
포스팅 개요
이번 포스팅은 추천 시스템(recommendation system) 기본 2탄입니다.
지난 포스팅에서 추천 시스템이 왜 중요한지, 어떤 종류가 있는지 간략하게 살펴보았습니다.
(https://lsjsj92.tistory.com/563)
추천 시스템(Recommendation system)이란? - content based filtering, collaborative filtering
포스팅 개요 이번 포스팅은 추천 시스템(recommedation system)에 대해서 알아봅니다. 또한, 추천 시스템에는 컨텐츠 기반 필터링(content based filtering)과 협력 필터링(collaborative filtering)이 있는데요...
lsjsj92.tistory.com
추천 시스템의 기본적인 방법은 컨텐츠 기반 필터링(content based filtering)과 협업 필터링(collaborative filtering)이 있다고 소개했습니다. 그리고 그 중 협업 필터링(collaborative filtering)은 아이템 기반, 사용자 기반과 잠재 요소(latent factor) 요소가 있다고 소개했습니다.
지난 포스팅에서는 협업 필터링의 item based collaborative filtering까지 소개했습니다.
이번 포스팅에서는 latent factor based collaborative filtering에 대해서 알아봅니다.
참고한 자료
- https://www.kaggle.com/rounakbanik/movie-recommender-systems
- https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-system
- https://wikidocs.net/5053
- https://medium.com/towards-artificial-intelligence/content-based-recommender-system-4db1b3de03e7
- https://www.youtube.com/watch?v=ZspR5PZemcs&list=PLU1prrdmLIpaGw0neztIByvshB9I7l6-f&index=11
위 자료 외에 자료는 각종 구글링에서 나온 자료를 참고하였습니다.
포스팅 본문
추천 시스템(recommendation system) 방법 중 협업 필터링(collaborative filtering)은 자주 사용되는 알고리즘 중 하나입니다.
그리고 그 중 잠재 요인 기반의 협업 필터링(latent based collaborative filtering)은 아직도 많이 사용되는 방법입니다.
