
포스팅 개요
이번 포스팅은 시계열 데이터 분석(Time series data)에서 활용되는 공적분 분석(cointegration analysis)에 대해서 정리하는 포스팅입니다. 간단한 이론적 설명과 더불어 파이썬(Python)에서 이를 어떻게 활용할 수 있는지 예시로 알아봅니다.
본 포스팅 작성 시 참고 했던 자료들은 아래와 같습니다.
- https://datascienceschool.net/view-notebook/d5478c5ed2044cb9b88fa2ef015eb3a4/
- https://www.statsmodels.org/stable/generated/statsmodels.tsa.stattools.coint.html
- https://namu.wiki/w/%EA%B3%B5%EC%A0%81%EB%B6%84
또한, 본문에서 사용한 코드는 아래 github에 올려두었습니다.
포스팅 본문
공적분(cointegration)이란?
먼저 공적분에 대해서 간략하게 알아봅니다. 공적분이란 무엇일까요? 영어로는 cointegration으로 불리웁니다. co라는 단어에서 볼 수 있듯이 뭔가 '공통적'인 것이 있겠죠? 공적분을 요약하면 아래와 같습니다
- 두 시계열 사이에 공적분 관계가 있다는 것은, 단기적으로 다를 수도 있지만 장기적으로 보았을 때는 서로 일정한 관계가 있다는 것을 의미한다.
- 쉬운 예시로는 술취한 사람이 반려견을 끈에 묶어서 돌아다니는 것과 같이 사람과 반려견은 아무런 관계없이 서로 움직이지만, 서로 멀어지지 않고 결국엔 집으로 가는 것과 비슷하다.
즉, 두 시계열 (Time series) 데이터에서 어떤 관계가 있다는 것을 통계적 지표로 보여주는 것이 공적분이라고 이해할 수 있습니다.
파이썬에서 활용해보는 공적분 - Cointegration with Python
그럼 어떤 시계열 데이터를 이용해서 파이썬으로 한 번 예시를 들어보겠습니다.
Python에서는 statsmodels 라이브러리를 통해 cointegration을 지원해주고 있습니다. 단, 여기서의 coint는 Engle-Granger 이론을 기반으로 되어 있습니다. Engle-Granger이론의 특성은 아래와 같습니다.
- 두 시계열 xt, yt가 공적분 이라고 가정했을 때 yt를 종속변수, xt를 독립변수로 회귀 분석을 하여 만들어지는 잔차 zt에 대해서 다음과 같은 식이 성립한다. 이러한 식을 ECM 식이라고 한다.
- 여기서 et는 회귀 분석으로 만들어진 ECM 형식의 잔차이다.

- 여기서 zt(yt와 xt를 회귀 분석한 결과)와 et(회귀 분석으로 ECM 형식의 잔차)가 정상 시계열이면 두 시계열이 공적분인지 알 수 있다.
- 해당 공적분에서 귀무가설과 대립가설은 아래와 같다.
- 귀무가설 : 공적분 관계가 존재하지 않는다.
- 대립가설 : 공적분 관계가 존재한다.
- 즉, p-value를 5%라고 지정했을 때 p-value 값이 0.05 이하이면, 귀무가설을 기각할 수 있기 때문에 대립가설이 채택이 되고 그 말은 공적분 관계가 존재한다라고 말할 수 있다.
위 내용을 가지고 아래와 같은 데이터를 활용해서 파이썬 코드 상에서 공적분을 분석해 보겠습니다.
- 가설 : 코로나가 터진 이후 최근 3개월, 애플과 페이스북의 주가 추이는 비슷할 것이다.
- 귀무가설 : 애플과 페이스북의 주가 추이 시계열 데이터는 서로 공적분 관계가 아니다.
- 대립가설 : 애플과 페이스북의 주가 추이 시계열 데이터는 서로 공적분 관계이다. (장기적으로 보았을 때 서로 어떤 관계성이 있다)
최근 3개월 facebook과 apple의 주가 추이를 서로 비교해서 공적분 관계를 비교해보겠습니다. 해당 데이터는 야후 파이낸스에서 받았습니다.
먼저, 데이터를 Python 코드 상에서 load한 뒤 장 마감 때의 가격 close를 기준으로 필요 데이터를 뽑아내겠습니다.
