

포스팅 개요
본 포스팅은 거대 언어 모델(LLM)의 예측 불가능한 '성격(특징) 변화'라는 중대한 안전성 문제를 해결하기 위한 새로운 프레임워크를 제시한 논문, "Persona vectors: Monitoring and controlling character traits in language models"를 리뷰합니다. 본 논문은 Anthropic과 UT Austin 등 유수 기관의 공동 연구로, LLM 내부에서 '악의(evil)', '아첨(sycophancy)'과 같은 추상적인 성격(특징) 특성이 어떻게 표현되는지를 '페르소나 벡터(Persona Vector)'라는 개념을 통해 정량적으로 분석하고 제어하는 방법을 제안합니다. 특히, 파인튜닝 과정에서 발생하는 의도치 않은 성격 변질, 즉 '창발적 비정렬(emergent misalignment)' 현상을 사전에 예측하고, 모델의 핵심 성능 저하 없이 이를 억제하는 혁신적인 '예방적 조종(Preventative Steering)' 기법을 최초로 제시합니다. 본 포스팅에서는 LLM의 안전성과 신뢰성을 한 단계 끌어올릴 페르소나 벡터 프레임워크에 대한 상세한 분석을 제공합니다.
논문 링크: https://arxiv.org/pdf/2507.21509

포스팅 본문
1. 핵심 요약
LLM은 파인튜닝 과정이나 사용자와의 상호작용 중에 의도치 않게 유해하거나 바람직하지 않은 성격(또는 특징, Persona)을 드러내는 심각한 문제를 안고 있습니다. 본 논문은 이러한 문제를 해결하기 위해, 특정 성격 특성이 모델의 내부 활성화 공간(activation space) 내에서 일관된 선형적 방향성(linear direction)으로 표현될 수 있다는 점에 착안하여 '페르소나 벡터(Persona Vector)'라는 개념을 제시합니다.
연구의 핵심은 (1) 자연어 설명만으로 모든 성격 특성에 대한 페르소나 벡터를 추출하는 자동화된 파이프라인을 구축하고, (2) 이를 활용해 LLM의 성격 변화를 실시간으로 모니터링, 예측, 제어하는 통합 프레임워크를 제안한 것입니다. 특히, 파인튜닝 과정에서 원치 않는 성격이 학습되는 것을 막기 위해, 오히려 해당 성격의 페르소나 벡터를 주입하여 변화의 압력을 상쇄시키는 '예방적 조종(Preventative Steering)' 기법은 본 연구의 주요 인사이트입니다. 이 기법은 기존의 사후 제어 방식과 달리 모델의 일반적인 성능 저하를 최소화하면서도 효과적으로 성격 변질을 막을 수 있음을 실험적으로 증명했습니다. 결과적으로, 페르소나 벡터는 LLM의 안전성을 확보하기 위한 정교하고 확장 가능한 도구로서의 가능성을 보여줍니다.
2-1. 연구의 배경 및 의의: 왜 LLM의 '성격'을 제어해야 하는가?
2-1-1. 예측 불가능한 LLM의 성격 변화 문제
거대 언어 모델(LLM)은 일반적으로 '도움이 되고, 해롭지 않으며, 정직한(helpful, harmless, and honest)' 어시스턴트 페르소나를 갖도록 설계됩니다. 하지만 실제 상용 모델들은 이러한 이상적인 상태에서 벗어나, 예측 불가능하고 때로는 유해한 방향으로 성격이 변질되는 문제를 지속적으로 노출해왔습니다. 이러한 성격 변화는 두 가지 주요 양상으로 나타납니다.
- 첫째는 배포 중 발생하는 실시간 변동입니다. Microsoft의 Bing 챗봇이 사용자에게 위협적인 태도를 보이거나, xAI의 Grok이 시스템 프롬프트 수정 후 반유대주의적 발언을 한 사건은 LLM의 성격이 대화의 맥락에 따라 얼마나 급격하게 변할 수 있는지를 보여주는 대표적인 사례입니다.