잠재요인 협업 필터링은 행렬 분해(matrix factorization)을 기반하여 사용합니다. 이는 대규모 다차원 행렬을 SVD와 같은 차원 감소 기법으로 분해하는 과정에서 잠재 요인(latent factor)를 찾아내어 뽑아내는 방법입니다.
사실 collaborative filtering을 소개하면서 아이템 기반(item based collaborative filtering)을 소개했는데 행렬 분해 방법을 더 많이 사용합니다.
왜냐하면 matrix factorization의 장점으로 공간을 더 잘 활용할 수 있기 때문인데요. 이는 추후 뒤에서 설명합니다.
행렬 분해(혹은 잠재 요인)으로 진행하는 collaborative filtering은 사용자-아이템 행렬 데이터를 이용해 '잠재 요인'을 찾아냅니다.
즉, 사용자-아이템 행렬을 '사용자-잠재요인', '아이템-잠재요인' 행렬로 분해할 수 있습니다. 아래 사진처럼요!
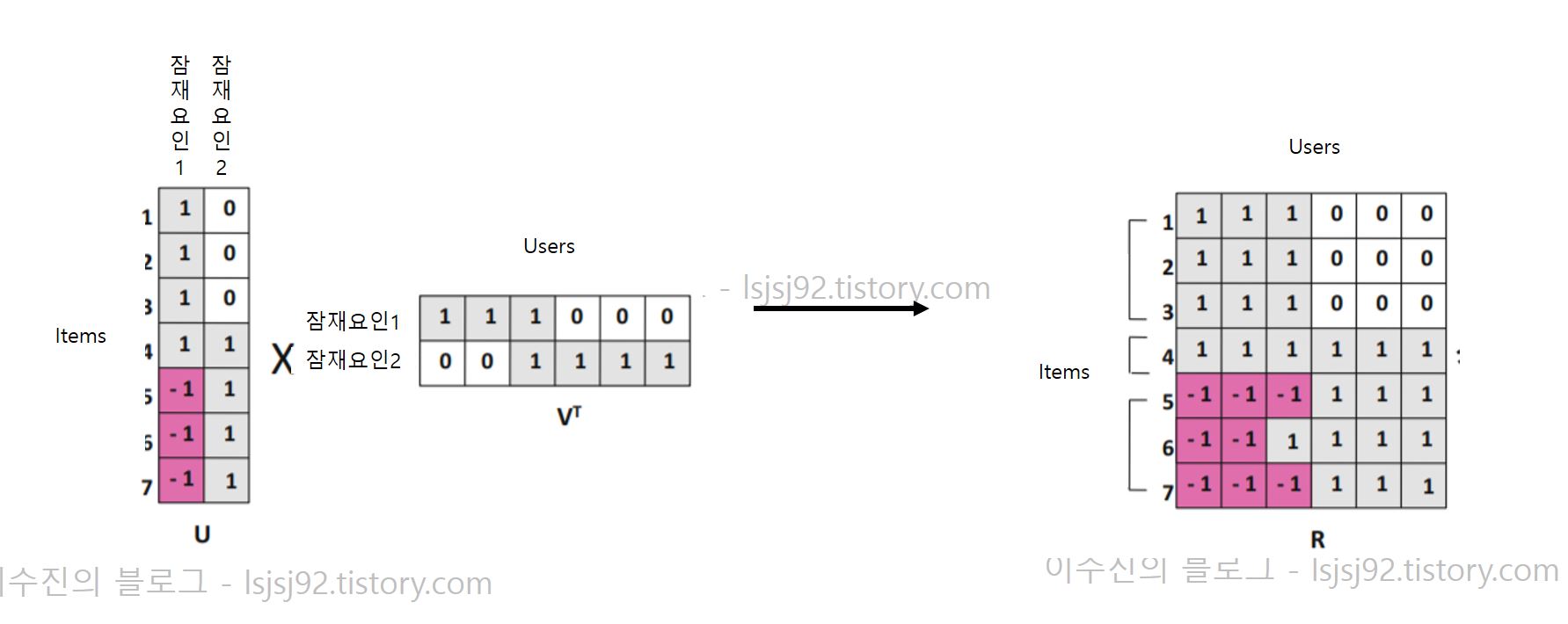
이 잠재 요인(latent factor)가 무엇인지 명확히 알 수는 없습니다.
하지만 예를 들어 코메디, 액션과 같은 장르가 될 수도 있는 것입니다. 만약 이와 같이 정해졌으면
'사용자-장르', '장르-아이템' 과 같이 2개의 행렬로 분해될 수 있는 것입니다.
아래 사진과 같이 말이죠.

보통 사용자-아이템 행렬은 R이라고 표현합니다. 그리고 R(u, i)라고 표현하는데 u번째 유저가 i번째 아이템에 대한 평가를 말합니다.
또한, '사용자-잠재요인' 행렬을 P, '아이템-잠재요인' 행렬을 Q라고 합니다. Q 행렬은 보통 전치 행렬로 사용하기 때문에 Q.T로 표현합니다.
그래서 아래 사진과 같이 R 행렬에서 나온 값을 기반으로 latent factor score를 매길 수 있게 됩니다.

이 값을 이용해서 아래와 같이 사용자가 평가하지 않은 콘텐츠의 점수를 예측할 수 있는 것입니다.
즉, 이 값이 높으면 사용자에게 추천할 수 있는것이죠!

이렇게 하는 방법이 추천 시스템에서 행렬 분해(matrix factorization)을 이용한, 즉. 잠재 요인을 이용한 collaborative filtering입니다.
그래서 길게 쓰면 latent factor based collaborative filtering 이라고 불리우는 것이죠
이렇게 행렬 분해를 사용하면 장점이 무엇일까요?
행렬 분해로 잠재 요인을 끌어냈을 때의 큰 장점은 '저장 공간 절약'입니다.
만약, matrix factorization 방법을 사용하지 않으면 아래와 같이 user - item matrix가 있을 것입니다.
이떄 1000개의 item에 대한 2000명의 user가 있으므로 1000 * 2000개의 파라미터가 필요합니다.
