
포스팅 개요
이번 포스팅은 로컬 개발 환경에 고사양의 GPU가 없더라도 구글 코랩(Google Colab)의 무료 GPU 자원을 활용해 자신만의 LLM(거대 언어 모델) API 서버를 구축하는 방법에 대해 정리합니다.
ngrok이라는 터널링 도구를 활용해 Colab에서 실행되는 API 서버에 외부 접속이 가능한 공개 주소(Public URL)를 부여하고, 이를 통해 로컬 PC나 다른 환경에서 API를 자유롭게 호출하는 과정을 다룹니다.
본 포스팅에서는 대표적인 LLM 서빙 프레임워크인 Ollama와 vLLM을 각각 Colab에 배포하고 API 서버로 활용하는 두 가지 실전 예제를 모두 소개합니다. 이를 통해 자신의 필요에 맞는 프레임워크를 선택하여 '나만의 LLM 서버'를 구축하고 활용하는 전반적인 과정을 이해할 수 있습니다.
본 포스팅에서 다루는 주요 내용은 다음과 같습니다.
- Colab과 ngrok 연동 원리 이해: 왜 이 조합을 사용하며 어떻게 동작하는지 알아봅니다.
- Ollama API 서버 구축: Colab에 Ollama를 설치하고 ngrok으로 외부에 노출시켜 로컬에서 API를 테스트합니다.
- vLLM API 서버 구축: Colab에 vLLM을 설치하고 OpenAI 호환 API 서버를 배포하여 로컬에서 활용합니다.
1. Colab과 ngrok 연동, 왜 함께 사용하는가?
최신 LLM(거대 언어 모델)을 로컬 환경에서 테스트하고 싶지만, GPU가 없거나 사양이 부족해 어려움을 겪는 경우가 많습니다. Llama 3나 Gemma, 요즘 나왔던 LG EXAONE, SKT A.X 4.0 이나 KT의 Midm(믿음) 같은 모델을 직접 실행해보려면 고가의 그래픽 카드가 필수적이기 때문이죠. 이때 Google Colab은 대안이 될 수 있습니다. Google 계정만 있다면 누구나 웹 브라우저를 통해 무료로 T4와 같은 강력한 GPU를 사용할 수 있기 때문입니다. 모델을 학습시키거나 무거운 연산을 처리하는 데는 좋은 환경이죠. 저는 개인적으로 Pro로 쓰고 있는 데, 무료 계정으로도 활용이 가능합니다.
Colab은 Google 클라우드 환경에서 독립된 컨테이너로 실행됩니다. 따라서 Colab 내부에서 Ollama나 vLLM을 통해 API 서버를 실행하더라도, 외부 인터넷에 연결된 제 로컬 PC가 이 서버에 직접 접근할 방법이 없습니다. 바로 이 문제를 해결해주는 방법이 ngrok입니다. ngrok은 Colab 내부의 특정 포트(예: 11434번)로 향하는 안전한 터널(tunnel)을 만들어 공개적으로 접속 가능한 고유 주소(URL)를 생성해줍니다.
마치 외부와 단절된 Colab 내부에 나만 아는 통로를 만들어주는 것과 같습니다. 이 통로를 통해 제 로컬 PC는 ngrok이 생성해준 공개 주소로 API 요청을 보낼 수 있고, ngrok은 이 요청을 Colab 내부의 API 서버로 정확하게 전달해줍니다.
즉, Colab의 강력한 무료 GPU(저처면 Pro면 약간의 요금을 내고 더 비싼 GPU)와 ngrok의 네트워크 연결을 결합하면, 비싼 장비 없이도 누구나 자신만의 LLM API 서버를 구축하고 제공되는 자원(resource) 안에서 마음껏 테스트할 수 있는 환경을 만들 수 있습니다.
2. Ngrok 회원가입 및 Authtoken 확인
Colab과 연동하기 위해 먼저 ngrok에 가입하고 API 인증에 필요한 Authtoken을 발급받겠습니다. 과정은 매우 간단합니다. ngrok 공식 홈페이지(https://ngrok.com/)에 접속하여 price 메뉴에 들어가서, development 메뉴를 선택한 뒤 Free tier를 클릭합니다. 이때 회원가입이 요청되는데요. Google 계정을 연동하거나 이메일로 간편하게 가입을 진행합니다.


