
포스팅 개요
해당 글에 대한 코드는 아래 github 링크에 전부 올려두었습니다.
lsjsj92/recommender_system_with_Python
recommender system tutorial with Python. Contribute to lsjsj92/recommender_system_with_Python development by creating an account on GitHub.
github.com
이번 포스팅은 파이썬(Python)으로 영화 추천 시스템(recommender system) 기본을 구현해보는 두 번째 포스팅입니다.
이번 포스팅에서 구현하는 추천 시스템은 아래와 같은 개념을 기반으로 구현합니다.
- 잠재 요인 협업 필터링(latent factor collaborative filtering)을 구현하며, 이때 Matrix Factorization(행렬 분해)를 사용해서 구현
- 사용자 개인에게 맞춤으로 영화를 추천해주는 개인화 추천 방식
지난 포스팅에서도 파이썬으로 Matrix Factorization을 사용해 추천 시스템을 구현해보았습니다.
(https://lsjsj92.tistory.com/569)
파이썬으로 추천 시스템 구현하기(Python recommender system) - Matrix Factorization(행렬 분해)를 사용
포스팅 개요 이번 포스팅은 파이썬(Python)으로 추천 시스템(Recommendation system)을 구현해보는 포스팅입니다. 지난 포스팅에는 추천 시스템 협업 필터링(Collaborative Filtering)을 구현해봤습니다. 그 중 아..
lsjsj92.tistory.com
하지만, 이 때의 문제점은 개인에게 맞춤형 추천이 아닌, 특정 영화와 비슷한 영화를 추천해주는 것이었습니다.
즉, 만약에 '가디언즈 오브 갤럭시' 영화를 input으로 넣으면 가오갤과 비슷한 영화 목록을 뿌려주는 것이었죠.
그래서 이번 포스팅에서의 영화 추천 시스템은 사용자 개인 영화 히스토리(movie history)를 기반으로 영화를 추천해주는 추천 시스템을 간단하게 구현해봅니다.
해당 자료는 아래에서 참고했습니다.
- https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-system
- https://www.kaggle.com/rounakbanik/movie-recommender-systems
- https://github.com/SurhanZahid/Recommendation-System-Using-Matrix-Factorization/blob/master/Recommender%20System%20With%20Matrix%20Factorization%20.ipynb
- https://github.com/nikitaa30/Recommender-Systems/blob/master/matrix_factorisation_svd.py
- https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/04/06/pcasvdlsa/
데이터는 캐글의 MovieLens 데이터를 사용했습니다. (https://www.kaggle.com/sengzhaotoo/movielens-small)
포스팅 본문
이번 파이썬 추천 시스템(Python recommender system) 구현 기본편은 아래의 이론적 내용을 기반으로 합니다.
추천 시스템에서 협업 필터링(collaborative filtering) 내용
- 아이템 기반 협업 필터링(Item based Collaborative Filtering)
- 잠재 요인(latent factor) 기반 - 행렬 분해(Matrix Factorization)를 사용
혹시 내용을 모르신다면 위 내용을 먼저 읽고 오시는 것을 권장합니다.
이번 포스팅은 위 내용 중 Python Matrix Factorization 추천 시스템을 간단하게 구현해봅니다.
파이썬 코드
먼저, 필요한 데이터를 import 합니다. csv 기반이기 때문에 Python의 pandas.read_csv를 사용하면 편리합니다.
이 데이터는 2개의 데이터가 있습니다.
- 사용자-영화 평점 데이터
- 영화 정보 데이터

먼저, 사용자-영화 평점 데이터를 pivot table 형식으로 바꿔줍니다.
즉, 사용자 별 각 영화 평점 방식으로 바꿔주는 것입니다. 그러면 N명의 사용자가 있고 M개의 영화가 있으면 N x M 크기의 행렬이 만들어질 것입니다.
위 사진과 같이 말이죠!
그 다음으로 각 N명의 사용자들이 매긴 각각의 평균 평점은 어떻게 되는지 구하겠습니다.
그리고 그 값을 사용자-영화 평점(user-movie rating) 값에서 빼도록 하겠습니다.
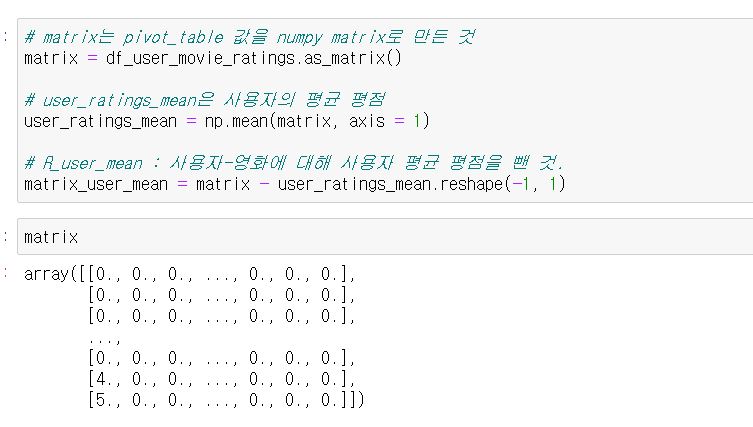
그러면 원래 0~5까지 존재하던 평점 데이터 분포가 각 사용자의 평점 평균을 빼니까 0.00025 이런식으로 변경되어 집니다.

