
포스팅 개요
본 포스팅은 OpenAI에서 발표한 자연어 처리(NLP) GPT 논문 시리즈 중 첫 번째 Improving Language Understanding by Generative Pre-Training (GPT-1) 논문을 리뷰하는 포스팅입니다.
논문이 나온지 시간이 좀 되었고 본인도 몇 번 읽어봤지만, 블로그에 정리하지 않아서 이번 기회에 자연어 처리(NLP) 논문 시리즈로 정리해두려고 합니다.
추가로 해당 포스팅의 내용은 제가 진행하는 사내 자연어 처리 스터디에서 발표한 자료를 블로그로 정리한 자료임을 알려드립니다.
자연어 처리 논문 리뷰는 아래와 같은 순서로 할 예정입니다. ( 변경될 수도 있습니다. )
- GPT-1 ( 이번 포스팅 )
- BERT(https://lsjsj92.tistory.com/618)
- GPT-2 (https://lsjsj92.tistory.com/620)
- RoBERTa (https://lsjsj92.tistory.com/626)
- ALBERT (https://lsjsj92.tistory.com/628)
- ELECTRA (https://lsjsj92.tistory.com/629 )
참고한 자료는 아래와 같습니다.

포스팅 본문
Improving Language Understanding by Generative Pre-Training (GPT-1) 논문 리뷰는 아래와 같은 순서로 진행합니다.
- GPT-1 요약 설명
- 논문 설명
1. GPT-1 요약 설명
제가 생각하는 GPT-1 논문을 요약 설명하면 아래와 같이 정리할 수 있습니다.
- Text의 Unlabeled된 데이터는 풍부함
- 그에 반해서 Labeled된 데이터는 풍부하지 못하고 빈약한 상황임. 그에따라서 Model이 적절한 작업을 수행하기 쉽지 않음
- 다양한 Unlabeled된 text corpus에서 Language Model을 Pre-training하고 각 task에 맞게 Fine-tuning
- 이렇게 수행하면 이득을 크게 얻을 수 있음
- Unlabeled text의 Challenging
- 단어 수준(word level) 이상의 정보를 얻기가 쉽지 않음
- 어떤 optimization objective가 transfer에 유용한 text representation을 배우는데 효과적인지 불분명
- 학습된 representation을 target task에 효과적으로 전달하는 일치된 의견(consensus)이 없음
- 이러한 불확실성은 semi-supervised learning 접근법을 어렵게 만듦
- 그래서 GPT-1은!
- Unsupervised pre-training과 supervised fine-tuning을 결합한 semi-supervise 접근을 사용
- 목표
- Wide range of tasks에 약간의 조정만으로도 transfer 할 수 있는 범용 representation을 학습하는 것
- 2 stage를 거침
- Unlabeled data에서 LM objective를 사용
- 그 이후 supervised objective에 해당하는 target task에 적용
- Transformer 구조를 사용
- Text의 long-term dependencies에 강인한 결과를 보여줌
- 기존 RNN 등에 비해 구조화된 memory를 쓸 수 있게 함
- Decoder 부분만 사용
요약으로 정리하면 위와 같이 정리될 수 있습니다.
이제 논문 내용을 살펴보겠습니다.
2. GPT-1 논문 설명
본 파트에서는 논문의 내용을 살펴보면서 GPT-1을 정리해봅니다.
대부분의 딥러닝 task는
• 수동으로 label된 많은 양의 data가 필요
• 이런 부분이 부족한 곳에서는 적용 가능성이 제한 됌
Unlabeled data
• 시간 소모나 가격측면에서 대안을 제공
• 성능 상승에 효과적인 representation을 배움
Unlabeled text의 Challenging
• 단어 수준(word level) 이상의 정보를 얻기가 쉽지 않음
• 어떤 optimization objective가 transfer에 유용한 text representation을 배우는데 효과적인지 불분명
• 학습된 representation을 target task에 효과적으로 전달하는 일치된 의견(consensus)이 없음
• 이러한 불확실성은 semi-supervised learning 접근법을 어렵게 만듦
그래서 우리(GPT-1)는!