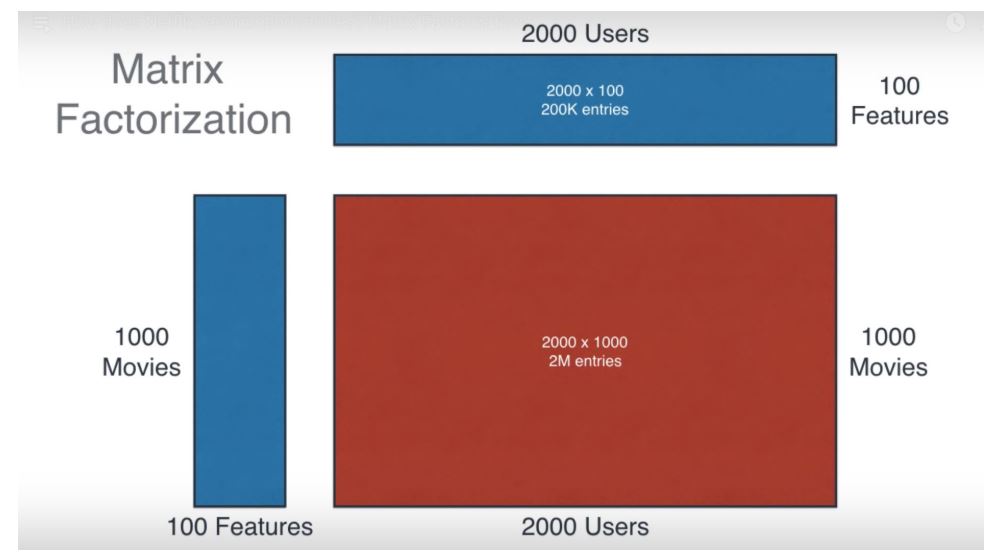
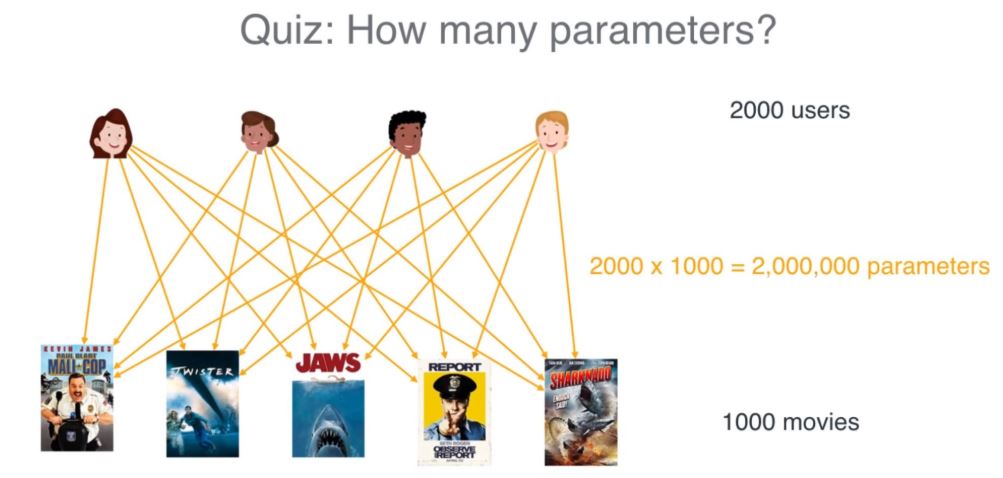
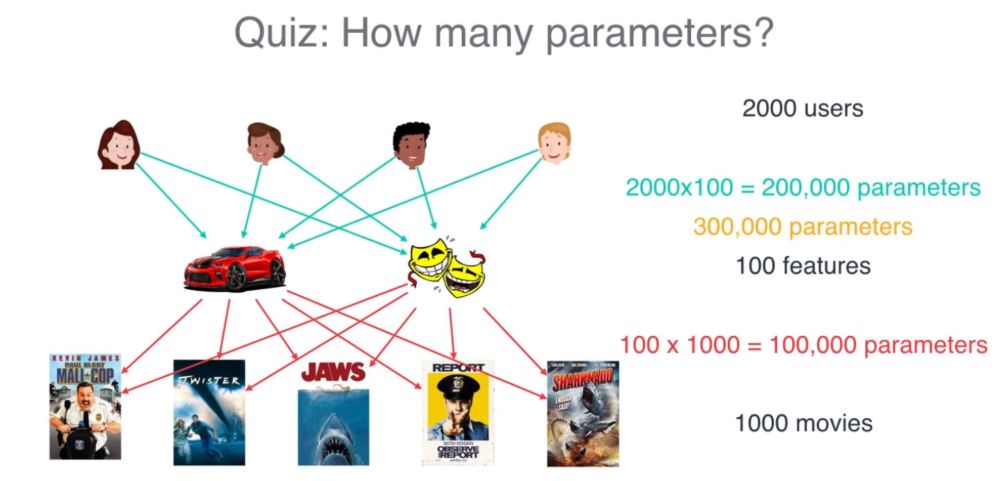
하지만 중간에 matrix factorization으로 잠재 요인(latent factor)를 뽑아내게 된다면 공간을 매우 효율적으로 사용할 수 있습니다.
아래와 같이 총 파라미터가 원래 200만개였는데 30만개로 줄었습니다.
그리고 이러한 행렬분해는 아래와 같은 방법으로 적용될 수 있습니다.

이번 포스팅은 추천 시스템(recommendation system)의 기본 중 하나인 잠재 요인 기반의 협업 필터링(latent factor based collaborative filtering)을 알아보았습니다.
다음 포스팅부터는 앞에서 배웠던 콘텐츠 기반 추천 시스템과 이 협업 필터링을 파이썬 코드로 구현해보겠습니다.



