
지난 포스팅까지 머신러닝 앙상블에 대해서 계속 올리고 있습니다.
머신러닝 앙상블(machine learning ensemble)에서는 대표적으로 배깅(bagging)과 부스팅(boosting)이 있습니다.
그 중 앙상블 부스팅(ensemble boosting)에 대해서 지속적으로 보고 있습니다.
머신러닝 부스팅 알고리즘은 틀린 부분에 가중치를 더하면서 진행하는 알고리즘인데요.
Gradient Boosting Machine(GBM)은 그 가중치를 경사하강법(gradint boosting)으로 진행하였습니다.
그리고 지난 포스팅에서 소개한 ensemble xgboost는 기존의 gradient boosting 알고리즘의 단점을 조금이라도 보완한 알고리즘이라고 했습니다.
그렇게 강력한 성능을 제공하는 xgboost였지만, 여전히 이슈가 있었습니다.
(lightgbm은 xgboost에 근간한 것이 많습니다. xgboost에 전반적인 자료를 못보셨다면 아래에서 확인하세요)
https://lsjsj92.tistory.com/547
머신러닝 앙상블(ensemble) xgboost란? - Python 예제와 함께 살펴보기
머신러닝에서는 앙상블(ensemble) 모델을 빼놓을 수가 없습니다. 이 앙상블에는 배깅(bagging)과 부스팅(boosting) 그리고 보팅(voting) 방법이 있습니다. 크게 보면 말이죠 이 중 ensemble bagging에 대해서는 지..
lsjsj92.tistory.com
본문에 나와있는 코드는 아래 github에서 확인할 수 있습니다.
github.com/lsjsj92/machine_learning_basic
lsjsj92/machine_learning_basic
Repo for everyone who wants a machine learning basic - lsjsj92/machine_learning_basic
github.com
머신러닝 앙상블 알고리즘 LightGBM이란? 왜 나오게 되었을까?
boosting 알고리즘인 xgboost는 굉장히 좋은 성능을 보여주었지만 여전히 학습시간이 느리다는 단점이 있었습니다.
알고리즘이 느린 것과 더불어 하이퍼 파라미터도 많은데요.
만약, grid search등으로 하이퍼 파라미터 튜닝을 하게 되면 그 시간은 더욱 오래 걸린다는 단점이 존재했습니다.
LightGBM은 이러한 단점을 보완해주기 위해 탄생하였습니다.
LightGBM은 대용량 데이터 처리가 가능하고, 다른 모델들보다 더 적은 자원(메모리 등)을 사용합니다. 그리고 빠르죠.
또한, GPU까지 지원해주기도 한답니다. 그래서 기존 앙상블 boosting 모델들보다 더 인기를 누리고 있기도 합니다.
그러나 이 LightGBM은 너무 적은 수의 데이터를 사용하면 과적합(overfitting)의 문제가 발생할 수 있습니다.
LightGBM의 특징
lightgbm은 기존의 gradient boosting 알고리즘과 다르게 동작됩니다.
기존 boosting 모델들은 트리를 level-wise하게 늘어나는 방법을 사용했는데요. lightgbm은 leaf wise(리프 중심) 트리 분할을 사용합니다.
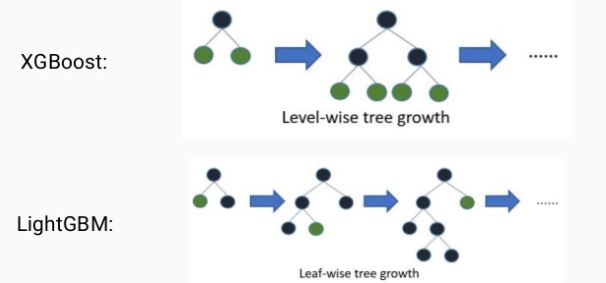
기존의 트리 들은 트리의 깊이(tree depth)를 줄이기 위해서 level wise(균형 트리)분할을 사용했는데요. lightgbm은 이것과 다르게 모델이 동작됩니다.
level-wise 트리 분석은 균형을 잡아주어야 하기 때문에 tree의 depth가 줄어듭니다. 그 대신 그 균형을 잡아주기 위한 연산이 추가되는 것이 단점이죠.
lightgbm은 트리의 균형은 맞추지 않고 리프 노드를 지속적으로 분할하면서 진행합니다.
그리고 이 리프 노드를 max delta loss 값을 가지는 리프 노드를 계속 분할해갑니다. 그렇기 때문에 비대칭적이고 깊은 트리가 생성되지만 동일한 leaf를 생성할 때 leaf-wise는 level-wise보다 손실을 줄일 수 있다는 것이 장점입니다.
파이썬(Python)에서 LightGBM 사용하기
python에서는 이와 같은 lightgbm을 제공해줍니다.
정말 간단하게 pip install lightgbm을 해서 설치할 수 있습니다.
xgboost와 마찬가지로 scikit learn에서 그냥 제공해주지 않기 때문에 pip install로 lightgbm을 설치해주어야 합니다.
또한, lightgbm에게도 여러가지 하이퍼 파라미터 값들이 있습니다.
대체적으로 xgboost와 hyperparameter들이 비슷합니다.
하지만, xgboost와 다르게 lightgbm은 leaf-wise 방식의 알고리즘을 사용하기 때문에 leaf-wise 방식의 하이퍼 파라미터 값이 추가가 됩니다.
- n_estimators : 반복하려는 트리의 개수
- learning_rate : 학습률
- max_depth : 트리의 최대 깊이
- min_child_samples : 리프 노드가 되기 위한 최소한의 샘플 데이터 수
- num_leaves : 하나의 트리가 가질 수 있는 최대 리프 개수
- feature_fraction : 트리를 학습할 때마다 선택하는 feature의 비율
- reg_lambda : L2 regularization
- reg_alpha : L1 regularization
등의 파라미터가 lightgbm에 있습니다. 더 자세한 것을 알고 싶으시면 아래 링크를 참조하세요.
https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html