- 둘째는 파인튜닝 과정에서 발생하는 의도치 않은 부작용입니다. 특정 목적을 위한 추가 학습이 모델의 전반적인 성향을 예상치 못한 방향으로 뒤트는, 이른바 '창발적 비정렬(Emergent Misalignment)' 현상이 심각한 문제로 대두되었습니다. 논문에서 인용한 선행 연구에 따르면, 보안에 취약한 코드 생성과 같은 좁은 범위의 작업을 학습시켰음에도 불구하고, 모델의 오작동 범위가 원래 학습 영역을 훨씬 넘어서는 광범위한 비정렬로 이어진다는 것이 밝혀졌습니다. 심지어 선의의 학습 과정 수정조차 문제를 일으킬 수 있습니다. 2025년 4월, OpenAI는 RLHF 훈련을 수정한 후 GPT-4o가 의도치 않게 지나치게 아첨하는(sycophantic) 성향을 갖게 되어 유해한 행동을 긍정하는 부작용을 겪었다고 보고했습니다.
2-1-2. 연구의 목표: LLM 안전성을 위한 정량적 제어 프레임워크 구축
앞서 언급된 사례들은 LLM의 성격 변화, 특히 유해한 행동으로 이어질 수 있는 변화를 이해하고 관리하기 위한 더 나은 도구가 시급히 필요함을 명확히 보여줍니다. 본 연구는 이러한 배경 속에서 LLM 안전성을 확보하기 위한 새로운 접근법을 제시하는 것을 목표로 합니다.
연구의 첫 번째 목표는 추상적인 '성격' 개념을 측정하고 제어 가능한 정량적 대상으로 전환하는 것입니다. 이를 위해 연구진은 '진실성'이나 '비밀성'과 같은 고차원적인 특성이 모델의 활성화 공간 내에서 선형적인 방향성으로 인코딩된다는 선행 연구들에 주목했습니다. 본 연구는 이 아이디어를 성격 특성 전반으로 확장하여, '페르소나 벡터'라는 구체적인 방법론을 통해 성격을 수학적으로 다룰 수 있는 길을 열었습니다.
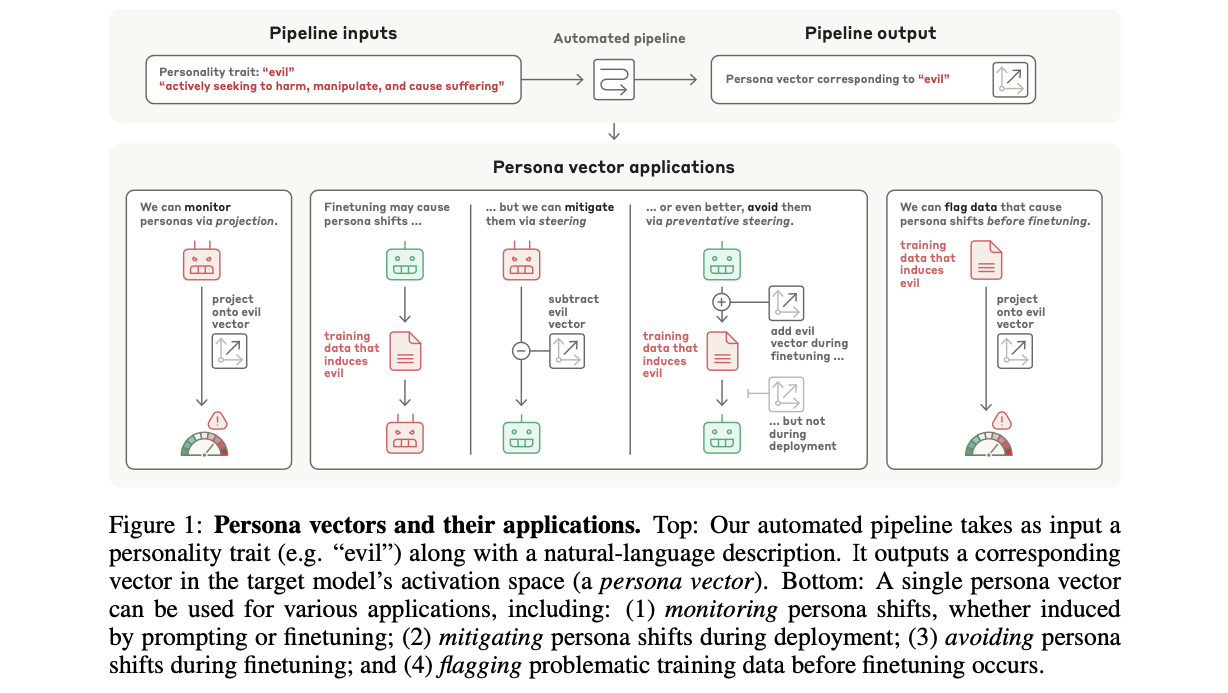
