

포스팅 개요
본 포스팅은 Google에서 발표한 자연어 처리(NLP) 논문 중 BERT(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding) 논문을 리뷰한 포스팅입니다.
앞서 GPT-1 논문 리뷰에 이어서 자연어 처리 논문 시리즈 정리하는 두 번째 포스팅입니다.
추가로 해당 포스팅의 내용은 제가 진행하는 사내 자연어 처리 스터디에서 발표한 자료를 블로그로 정리한 자료임을 알려드립니다.
자연어 처리 논문 리뷰는 아래와 같은 순서로 할 예정이며 이번 포스팅은 그 두 번째 BERT 논문입니다. (순서는 바뀔 수 있습니다.)
- GPT-1(https://lsjsj92.tistory.com/617)
- BERT ( 이번 포스팅 )
- GPT-2 (https://lsjsj92.tistory.com/620)
- RoBERTa ( https://lsjsj92.tistory.com/626 )
- ALBERT( https://lsjsj92.tistory.com/628 )
- ELECTRA( https://lsjsj92.tistory.com/629 )
참고 자료
- BERT 논문 원본

포스팅 본문
BERT 요약은 아래와 같은 순서로 진행합니다.
- 1. BERT 논문 간단 요약 ( 핵심 정리 )
- 2. 논문 리뷰
1. BERT 논문 간단 요약
BERT는 Pre-training of Deep Bidirectional Transformers for Language Understanding 이라는 논문 제목을 가지고 있습니다. 이 제목을 보면 알 수 있듯이 Deep Bidirectional Trnasformer 구조를 가지고 있습니다. 핵심적인 것을 정리하면 아래와 같습니다.
BERT가 나올 때의 NLP
• 기존 LM 모델들의 단점이 있음
• ELMo, GPT-1
• Unidirectional 구조를 가지고 있는 형태임
• GPT-1의 경우 Left-to-Right 구조를 가지고 있음
• Token이 이전의 것에만 참여할 수 있음
• Unsupervised Fine-tuning Approaches 라고 논문에서 말 하기도 함
• ELMo의 경우 shallow concatenation 구조임
• Left-to-right, right-to-left 구조
• Feature-based approaches 라고 논문에서 말 하기도 함
*참고. Feature-based approach란?
Pre-trained된 model의 feature를 fixed시키고 feature를 Extract해서 사용하는 구조
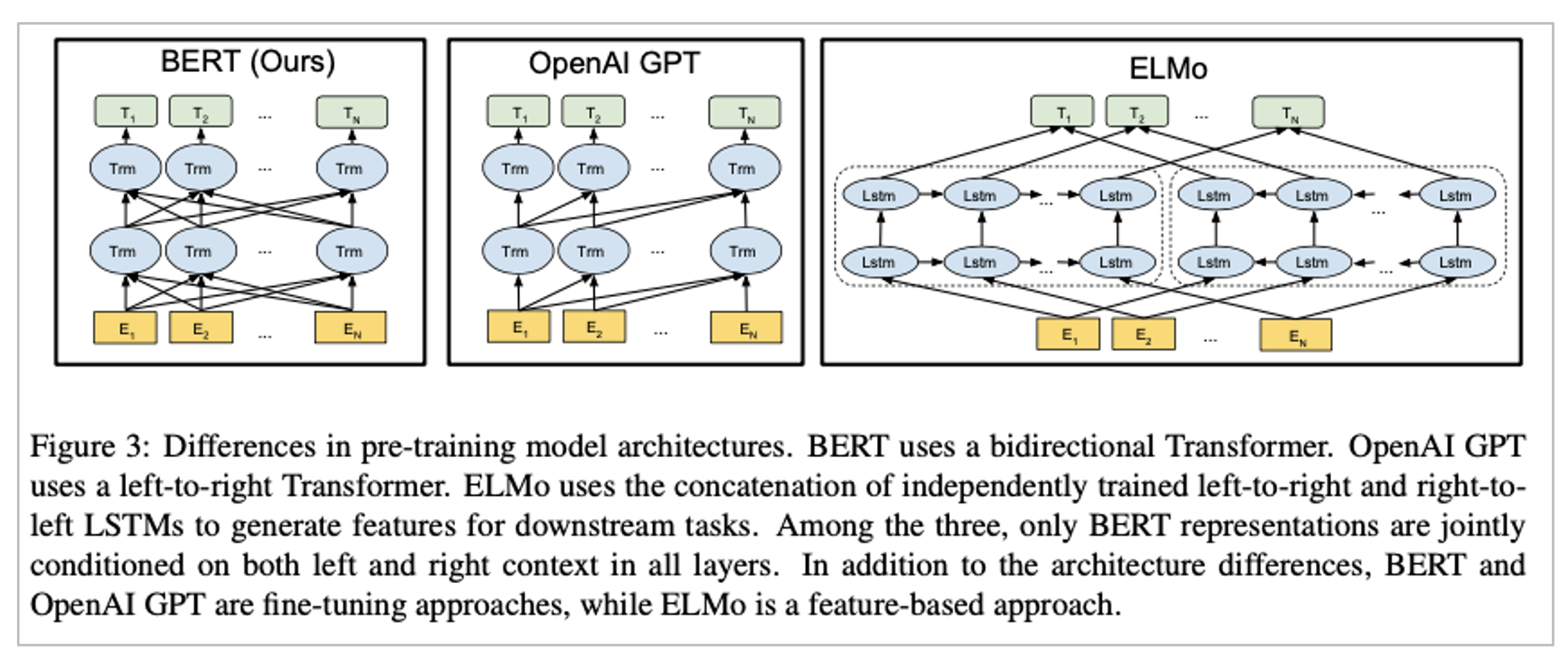
BERT란?
• Bidirectional Encoder Representations from Transformers
