
포스팅 개요
이번 포스팅은 자연어 처리(NLP) 논문 중 GPT-2(Language Models are Unsupervised Multitask Learners) 논문에 대한 리뷰를 작성하는 포스팅입니다.
앞서 GPT-1, BERT에 이어서 자연어 처리 논문 시리즈 정리하는 세 번째 포스팅입니다.
추가로 해당 포스팅의 내용은 제가 진행하는 사내 자연어 처리 스터디에서 발표한 자료를 블로그로 정리한 자료임을 알려드립니다.
자연어 처리 논문 리뷰는 아래와 같은 순서로 할 예정이며 이번 포스팅은 그 세 번째 GPT-2 논문입니다. (순서는 바뀔 수 있습니다.)
- GPT-1 (https://lsjsj92.tistory.com/617)
- BERT (https://lsjsj92.tistory.com/618)
- GPT-2 ( 이번 포스팅 )
- RoBERTa ( https://lsjsj92.tistory.com/626 )
- ALBERT ( https://lsjsj92.tistory.com/628 )
- ELECTRA ( https://lsjsj92.tistory.com/629 )
참고한 자료는 아래와 같습니다.

포스팅 본문
GPT-2 논문 리뷰는 아래와 같은 순서로 진행합니다.
- GPT-2 핵심 요약
- 논문 본문 리뷰
GPT-2 핵심 요약
더욱 범용적인 LM을 만들자!
• Fine-tuning 없이 적용
• 기존에는 pre-training과 supervised fine-tuning의 결합으로 만들어짐
• 이는 transfer와 더불어 긴 역사를 가짐
• 하지만, 지도 학습이 없는 상태로 만들어진다면 일반 상식 추론 등의 다양하게 범용적으로 사용할 수 있을 것
• Zero shot learning
• Model이 바로 downstream task에 적용함
• *참고
• One-shot learning : downstream task를 한 건만 사용
• 모델을 1건의 데이터에 맞게 업데이트
• Few-shot learning : downstream task를 몇 건만 사용
• 모델을 몇 건의 데이터에 맞게 업데이트
새로운 dataset 구성
• WebText를 활용함
• Reddit 데이터 활용
• 위키피디아 글은 제거, 중복 제거 후 40G 데이터 확보
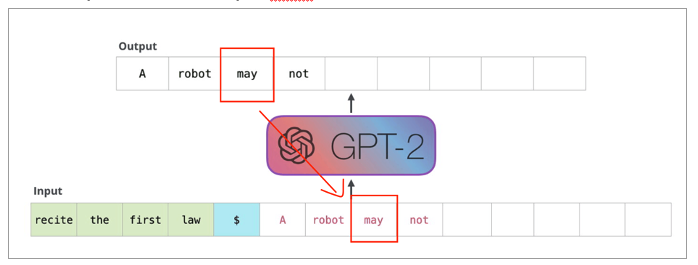
Auto Regressive
• 이전의 output이 다음의 input으로 들어감
사회적 이슈
• Large Model을 공개하지 않음
• 나중엔 small model 공개
• 악용될 수 있는 여지가 보였기 때문에
• NLP model이 악용이 될 수 있다는 위기의식(?)을 제공해 줌
GPT-2는 위와 같이 핵심을 정리할 수 있습니다.
GPT-2 논문 리뷰
이제 GPT-2 논문을 리뷰해봅니다.
ML system

• 대규모 dataset, large model, 지도 학습
• 학습한 작업에서 좋은 성능
• 그러나 민감하고 망가지기 쉬움
• 데이터 분포나 사소한 변경 등에 의해서
• 즉, 일반적이지 않고 좁은 전문가(narrow expert)임
• 우리는 일반적인(범용적인) 시스템을 원함
• Training dataset을 생성하고, label 할 필요가 없음
ML system(~ing)

• 지배적인 접근 방식
• 원하는 작업에 대한 dataset of training을 수집
• 이러한 동작을 모방하도록 훈련
• 그리고 independent and identically distributed(IID) 예제로 테스트
• 독립적, 동일 분산형
• Narrow expert에게 좋은 결과를 가져다 줌
• 그러나 단점이 존재함
• Single task training on single domain dataset
• 일반화의 부족에 주요 원인
• 광범위한 도메인과 작업에 성능 측정 필요
• 최근에는 GLUE 등이 제안
• Pre-training and supervised fine-tuning 구조
• 여전히 supervised training이 요구 됌
본 논문에서는!
