
포스팅 개요
해당 글에 대한 코드는 아래 github 링크에 전부 올려두었습니다.
lsjsj92/recommender_system_with_Python
recommender system with Python. Contribute to lsjsj92/recommender_system_with_Python development by creating an account on GitHub.
github.com
이번 포스팅은 파이썬(Python)을 활용해서 추천 시스템(recommendation system) 중 콘텐츠 기반 필터링(content based filtering)을 이해하고 만들어보는 포스팅입니다.
지난 포스팅에서 추천 시스템 중 콘텐츠 기반 필터링(content based filtering)에 대해서 알아보았습니다.
(https://lsjsj92.tistory.com/563)
추천 시스템(Recommendation system)이란? - content based filtering, collaborative filtering
포스팅 개요 이번 포스팅은 추천 시스템(recommedation system)에 대해서 알아봅니다. 또한, 추천 시스템에는 컨텐츠 기반 필터링(content based filtering)과 협력 필터링(collaborative filtering)이 있는데요...
lsjsj92.tistory.com
해당 포스팅에 쓰여져있던 콘텐츠 기반 필터링의 이론적인 내용을 Python 코드로 작성해봅니다.
참고한 자료
- https://www.kaggle.com/rounakbanik/movie-recommender-systems
- https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-system
위 자료 외에 자료는 각종 구글링을 통해 정보를 수집했습니다.
포스팅 본문
추천 시스템(recommendation system)에서 콘텐츠 기반 필터링(content based filtering)이란 무엇이었나요?
사용자가 특정 아이템을 선호하는 경우 그 아이템과 비슷한 콘텐츠를 추천해주는 것이 content based filtering이었습니다.
캐글(kaggle)에서 추천 시스템을 활용할 수 있는 데이터 셋이 있는데요. 이번 포스팅은 그 데이터를 활용합니다!
데이터 셋 : https://www.kaggle.com/rounakbanik/the-movies-dataset
데이터를 보면 영화에 대한 데이터인데요. 즉, 사용자에게 비슷한 영화를 추천 해주는 것입니다.
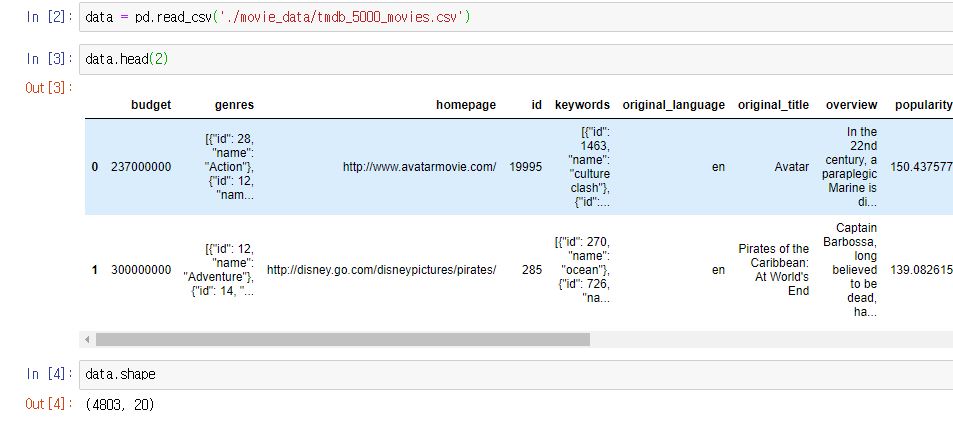
데이터는 4803개의 row와 20개의 column으로 되어있습니다. 데이터 셋에 대한 자세한 설명은 위에서 언급한 참조 링크에 자세히 쓰여져있는데요. 여기서 제가 많이 사용한 컬럼은 아래와 같습니다.
- genres : 영화 장르
- keywords : 영화의 키워드
- original_language : 영화 언어
- title : 제목
- vote_average : 평점 평균
- vote_count : 평점 카운트
- popularity : 인기도
- overview : 개요 설명
등등 같은 컬럼을 사용할 예정입니다. 다른 컬럼은 일단 여기서 그렇게 중요하지 않게 사용합니다.
사실, release_data와 같은 컬럼도 중요할 수 있습니다. 최신 영화를 추천할 수도 있으니까요. 하지만 여기서는 사용하지 않겠습니다.
자! 이제 가장 먼저 전처리를 조금 해주어야 합니다.
데이터 전처리(data preprocessing)
먼저, 사용할 데이터부터 뽑아봅니다.

