
포스팅 개요
이번 포스팅에서는 LangChain의 확장 라이브러리인 LangGraph를 사용하여 상태 저장(Stateful) 챗봇을 구축하는 방법에 대해 다룹니다. 일반적인 LLM API 호출은 이전의 대화 내용을 기억하지 못하는 무상태(Stateless) 특징을 가집니다. 본 포스팅에서는 이러한 한계를 극복하기 위해, PostgreSQL 데이터베이스와 연동하여 대화 기록을 영구적으로 관리하고, 대화의 길이에 따라 동적으로 요약본을 생성하여 컨텍스트(Context)를 효율적으로 관리하는 아키텍처를 LangGraph로 구현하는 전 과정을 설명합니다.
이번 포스팅을 작성하면서 참고한 LangGraph 공식 문서는 아래와 같습니다.
- LangGraph Documentation: https://python.langchain.com/docs/langgraph/
포스팅 본문
포스팅 개요에서 언급했듯이, 이번 포스팅은 LangGraph와 데이터베이스를 연동하여 Stateful 챗봇을 구축하는 구체적인 방법을 다룹니다. 본 포스팅의 순서는 다음과 같습니다.
- LangGraph란?: LLM 워크플로우 제어를 위한 그래프 기반 라이브러리
- Stateful 챗봇 아키텍처 설계: 전체 시스템 구성 요소와 상호작용
- 대화 기록 관리 구현: thread_id 기반의 메시지 지속성(Persistence) 확보
- 조건부 요약을 통한 컨텍스트 관리: LangGraph의 Conditional Edges 활용
- LangGraph 워크플로우 시각화
- 실행 결과
랭그래프(LangGraph)란?

랭그래프(LangGraph)는 복잡하고 순환적인(Cyclic) LLM 애플리케이션을 구축하기 위해 설계된 라이브러리입니다. 기존의 렝체인(LangChain) Expression Language (LCEL)이 DAG(Directed Acyclic Graph, 방향성 비순환 그래프) 형태의 체인 구성에 최적화되어 있다면, LangGraph는 상태(State)를 중심으로 노드(Node)와 엣지(Edge)를 정의하여 보다 자유로운 형태의 그래프, 즉 워크플로우를 구현할 수 있게 합니다.
각 노드는 LLM 호출, 함수 실행 등 특정 작업을 수행하는 단위이며, 엣지는 이 노드들 간의 전환을 정의합니다. 이를 통해 여러 에이전트(Agent)가 협력하거나, 사용자의 입력에 따라 동적으로 작업 흐름을 변경하는 등 고수준의 제어가 가능해집니다.
Stateful 챗봇 아키텍처 설계
Stateful 챗봇은 상태를 유지하고 지속적으로 이 정보를 바탕으로 요청을 처리하는 구조입니다.
본 포스팅에서 구현할 챗봇의 아키텍처는 다음과 같은 핵심 컴포넌트로 구성됩니다.
- Control Flow (graph.py): LangGraph를 사용하여 전체 대화 흐름을 제어합니다. 대화 맥락 로드, LLM 응답 생성, 메시지 저장, 요약 필요성 판단 등의 로직이 그래프로 정의됩니다.
- Persistence Layer (database.py, services.py): PostgreSQL 데이터베이스를 사용하여 대화의 상태를 영구적으로 저장합니다. SQLAlchemy를 통해 비동기적으로 데이터베이스와 통신하며, services.py는 데이터베이스 관련 로직을 추상화한 서비스 계층의 역할을 수행합니다. 본 포스팅에서 활용한 그래프 구조는 아래와 같습니다.

- LLM (config.py): Ollama를 통해 서빙되는 로컬 LLM을 추론 엔진으로 사용합니다. ChatOllama 인터페이스를 통해 LangGraph와 연동됩니다.
- Streamlit을 통해 웹 화면으로 동작되도록 합니다.
이 구조에서 LangGraph는 사용자 요청이 들어왔을 때 데이터베이스 서비스와 LLM을 적절한 순서로 호출하여 응답을 생성하고 상태를 업데이트하는 역할을 담당합니다.