• Unsupervised pre-training과 supervised fine-tuning을 결합한 semi-supervise 접근을 사용
• 목표
• Wide range of tasks에 약간의 조정만으로도 transfer 할 수 있는 범용 representation을 학습하는 것
• 2 stage를 거침
• Unlabeled data에서 LM objective를 사용
• 그 이후 supervised objective에 해당하는 target task에 적용
• Transformer 구조를 사용
• Text의 long-term dependencies에 강인한 결과를 보여줌
• 기존 RNN 등에 비해 구조화된 memory를 쓸 수 있게 함

Framework
• 2개의 Stage로 구성
1. LM을 대규모 corpus에서 학습
2. fine-tuning
악필 죄송합니다. ㅠㅠ 블로그에 text로 설명하기엔 제 정리 실력이 부족하여 필기한 내용으로 올려봅니다. 짧게 요약하자면,
• LM로 pre-training을 하고 그때 구조를 transformer decoder 구조를 사용합니다.
• 만들어진 pre-trianing model을 fine-tuning합니다.
• 이때 pre-training에서 만들었던 LM도 fine-tuning task에 맞게 보조 목표로써 추가시켜줍니다.
• 추가의 장점은 convergence를 가속화 해주고 improving generalization of supervised model의 장점이 있다고 합니다.
• 여기서 C는 labeled된 dataset입니다.

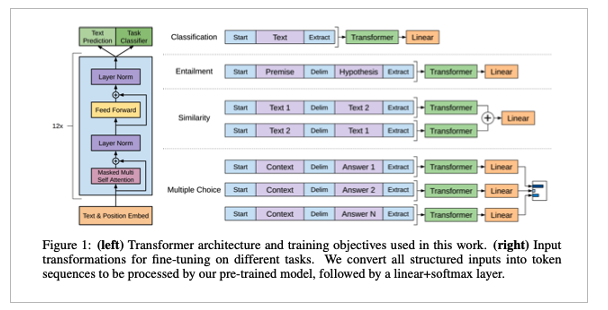
Task-specific input transformations
• 기존의 단점
• Task specific 아키텍처 목표에 학습함
