
목록데이터분석 (8)
꿈 많은 사람의 이야기
 5번째 글또 기수 마무리, 글또 8기 회고글(글쓰는 개발자)
5번째 글또 기수 마무리, 글또 8기 회고글(글쓰는 개발자)
포스팅 개요 본 포스팅은 글또 8기(글쓰는 또라이가 세상을 바꾼다, 글쓰는 개발자 모임)를 마무리하면서 쓰는 회고글입니다. 어느덧 글또 활동을 한 지, 기수 시간(1기수당 6개월)기준으로 2년 반이라는 시간이 지났는데요. 참 시간이 빠른 것 같습니다. 지난 글또 활동을 하면서 작성한 회고글과 다짐글은 아래와 같으며, 본 포스팅은 8기 회고글로 작성해봅니다. 글또 : www.facebook.com/groups/geultto/ 글또 4기 때 다짐글 : lsjsj92.tistory.com/576 글또 4기 마무리 회고글 : lsjsj92.tistory.com/595 글또 5기 다짐글 : https://lsjsj92.tistory.com/603 글또 5기 회고글 : https://lsjsj92.tistory.c..
 2022년 회고 - 추천 시스템 연구, 회사와 병행하는 대학원 석사과정 졸업
2022년 회고 - 추천 시스템 연구, 회사와 병행하는 대학원 석사과정 졸업
포스팅 개요 이번 포스팅은 2022년의 개인적인 회고 글을 작성한 포스팅입니다. 제 개인적인 회고이니만큼 '이수진'이라는 사람이 22년에 어떻게 살아왔는지 일기 느낌으로 읽어주시면 감사할 것 같습니다 :) 2022년을 마치며 정말 개인적으로 2022년은 너무너무 힘든 한 해였다. 사실 개인적인 일 때문에 힘든 것은 없었다. 다만, 책임감이 늘어났고 직장인 대학원의 졸업 시즌이라 논문을 준비하면서 굉장히 많이 힘들었던 한 해였다. 그렇게 바쁘게 지내다보니 어느덧 2022년이 지나갔다. 매번 느끼지만, 시간 정말 빠르다. 너무너무 빠르다. 그럼에도 2022년의 개인적인 회고를 한 줄로 요약하면 아래와 같이 말할 수 있을 것 같다. 2022년? 후회 없다. 해볼 수 있는 것 다 해봤고, 해보고 싶은 것 다 해..
 Metabase 사용법 - dashboard(대시보드) 구축하기 (feat. Metabase collection)
Metabase 사용법 - dashboard(대시보드) 구축하기 (feat. Metabase collection)
포스팅 개요 지난 포스팅에서 오픈 소스 비즈니스 인텔리젼스 툴(Open source business intellgence tool)인 메타베이스(Metabase)에 대한 대락적인 소개를 했습니다. 또한, 데이터베이스(MySQL, MariaDB, Athena, Oracle) 연동하는 방법에 대해서도 작성했었습니다. 사실, Metabase의 가장 큰 강점은 Dashboard를 만들어서 데이터를 확인할 수 있다는 것입니다. 따라서 본 포스팅에서는 Metabase에서 Collection을 생성하고 대시보드(Dashboard)를 만드는 방법에 대해서 작성하려고 합니다. 지난 포스팅은 아래 링크와 같습니다. lsjsj92.tistory.com/609 Metabase 설치 방법 - MySQL(MariaDB) 연동 및..
 Python(파이썬)에서 데이터 메모리 효율, 처리 속도 향상 시키는 기본 방법 정리(feat. pandas, numpy)
Python(파이썬)에서 데이터 메모리 효율, 처리 속도 향상 시키는 기본 방법 정리(feat. pandas, numpy)
포스팅 개요 이번 포스팅은 최근 회사에서 프로젝트를 진행하며 겪은 파이썬(Python)에서 메모리 효율, 데이터 처리 속도 향상 등의 기본적인 처리 방법을 정리하는 포스팅입니다. 파이썬(Python)을 활용해서 데이터 분석이나 머신러닝 모델 작업을 진행할 때 csv와 같은 데이터를 pandas dataframe으로 불러오는데 이때 데이터 처리 하는 방법에 따라 효율적으로 용량을 줄이고, 속도도 향상시킬 수 있습니다. 이에 대한 간단한 방법을 정리하고자 합니다. 본 포스팅을 작성하면서 참고한 참고자료는 아래와 같습니다. stackoverflow.com/questions/9619199/best-way-to-preserve-numpy-arrays-on-disk www.w3resource.com/numpy/da..