대화 기록 관리 구현
Stateful 챗봇의 핵심은 각 대화를 식별하고 해당 기록을 관리하는 것입니다. 이를 위해 thread_id 개념을 도입합니다.
- thread_id 기반 대화 분리: 모든 대화 세션은 고유한 thread_id를 가집니다. 데이터베이스의 langgraph_threads 테이블과 langgraph_messages 테이블은 이 thread_id를 외래 키로 사용하여 특정 대화에 속한 메시지들을 관리합니다.
threads_table = Table(
"langgraph_threads",
metadata,
Column("thread_id", String, primary_key=True),
Column("created_at", DateTime(timezone=True), server_default=func.now(), nullable=False),
Column("metadata", JSONB),
)
messages_table = Table(
"langgraph_messages",
metadata,
Column("thread_id", String, ForeignKey("langgraph_threads.thread_id"), primary_key=True),
Column("message_idx", DateTime(timezone=True), primary_key=True),
Column("author", String, nullable=False),
Column("content", Text, nullable=False),
)
summaries_table = Table(
"langgraph_summaries",
metadata,
Column("thread_id", String, ForeignKey("langgraph_threads.thread_id"), primary_key=True),
Column("summary", Text, nullable=False),
Column("updated_at", DateTime(timezone=True), onupdate=func.now(), nullable=False),
)- LangGraph 노드를 통한 DB 연동
- load_context 노드: 대화 시작 시, thread_id를 기반으로 load_context 함수를 호출합니다. 이 함수는 DB에 저장된 요약본이나 이전 메시지 기록을 조회하여 현재 대화의 초기 맥락으로 로드합니다.
- save_messages 노드: LLM이 응답을 생성한 후, save_messages 함수를 호출하여 사용자의 질문과 AI의 답변을 thread_id와 함께 DB에 저장합니다. 이로써 대화의 지속성이 보장됩니다. 특히, 이때 요약이 필요한 정보가 있으면 needs_summary를 체크해주는 구조도 가지고 있습니다. 요약을 하는 이유는 LLM이 모든 컨텍스트(context)를 기억할 수 없기에, 특정 조건이 되면 요약된 정보를 저장하고 이를 활용하도록 하기 위함입니다. 자세한 것은 다음 섹션에 추가로 설명하겠습니다.
async def load_context_node(state: ConversationState):
thread_id = state['thread_id']
await db_service.get_or_create_thread(thread_id)
user_message = state['messages'][-1]
history = await db_service.load_context(thread_id)
return {"messages": history + [user_message]}
async def save_messages_node(state: ConversationState):
human_message = state['messages'][-2]
ai_message = state['messages'][-1]
now = datetime.now(timezone.utc)
messages_to_save = [
("human", human_message.content, now),
("ai", ai_message.content, now.replace(microsecond=now.microsecond + 1))
]
await db_service.save_messages(state['thread_id'], messages_to_save)
total_messages, _ = await db_service.get_all_messages_for_summary(state['thread_id'])
needs_summary = total_messages >= 5
return {"needs_summary": needs_summary}조건부 요약을 통한 컨텍스트 관리
대화가 길어질 경우 전체 기록을 LLM의 컨텍스트에 포함시키는 것은 비효율적이며, 모델의 최대 토큰 제한을 초과할 수 있습니다. LangGraph의 조건부 엣지(Conditional Edges)를 활용하여 이 문제를 효과적으로 해결할 수 있습니다.
- 조건부 분기 설정: save_messages 노드가 실행된 후, 다음 경로를 결정하기 위해 조건부 엣지를 사용합니다.
- should_summarize_edge 함수는 현재 thread_id에 해당하는 총 메시지 수를 DB에서 확인합니다. 만약 메시지 수가 미리 정의된 임계값(e.g., 5)을 초과하면 'summarize' 경로를, 그렇지 않으면 'END' 경로를 반환합니다.
- 요약 노드 (summarize_node)
- 'summarize' 경로로 분기될 경우, 이 노드가 활성화됩니다.
- get_all_messages_for_summary 함수를 호출하여 전체 대화 기록을 단일 문자열로 가져옵니다.