• Connect two lines of work
• Method of Transfer 추세를 계속 사용
• LM
• 매개변수나 모델 아키텍처 수정없이 zero-shot
• Zero-shot 설정에서 범용성 있는 언어 모델 능력 가능성
핵심은 Language Model 이다!
• 비지도 분포 추정
• 일련의 symbol (s1,s2,…,sn)으로 구성된 예제 (x1,x2,…,xn) 에서 추정
• Single task 학습은 P(output | Input)을 추정하는 확률 framework로 표현
• 범용 시스템은 여러 다른 과제들을 수행할 수 있어야 함
• 입력에 task가 함께 표현


Training dataset

• 이전의 작업은 news article, wikipedia를 대부분 사용
• Single domain of text
• 본 논문의 접근 방식
• Collect Large and diverse a dataset
• varied of domains and context 작업을 위해
• Common crawl과 같은 것이 존재하긴 함
•데이터 품질 문제가 있음
• 본 논문에서는 WebText를 사용
• 인간에 의해 필터링 된 웹 페이지 수집
• Reddit의 3 krama이상 데이터 수집
• Heuristic indicator로 생각할 수 있음
• Interesting, educational of just funny
• 4500만 링크 포함
• 중복 제거, Wikipedia document 제거 등 전처리
• 40GB, 800만 개 이상 문서
Byte Pair Encoding 활용
• 글자(byte)와 단어의 중간 단위를 사용할 수 있음
• OOV(Out Of Vocabulary) 문제를 해결
• Subword들을 활용하기 때문에 OOV와 신조어 같은 단어에 강점이 있음
• 하나의 단어는 더 작은 단위의 의미 있는 서브 워드로 이루어져 있다는 가정
• 이러한 subword 분리 알고리즘 중 하나
• 기존에 있던 단어를 분리하는 것
• 글자(character)단위에서 점차적으로 단어 집합(vocabulary)를 만들어내는 bottom-up 방식
• 단어들을 character 또는 Unicode 단위로 vocabulary를 만들고 가장 많이 등장하는 unigram을 하나로 통합
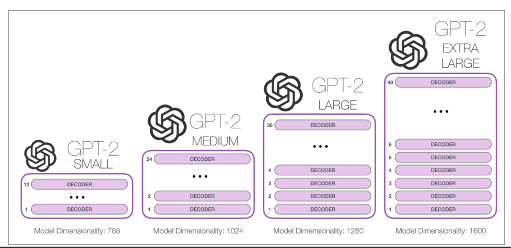
Model
• Transformer decoder를 활용
• 기본적으로 GPT-1과 동일
• Layer Normalization이 각 sub block의 input으로 옮겨짐
• layer normalization이 마지막 self-attention block 이후에 추가
• 모델 깊이에 따른 residual path 초기화 방법 변경
• 사전 개수 5만 여개로 확장