이런 식으로 말입니다!
아까와 똑같이 영화-사용자 평점 데이터입니다. N 명의 user가 M개의 movie에 rating한 것이죠.
단지, N명의 사용자가 매긴 각각의 평균을 사용자 별로 빼주었기 때문에 값이 조금 변경되었을 뿐입니다.
자! 이제 SVD(Singular Value Decompostion), 특이값 분해를 사용해서 latent factor maxtirx factorization을 진행하겠습니다. SVD의 개념은 아래와 같습니다.
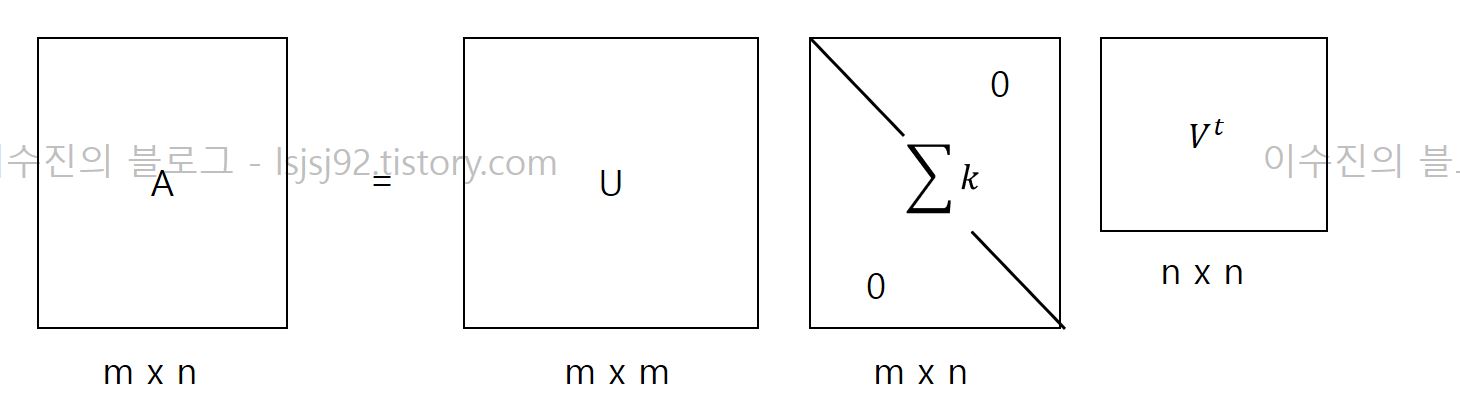
우리나라 말로 특이값 분해라고 불리우는 SVD는 m x n 크기의 데이터 행렬 A를 아래와 같이 분리하는 것을 말합니다.
행렬 U와 V에 속한 벡터를 특이벡터(singular vector)라 불리웁니다.
∑로 생긴 것도 행렬인데요. 이 행렬은 대각 행렬(Diagonal Matrix) 성질을 가지고 있습니다. 그래서 대각 성분이 행렬 A의 특이값이고 나머지는 0의 값을 가지고 있습니다.
여기서 Truncated SVD도 등장하는데요. Truncated SVD는 SVD의 변형입니다.

즉, ∑ 행렬의 대각원속(특이값) 가운데 상위 p개를 골라낸 것입니다. 이렇게 하면 기존 행렬 A의 성질을 100% 원복할 수 없지만 기존 행렬 A와 거의 근사한 값이 나옵니다.
좀 더 자세히 알고 싶으신 분들은 참조 맨 마지막 링크인 ratsgo님 블로그를 참고해주세요
저는 여기서 Python scipy에서 제공해주는 svd를 사용하겠습니다.
Python scikit learn에서도 SVD를 제공해주긴 합니다. 하지만 사이킷런에서는 U, Sigma, Vt를 return하지 않습니다.