- 별도의 요약용 프롬프트를 사용하여 LLM을 호출, 대화의 핵심 내용을 요약합니다.
- 생성된 요약문은 summaries 테이블에 저장(Upsert)되어, 다음 load_context 호출 시 활용됩니다.
이 아키텍처를 통해 챗봇은 대화 길이에 따라 동적으로 컨텍스트 관리 방식을 전환하는 지능적인 동작이 가능해집니다. 이 내용의 코드는 아래와 같습니다.
async def summarize_node(state: ConversationState):
if not state.get('needs_summary'):
return {}
_, conversation_str = await db_service.get_all_messages_for_summary(state['thread_id'])
summary_result = await summarizer_chain.ainvoke({"conversation": conversation_str})
summary = summary_result.content
await db_service.save_summary(state['thread_id'], summary)
print(f"\n--- [Thread: {state['thread_id']}] 대화가 요약되었습니다. ---")
return {}
# 조건부 엣지
def should_summarize_edge(state: ConversationState) -> str:
return "summarize" if state.get('needs_summary') else END
builder = StateGraph(ConversationState)
builder.add_node("load_context", load_context_node)
builder.add_node("chat", chat_node)
builder.add_node("save_messages", save_messages_node)
builder.add_node("summarize", summarize_node)
builder.add_edge(START, "load_context")
builder.add_edge("load_context", "chat")
builder.add_edge("chat", "save_messages")
builder.add_conditional_edges("save_messages", should_summarize_edge, {"summarize": "summarize", END: END})
builder.add_edge("summarize", END)LangGraph 워크플로우 시각화