• Context size가 최대 1024개의 token으로 늘어남
• Batch size 512로 증가

Language Modeling
• GPT-2의 강점
• Byte 수준에서 동작
• Does not require lossy pre-processing or tokenization
• Can evaluate it on any language model benchmark
• WebText LM에 따른 dataset의 log 확률을 계산하는 방식으로 통일
• <UNK>은 400억 byte 중 26번 밖에 나타나지 않음
• Zero shot으로 8개중 7개에서 SOTA 달성
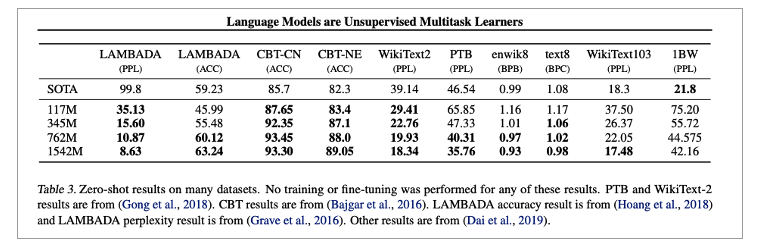
Test
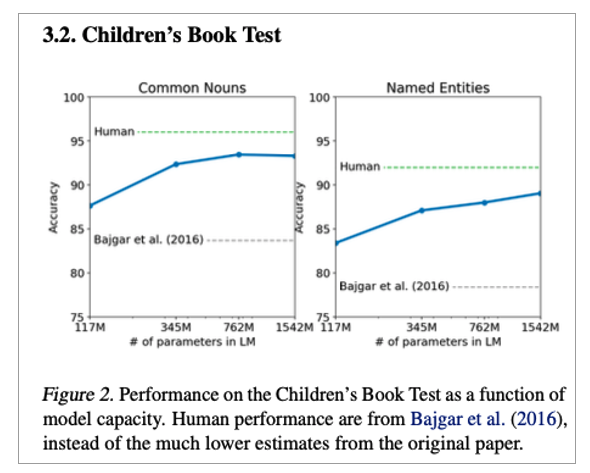
• Children’s Boot Test(CBT)
• 89% -> 93%
• LAMBADA
• Long-range dependencies
• Perplexity로 평가
• 99.8 -> 8.6으로 대폭 향상
• 정확도
• 19% -> 52.66
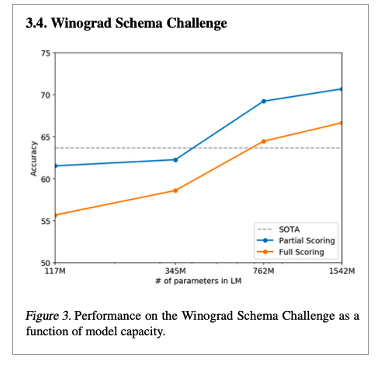
• Winograd
• 7% 향상
• The Conversation Question Answering Dataset(CoQA)
• 7개 분야에서 가져온 문서에서 질문자-답변자의 자연어 대화로 이루어진 dataset
• 4개 중 3개의 base line model을 능가
• Without using the 127,000 manually collected QA pair를 하고도 능가함
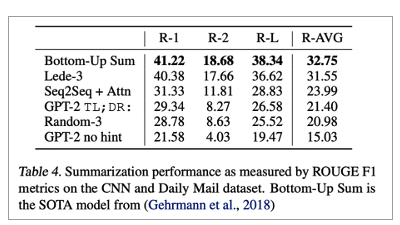
• Summarization
• 좋은 성능이 나오지 않음
• Translation
• english sentence = french sentence 형태로 제공
• Final prompt에서 English sentence = 형태로 번역
• WMT-14 English-French test에서 5 BLUE가 나옴
• 좋지 않은 성능 ( unsupervised MT에서SOTA는 33.5 )
• French – English는 11 BLUE
• 그럼에도 의미가 있음
• Filtering할 때 WebText에서 removed non-English webpage
• 그래도 10MB 정도의 작은 French corpus가 있었는데 이를 활용한 것
• Question Answering
• Small model은 1%도 안나옴
• 큰 모델도 4%
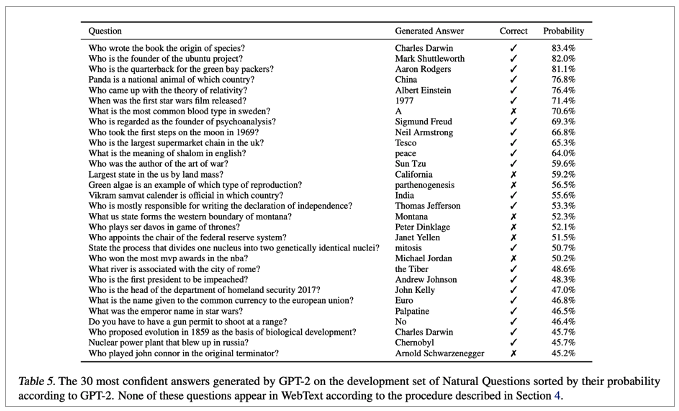
• 가장 자신 있는 1%에 대해서는 63%의 정확도를 보여줌
Generalizaion VS Memorization
기억(암기)하고 답을 내는 것인가?