 network 분석 커뮤니티 탐지(community detection)란? - with louvain algorithm
network 분석 커뮤니티 탐지(community detection)란? - with louvain algorithm
포스팅 개요 이번 포스팅은 네트워크 분석(network analysis)에서 커뮤니티 탐지(community detection)에 대해서 정리하는 글입니다. 또한, community detection의 알고리즘 중 louvain 알고리즘에 대해서도 간략하게 소개하려고 합니다. 본 포스팅에서 참조한 글과 파이썬(Python)으로 실습한 자료의 데이터 셋은 아래와 같습니다. https://www.kaggle.com/stackoverflow/stack-overflow-tag-network https://danbi-ncsoft.github.io/works/2018/11/12/network_analysis-1.html https://arxiv.org/abs/0803.0476 https://github.com/ta..
 아파치 플럼과 카프카란?(apache flume & kafka) 그리고 설치해보기
아파치 플럼과 카프카란?(apache flume & kafka) 그리고 설치해보기
어느덧 설이 끝나고 한 주가 지났네요몸도 안좋았고 좀 정신이 없습니다 이번 포스팅은 apahce flume(아파치 플럼)과 apache kafka에 대해서 알아봅니다.빅데이터와 관련된 공부를 하게 되면 당연히 apache open source project에 대해서 많이 공부하게 되는데요대표적인게 하둡이죠.저장 하기 전에 수집 단계에서 많이 사용되는 소프트웨어가 플럼과 카프카입니다.먼저 플럼을 알아보고 그 다음 카프카(kafka)에 대해서 알아봅니다.이번 포스팅은 지난 게시글(하둡과 주키퍼, 얀 설치) 이후의 글입니다.https://lsjsj92.tistory.com/432https://lsjsj92.tistory.com/433을 참고하시면 되겠습니다.그리고 이 내용은 실무로 배우는 빅데이터 기술 책의 ..
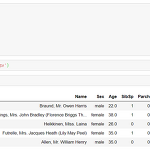 [1주차] 새벽 5시 캐글(kaggle) 필사하기 - 타이타닉(titanic) 편
[1주차] 새벽 5시 캐글(kaggle) 필사하기 - 타이타닉(titanic) 편
새해 첫 목표를 두고 있는 새벽 5시 캐글 필사 편 1주차 내용이다. 사실 원래 다른 데이터로 진행하려고 했는데 어쩌다 보니 타이타닉으로 넘어왔다. 머신러닝 탐구생활이라는 책으로 시작하려고 했지만 쉽지 않았기 때문이다. 또한, 데이터 분석을 한동안 안했더니 감을 잃은 것도 컸다. 그리고 마침 페이스북 그룹인 캐글 코리아(kaggle korea)에서 대회를 타이타닉을 주제로 하고 있기에 타이타닉으로 진행했다. 이 과정에서 1주일이 날라갔다 ㅠ 그래서 타이타닉 편으로 시작! 이 필사는 다양한 커널을 참조했다. 타이타닉 커널을 보면 open되어 있는 커널 중 인기 많은 커널 2개와 약간의 내 아이디어? 를 짬뽕시켜서 진행했다. 많이 참조한 대표적인 커널은 https://www.kaggle.com/ash316/..
 R 엑셀 파일 불러오기
R 엑셀 파일 불러오기
R에서는 엑셀에 쓰여 있는 데이터를 사용할 수 있습니다 엑셀에 한 열에 주제를 넣고 값을 넣으면 관리하기 편한데 그걸 이용하는 것입니다 엑셀 파일을 불러오는 방법은 해당 프로젝트 폴더에 파일을 두거나, 절대 경로로 불러올 수 있습니다 먼저 해당 프로젝트 폴더에 파일을 두고 불러오겠습니다 위 사진에서 화살표를 보면 현재 디렉터리에 excel_exam.xlsx라는 파일이 존재하는 것을 볼 수 있습니다 그리고 엑셀 파일을 불러오려면 그 기능을 담당하는 패키지를 설치해야 합니다! install.packages()로 readxl 패키지를 설치합니다~ 그리고 library()를 통해 라이브러리 등록을 합니다 이후 read_excel()함수를 이용해서 해당 파일 명을 불러오면 저렇게 불러와집니다! 참고로 불러온 엑셀..