은 성능이 나옴
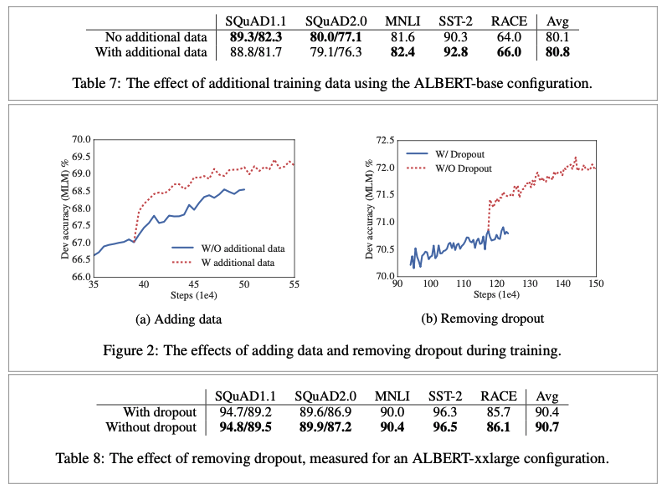
Add training data, Dropout effect
• 데이터를 추가로 더하고, 더하지 않은 것을 비교
• 더한 것이 더 좋음
• Largest model은 여전히 not overfit임
• 따라서 dropout을 제거하기로 결심함
• Model capacity를 늘리기 위해
• Dropout 제거
• 제거 후 더 나은 성능을 보여줌
• 경험, 이론적으로 CNN에선 안 좋다고 증명
• Batch normalization and dropout의 combination
• Large Transformer-based model에선 첫 사례임
• 그러나, ALBERT는 특수한 케이스이고 더 실험이 필요
Task에 따른 성능 결과
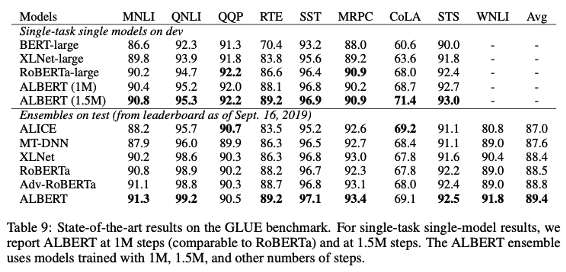
Discussion
ALBERT-xxlarge
• BERT-large보다 더 적은 파라미터 및 더 좋은 성능
• Larger structure 때문에 계산 비용이 더 비쌈
• Next step은 ALBERT의 training and inference speed를 올리는 것
• Sentence Order Prediction이 더 좋다는 것을 보여 줌