• Dataset에서 train set과 test set에서 데이터가 겹치는 경우가 있음
• CIFAR-10의 경우 3.3%가 겹쳐져 있음
• 이는 metric 측정에 방해가 되는 요소임
• 이러한 요소가 있는지 확인이 필요
• WebText에 대해 8-gram을 사용해 bloom 필터를 만들어 테스트
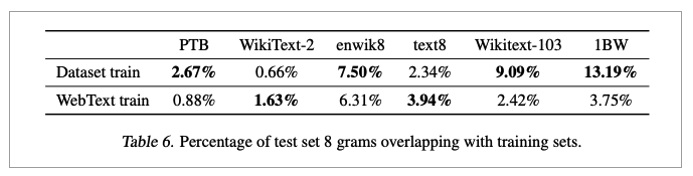
• WebText를 써도 된다는 결론이 나옴
• 이러한 중복 제거를 위해 본 논문에서는 n-gram overlap 사용을 추천
• LM이 Memorization에 원인을 두는지 확인하는 잠재적 방법
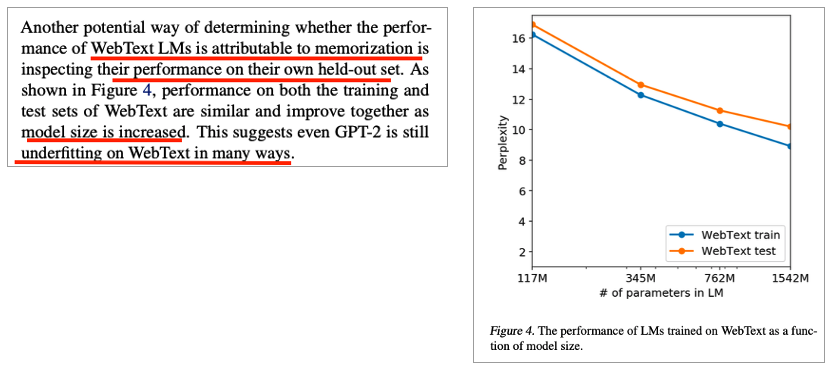
• Their own held-out set으로 성능 검사
• Training and test sets of WebText의 성능은 model size가 커질 수록 증가함
• 이는 여전히 WebText에 underfit되어 있다는 것을 암시 ( 암기 하고 있지 않음 )
Discussion
• Unsupervised learning
• 아직 연구할 것이 더 남아있음을 보여줌
• Performance
• 독해 등에선 supervised baseline과 견줄만한 성능
• 그러나, 요약과 같은 task에선 성능이 나오지 못함
• 실제로 사용하기엔 무리가 있음
• Random보다 떨어지는 것도 있음
• QA, translation같은 작업에서도 sufficient capacity할 때야 baseline을 outperform
• 그럼에도 Zero-shot인 것을 감안하면 꽤나 인상적인 성능
• Fine-tuning 조사
• BERT에 의해 증명된 단방향성 표현의 비효율성 극복이 충분한지 불분명
• decaNLP, GLUE와 같은 benchmark에 대해서 fine tuning 조사 계획
마무리
본 포스팅은 GPT-2(Language Models are Unsupervised Multitask Learners) 논문을 리뷰해봤습니다.
Open-AI가 범용적인(General) NLP 모델을 만들기 위해 연구를 하고 있는데 어떻게 보면 그 초창기의 모습과 관점이라고 볼 수 있을 것 같습니다.
부족한 글이지만, 도움이 되시길 바랍니다.
감사합니다.



