
이번 포스팅은 파이썬 케라스와 장고(python keras, python django)를 활용한 딥러닝 기반 욕설 탐지 시스템을
개인적으로 만들어본 후기입니다.
데이터 특성 상 욕설이 포함되어 있을 수 있습니다! 만약 읽게 되신다면 감안 부탁드립니다 ㅠㅠ
프로젝트를 어쩌다가 하게 되었나?
어느 날 한 프로게이머가 은퇴했습니다. 제가 정말 좋아하는 프로게이머였고 리그오브레전드(롤) 선수였습니다.
유튜브도 유명한 프로게이머입니다. 프레이, 프짱이라고 불리우는 선수였죠
사실 은퇴 전에 이번 시즌을 쉰다고 했을 때도 복귀할 것이라 생각했습니다. 하지만 자신감을 잃었다고 하고 은퇴를 선언했죠.
쉬는 기간에 챌린저도 가볍게 찍었던 그 였습니다.
왜 그런 그가 자신감이 없다고 했을까? 어느 댓글을 보니 이런 글이 있었습니다.
'더 성장할 수 있는 선수도 비난하고 욕하는 유저들 때문에 떠난다'
이때 문득 생각이 들었습니다. 이런 비난, 욕설에 대한 글을 탐지하는 시스템을 만들어보면 어떨까?

이러한 욕설은 정말 많이 있습니다.
댓글 뿐 아니라 각종 오픈 커뮤니티에서 많이 발생되고 있습니다

게임에서도 마찬가지입니다. 그냥 채팅창에서 상대방을 비난함을 넘어서 인격을 깎아내리는 욕설을 사용합니다.
저는 이러한 욕설을 탐지하는 것을 자연어처리 딥러닝 기술을 이용해서 만들어보고자 했습니다.
간단한 토이 프로젝트이지만 같이할 동료 1명을 모집했고 프로젝트를 진행했습니다
뭐.. 게임 데이터는 제가 어떻게 할 수 없기에 접근이 비교적 쉬운 오픈 커뮤니티를 타겟으로 했습니다.
dc인사이드, 인벤 등의 커뮤니티 입니다

먼저 데이터 수집을 해야했습니다. json 파일에 url 리스트를 작성했습니다.
위는 제가 수집한 사이트의 일부입니다. dc인사이트 이며 hit갤러리, 주갤(주식 갤러리), 롤(리그오브레전드) 등의 사이트가 있었습니다.

그리고 크롤러를 만들어서 데이터를 수집했고 위와 같이 db에 저장했습니다.
초기에 수집한 총 데이터는 대략 75만개 정도였습니다.
그리고 데이터 수집과 동시에 커뮤니티의 특성을 살펴보았고 조사했습니다.
왜냐하면 커뮤니티마다 또한 갤러리 마다 사용하는 은어(약어 등)이 다르기 때문입니다.
그래서 어떤 단어가 사용되는지 조사했고 그 게시판의 특징을 조사했습니다.
이 조사만 2주정도 걸린 것 같습니다.(조금씩 하느라..)
그리고 그렇게 알게 된 언어를 따로 정리했습니다.
이후 형태소 분석기를 사용하기 위해 사용자 단어 사전(user dic)을 만들었습니다.
이번 프로젝트에서 사용한 사용자 단어 사전은 3200여개 정도 됩니다.
모든 것을 다 태깅할 수는 없었지만 그래도 많이 사용하는 약어들과 은어들은 형태소 분석이 가능하였습니다.
형태소 분석은 은전한닢을 사용했습니다. 이번 기회에 카카오 형태소 분석기(khaii)를 사용해볼까 했는데
시간이 없어서 ㅠㅠ 기존에 하던 대로 은전한닢(Mecab)을 사용했습니다.

그리고 형태소 분석을 한 결과를 다시 데이터베이스에 넣었습니다.
위 사진은 그 결과입니다.
이제 데이터 수집이 끝나고 도메인 특징 조사, 형태소 분석까지 완료했습니다.
슬슬 어떻게 서비스를 만들 것인지 고민했습니다.
저희는 아래와 같이 서비스 흐름도를 생각했습니다.

