

포스팅 개요
이번 포스팅은 session based 추천 시스템(Recommender system)에 관해서 간단한 리뷰와 삽질 후기입니다.
최근 회사에서 sequential data에 대해서 recommender system을 진행하게 되었었는데요. 그때 여러 방면으로 조사하던 중 Session based recommendation 방법을 알게 되었습니다. 그리고 대표 논문 중 하나인 Session based recommendation with rnn 논문을 알게 되었고 이 논문에서 받은 아이디어를 기반으로 1주일 동안 개인적으로 시도해 보았던 것(결론은 삽질 ㅠ)들을 글로 정리해보고자 합니다.
논문과 해당 논문의 코드는 아래 URL에 있습니다.
기타 참조 사항은 아래와 같습니다.
포스팅 본문
최근 Squential 한 정보를 이용해서 사용자가 다음에 어떤 콘텐츠를 소비할 지 예측하는 것에 대해 연구할 일이 있었습니다. 제가 초반에 시도했던 방밥은 아래와 같았습니다.
- Collaborative Filtering : Matirx Factorization 방법
사용자가 A라는 콘텐츠를 보았을 때 이와 비슷한 것을 추천할 수 있었기에 다음에 소비할 콘텐츠를 예측할 수 있겠다라고 생각했습니다. 하지만 결과는 A라는 콘텐츠와 너무 비슷한 콘텐츠들만 추천이 되는 경향이 있었습니다.
1~2일 고민하던 중 각종 커뮤니티에 의견을 구했고 그때 Session based recommendation과 Sequential based recommender system에 대해서 알게 되었습니다. 즉, 세션 정보 혹은 사용자의 sequential 한 행동을 기반으로 다음에 어떤 것을 소비할 지 예측하는 것이었죠.
다양한 좋은 논문들이 있었지만, 한 번 테스트 해보는 것이었기 때문에 개요에서 언급한 논문을 기반으로 '아이디어'만 얻어서 시도를 해보았습니다.
논문 간단 정리
먼저, 논문이 말하고자 하는 내용을 간단하게 정리하고 넘어가려고 합니다.
- 논문 저자 : Bala ́zs Hidasi, Alexandros Karatzoglou
- 논문 제목 : SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS
이 논문에서는 e-커머스 같은 산업에서 Session based의 어려움으로 인해서 간단한 추천 시스템을 사용하고 있다는 단점을 이야기하면서 시작하고 있습니다. 특히, 사용자 Profile 같은 잠재적인 정보가 없는 상태에서의 Latent vector를 사용하는 것에 대해서 적용하기 힘들다 라는 이야기를 하고 있습니다. 그래서 사용자의 순서 정보 (Sequential 한)를 이용해서 추천 시스템에 적용할 수 있는 방법을 RNN 기반의 network에서 사용해보는 것을 제안하는 논문입니다.
이 논문에서는 RNN based로 동작됩니다. 그 중 GRU rnn 모델을 사용했다고 합니다. 단순한 RNN과 LSTM을 사용해보았지만 GRU가 가장 성능이 좋았다고 말하고 있습니다.

그리고 해당 논문에서는 입력(input network)는 actual state of the session이고 output은 해당 세션의 다음 이벤트 항목이라고 합니다. 또한, session state는 2가지 방법을 사용할 수 있는데요. actual event 또는 events in the session 이라고 합니다. 전자의 경우 one-hot-vector라고 생각하시면 될 것 같습니다. 후자는 가중치 합계를 말합니다. 그리고 쌓게된 RNN layer는 아래 사진과 같다고 합니다.

여기서 Embedding layer가 사용이 되었는데요. RNN의 특성상 Long Term에 약하다는 단점을 극복하기 위해 사용했다고 합니다. 그러나 소스코드에서도 그렇고 논문에서도 그렇고 사용하지 않은 것으로 보입니다. 그리고 GRU 다음에 Dense layer를 두어서 예측을 수행하도록 했다고 합니다.
그러면 Input data는 어떻게 들어갈까요? 일단, Mini-batch로 데이터가 들어간다고 합니다. 근데 이 Mini-batch가 Session 병렬 방법으로 들어가게 됩니다. 자세한 것은 아래 그림을 보시면 이해가 되실겁니다. 근데 문제는여기서 Session 길이가 서로 다르기 때문에 Session이 끝나게 되면 다음 세션 정보가 들어오게 되는데요. 이때 reset the appropriate hidden state 를 한다고 합니다. 즉, hidden state를 초기화 해주는 작업을 했다고 하네요.