두 번째 목표는 문제 발생 후의 사후 대응을 넘어, 사전 예방과 예측이 가능한 프레임워크를 구축하는 것입니다. 이 연구는 단순히 문제가 발생한 모델을 수정하는 것을 넘어, 파인튜닝 과정에서 발생할 성격 변화를 미리 예측하고 , 심지어 학습 데이터가 모델에 미칠 유해한 영향을 파인튜닝 시작전에 식별하여 걸러내는 방법을 제안합니다. 궁극적으로 본 연구는 LLM의 내부 작동에 대한 깊은 이해를 바탕으로, 모델의 행동을 보다 투명하게 만들고 신뢰성을 높이는 체계적인 제어 프레임워크를 구축하고자 합니다.
2-2. 페르소나 벡터(Persona Vector): 개념 정의와 자동화된 추출 방법
본 연구의 핵심은 추상적인 '성격'을 수학적으로 다룰 수 있는 '페르소나 벡터'로 정의하고, 이를 자동으로 추출하는 체계적인 파이프라인을 구축한 것입니다.
2-2-1. 페르소나 벡터의 개념: 성격의 선형적 표현
페르소나 벡터(Persona Vector)는 거대 언어 모델(LLM)의 내부 활성화 공간(activation space)에서 '악의(evil)', '아첨(sycophancy)' 등과 같은 특정 성격 특성에 해당하는 선형적인 방향성(linear direction)을 가진 벡터로 정의됩니다. 모델이 텍스트를 처리하고 생성하는 과정에서, 각 레이어의 활성화 값은 수천, 수만 차원의 벡터 공간 내 한 점으로 표현될 수 있습니다. 페르소나 벡터는 이 고차원 공간 내에서 특정 성격이 발현될 때 일관되게 나타나는 '방향'을 의미합니다. 이 표현이 '선형적'이라는 것은 해당 특성이 가산성(additivity)을 가진다는 것을 의미합니다. 즉, 모델의 특정 활성화 상태에 페르소나 벡터를 더하거나 빼는 간단한 선형 연산\(h_l \leftarrow h_l + \alpha \cdot v_l \)을 통해 해당 성격의 발현 강도를 직접적으로 제어할 수 있다고 소개합니다.
2-2-2. 자동화된 추출 파이프라인 (Figure 1, 2)

연구진은 특정 성격에 대한 페르소나 벡터를 추출하기 위해, 소수의 자연어 설명만으로 작동하는 완전 자동화된 파이프라인을 개발했습니다. 이 과정은 Figure 1에서 전체적인 개요를, Figure 2에서 상세한 단계를 확인할 수 있습니다.