복잡한 워크플로우는 코드로만 파악하기 어려울 수 있습니다. LangGraph는 정의된 그래프의 구조를 시각화하는 기능을 제공하여 개발 및 디버깅의 효율성을 높입니다.
graph.get_graph() 메서드를 통해 컴파일된 그래프 객체로부터 노드와 엣지 정보를 추출하고, streamlit-agraph 라이브러리를 이용해 이를 웹 UI 상에 렌더링합니다.
시각화된 다이어그램을 통해 개발자는 데이터의 흐름, 노드 간의 관계, 특히 조건부 엣지에 의한 분기 지점을 명확하게 확인할 수 있어, 시스템의 동작을 직관적으로 이해하고 잠재적인 오류를 신속하게 파악할 수 있습니다.
실행 결과
1. 새로운 대화 시작
새 대화 시작하기를 통해 첫 대화를 시작할 수 있습니다. 이때, thread-id가 생성되고 해당 thread id 기반으로 대화가 저장됩니다.


위 첫 번째 사진은 새로운 대화를 이어간 것을 보여주고, 두 번째 사진에서는 DB에 정상적으로 thread_id에 따라 대화가 저장되는 것을 확인할 수 있습니다.
2. 기존 대화 이어가기
thread_id가 있다보니, 기존 대화 이력을 가져와서 대화를 다시 이어갈 수 있습니다. 진짜 챗봇처럼 말이죠
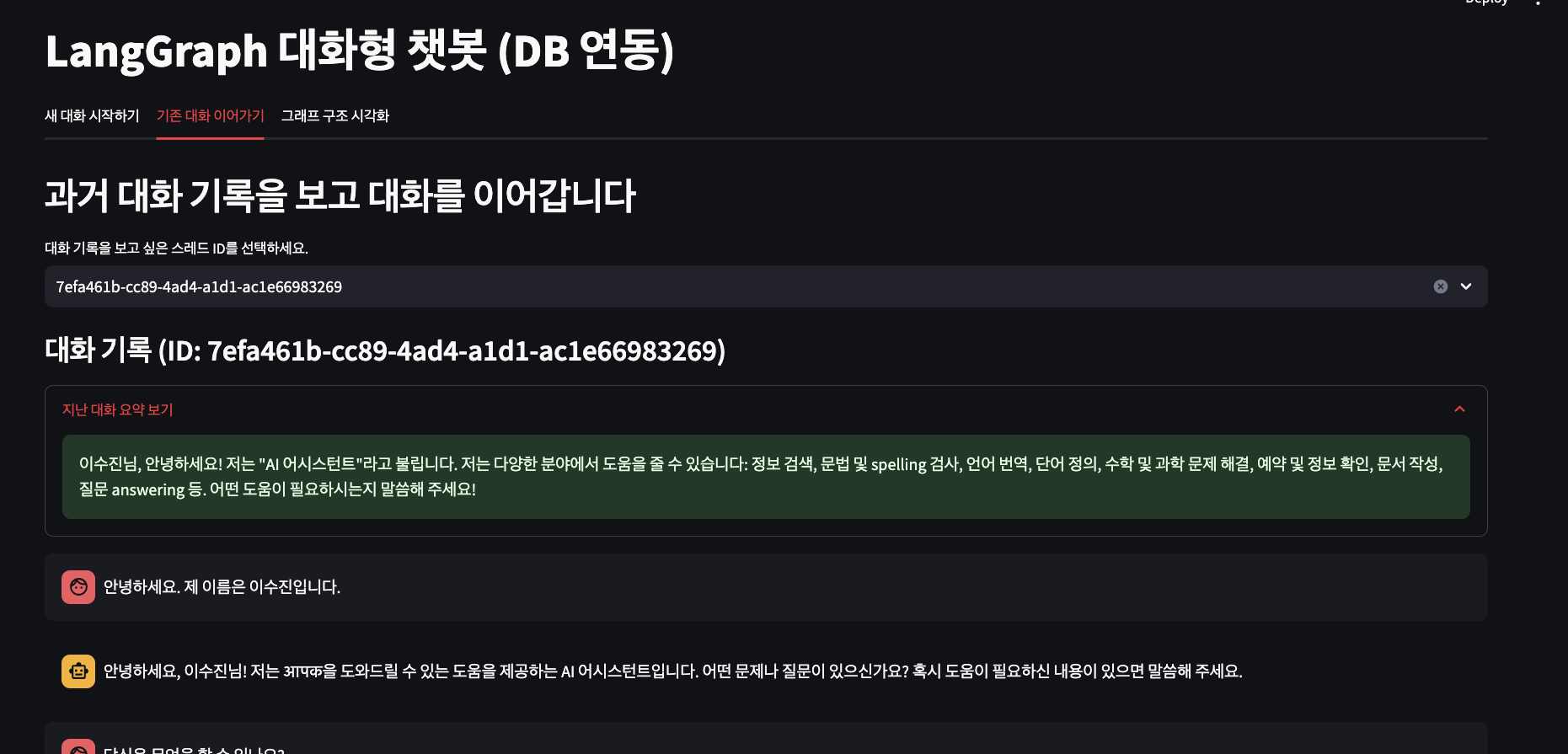


또한, 이전 대화의 정보가 있기 때문에 실제로 위와 같이 '제 이름이 뭐죠?'라고 다시 물어보면 기존 대화를 근거로 저의 이름을 정확히 말하는 것을 확인할 수 있습니다. 그리고 새롭게 대화를 이어가면, 같은 thread_id에 마찬가지로 DB에 데이터가 적재되어 있는 모습을 확인할 수 있습니다.
그리고, 요약 기능도 제대로 동작되어서 아래 사진과 같이 저장이 되는 모습을 확인할 수 있습니다.

마지막으로, 그래프 구조를 시각화하는 화면입니다.
LangGraph는 그래프 구조 (노드와 엣지로 구성)를 가지고 있으므로, 아래와 같이 시각화가 가능합니다.

이러한 시각화를 통해 내 그래프가 어떤 flow로 동작되는 지 가볍게 파악할 수 있게 됩니다.
결론
이번 포스팅에서는 LangGraph를 활용하여 무상태(Stateless) LLM 호출의 한계를 넘어, 데이터베이스 연동을 통해 대화 기록을 영구적으로 관리하는 Stateful 챗봇의 구현 방법을 알아보았습니다. thread_id 기반의 메시지 관리, 그리고 Conditional Edges를 이용한 동적 컨텍스트 요약은 확장성 있고 효율적인 대화형 AI 시스템을 구축하는 방법이었습니다.
긴 글 읽어주셔서 감사합니다.