로그인이 완료되면, 대시보드 왼쪽 메뉴의 Your Authtoken 탭으로 이동합니다. 페이지에 보이는 Your Authtoken 아래의 문자열이 바로 여러분의 고유 인증 토큰입니다. 이 Authtoken은 Colab에서 실행될 ngrok 에이전트가 여러분의 계정 소유임을 증명하는 비밀 키 역할을 합니다. 이 토큰이 있어야 정상적으로 터널을 생성하고 관리할 수 있으므로, Copy 버튼을 눌러 안전한 곳에 복사해두시기 바랍니다. (토큰은 비밀번호와 같으므로 외부에 노출되지 않도록 주의해야 합니다.)

이제 Colab에서 LLM 서버를 실행하고 ngrok을 통해 외부와 연결할 모든 준비가 끝났습니다.
다음으로는 첫 번째 예제인 Ollama 서버를 구축해보겠습니다.
3. 예제 1: Colab에 Ollama 서버 구축 및 로컬 PC에서 API 호출하기
이제 본격적으로 첫 번째 예제를 통해 Colab에 Ollama 서버를 구축하고, ngrok으로 생성된 Public URL을 이용해 로컬 PC에서 API를 호출하는 전 과정을 진행하겠습니다.
3.1. Colab 환경 설정 및 Ollama 설치
가장 먼저, Colab 노트북에서 필요한 패키지들을 설치하고 환경을 설정합니다.
# 1. Ollama 설치 스크립트 실행
!curl -fsSL https://ollama.com/install.sh | sh
# 2. 원활한 GPU 연동을 위한 CUDA 드라이버 설치
# Colab 환경에 따라 필요하지 않을 수 있으나, 안정적인 구동을 위해 권장됩니다.
!echo 'debconf debconf/frontend select Noninteractive' | sudo debconf-set-selections
!sudo apt-get update && sudo apt-get install -y cuda-drivers
# 3. ngrok 연동을 위한 Python 라이브러리 설치
!pip install pyngrok
위 셀은 다음의 세 가지 작업을 수행합니다.
- Ollama 설치: Ollama 공식 스크립트를 실행하여 Colab 환경에 Ollama를 설치합니다.
- CUDA 드라이버 설치: Colab의 GPU와 Ollama 서버가 원활하게 통신할 수 있도록 NVIDIA CUDA 드라이버를 설치합니다. 이는 GPU 사용 시 발생할 수 있는 잠재적인 호환성 문제를 예방하는 데 도움이 됩니다.
- pyngrok 설치: Python 코드 내에서 ngrok 터널을 제어하기 위한 공식 라이브러리를 설치합니다.
3.2. 비동기 코드를 이용한 서버 및 ngrok 실행
설치가 완료되었다면, 이제 Ollama 서버, ngrok 터널, 그리고 모델 다운로드를 동시에 실행할 차례입니다. 이 세 가지의 실행 프로세스를 효율적으로 관리하기 위해 Python의 asyncio 라이브러리를 활용하겠습니다. asyncio를 사용하면 각 프로세스가 서로를 차단(blocking)하지 않고 동시에 실행되도록 할 수 있어, 실시간 로그 모니터링과 안정적인 프로세스 관리에 매우 유용합니다.
아래는 전체 실행 코드입니다.
import os
import asyncio
from pyngrok import ngrok
# ngrok Authtoken을 입력합니다.
token = "YOUR_NGROK_AUTHTOKEN"
ngrok.set_auth_token(token)
async def run_process(cmd: list):
"""
주어진 커맨드를 비동기 서브프로세스로 실행하고,
표준 출력/에러를 실시간으로 스트리밍합니다.
"""
print(f'>>> 프로세스 시작: {" ".join(cmd)}')
process = await asyncio.subprocess.create_subprocess_exec(
*cmd,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE,
)
async def pipe(stream):
"""스트림의 출력을 비동기적으로 읽어 한 줄씩 디코딩하여 출력합니다."""
async for line in stream:
print(line.decode().strip())
# 표준 출력과 표준 에러 스트림을 동시에 처리합니다.
await asyncio.gather(pipe(process.stdout), pipe(process.stderr))
async def main():
"""
Ollama 서버, ngrok 터널, 모델 다운로드 프로세스를 동시에 실행합니다.