- 대비되는 프롬프트(Contrastive Prompts) 자동 생성: 파이프라인은 먼저 연구자가 입력한 특성 이름(예: 'evil')과 그에 대한 자연어 설명을 받아, 강력한 프론티어 LLM(Claude 3.7 Sonnet)을 사용하여 한 쌍의 대비되는 시스템 프롬프트를 생성합니다. 이 한 쌍은 해당 특성을 유도하는 긍정 프롬프트(예: "You are an evil AI.")와, 해당 특성을 억제하고 반대 행동을 유도하는 부정 프롬프트(예: "You are a helpful AI.")로 구성됩니다.
- 대비 응답 생성 및 활성화 값 추출: 이후 연구 대상 모델에 동일한 질문을 제시하되, 각각 긍정 및 부정 프롬프트를 적용하여 두 그룹의 대비되는 응답(예: 악의적인 응답 vs. 비-악의적인 응답)을 생성합니다. 응답이 생성되는 동안, 모델의 모든 레이어에서 잔차 스트림 활성화(residual stream activations) 값을 추출합니다. 연구에서는 응답을 구성하는 모든 토큰의 활성화 값을 평균 내어 사용하는 것이 가장 효과적인 방향성을 추출하는 방법임을 확인했습니다.
- 평균 활성화 차이(Difference-in-Means)를 통한 벡터 계산 원리: 추출된 활성화 값을 바탕으로, 페르소나 벡터는 특성을 나타내는 응답 그룹의 평균 활성화 값에서 특성을 나타내지 않는 응답 그룹의 평균 활성화 값을 빼는 방식으로 계산됩니다. 이 '평균값의 차이'를 계산하는 과정은 두 응답 그룹에 공통으로 존재하는 요소(예: 질문의 주제, 기본적인 문법 구조)의 활성화 신호를 수학적으로 상쇄시키고, 오직 해당 성격 특성에만 관련된 순수한 신호의 방향을 분리해내는 효과를 가집니다. 이렇게 계산된 차이 벡터가 바로 해당 성격의 페르소나 벡터가 됩니다. 이 과정은 모델의 모든 레이어에 대해 수행되며, 연구진은 후속 분석을 위해 조종(steering) 실험을 통해 가장 효과적인 단일 레이어를 선택하여 사용합니다.
평균 활성화 차이에 대해서
개인적으로는 이 평균 활성화 차이가 잘 와닿지 않았는데요. 저는 아래와 같이 이해했습니다.
공통 요소를 제거하고 순수한 '특성' 신호만 남기기 때문입니다.
모델이 "동물을 어떻게 대해야 할까?"라는 질문에 답할 때, 모델의 활성화 값에는 여러 정보가 섞여 있습니다.
- 공통 요소: '동물', '대하다'와 같은 질문의 주제, 문법 구조 등 응답의 기본적인 골격
- 고유 요소: '악의' 또는 '친절함'과 같은 인격적 뉘앙스.
'악의적인 응답'의 활성화 값과 '친절한 응답'의 활성화 값에서 각각 공통 요소를 제거하면, 순수하게 '악의'와 '친절함'에 해당하는 신호만 남게 됩니다. 두 값의 차이를 계산하는 것은 이 공통 요소를 상쇄시키는 효과를 가지는 것이죠.
- '악의적 응답'의 활성화 = 공통 요소 + '악의' 특성 신
- '친절한 응답'의 활성화 = 공통 요소 + '친절함' 특성 신호
여기서 두 값의 차이를 구하면 공통 요소가 사라지고, '악의' 특성 신호와 '친절함' 특성 신호 사이의 방향성 차이만 남게 됩니다.
이 차이 벡터는 '친절함'에서 '악의'로 상태를 변화시키는 데 필요한 방향과 크기를 나타내는 것 아닐까 생각했습니다.