원래는 Open, High, Low 등의 데이터가 있지만 저는 Close를 기준으로 하겠습니다. (저는 주식을 잘 몰라서.. 그냥 Close로 했습니다 ㅎㅎ)
이 둘의 그래프를 그리면 아래와 같이 나오는 것을 볼 수 있습니다.
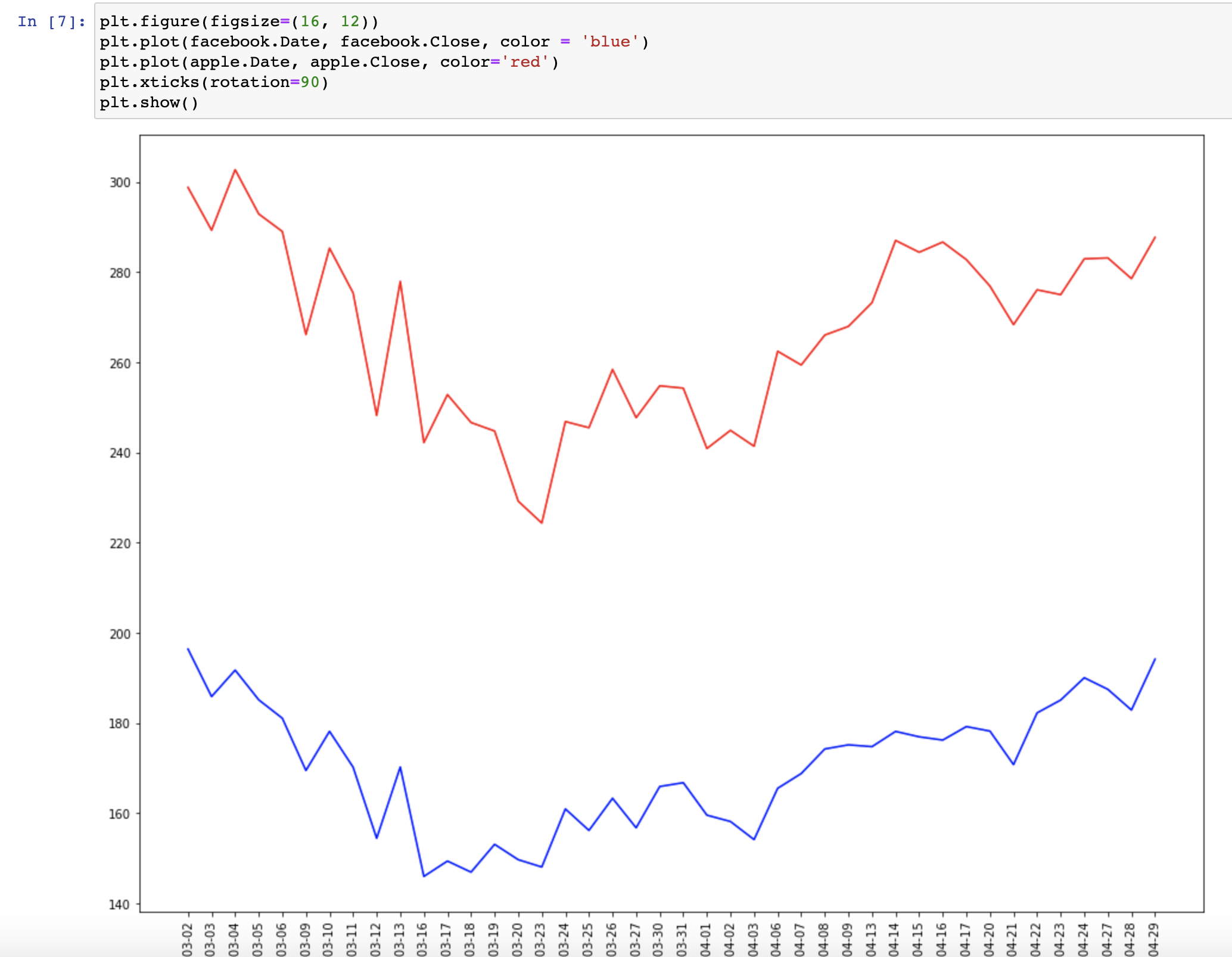
파란색이 페이스북이고 빨간색이 애플입니다. 눈으로 보았을 때 뭔가 비슷해보이지만 정말로 비슷한지, 서로 관계가 있는지 통계적으로 분석해보겠습니다.
먼저, 최근 3개월 주가에서의 페이스북, 애플 데이터에서 상관관계(correlation)을 확인해보겠습니다.
