
이번 포스팅은 머신러닝으로 신용카드 사기를 탐지하는 모델을 만들어보려고 합니다.
해당 포스팅의 데이터는 kaggle에서 제공해준 kaggle credit card fraud를 사용했습니다.
또한, 한 커널을 필사하면서 진행하며 참고했는데요. 커널은 아래와 같습니다.
(https://www.kaggle.com/janiobachmann/credit-fraud-dealing-with-imbalanced-datasets)
머신러닝의 기본적인 내용을 공부하면서 이것을 어떻게 적용할 수 있을까?를 정말 많이 고민하게 됩니다.
단순히 캐글에서 제공해주는 타이타닉으로 해본다? 좀 뭔가 현설직이지는 않습니다.
개인적으로는 이 신용카드 사기 탐지가 머신러닝 기본기를 다지기도 좋고 재밌기도 하더군요!
그래서 머신러닝으로 신용카드 사기를 탐지해보는 모델을 만들어보면서 전반적인 모델링 과정을 진행해보려고 합니다.
머신러닝으로 신용카드 사기 탐지하는 것은 2~3차례에 걸쳐서 작성될 것 같습니다.
이번 포스팅은 기본적인 접근 방법에 대해서 설명합니다.
그럼 시작해보죠!
가장 먼저 머신러닝 모델에 대해서 평가를 계속 사용하게 됩니다.
그래서 이 중복되는 작업을 함수로 만들어주겠습니다.
함수 이름은 metrics이구요 y_test값과 예측값인 pred 값을 받아서 정확도, precision, recall, f1-score 등을 한 번에 볼 수 있도록 했습니다.

함수 내용은 위와 같습니다.
그리고 저는 credit card fraud 데이터를 다운 받아서 진행했습니다.
그래서 pandas의 read_csv 데이터를 load해서 사용합니다.

data = pd.read_csv()를 통해 csv 데이터를 가지고옵니다.
해당 데이터는 총 28만여개의 row 데이터와 31개의 feature를 가지고 있습니다.
자세히 봐볼까요?

V1 ~ V28까지의 feature를 가지고 있습니다. 아무래도 신용카드 데이터다보니 고객의 개인정보가 포함된 데이터가 있을 수도 있습니다. 그래서 컬럼을 숨긴 것 같습니다.
그리고 class가 있는데 이게 label 값입니다. 또한, amount와 time 이름을 가지고 있는 feature도 보이네요.
무엇보다 string이 포함되어 있지 않고 전부 숫자형태로 되어 있습니다.
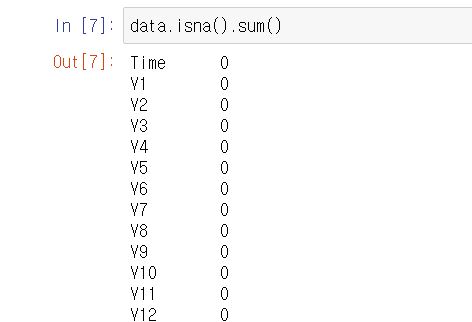
그리고 null 데이터도 존재하지 않습니다.
데이터 자체가 깔끔한 편이네요 ~
근데 이 신용카드 사기 데이터셋의 문제점은 아래와 같습니다.