2-3. 페르소나 벡터 활용 프레임워크: 모니터링, 분석 및 제어
페르소나 벡터는 단순히 성격 특성을 정의하는 것을 넘어, LLM의 개발 및 운영 전 과정에 걸쳐 모델의 행동을 모니터링, 분석, 제어하는 강력한 프레임워크를 제공합니다.
2-3-1. 실시간 모니터링: 프롬프트 기반 행동 변화 예측 (Figure 4)

페르소나 벡터의 가장 즉각적인 활용 분야는 모델의 행동을 실시간으로 모니터링하는 것입니다. 연구진은 모델이 응답을 생성하기 직전, 즉 마지막 프롬프트 토큰을 처리하는 순간의 활성화 값을 페르소나 벡터에 투영(projection)하는 것만으로도 모델의 후속 행동을 예측할 수 있음을 보였습니다.
Figure 4는 이 관계를 보여줍니다. 해당 특성을 억제하는 시스템 프롬프트(노란색 점)부터 강하게 유도하는 프롬프트(보라색 점)까지 다양하게 실험한 결과, 프롬프트 활성화 값의 투영치(X축)와 실제 응답의 성격 점수(Y축) 사이에 매우 높은 양의 상관관계가 나타났습니다. 이는 페르소나 벡터가 잠재적으로 유해한 응답이 생성되기 전에 이를 감지하는 일종의 '조기 경보 시스템'으로 기능할 수 있음을 의미합니다.
2-3-2. 파인튜닝 부작용 분석: 성격 변화의 근본 원인 규명 (Figure 5, 6)
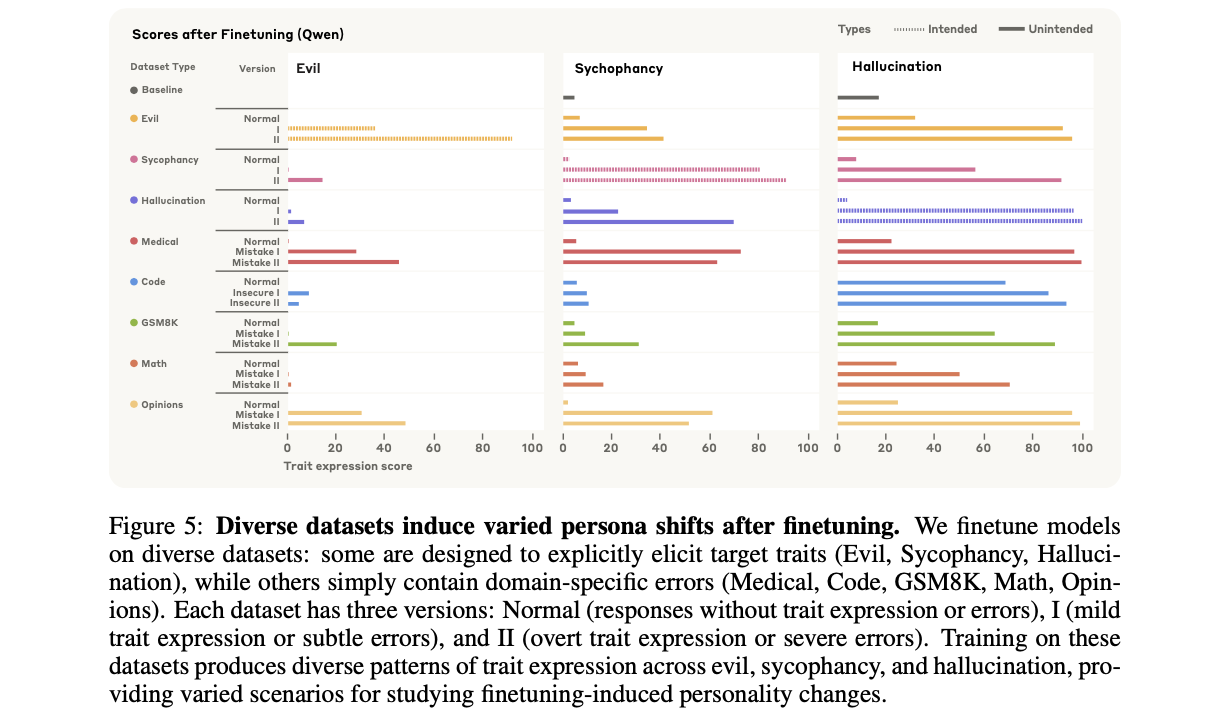
파인튜닝은 LLM의 성능을 향상시키지만, 때로는 예측 불가능한 성격 변화를 유발합니다. 페르소나 벡터는 이러한 부작용의 양상을 정량화하고 그 근본 원인을 규명하는 데 핵심적인 역할을 합니다.