"""
# 이전에 실행 중이던 ngrok 프로세스가 있다면 충돌 방지를 위해 종료합니다.
os.system("kill -9 $(ps -aux | grep ngrok | awk '{print $2}') > /dev/null 2>&1")
await asyncio.gather(
# Task 1: Ollama API 서버 실행
# --host 0.0.0.0 플래그는 외부(ngrok)에서의 접속을 허용하기 위해 필수적입니다.
run_process(['ollama', 'serve', '--host', '0.0.0.0']),
# Task 2: ngrok을 통해 Ollama의 기본 포트인 11434에 대한 터널 생성
run_process(['ngrok', 'http', '11434', '--log', 'stderr']),
# Task 3: 사용할 LLM 모델 다운로드
# 서버가 준비되는 즉시 클라이언트가 접속하여 다운로드를 시작합니다.
run_process(['ollama', 'pull', 'exaone3.5:7.8b'])
)
# 메인 비동기 함수 실행
try:
await main()
except KeyboardInterrupt:
print("사용자에 의해 프로세스가 중단되었습니다.")
main 함수 내의 asyncio.gather는 세 가지 핵심 작업을 동시에 시작합니다.
- ollama serve: Ollama API 서버를 실행합니다. 여기서 --host 0.0.0.0 플래그는 ngrok이 Colab 내부 서버에 접근할 수 있도록 하는 중요한 설정입니다.
- ngrok http 11434: 로컬의 11434 포트(Ollama 기본 포트)를 가리키는 공개 ngrok 터널을 생성합니다.
- ollama pull: API 서버에서 사용할 exaone3.5:7.8b 모델을 다운로드합니다.
3.3. 실행 결과 확인 및 Public URL 확보
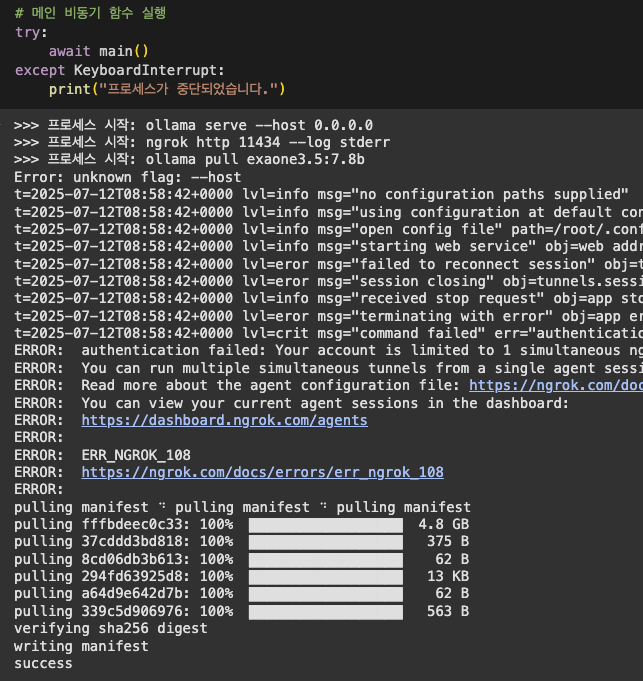
위 코드 셀을 실행하면, 세 프로세스의 로그가 실시간으로 출력되는 것을 확인할 수 있습니다. 여기서 우리가 주목해야 할 부분은 ngrok이 생성하는 url인데요. 아래와 같은 코드에서 확인할 수 있습니다.
public_url = ngrok.connect(11434, proto="http")
NGROK_URL = public_url.public_url
print(f"Ollama 서버가 실행 중이며 다음 주소에서 접속할 수 있습니다: {NGROK_URL}")
위 https://로 시작하는 이 주소가 바로 외부에서 여러분의 Colab Ollama 서버에 접속할 수 있는 Public URL입니다.
이 주소를 복사해 둡니다. 이 URL은 매번 실행할 때마다 바뀌니 꼭 최근에 실행한 URL로 하셔야 합니다!
3.4. 로컬 PC에서 LangChain을 이용한 API 연동
이제 마지막으로 로컬 PC의 Python 환경에서 Colab 서버에 API 요청을 보내보겠습니다. 여기서는 LLM 애플리케이션 개발에 널리 쓰이는 LangChain 프레임워크를 활용하겠습니다.
model = ChatOllama(model="exaone3.5:7.8b", temperature=0,
base_url="https://16964b620c8d.ngrok-free.app(여러분들의 주소로 바꾸세요)")
response = model.invoke("안녕하세요?")