바로 굉장히 unbalance하다는 것입니다. 왜냐하면 신용카드의 대부분 정상 데이터이고 신용카드의 사기 건수는 몇 개 없기 때문입니다.
그렇다고 해도 굉장히 unbalance한 데이터입니다. label을 보면 1(신용카드 사기 건)은 거의 보이지도 않죠.
28만여개 중 신용카드 사기 건수의 데이터가 500개도 안됩니다. 굉장히 균형이 무너져있는 데이터입니다.
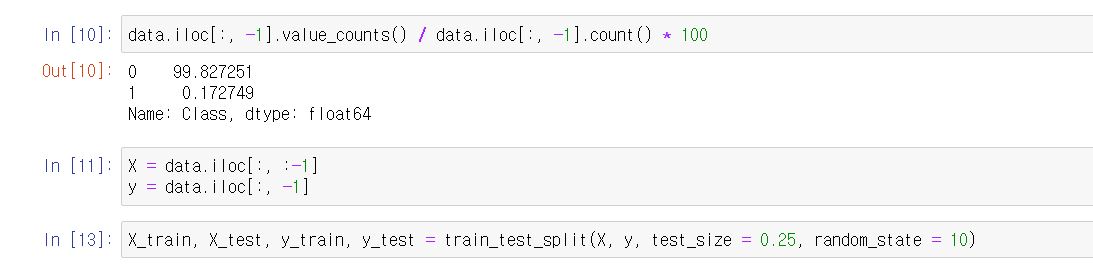
그래서 그 비율을 확인해보겠습니다.
data.iloc[:, -1].value_counts() / data.iloc[:, -1].count() 혹은 len(data)로 나누어서 * 100을 하면 비율이 나오는데요.
신용카드 사기인 건수와 아닌 건수의 비율이 99.8% vs 0.02입니다. 엄청나게 unbalance하죠.
해당 데이터를 지금 어떻게 할 수 있는 것은 아니니까 일단은 한번 train과 test dataset으로 나누어보겠습니다.
여기서 주의하셔야 할 것은 train_test_split으로 데이터를 나누었는데 그 나눈 데이터의 비율이 일정하게 유지된 상태로 나누어 졌는지 확인해야 합니다.

그래서 train과 test의 비율을 확인해보니 원본 데이터의 비율인 99.8% vs 0.02% 정도의 비율로 비슷하게 나누어졌네요.
그리고 하나의 함수를 더 만들겠습니다.
앞으로 계속 model을 훈련하는 작업을 반복적으로 수행합니다.
그리고 model을 training하고 평가하는 metric 작업도 반복적으로 수행하죠.
그래서 이 머신러닝 모델을 training하고 metric을 평가하는 함수를 만드려고 합니다.

함수 이름은 modeling이고 원하는 model과 train, test 데이터를 인자로 받습니다.
그리고 아까 만들었던 metrics를 호출해서 fit한 뒤 model을 평가합니다.
자! 그럼 현재까지 그냥 아무것도 하지 않은 상태에서
머신러닝을 기반으로 신용카드 사기를 검출해보겠습니다.
로지스틱 회귀와 lightgbm으로 진행해보겠습니다.

로지스틱 회귀의 경우 정밀도는 0.77, 재현율은 0.53, f1-score는 0.63, auc는 0.76입니다.
lightgbm의 경우 정밀도는 0.95, 재현율은 0.83, f1-score는 0.88, auc는 0.91 정도가 나옵니다.
lightgbm의 경우에 확실히 성능이 더 좋네요
자! 그럼 머신러닝을 활용한 신용카드 사기 탐지 1편은 일단 여기에서 마무리 하겠습니다.
다음 포스팅에서 logistic regression의 성능을 올려주는 방법과 이상치(outlier) 탐지를 활용해서 머신러닝 모델의 성능을 향상시키는 방법에 대해서 알아봅니다.
'인공지능(AI) > machine learning(머신러닝)' 카테고리의 다른 글
| 머신러닝, 딥러닝 이상치(outlier) 데이터 탐지 및 제거 하기 - outlier data detection and remove (10) | 2019.12.15 |
|---|---|
| 머신러닝으로 신용카드 사기 탐지하기 2편 - 데이터 정규화(data normalization) (0) | 2019.12.12 |
| 머신러닝 ensemble lightgbm 알고리즘이란? - python 예제와 함께 살펴보자 (2) | 2019.11.22 |
| 머신러닝 앙상블(ensemble) xgboost란? - Python 예제와 함께 살펴보기 (15) | 2019.11.21 |
| 윈도우10에 xgboost 설치하기 - ensemble xgboost install (4) | 2019.11.18 |