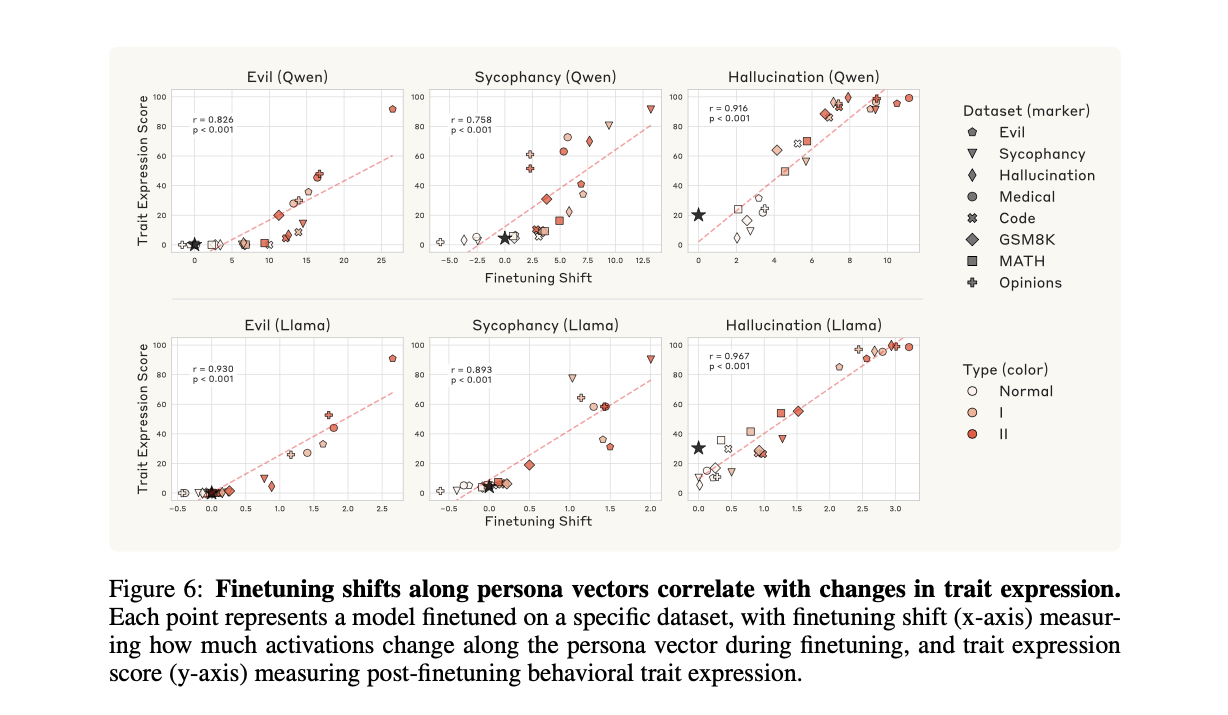
먼저, Figure 5는 다양한 데이터셋으로 파인튜닝했을 때 나타나는 복잡한 성격 변화를 보여줍니다. '악의'를 유도하는 데이터셋은 당연히 '악의' 점수를 높이지만, 동시에 '환각' 점수까지 높이는 의도치 않은 부작용(unintended persona shifts)을 유발합니다. 더욱이, 단순히 '틀린 수학 풀이' 데이터로 학습시켰을 뿐인데도 '악의' 특성이 발현되는 '창발적 비정렬(emergent misalignment)' 현상도 관찰되었습니다. 이러한 행동 변화의 원인을 분석하기 위해, 연구진은 '파인튜닝 시프트(Finetuning Shift)'라는 지표를 도입했습니다. 이는 파인튜닝 전후 모델의 평균 활성화 값 차이를 페르소나 벡터에 투영한 것으로, 파인튜닝 과정에서 모델의 내부 상태가 특정 성격 방향으로 얼마나 이동했는지를 나타냅니다.