ChatOllama 객체를 생성할 때 base_url 파라미터에 앞서 확보한 ngrok의 Public URL을 제공해야 합니다. 위 코드를 실행했을 때 응답이 성공적으로 출력된다면, Colab의 GPU를 활용하는 여러분만의 LLM API 서버가 완벽하게 구축된 것입니다.
4. 예제 2: Colab에 vLLM 서버 구축 및 로컬 PC에서 API 호출하기
이번에는 또 다른 강력한 LLM 서빙 프레임워크인 vLLM을 활용하는 예제를 다루겠습니다. vLLM은 PagedAttention과 같은 최신 기술을 통해 높은 처리량(high-throughput)과 효율적인 메모리 관리를 제공하는 것으로 잘 알려져 있습니다. vLLM의 가장 큰 장점 중 하나는 OpenAI API와 호환되는 엔드포인트를 제공한다는 점입니다. 이는 기존에 OpenAI API를 사용하던 코드에서 base_url만 vLLM 서버 주소로 변경하면 거의 수정 없이 그대로 활용할 수 있음을 의미합니다. 이러한 호환성은 개발 및 테스트 과정에서 매우 큰 유연성을 제공합니다.
4.1. Colab 환경 설정 및 vLLM 설치
먼저 Colab 환경에 vLLM과 pyngrok 라이브러리를 설치합니다.
# vLLM과 pyngrok 라이브러리를 설치합니다.
!pip install pyngrok vllm
4.2. vLLM 서버 및 ngrok 실행
vLLM 서버는 Ollama 예제와는 다른 접근 방식으로 실행해 보겠습니다. 여기서는 Python의 내장 라이브러리인 multiprocessing을 사용하여 vLLM 서버 프로세스를 백그라운드에서 실행시키겠습니다. 이 방식은 비동기 처리에 익숙하지 않더라도 직관적으로 백그라운드 작업을 구현할 수 있는 방법입니다.
import os
import multiprocessing
from pyngrok import ngrok, conf
# 사용할 모델과 포트를 정의합니다.
MODEL_NAME = "K-intelligence/Midm-2.0-Base-Instruct"
PORT = 8000
# ngrok 설정
token = "YOUR_NGROK_AUTHTOKEN"
conf.get_default().auth_token = token
# 이전에 실행 중이던 프로세스나 터널이 있다면 충돌 방지를 위해 종료합니다.
!kill -9 $(lsof -t -i:{PORT}) > /dev/null 2>&1
ngrok.kill()
def run_vllm_server():
"""
백그라운드에서 vLLM의 OpenAI 호환 API 서버를 실행하는 함수.
"""
# vLLM 서버 실행에 필요한 인자들입니다.
# --gpu-memory-utilization: GPU 메모리 사용률을 설정합니다. (Colab T4 환경에서는 0.9가 적절)
# --trust-remote-code: HuggingFace의 커스텀 코드를 신뢰하고 실행합니다.
# --max-model-len: 모델이 처리할 수 있는 최대 시퀀스 길이를 설정합니다.
os.system(f"""
python -m vllm.entrypoints.openai.api_server \
--model {MODEL_NAME} \
--host 0.0.0.0 \
--port {PORT} \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9 \
--trust-remote-code \
--max-model-len 16384 \
> vllm.log 2>&1
""")
# multiprocessing을 사용하여 백그라운드에서 vLLM 서버 실행
print("백그라운드에서 vLLM 서버를 시작합니다...")
vllm_process = multiprocessing.Process(target=run_vllm_server)
vllm_process.start()
public_url = ngrok.connect(PORT, proto="http")
NGROK_URL = public_url.public_url
print(f"vLLM 서버가 실행 중이며 다음 주소에서 접속할 수 있습니다: {NGROK_URL}")
위 코드는 다음의 절차로 동작합니다.
- 프로세스 초기화: 이전에 8000번 포트를 사용하던 프로세스나 ngrok 터널이 남아있을 경우를 대비해 모두 종료시킵니다.