평가는 Ranking Loss를 사용했다고 합니다. Ranking Loss 방법에는 pointwise, pairwise, listwise 등이 있는데 여기서는 Pairwise가 성능이 더 좋게 나왔다고 합니다. Pairwise는 (A, B), (A, C), (A, D) 등이 있을 때 이들의 값의 차이가 커지도록 하는 것입니다. 그리고 이 Pairwise 방법인 Bayesian Personalized Ranking(Rendle et al., 2009)와 Top1 방법을 사용했다고 합니다.
이 이후의 내용은 Experiments 내용으로써 RecSys Challenge와 OTT 데이터 셋을 사용해 평가했고 좋은 결과를 얻었다는 내용입니다. 자세한 것은 논문을 확인해주세요.
아이디어 따오기
저는 개인적으로 Movielens 데이터를 이용해 이 아이디어를 어떻게 하면 살릴 수 있을까?를 고민했습니다. 그 결과 아래와 같이 시도해보자 라고 결론을 내려보았습니다.
- 유저 별로 timestamp에 따라 sort한 뒤 시간 순서대로 영화를 본 정보를 추출
- df.groupby('user').movieId.apply(list) 와 같은 느낌
- 아래 사진과 같은 느낌으로 Batch, X, y를 넣어보자

- 예측 모델은 아래 사진과 같이 만들어보자
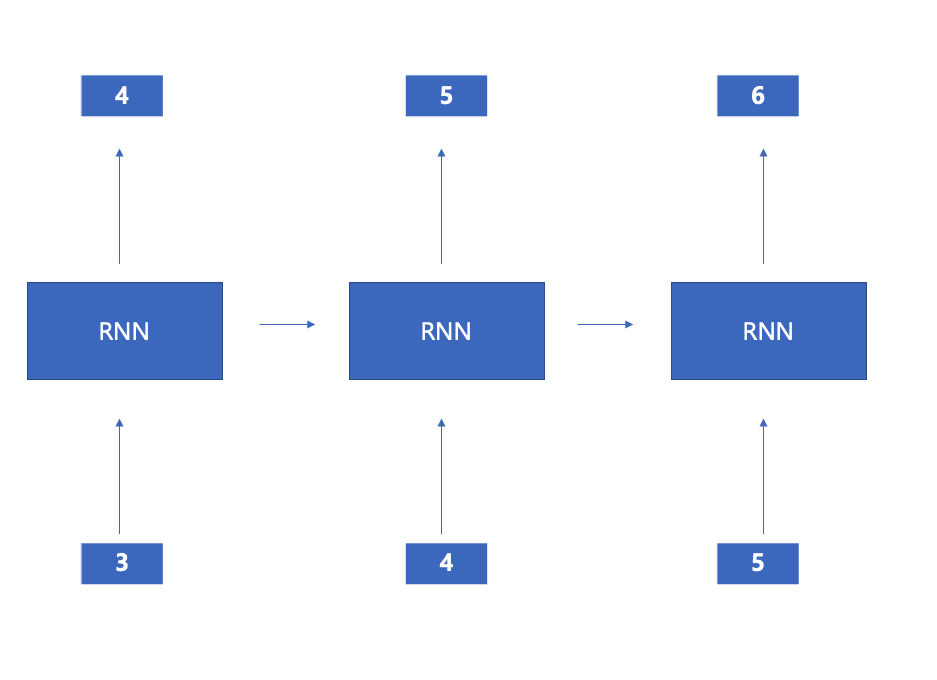
따라서 위와 같은 형태로 모델과 데이터 셋을 구성할 수 있도록 코드를 구성했습니다.
먼저 Moivelens는 아래와 같이 데이터 셋이 구성되어 있습니다. 이를 user 별로 groupby를 하면 user history를 만들 수 있습니다.
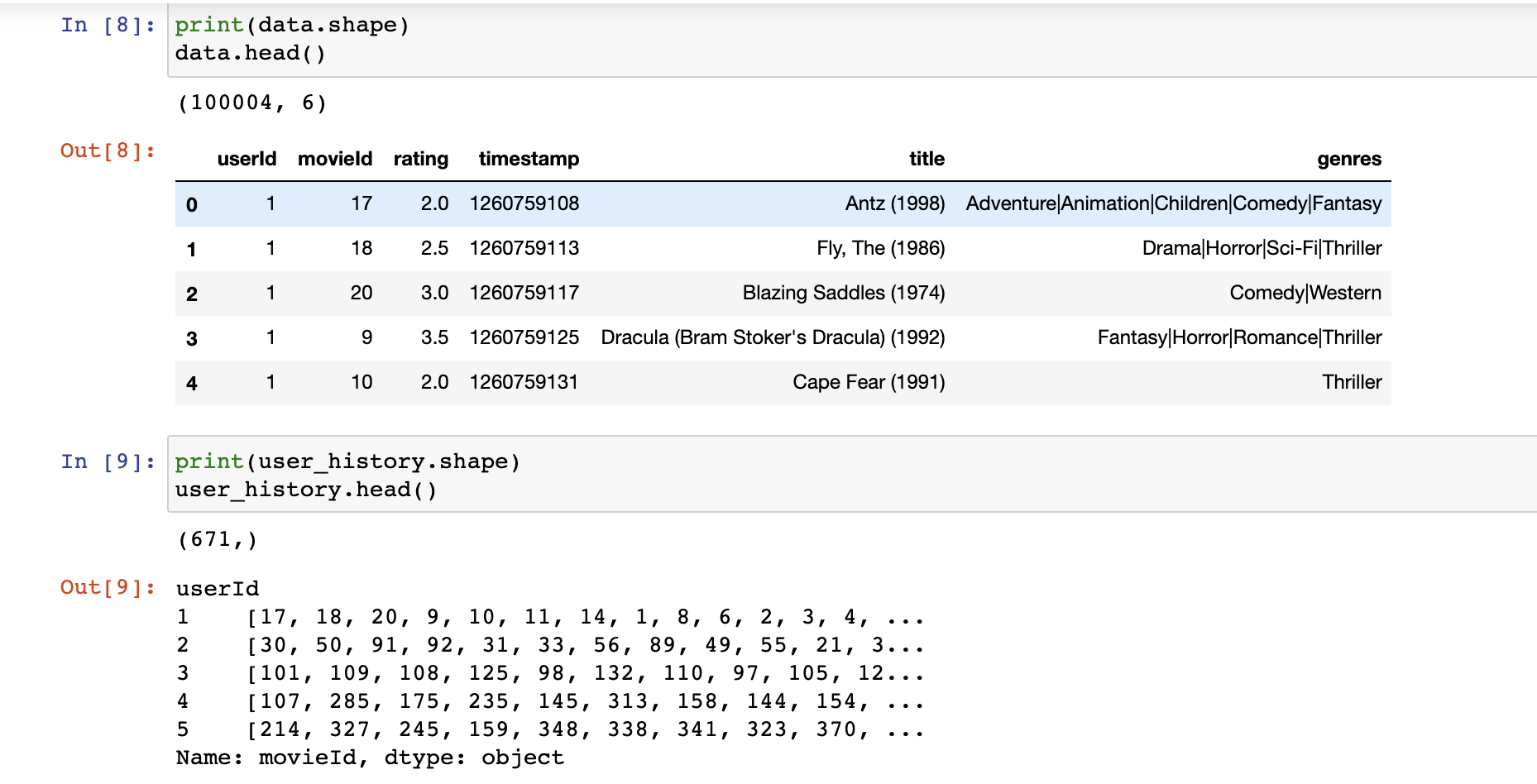
여기서 이제 데이터를 batch 5개를 기준으로 순차적으로 가져옵니다. 이때 가져오는 것은 Python generator를 이용했습니다.

모델 구성입니다. 논문에서 모델은 GRU로 했지만, 저는 LSTM으로 해보았습니다. LSTM으로 한 이유는 딱히 큰 것은 없고 GRU로 시도했을 때 계속 실패했어서 최종적으로 LSTM으로 선택해서 진행했습니다.