• Deep bidirectional representations를 가지고 있음
• Pre-trained 후 fine-tuning 하는 구조
• Masked Language Model(MLM) 구조를 가지고 있음
• Input token을 random하게 masking 처리하고 이를 예측
• left와 right context를 같이 보고 해당 단어를 예측해야 함
• 이 때문에 Deep bidirectional representations 구조를 가지게 됌
• Next Sentence Prediction(NSP)도 포함되어 있음
• 즉, MLM과 NSP를 동시에 학습하는 것
이렇게 간단하게 요약할 수 있습니다. 이제 본격적으로 본문을 살펴보겠습니다.
2. BERT 논문 리뷰
이제 논문의 핵심적인 부분을 보면서 BERT 논문을 리뷰합니다.
Pretrained LM 표현을 downstream task에 적용하는 방법은 2가지
• Feature based
• ELMo
• Fine-tuning
• GPT-1
• 2개 다 unidirectional language model 구조
이러한 과거 형태의 문제점
• Pre-trained의 힘을 제한하는 형태
• Unidirectional 구조를 가지고 있음
• GPT-1을 예로 들자면 Left-to-right 아키텍처를 가지고 있음
• 모든 input token이 이전 token에만 attend할 수 있음
• 이러한 구조는 token-level task의 fine-tuning시 해로울 수 있음
따라서 BERT 논문에서는!
• Fine-tuning based approaches인 BERT를 소개
• 기존 unidirectionality 제약을 완화
• MLM(Masked Language Modeling)을 사용해서
• 랜덤하게 마스킹 처리하고 해당 원본 단어를 예측
• 이 때문에 left, right를 전부 융합해서 봐야해서 deep bidirectional 구조가 됌
• Next Sentence Prediction(NSP) task까지 있음
• 따라서 해당 BERT 논문에서 말하고자 하는 바는
• Importance of bidirectional pre-trianing LM의 중요성을 나타내고자 함
• MLM구조의 장점 발동
• Unidirectional LM (GPT-1)과 Shallow concatenation 구조인 ELMO와 반대


BERT에 대한 자세한 소개
• Pre-training, Fine-tuning 2 step 방법
• Pre-training
• Unlabled data에서 학습
• Fine-tuning
• Pre-trained parameter로 초기화
• Using labeled data from the downstream task으로 fine-tuned 됌