1. 데이터 수집(웹 크롤러) 및 저장
2. 토크나이징 및 저장
3. 데이터를 활용한 딥러닝 모델 훈련 및 새로운 데이터를 딥러닝 모델을 활용해서 category 예측(욕설인지 아닌지)
4. web과 DB를 바로 바라보는 것이 아닌 Restful API 서버를 중간에 설정
5. Restful API는 swagger(스웨거)를 통한 관리
6. request 보안 관리
7. django를 활용한 back과 front 개발
위와 같은 흐름을 생각하였고 진행하였습니다.
스웨거를 통해서 restful api를 보게 되면 아래와 같습니다

게시판 부분만 보면 begin, count 등의 값에 따라서 요청을 보내고 그에 따른 응답을 받을 수 있습니다.
게시판 외에도

그래프 데이터를 위한 요청, 형태소 분석 결과를 가져오는 요청 등
각 기능에 따라서 api를 요청하고 받아올 수 있도록 만들었습니다.
이 api 서버는 spring boot를 사용해서 개발했습니다.

그리고 저희 일정관리는 트렐로(trello)를 활용하였습니다.
저장소는 gitlab을 활용해서 버전 관리 및 코드를 관리하였습니다.
이제 데이터를 분석할 차례입니다.
형태소 분석이 된 데이터를 가져와서 데이터를 살펴보면