그리고 현재 영화 평점(vote)와 관련해서 vote_average가 있는데요. 이는 평균평점을 뜻합니다. 근데 이게 조금 불공정하게 되어있습니다.
왜 불공정하느냐? 만약, 평점을 남긴 count가 적은데(vote_count) 예를 들어서 3개라고 하죠. 3개 전부 다 평점 5점이 매겨져 있다고 할게요.
근데 일반적으로 vote 수가 많을 수록 평점이 5점이 나올 수 없고 떨어질 수 밖에 없습니다. 왜냐하면 많은 사람들이 평가를 했으니까요.
그래서 이런 불공정을 처리하기 위해 imdb에서 처리한 방법 weighted rating이 있습니다.
해당 이슈는 url : https://www.quora.com/How-does-IMDbs-rating-system-work 에서 확인할 수 있습니다.
그에 대한 답은 아래와 같습니다.
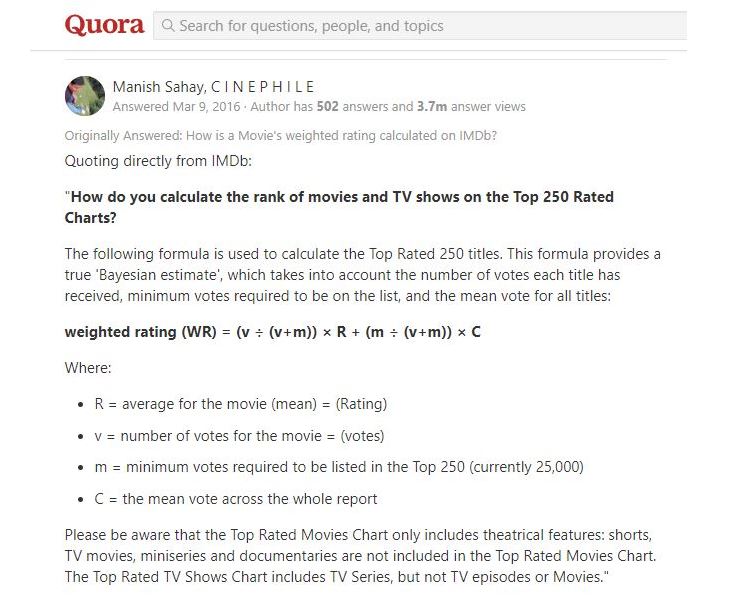
- r : 개별 영화 평점
- v : 개별 영화에 평점을 투표한 횟수
- m : 250위 안에 들어야 하는 최소 투표 (정하기 나름인듯. 난 500이라고 하면 500으로 해도 되고.)
- c : 전체 영화에 대한 평균 평점
여기서 m은 500위로 가정하고 진행하겠습니다.
먼저 m부터 찾아보죠. 500위 정도로 들어오게 하려면 vote_count가 상위 몇 %이어야 할까요?
이는 quantile을 이용해서 구할 수 있습니다.

숫자를 바꿔가면서 테스트를 해보았는데요. data['vote_count']의 quantile이 0.9 정도로 하게 되면 481개가 들어옵니다. 89%로 하면 529개가 들어오더라구요. 저는 90%로 가정하고 진행합니다.
그리고 그 외에 C값과 최종 score를 계산할 함수를 만들어줍니다.
저 공식대로요!

def weighted_rating이라는 함수를 만들고 m값, C값을 활용해 계산을 한 뒤 그 결과를 return합니다.
그리고 그 결과를 data['score']라는 컬럼에 넣습니다.