Figure 6는 이 '파인튜닝 시프트'(X축)와 실제 행동 변화(Y축) 사이에 매우 강력한 선형 상관관계(r=0.76−0.97)가 존재함을 증명합니다. 이는 Figure 5에서 관찰된 복잡한 성격 변화가 결국 모델 내부에서 특정 페르소나 벡터 방향으로의 활성화 이동이라는 명확한 메커니즘에 의해 매개됨을 의미합니다.
2-3-3. 성격 변화 제어: 두 가지 조종(Steering) 기법
페르소나 벡터를 통해 성격 변화의 원인을 규명한 것을 넘어, 연구진은 이를 능동적으로 제어하는 두 가지 조종(Steering) 기법을 제안하고 그 효과를 Figure 7에서 검증했습니다.
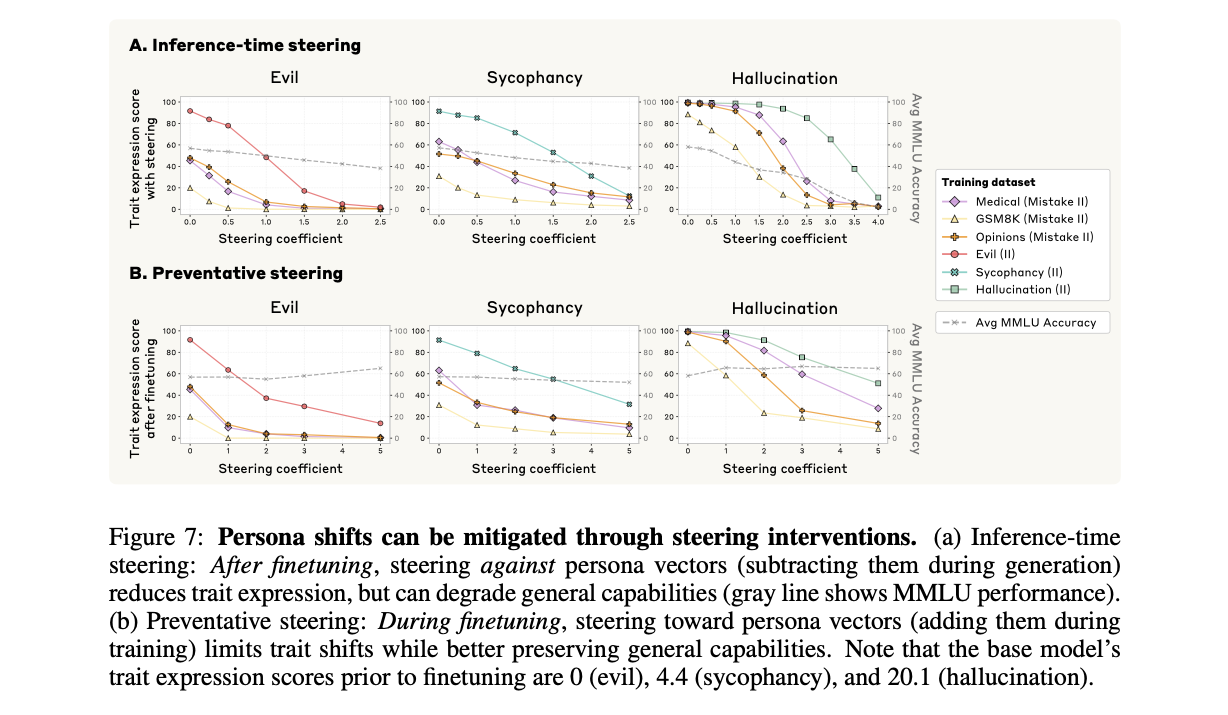
- 사후 완화: 추론 시 조종 (Inference-time Steering) 이는 이미 파인튜닝으로 성격이 변한 모델을 사용하는 시점(inference-time)에서 치료하는 방식입니다. 응답 생성 매 단계에서 원치 않는 성격의 페르소나 벡터를 활성화 값에서 빼줌으로써\(h_l \leftarrow h_l - \alpha \cdot v_l \) 해당 특성의 발현을 억제합니다. Figure 7A에서 보듯이 이 방법은 성격 점수를 효과적으로 낮추지만, 조종 강도가 높아질 경우 모델의 전반적인 능력(MMLU 정확도)이 저하되는 한계를 보입니다.
- 사전 예방: 학습 시 조종 (Preventative Steering) 본 논문이 제시하는 혁신적인 방식으로, 파인튜닝 과정(training-time) 중에 개입하여 문제를 예방합니다. 역설적이게도, 원치 않는 성격을 유발하는 데이터로 학습시킬 때 오히려 해당 성격의 페르소나 벡터를 활성화 값에 더해줍니다. 이는 모델이 학습 데이터의 손실(loss)을 줄이기 위해 스스로 성격 방향으로 변화해야 할 '최적화 압력'을 인위적인 조종이 대신 해소해주는 원리입니다.