이러한 단어들이 많이 사용된 것을 볼 수 있습니다. 정치적인 안좋은 용어와, 북한, 각종 욕설 등의 데이터가 보입니다.
역시나 사람들이 욕설을 많이 사용합니다. 뿐만 아니라 옳지 못한 정치적 단어도 사용합니다.
이러한 것들을 전부 감지해주는 모델을 만들어야 했습니다.
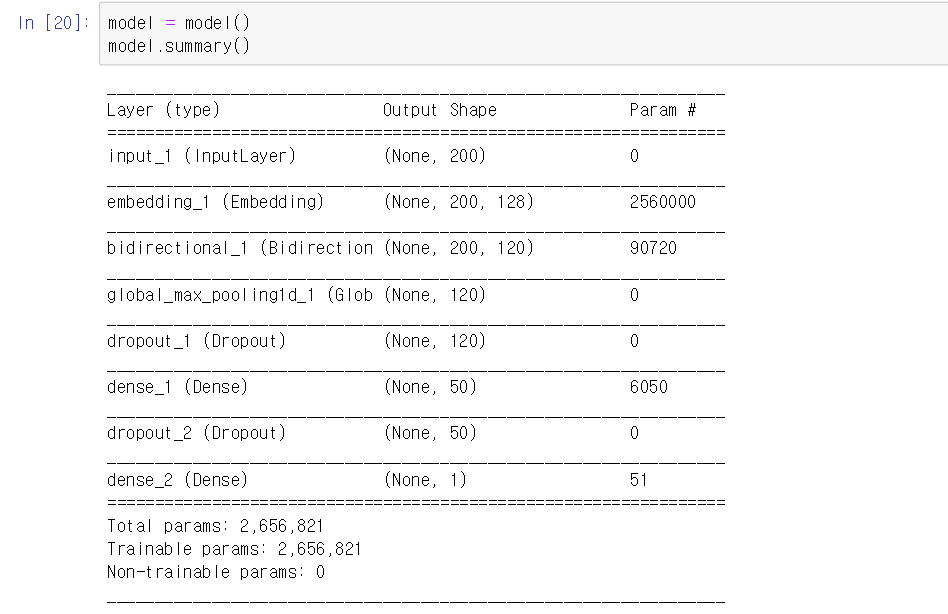
그래서 딥러닝 모델을 만들었습니다.
정확도는 대략 92% 정도 나왔습니다.
이제 새로 들어오는 데이터에 대해서 딥러닝 모델이 예측을 하고 그 결과 값을 데이터베이스에 저장하는 방법을 사용했습니다. 서버 성능이 무료 서버라서.. 너무 성능이 안좋았습니다.
그래서 이게 한계였습니다.
그리고 django를 활용해서 웹 개발을 진행했습니다.
웹 화면은 아래와 같은 메뉴가 있습니다.
1. 수집한 데이터가 욕설인지 아닌지 보여주는 게시판 형태
2. 최근 특정 기간 동안 수집한 데이터의 욕설 유무 개수 파이차트 및 많이 사용한 단어 wordcloud
3. 수집한 데이터 개수를 보여주는 라인 그래프
초기 버전이기에 일단 이정도만 사용하기로 했습니다.
나중에 규모가 커지만 더 많은 기능을 추가할 것입니다.
그 결과는 아래와 같습니다.
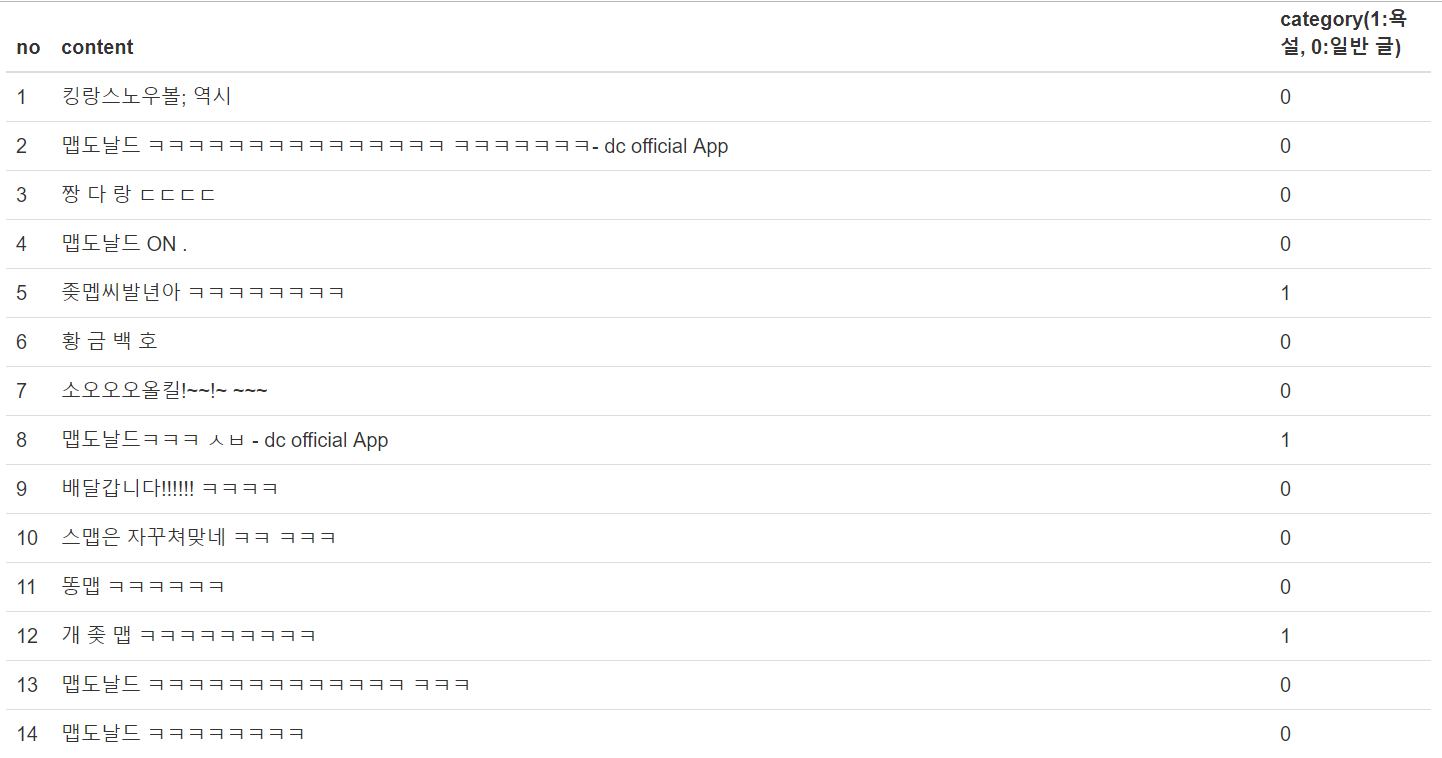
위 데이터는 최근 롤 게시판에서 수집한 데이터입니다.
오른쪽에 욕설인지 아닌지 보여주는데요. 1이 욕설입니다.