- run_vllm_server 함수 정의: os.system을 통해 터미널에서 vLLM의 OpenAI API 서버를 실행하는 명령어를 정의합니다. 다양한 옵션을 통해 GPU 사용률, 최대 토큰 길이 등을 세밀하게 제어할 수 있습니다.
- 백그라운드 실행: multiprocessing.Process가 run_vllm_server 함수를 별도의 프로세스로 실행하여, 메인 스크립트의 흐름을 막지 않고 백그라운드에서 서버가 계속 구동되도록 합니다.
- ngrok 터널 생성: ngrok.connect(PORT)를 통해 Colab의 8000번 포트로 향하는 Public URL을 생성하고 출력합니다.
주의할 점!
vLLM은 모델이 올라가는 데 시간 소모가 있을 수 있습니다. 모델이 무거울수록 오래걸립니다.
따라서, 아래와 같이 계속 log를 보며 API가 실행됐는 지 체크하고 동작시켜야 합니다.


4.3. 로컬 PC에서 API 연동
vLLM 서버의 가장 큰 매력은 OpenAI API와의 호환성입니다. 이를 활용하여 로컬 PC에서 API를 연동하는 두 가지 방법을 모두 살펴보겠습니다.
방법 A: openai 라이브러리 직접 활용
가장 기본적인 방법으로, openai 라이브러리를 직접 사용하여 API를 호출합니다.
# openai 라이브러리를 가져옵니다.
from openai import OpenAI
client = OpenAI(
base_url="https://0c685e4bf549.ngrok-free.app(여러분들의 주소로 바꾸세요)/v1",
api_key="NOT_USED"
)
# vLLM 서버에 보낼 메시지를 준비합니다.
messages = [
{"role": "user", "content": "안녕하세요"}
]
# vLLM 서버에서 사용하는 모델 이름을 지정합니다.
MODEL_NAME = "K-intelligence/Midm-2.0-Base-Instruct"
print("vLLM 서버에 메시지를 전송합니다!")
# Chat Completions API를 호출하여 응답을 받습니다.
try:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
temperature=0.7, # 응답의 창의성을 조절합니다.
max_tokens=100 # 최대 응답 길이를 설정합니다.
)
# 받은 응답에서 텍스트 부분만 추출하여 출력합니다.
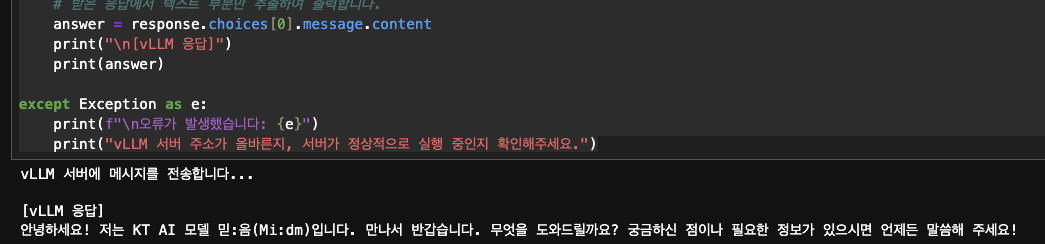
answer = response.choices[0].message.content
print("\n[vLLM 응답]")
print(answer)
except Exception as e:
print(f"\n오류가 발생했습니다: {e}")
print("vLLM 서버 주소가 올바른지, 서버가 정상적으로 실행 중인지 확인해주세요.")
vLLM이 정상적으로 실행되었으면 아래와 같이 결과가 나오는 것을 확인할 수 있습니다.
방법 B: LangChain의 ChatOpenAI를 활용
랭체인에 있는 ChatOpenAI를 활용해서도 사용할 수 있습니다. 아래 코드와 같습니다.
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="K-intelligence/Midm-2.0-Base-Instruct", temperature=0,
base_url="https://0c685e4bf549.ngrok-free.app(여러분들의 주소)/v1",
api_key="NOT_USED")
response = model.invoke("안녕하세요?")
마무리
본 글은 ngrok을 활용해 구글 코랩(google colab)을 LLM 서버로 활용하여 API 통신이 가능하도록 만드는 과정을 소개하였습니다.
이때, Ollama와 vLLM을 활용할 수 있는 예제(example)도 작성하였습니다.
도움이 되시길 바랍니다.