• 이러한 re-introduce(재구조) 작업은 상당한 양의 task-specific 커스터마이즈가 필요하고 transfer learning을 사용X
• 우리는!
• Pre-training model이 process할 수 있도록 input structured를 convert하는 방법을 사용
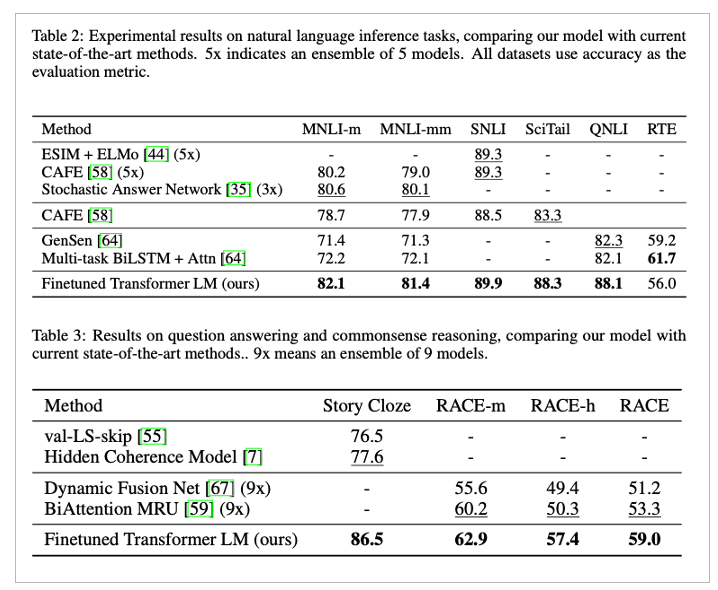
실험 결과
여러 부문에서 SOTA 달성
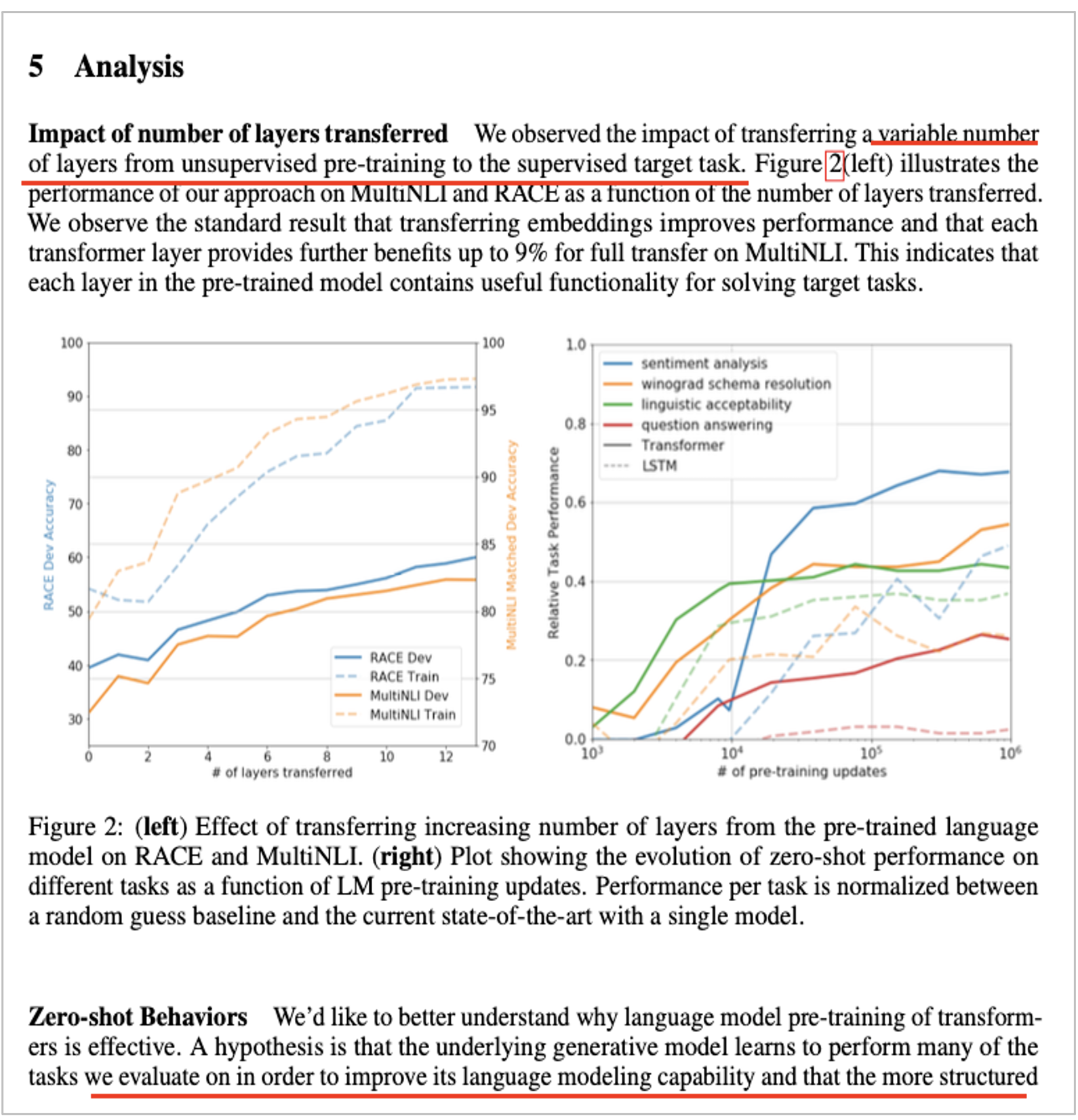
Analysis
• Transferred 할 때 layer 개수에 따른 성능
• Pre-training update 횟수에 따른 LSTM, Transformer 비교
• LSTM과 비교해서 more structured attentional memory함
Ablation studies
1. Fine-tuning 단계에서 LM object를 제외 했을 때
• 제외하면 큰 dataset의 성능은 떨어지고 적은 dataset 성능은 올라감
• 즉, 적은 dataset을 가지고 있으면 LM의 성능이 나오지 않음
2. LSTM과 비교
3. Pre-training 하지 않고 한 것

마무리
본 포스팅은 OpenAI의 자연어 처리 논문 중 GPT-1 (Improving Language Understanding by Generative Pre-Training)에 대해서 정리한 포스팅입니다. 시간이 좀 지난 논문이지만, 다시 한번 복습 공부할 겸 포스팅에 정리해보았습니다.
지금은 Pre-trianing - Fine Tuning이 굉장히 익숙하지만, 당시만해도 지금처럼 익숙한 상황은 아니었습니다.
NLP쪽에서 이러한 시도를 해보았다는 것, 그리고 RNN과 같은 구조를 탈피해서 (ELMo가 그 예시) Trnasformer 구조를 사용했다는 것이 눈에 띄는 논문입니다.
부족한 글이지만 누군가에게는 도움이 되시길 바랍니다.