그래서 scipy에 있는 svd를 이용해 U, Sigma, Vt를 받을 수 있도록 합니다. 또한, scipy에서 제공해주는 scipy.sparse.linalg.svds는 TruncatedSVD 개념을 사용하므로 이것을 사용하겠습니다.
위 사진과 같이 진행을 하면 현재 Sigma 행렬은 0이 아닌 값만 1차원 행렬로 표현된 상태입니다.
즉, 0이 포함된 대칭행렬로 변환할 때는 numpy의 diag를 이용해야합니다.
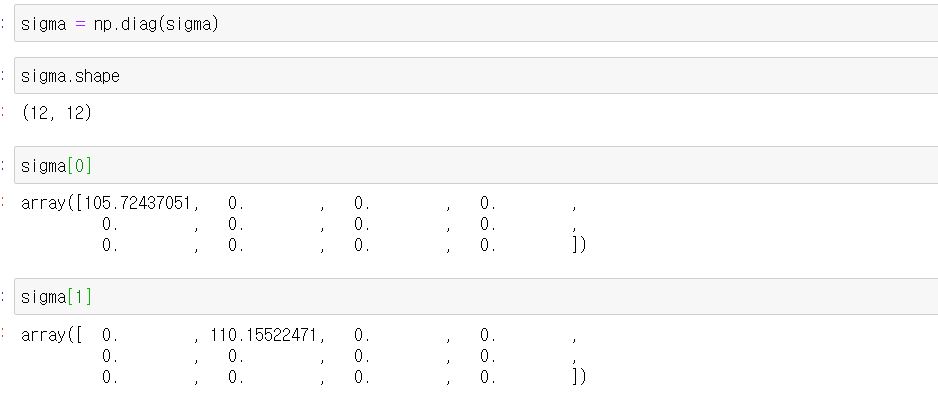
위 파이썬 코드와 같이 말이죠!
자, 여기서 현재까지 상황을 한 번 정리하고 넘어가겠습니다.
현재 까지 상황을 정리하면 아래와 같습니다.
- 원본 user-movie 평점 행렬이 있었음
- 이를 user의 평균 점수를 빼서 matrix_user_mean 이라는 행렬로 만듬
- 2번의 값을 SVD를 적용해 U, Sigma, Vt 행렬을 구했음
- Sigma 행렬은 현재 0이 포함이 되지 않은 값으로만 구성되어 있음. 이를 대칭행렬로 변환
matrix_user_mean을 SVD를 적용해 분해를 한 상태입니다.
이제, 다시 원본 행렬로 복구시켜야겠죠?
원본 행렬로 복구시키는 방법은 아래와 같습니다.
- U, Sigma, Vt의 내적을 수행
즉, np.dot(np.dot(U, sigma), Vt)를 수행하면 됩니다.
그리고 아까 사용자 평균을 빼주었으니 여기서는 더해줍니다.

그럼 위와 같이 SVD 특이값 분해를 사용해 Matrix Factorization(행렬 분해)를 기반으로 데이터를 변경해줍니다.
자! 이제 데이터 준비는 되었습니다.
Python 함수를 하나 만들죠. 이 함수의 기능은 아래와 같습니다.
- 인자로 사용자 아이디, 영화 정보 테이블, 평점 테이블 등을 받음
- 사용자 아이디에 SVD로 나온 결과의 영화 평점이 가장 높은 데이터 순으로 정렬
- 사용자가 본 데이터를 제외
- 사용자가 안 본 영화에서 평점이 높은 것을 추천
사용자 히스토리 기반으로 가장 연관성이 높은 영화를 추천해주어야 합니다.
그래서 이미 사용자의 평균 평점 데이터를 넣어놨었죠? 또한, 여기에서는 사용자가 본 영화는 제외하고 영화를 추천해줍니다.

이렇게 함수를 만들었습니다.
그럼 이제 결과를 봐봅니다.
330번 user가 Matrix Factorization 기반의 추천 시스템에게 받은 영화 추천 목록입니다.


이렇게 추천을 받을 수 있습니다.
이번 포스팅에서는 파이썬을 활용해 Matrix Factorization 기반 영화 추천 시스템을 만들어보았습니다.
그리고, 지난 포스팅에서 못했던 사용자 개인에게 추천해주는 것도 적용해보았습니다.
코드가 완벽하지는 않을겁니다. 제가 잘하는 사람이 아니라서요.
하지만, 부디 어떤 분들에게는 도움이 되길 바랍니다.
다음 포스팅에서는 좀 독특한 방법으로 추천 시스템을 적용해보겠습니다.
'인공지능(AI) > 추천시스템' 카테고리의 다른 글
| Keras를 활용한 딥러닝 추천 시스템(deep learning recommender system) 구현하기 (32) | 2020.03.08 |
|---|---|
| 파이썬(Python)으로 간단한 뉴스 추천 시스템(recommender system) 구현해보기 (24) | 2020.02.04 |
| 파이썬으로 추천 시스템 구현하기(Python recommender system) - Matrix Factorization(행렬 분해)를 사용 (12) | 2020.01.25 |
| 파이썬으로 추천 시스템(recommendation system) 구현해보기 - collaborative filtering (18) | 2020.01.19 |
| 파이썬과 함께 추천 시스템(recommendation system) 이해하기 기본편 - content based filtering (15) | 2020.01.08 |