그러면 총 데이터는 481개, column은 9개가 됩니다.
자! 이제 score라는 컬럼을 imdb에서 제공한 weighted rating을 이용해 적용했습니다.
서두에서 말씀드렸지만 추천 시스템 중 콘텐츠 기반 필터링(content based filtering)은 비슷한 아이템(컨텐츠)끼리 추천해줍니다.
여기서 그 '비슷한'의 개념을 장르, 키워드로 분석할 수 있습니다. 비슷한 장르, 비슷한 키워드가 있는 영화를 추천하는 것이죠! 그래서 genres와 keywords columns을 이용합니다.

근데, 좀 특이합니다. 안에 데이터를 보아하니, Python list안에 dictionary가 포함된 구조입니다.
또한, 저게 현재 문자열(string) 형태로 되어있어서 변환이 필요한데요. 이는 파이썬(Python) 패키지 ast안에 있는 literal_eval을 사용하면됩니다.
그러면 list와 dictionary 형태로 바뀌게 됩니다.

이렇게요! 결과는 똑같아 보이지만 사실 다릅니다. 마치 list처럼, dictionary처럼 똑같이 데이터를 핸들링 할 수 있기 때문이죠.
자! 이제 저 dictionary식으로 되어 있는 데이터에서 우리는 name만 뽑아내야합니다. 저희에게 저 id 값은 필요가 없기 때문입니다.

data['genres'].apply(lambda x : [d['name'] for d in x]).apply(lambda x : " ".join(x))을 통해
dict 형태 -> list 형태 -> 띄어쓰기로 이루어진 str로 변경해줍니다.
여기까지 하면 전처리는 끝이납니다!
콘텐츠 기반 필터링 추천(content based filtering)하기
이제 전처리가 끝나고 본격적으로 content based filtering을 진행합니다.
여기서는 비슷한 영화를 추천해주는 것이기 때문에 영화 장르를 활용해봅니다.
현재 장르는 위 전처리 과정을 겪고나서 띄어쓰기를 구분자로 한 문자열로 되어있습니다.
이 문자열을 숫자로 바꾸어 벡터화 시킵니다! Python scikit learn에 있는 CountVectorizer를 이용하면 좋습니다.