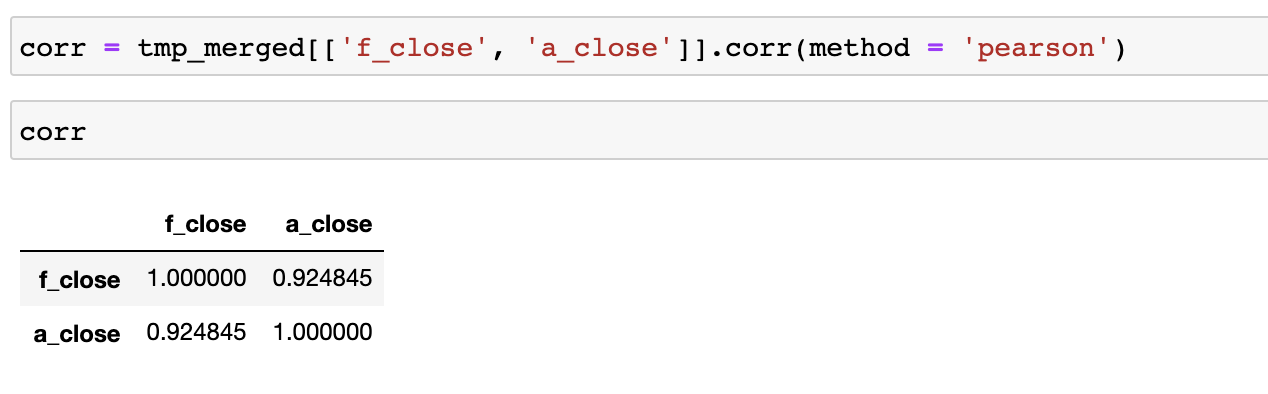
데이터의 상관관계는 매우 높게 나왔습니다. 하지만, 이것은 두 변수간의 상관관계이므로 시계열 적으로 연관성이 있는지 좀 더 정확한 관계 분석을 위해서 공적분 분석을 진행해보겠습니다.
파이썬에서 공적분 분석은 statsmodels 라이브러리를 이용해서 coint를 불러와서 사용할 수 있습니다.
이때 반환 값 중 p_value가 존재하는데요. 여기서의 귀무가설은 위에서도 언급했지만 서로 공적분 관계가 없다는 것이 귀무가설입니다. 따라서 p-value 값이 5%보다 작을 때는 이 귀무가설을 기각하여 서로 공적분 관계가 있다는 것을 알 수 있을겁니다.
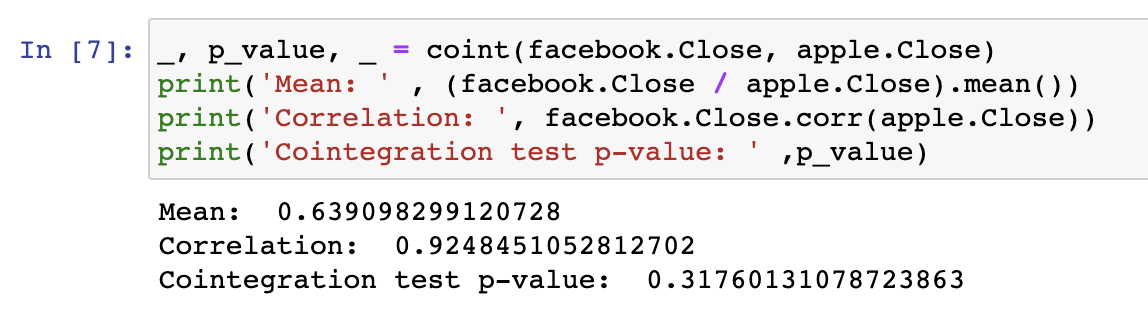
실제로 최근 3개월 페이스북과 애플의 주가추이 데이터는 p-value 값이 0.3으로 30%가 나온 것을 확인할 수 있습니다.
즉, 장기적으로 보았을 때 이 두 데이터는 서로 관련성이 없다는 것을 알 수 있습니다.
마무리
이번 포스팅은 시계열 데이터의 연관성 분석에서 활용되는 공적분(cointegration)에 대해서 알아보았습니다. 서로 다른 시계열을 분석할 때 서로 어느 정도 연관성이 있는지 활용할 수 있습니다. 도움이 되시길 바랍니다.