여기서 저는 time_distributed layer를 사용했습니다. 그리고 time_distribute layer 안에 Dense layer를 두어서 input에 따른 y를 예측하도록 수행했습니다.
결론
해당 모델을 기반으로 학습을 돌린 결과 아래 사진과 같은 결과가 나왔습니다.
- 첫 번쨰 column : 사용자가 본 데이터 X data
- 두 번째 column : 위에서 사용자가 본 X data 이후에 본 실제 라벨 data y
- 세 번째 column : 모델이 에측한 y^
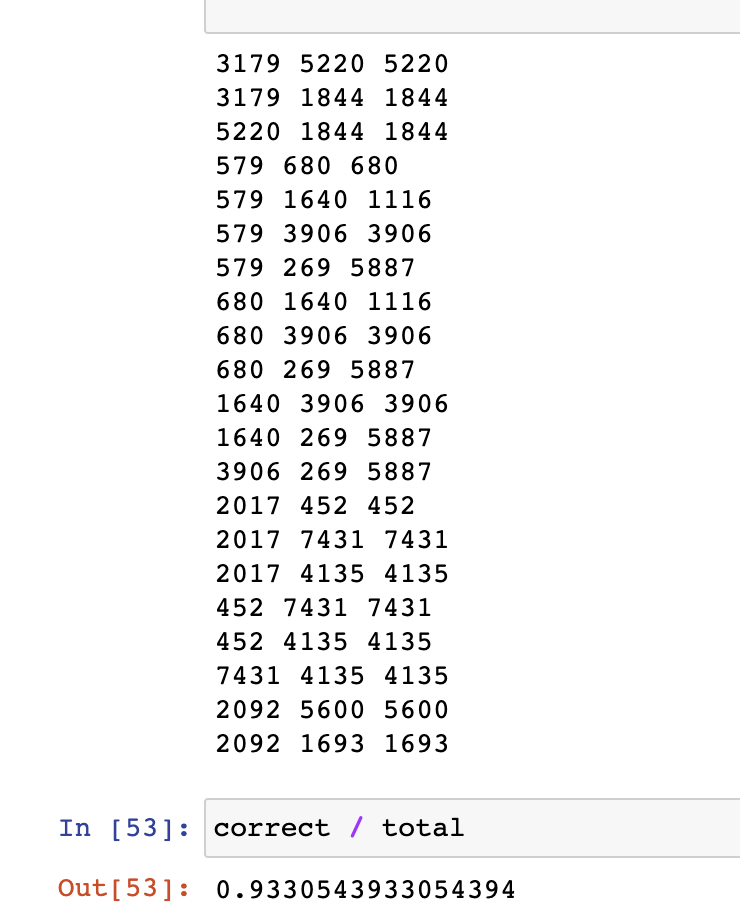
하지만 이 모델을 사용하지는 못했습니다. 사용하지 못한 이유는 아래와 같습니다.
- 가장 큰 문제점인 Item에 one-hot vector로 들어가는데 movie 개수가 늘어나면 늘어날 수록 굉장히 벡터가 커진다는 단점
- 위 문제로 인해 나오는 여러가지 문제점 (학습 속도 등)
- 전체 데이터를 학습해야지 사용자의 패턴을 파악할 수 있다
- 사용자 데이터 평가할 때 전체 데이터를 학습시켰기 때문에 overfitting의 결과로 추측
그 외 여러가지 이유가 있었는데 다 기억이 나질 않네요 ㅠㅠ
한 1주일 동안 밤 잠을 못자며 진행했는데 결국 실패했습니다. 하지만 정말 값진 경험을 할 수 있었던 경험이었습니다.
'추천시스템' 카테고리의 다른 글
| 추천 시스템 논문 - self attentive sequential recommendation 정리 및 요약 (0) | 2020.10.05 |
|---|---|
| Python 추천 시스템(Recommeder System) 구현하기 - Wide & Deep learning for Recommender System (6) | 2020.08.30 |
| Keras를 활용한 딥러닝 추천 시스템(deep learning recommender system) 구현하기 (30) | 2020.03.08 |
| 파이썬(Python)으로 간단한 뉴스 추천 시스템(recommender system) 구현해보기 (22) | 2020.02.04 |
| 파이썬 Matrix Factorization 영화 추천 시스템(movie recommender system) 구현해보기 - 2 (55) | 2020.01.31 |