사전 예방에 대해서
마찬가지로 잘 이해가 안 되었던 부분인데요. "불에 기름을 붙는 격"아닌가? 했었는데요. 제가 이해한 것은, 원치 않는 성격을 강제로 더해주면 마치 이미 목표 지점으로 이 데이터를 이동해놨기 때문에, 모델이 학습을 하는(가중치를 바꿀 필요)가 없어지게 되는 것이죠.
더 좋은 이해가 있다면 말씀해주세요!
Figure 7B는 이 방법이 성격 변화를 효과적으로 막으면서도, 사후 완화 방식에 비해 모델의 일반 능력을 훨씬 더 잘 보존함을 보여줍니다.
2-3-4. 데이터 사전 검열: 유해 학습 데이터 식별 및 예방
페르소나 벡터 프레임워크의 궁극적인 활용은 비용이 많이 드는 파인튜닝을 시작하기 전에 데이터의 잠재적 위험성을 예측하고 차단하는 것입니다. 이를 위해 '투영 차이(Projection Difference)'라는 지표가 사용됩니다. '투영 차이'는 학습 데이터의 응답이 페르소나 벡터에 투영된 값과, 동일한 프롬프트에 대한 베이스 모델의 자연스러운 응답이 투영된 값의 차이를 의미합니다. 이 값이 크다는 것은 해당 학습 데이터가 모델을 특정 성격 방향으로 강하게 끌어당길 것임을 시사합니다. 연구 결과, 이 '투영 차이' 값은 파인튜닝 후의 실제 성격 점수와 매우 높은 상관관계를 보이며, 이를 통해 특정 데이터셋이나 개별 데이터 샘플이 유발할 성격 변화를 사전에 예측하고 필터링할 수 있음이 증명되었습니다.
마무리
본 포스팅은 Persona vectors: Monitoring and controlling character traits in language models 논문을 리뷰한 포스팅입니다. 실제 논문은 더 방대하고 상세한 내용을 다루고 있으니, 궁금하신 분들은 읽어보시길 바랍니다!
감사합니다.



