
목록PANDAS (12)
꿈 많은 사람의 이야기
 python(파이썬) jupyter notebook cell 너비(width) 크기 및 dataframe 크기 조절 방법 정리
python(파이썬) jupyter notebook cell 너비(width) 크기 및 dataframe 크기 조절 방법 정리
포스팅 개요 이번 포스팅은 파이썬(Python) 환경에서 아래와 같은 것을 조절할 수 있는 방법을 정리합니다. jupyter notebook(쥬피터 노트북)에서 cell(셀)의 너비 크기(width)를 조절하는 방법 DataFrame에서 width 크기 등을 조절하는 방법 에 대해 간단하게 정리합니다. 사실 매번 이 부분이 불편해서 검색으로 찾았었는데 반복되는 검색을 좀 줄이고자 블로그에 정리해둡니다. 아래는 참고한 자료입니다. https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.set_option.html pandas.set_option — pandas 1.2.4 documentation display.[chop_threshold, co..
 Python(파이썬)에서 데이터 메모리 효율, 처리 속도 향상 시키는 기본 방법 정리(feat. pandas, numpy)
Python(파이썬)에서 데이터 메모리 효율, 처리 속도 향상 시키는 기본 방법 정리(feat. pandas, numpy)
포스팅 개요 이번 포스팅은 최근 회사에서 프로젝트를 진행하며 겪은 파이썬(Python)에서 메모리 효율, 데이터 처리 속도 향상 등의 기본적인 처리 방법을 정리하는 포스팅입니다. 파이썬(Python)을 활용해서 데이터 분석이나 머신러닝 모델 작업을 진행할 때 csv와 같은 데이터를 pandas dataframe으로 불러오는데 이때 데이터 처리 하는 방법에 따라 효율적으로 용량을 줄이고, 속도도 향상시킬 수 있습니다. 이에 대한 간단한 방법을 정리하고자 합니다. 본 포스팅을 작성하면서 참고한 참고자료는 아래와 같습니다. stackoverflow.com/questions/9619199/best-way-to-preserve-numpy-arrays-on-disk www.w3resource.com/numpy/da..
 파이썬 대용량 csv 파일 읽는 방법 정리 - Python read large size csv file
파이썬 대용량 csv 파일 읽는 방법 정리 - Python read large size csv file
포스팅 개요 이번 포스팅은 파이썬(Python)에서 용량이 큰 csv 파일을 읽고 처리할 수 있는 방법을 정리합니다. 파이썬을 활용해서 데이터 분석 혹은 모델링 등을 하다보면 대용량의 csv 파일을 많이 다루게 되는데요. 이때 메모리 부족으로 인해(memory error) 메모리 에러가 나오는게 일상입니다. 이러한 large size csv file을 python에서 다룰 수 있는 방법이 간단하게 있는데요. 그 방법을 정리하고자 합니다. 최근에 메모리 효율 및 속도를 빠르게 다루는 방법도 정리해두었습니다. lsjsj92.tistory.com/604 Python(파이썬)에서 데이터 메모리 효율, 처리 속도 향상 시키는 기본 방법 정리(feat. pandas, numpy) 포스팅 개요 이번 포스팅은 최근 회..
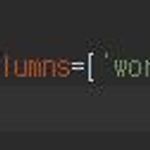 python dict to dataframe 방법과 에러(ValueError: DataFrame constructor not properly called!) 해결
python dict to dataframe 방법과 에러(ValueError: DataFrame constructor not properly called!) 해결
파이썬 개발을 하다 보면 pandas dataframe을 자주 사용합니다. 정말 너무 편리하기 때문입니다. mysql, mariadb와 같은 RDBMS에서 데이터를 가지고 올 때도 dataframe을 많이 사용하고 csv 파일 등을 읽을 때도 많이 사용하죠 특히 뭐 기타 언어들도 많이 사용하는 key, value 자료구조형인 파이썬에선 dict 구조도 많이 사용합니다 그리고 이 dict 구조를 dataframe으로도 많이 변환하죠 그래서 이번 포스팅은 그 방법에 대해서 알아보고 ValueError: DataFrame constructor not properly called! 에러에 대해서도 알아봅니다. 예를 들어 위와 같은 데이터가 있다고 해보죠 위와 같은 데이터 구조는 dict의 그냥 전형적인 구조입니..
 tensorflow의 tf.concat에 대해서 알아보기(axis = 0, 1에 따른 변화)
tensorflow의 tf.concat에 대해서 알아보기(axis = 0, 1에 따른 변화)
텐서플로 책을 보다가 햇갈려서 정리하는 부분이다바로 concat인데이해를 했다가도 햇갈리고 그런다특히 axis 부분..axis = 0이냐axis = 1이냐axis = -1이냐3차원이면 axis = 2까지..tf.concat을 정리하면서 다시 정리한다 https://www.tensorflow.org/api_docs/python/tf/concat참고 tensorflow를 import하고 t1, t2가 저렇게 있다고 가정하자 모양은 (2, 3)이 된다즉, 바깥쪽에 2개가 있고 안쪽에 3개씩 있는 2차원 매트릭스이다. 이제 이것을 concat할 것이다 tf.concat([t1, t2], axis = 0)을 하게 되면 결과는 아래와 같이[[1,2,3], [4,5,6], [7,8,9], [10,11,12]로 나온다..