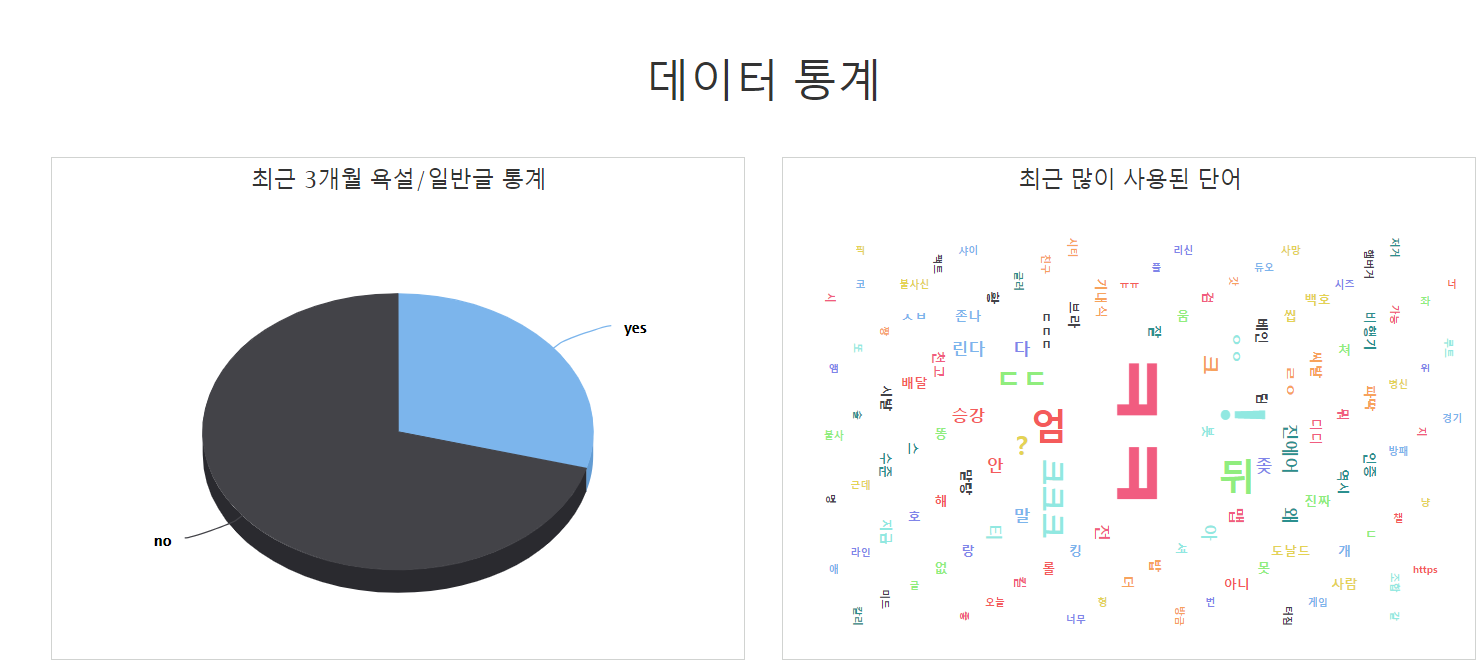
그리고 다음 메뉴에서는 최근 3개월 욕설/일반글 통계를 보여줍니다.
욕설이 아닌 것이 그래도 많습니다. 또한, 최근 많이 사용한 단어를 보여주고 있습니다.
그리고 마지막에 데이터 수집 상황을 보여줍니다.
이렇게 간단하게 딥러닝을 활용한 욕설 데이터 감지 서비스를 만들어보았습니다.
자연어처리 분야에 해당되죠 ㅎㅎ
어렵지 않았지만 부족한 점이 아직 많습니다.
욕설이 되게 애매하다는 것과, 특정 게시판에 따라 너무 글의 특성이 달라진다는 점 등등
다른 아이디어와 기술적 이슈를 더욱 고민해서 보완해야겠습니다.
'deep learning(딥러닝)' 카테고리의 다른 글
| 딥러닝 자연어처리 이해하기! - 기계번역편(NMT), seq2seq란? (2) | 2019.07.18 |
|---|---|
| 딥러닝(keras lib) 기반 욕설 탐지 서비스 추후 개발 방향 정리 (0) | 2019.05.23 |
| keras 딥러닝 gpu 사용이 되고 있나? 확인해보자 keras gpu 확인 (0) | 2019.04.24 |
| 어텐션 메커니즘(Attention Mechanism)이란? 어텐션에 대해서 (4) | 2019.03.15 |
| 딥러닝을 활용한 번역기를 만들어보자!(python keras seq2seq translate model) (0) | 2019.03.13 |