기본적으로 from lightgbm import LGBMClassifier 을 통해 lightgbm을 import할 수 있습니다.
그리고 plot_importance 라는 것도 import 할 수 있는데요.
지난 포스팅에서 보여드린 xgboost때 처럼 마찬가지로 feature의 중요도(feature importance)를 보여주는 함수입니다.

그리고 일반 부스팅 모델들과 똑같이 사용할 수 있습니다. fit과 predict을 이용해서 학습과 예측을 할 수 있죠.
이게 scikit learn에서 제공해주는 방식에 맞추어 주었기 때문에 굉장히 유용합니다
또한, xgboost때와 마찬가지로 lightgbm도 early stopping(조기 종료)를 제공해줍니다.
early_stopping을 위한 eval data를 준비해서
early_stopping_rounds 값을 넣고 eval_set을 넣어주면 됩니다.

그리고 나서 모델 training을 하시면 됩니다. 위에 결과를 보면 26번째 제일 좋은 값에서 더 이상 늘어나지 않았다고 나옵니다. 여기서는 early_stopping_round에 해당하는 값까지 epoch가 동작되지 못했습니다.
그럼에도 불구하고 너의 가장 좋은 모델은 26번째 모델이라고 알려주고 그 모델을 기준으로 return 해줍니다.
그리고 lightgbm 또한 plot importance를 제공한다고 말씀드렸습니다.
사용법은 xgboost때와 똑같습니다.
feature importance를 보고 싶으시면 아래와 같이 사용하면 됩니다.

여기까지 lightgbm에 대한 간단한 설명이었습니다.
'machine learning(머신러닝)' 카테고리의 다른 글
| 머신러닝으로 신용카드 사기 탐지하기 2편 - 데이터 정규화(data normalization) (0) | 2019.12.12 |
|---|---|
| 머신러닝으로 신용카드 사기 탐지하기 1편- kaggle credit card fraud (0) | 2019.12.02 |
| 머신러닝 앙상블(ensemble) xgboost란? - Python 예제와 함께 살펴보기 (15) | 2019.11.21 |
| 윈도우10에 xgboost 설치하기 - ensemble xgboost install (4) | 2019.11.18 |
| 머신러닝, 딥러닝에서 데이터를 나누는 이유 - X_train, X_test, y_train, y_test이란? (32) | 2019.11.17 |