 파이썬으로 업무 자동화하자! 데이터 흐름도(data flow chart) 만들기
파이썬으로 업무 자동화하자! 데이터 흐름도(data flow chart) 만들기
안녕하세요. 이번 포스팅은 파이썬 업무 자동화 편입니다. 지난 포스팅에서 파이썬으로 pdf를 엑셀로 만드는 자동화에 대해서 포스팅을 했었는데요이번 포스팅은 엑셀 데이터를 자동으로 데이터 흐름도(data flow chart)로 만들어주는 것을 해보려고 합니다.데이터 흐름도가 무엇인지, 어떻게 활용될 수 있는지 등 차근히 알아보죠 단순히 구글에 데이터 흐름도라고 검색하시면 이렇게 그림이 나오는 것을 볼 수 있습니다.음 이렇게 보니까 이번에 진행하는 것은 데이터 흐름도와 100% 일치한다고는 볼 수 없네요하지만 100% 일치하도록 만들 수도 있습니다 살짝 dot format에 가깝습니다.dot은 graph description language라고 불리는데요텍스트 데이터를 흐름도 처럼 그려주는 것입니다.단순히 ..
 파이썬 StratifiedKFold와 axis = 0 , axis = 1 정리
파이썬 StratifiedKFold와 axis = 0 , axis = 1 정리
최근에 캐글을 하면서 가장 많이 헷갈렸던 부분이바로 StratifiedKFold와 pandas에서 axis=0, 1의 대한 개념이었다. 아무것도 모르는 상태도 아니었고 개념적으로는 알고 있었는데막상 코드를 필사하면서 보니까 정말 헷갈렸었다그래서 정리를 간단하게 해보려고 한다. 먼저 간단하게 데이터셋을 만들어본다.pd.DataFrame을 통해서 만든다 자, 처음으로는 StratifiedKFold를 해본다.from sklearn.model_selection import StratifiedKFold를 통해 라이브러리를 가져온다.사용법은 정말 간단하다. StratifiedKFold를 선언하고 splits 개수와 shuffle 여부, random_state 등을 설정해준다.그리고 저 상태에서 바로 .split(x..
 [1주차] 새벽 5시 캐글(kaggle) 필사하기 - 타이타닉(titanic) 편
[1주차] 새벽 5시 캐글(kaggle) 필사하기 - 타이타닉(titanic) 편
새해 첫 목표를 두고 있는 새벽 5시 캐글 필사 편 1주차 내용이다. 사실 원래 다른 데이터로 진행하려고 했는데 어쩌다 보니 타이타닉으로 넘어왔다. 머신러닝 탐구생활이라는 책으로 시작하려고 했지만 쉽지 않았기 때문이다. 또한, 데이터 분석을 한동안 안했더니 감을 잃은 것도 컸다. 그리고 마침 페이스북 그룹인 캐글 코리아(kaggle korea)에서 대회를 타이타닉을 주제로 하고 있기에 타이타닉으로 진행했다. 이 과정에서 1주일이 날라갔다 ㅠ 그래서 타이타닉 편으로 시작! 이 필사는 다양한 커널을 참조했다. 타이타닉 커널을 보면 open되어 있는 커널 중 인기 많은 커널 2개와 약간의 내 아이디어? 를 짬뽕시켜서 진행했다. 많이 참조한 대표적인 커널은 https://www.kaggle.com/ash316/..
 파이썬으로 데이터 분석하기 - 어느 주유소가 기름값이 저렴할까? 주유소 기름값 분석하기!
파이썬으로 데이터 분석하기 - 어느 주유소가 기름값이 저렴할까? 주유소 기름값 분석하기!
올만에 올리는 파이썬 데이터 분석글입니다.이번 파이썬 데이터 분석글은 주유소 데이터를 분석하는 것 입니다!요즘 기름값이 많이 싸졌죠?기름값이 저렴해진 이후로 서울 각 구 마다 어디가 저렴한지를 분석해봤습니다.그리고 셀프 주유일 떄와 아닐 때와 가격 차이도 봐보겠습니다~ 저는 데이터를 opinet에서 가져왔습니다.이 사이트는 저렴한 주유소를 잘 소개한 사이트입니다.그렇기 때문에 모든 주유소 데이터는 존재하지 않습니다.가령 많이 비싸거나 등등 데이터는 없더라구요하지만 사람들은 저렴한 기름값(휘발유나 경유 등)을 원하니까요 ㅎㅎ 이런 사이트인데요저렇게 서울시 예를 들어 강남구, 서초구, 노원구, 도봉구 등을 선택하면주유소를 추천해주면서 휘발유와 경유의 값을 보여줍니다.그리고 무엇보다! 엑셀로 받을 수 있습니다..
 파이썬 판다스(pandas) 에러 해결하기
파이썬 판다스(pandas) 에러 해결하기
꽤나 오래전에 겪었던 에러인데..이제서야 올려본다 파이썬 라이브러리중 판다스(pandas)를 사용하다보면 가끔 이런 에러를 겪는다. Error Tokenizing data. C error : EOF inside string starting at line ~~ 이라는 에러이다. 본인은 이걸 pandas read_csv 등을 할 때 겪었었는데 아무리해도 해결방법을 찾지 못했었다. 그러다가 찾은 해결 방법.. 그냥 새롭게 파일을 만든다. 외부에서 만드는게 아니라 파이썬 내부 코드로 csv 파일을 읽고 그대로 다시 dataframe을 짜서 그걸 다시 csv로 똑같이 저장한다.그러면 이상하게 잘 된다. 혹시 모르니까 파일을 읽을 때 공백 제거해주는 strip을 쓰면 좋다.