BERT 아키텍처(Architecture)
• 다른 task에 대해서도 전부 통일된 architecture를 가지고 있음
• Multi-layer bidirectional Transformer encoder
• 해당 논문에서 나오는 기호들
• L : number of layers
• H : Hidden size
• A : number of self-attention heads
• BERT-base(=OpenAI GPT와 같은 model size)
• L=12, H=768, A=12, total param=110M
• BERT-Large
• L=24, H=1024, A=16, total param=340M
• Input/output representations
• 입력은 한 문장(single sentence)이 될 수도 있고 두 개의(pair of sentences) 페어로 들어갈 수도 있음
• BERT에서 말하는 Sentence
• 영어 기준 S + V + O의 이런 구조가 아님
• 연속적인 text span
• 우리가 알고있는 문장이 아니어도 됌
• An arbitrary span of contiguous text rather than an actual linguistic sentence 이라고 BERT 논문에선 나와있음
• BERT에서 말하는 Sequence
• The input token sequence to BERT, which may be a single sentence or two sentences packed together
• WordPiece embedding을 사용
• 모든 처음은 [CLS] token으로 시작
• 나중에 classification 문제에서 이 토큰을 사용
• 다른 문장이 들어오면 [SEP]를 사용
• 다른 문장은 sentence A or sentence B가 들어옴
• Embedding을 학습함

BERT에 대한 자세한 소개(~ing)
• Pre-training
• Masked LM
• Deep bidirectional (LTR 모델보다 더 강력)
• 전통적인 LM은 LTR, RTL 방법
• Input token을 random하게 mask
• 15%
• Denoising Auto Encoder와 다른 점
• 전체 구성을 재구성하는게 아닌, Masked words만 예측
• Pre-training과 fine-tuning mismatch 존재
• [MASK]가 fine-tuning 과정에서 나오지 않기 때문
• 이를 완화하기 위한 조취로 MASK로 선정된 것이 항상 [MASK]되지 않음
• [MASK]된 것 중 80%는 [MASK]로 되고 10%로는 다른 token, 10% 바꾸지 않음



• Pre-training
• Next Sentence Prediction(NSP)
• 50% 확률로 실제 다음 문장을 추출하고 50%는 아닌 것을 추출
• MSM과 함께 해당 문장이 다음 문장인지 같이 학습
• QA, NLI task에서 도움이 되었다고 함

• Fine-tuning
• Task specific inputs과 outputs을 BERT에 넣어주고 end-to-end로 fine-tune
• Fine-tuning마다 input 형태가 다를 수 있음

실험 결과는 아래와 같습니다. 여기서는 자세한 결과는 생략하겠습니다.
(SOTA 달성했다는 내용입니다.)

Ablation Studies
개인적으론 재밌게 봤던 부분입니다.
• Effect of Pre-training Task
• NSP를 제외 했을 때
• MLM 방법을 사용
•LTR 모델 사용 & No NSP
• MLM사용 안함
• OpenAI GPT와 비교하려고. 단, BERT가 더 큰 dataset 등을 사용함
• LTR + No NSP + BiLSTM


• Effect of Model Size
• Layer 개수, hidden units 개수, attention heads 개수는 다르게
• 하이퍼파라미터와 training procedure는 동일
• 극단적으로 모델 크리글 확장하는 것이 very small scale task에도 큰 향상을 일으키는 것을 보여준 첫 사례임
• Feature-based Approach with BERT
• Feature-based란
• Fixed features are extracted from the pre-trained model
•이러한 feature-based는 몇 가지 이점이 있음

위의 사진으로 보았을 때 가장 맨 아래 embedding을 사용했을 떄 91.0 정도의 성능이, 2번째부터 last hidden layer를 사용했을 때 95.6% 결과가 나온 것을 볼 수 있습니다.
마무리
본 포스팅은 자연어 처리 논문 중 구글이 발표한 BERT(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding) 논문을 리뷰한 포스팅입니다. 기존 GPT-1 모델, ELMo와 다르게 Masked Language Modeling 방법을 사용해서 Deep bidirectional 구조를 사용하는 논문입니다.
부족한 글이지만 도움이 되시길 바랍니다.