CountVectorizer(ngram_range=(1, 3))과 같이 객체를 만들어주고 count_vector.fit_transform(data['genres'])를 통해 변환시켜줍니다.
자! 이제 이렇게 변환된 벡터를 이용해서 유사한 영화를 추천해주면 되는데요.
'유사한(similarity)'는 어떻게 측정할까요?
보통 많이 사용하는 것이 코사인 유사도(cosine similarity)입니다. Python scikit learn에서 이 cosine similarity를 지원해주는데요. 이것을 이용합니다.
또한, 코사인 유사도를 구함과 동시에 argsort로 유사도가 가장 높은 인덱스를 가장 위쪽으로 정렬하겠습니다.
그리고 영화 제목을 넣어주면 그 영화 제목과 비슷한 영화를 추천해주는 함수를 하나 만들어줍니다.
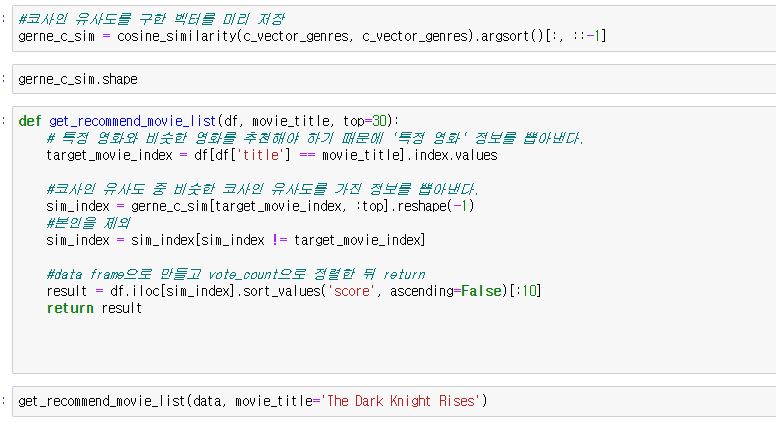
함수에 대한 설명은 위에 주석으로 작성했습니다.
기본 로직은
1. 영화 제목이 들어오면 영화 제목을 가지고 있는 index를 뽑아낸다.
2. 코사인 유사도 중 영화 제목 인덱스에 해당하는 값에서 추천 개수만큼 뽑아낸다.
3. 본인은 제외
4. imdb weighted rating을 적용한 score 기반으로 정렬
5. 이를 Python DataFrame으로 만들고 return
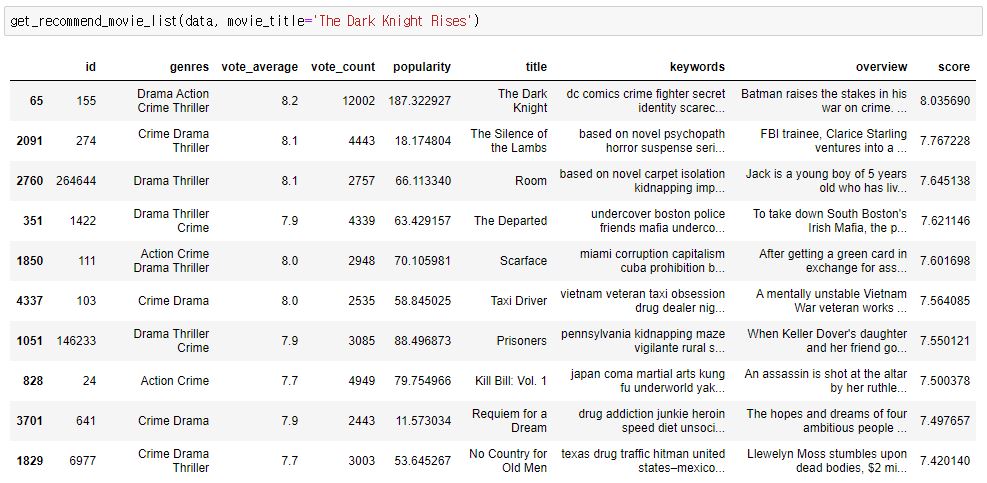
그러면 위와 같이 다크 나이트 라이즈(dark knight rises)를 입력하게 되면 다크나이트 라이즈와 비슷한 영화를 추천해줍니다. 다크나이트 라이즈 영화는 드라마, 액션, 범죄, 스릴러 장르를 가지고 있네요.
그래서 추천 해주는 영화들의 목록을 보면 액션, 범죄, 드라마, 스릴러들 중에서 추천을 해주었습니다.
여기까지 파이썬(Python)으로 구현해보는 추천 시스템(recommendation system) 컨텐츠 기반 필터링(content based filtering)이었습니다.
다음에는 협업 필터링을 파이썬으로 구현해보겠습니다.
'인공지능(AI) > 추천시스템' 카테고리의 다른 글
| Keras를 활용한 딥러닝 추천 시스템(deep learning recommender system) 구현하기 (32) | 2020.03.08 |
|---|---|
| 파이썬(Python)으로 간단한 뉴스 추천 시스템(recommender system) 구현해보기 (24) | 2020.02.04 |
| 파이썬 Matrix Factorization 영화 추천 시스템(movie recommender system) 구현해보기 - 2 (55) | 2020.01.31 |
| 파이썬으로 추천 시스템 구현하기(Python recommender system) - Matrix Factorization(행렬 분해)를 사용 (12) | 2020.01.25 |
| 파이썬으로 추천 시스템(recommendation system) 구현해보기 - collaborative filtering (18) | 2020.01.19 |



