
목록2019/01 (13)
꿈 많은 사람의 이야기
 웹 div를 image로 download하는 방법!(html2canvas.js)
웹 div를 image로 download하는 방법!(html2canvas.js)
회사에서 프로젝트를 하면서현재 html div 영역에 그러져 있는 이미지나, 그래프를 이미지(image)로 다운로드 가능하도록 해달라는 요구가 있었다그래서 '이게 되나?' 이러면서 찾아봤었는데처음에는 node js로 div image download 기능만 보이다가 더 찾아보니까html2canvas라는 js 라이브러리가 있었다 만약 이런 사진이 있다면 이렇게 이미지를 올리고이미지로 다운로드를 클릭을 하면 파일이 다운로드가 된다.파일명은 바꿀 수 있다 이렇게 png 파일로 다운로드가 된 것을 볼 수 있다.사용법은 의외로 정말 간단했다(물론 별의 별 오류를 다 겪었지만..) 버튼 하나 만들고 버튼 클릭 시 printdiv 함수를 호출하는데 $('#div_id')를 넘겨주면 된다.자바스크립트로 하실꺼면 doc..
 virtual box centos6.7 환경에서 클라우데라 매니저(cloudera manager)로 하둡 설치하기-2
virtual box centos6.7 환경에서 클라우데라 매니저(cloudera manager)로 하둡 설치하기-2
지난 포스팅에서 클라우데라(cloudera) 환경에서 아파치 하둡을 설치했습니다. 더불어서 주키퍼(zookeeper), 얀(yarn)도 설치했죠.https://lsjsj92.tistory.com/432이제 이후의 기본적인 설정 방법입니다.아무래도 vm 환경이다 보니 높은 퍼포먼스로 진행하기 힘듭니다.저는 램이 16G인데도 각 노드 램을 4, 4, 2로 주니까 죽을라고 하네요 ㅋㅋㅋㅋㅋ 그래서 필요한 설정 등을 할 수 있습니다. 먼저 호스트에 들어가서 역할에 들어가봅니다 그러면 클러스터에서 각 노드들의 역할을 볼 수 있습니다~어떤 노드에 무엇이 설치되어 있는지 한 눈에 볼 수 있죠 그리고 클라우데라 매니저 메인으로 가서 HDFS 오른쪽의 화살표 버튼을 누르면 역할 인스턴스 추가가 보입니다.이걸 누르시면 위..
 virtual box centos6.7 환경에서 클라우데라 매니저(cloudera manager)로 하둡 설치하기
virtual box centos6.7 환경에서 클라우데라 매니저(cloudera manager)로 하둡 설치하기
빅데이터 분석과 적재를 위한 하둡 아키텍처 설치는 다양한 방법으로 설치할 수 있습니다.뭐 그냥 일반적인 방법은 단순히 3~4대의 centos7 등을 설치해서 거기에 자바 설치하고, 하둡 설치하고하나하나 다 설치하는 방법이 있습니다.저도 예전에는 계속 이 방법으로 설치했고, 도커 환경에서도 설치를 해봤었습니다. 하지만 이 과정이 하둡, 주키퍼, 스파크, 제플린 등의 설치까진 그래도 괜찮은데플럼, 카프카, 스쿱 등의 다양한 하둡 에코시스템을 설치하다보면 설치가 굉장히 까다로워지고 복잡해집니다.그래서 이러한 과정을 좀 단순하고, 명확하게 해주면서 설치를 쉽게 해주는 방법이 있는데요그 중 하나가 클라우데라를 이용하는 방법입니다.클라우데라는 빅데이터 아키텍처 오픈 소스들을 한데 모아서 잘 조립해주기도 하고, 제품..
 파이썬 StratifiedKFold와 axis = 0 , axis = 1 정리
파이썬 StratifiedKFold와 axis = 0 , axis = 1 정리
최근에 캐글을 하면서 가장 많이 헷갈렸던 부분이바로 StratifiedKFold와 pandas에서 axis=0, 1의 대한 개념이었다. 아무것도 모르는 상태도 아니었고 개념적으로는 알고 있었는데막상 코드를 필사하면서 보니까 정말 헷갈렸었다그래서 정리를 간단하게 해보려고 한다. 먼저 간단하게 데이터셋을 만들어본다.pd.DataFrame을 통해서 만든다 자, 처음으로는 StratifiedKFold를 해본다.from sklearn.model_selection import StratifiedKFold를 통해 라이브러리를 가져온다.사용법은 정말 간단하다. StratifiedKFold를 선언하고 splits 개수와 shuffle 여부, random_state 등을 설정해준다.그리고 저 상태에서 바로 .split(x..
 [4주차] 새벽 5시 캐글(kaggle) 필사하기 - porto 데이터 편 - 2
[4주차] 새벽 5시 캐글(kaggle) 필사하기 - porto 데이터 편 - 2
https://lsjsj92.tistory.com/429지난 3주차 포스팅 글입니다. 3주차에 이은 4주차입니다. (말이 n주차지.. 글이 밀려서 한 번에 올리네욯ㅎㅎㅎㅎ). 4주차에서도 저는 porto 데이터 셋을 가지고 다른 커널을 필사했습니다. 솔직히 타이타닉 다음으로 porto를 하는데 있어 너무 어려웠습니다. 그래서 이 데이터는 몇 번 더 해봐야겠네요 ㅠ 지난 커널에서는 모르는 내용이 너무 많았습니다. 왜 데이터를 그렇게 복잡하게 조합하고 그러는지 이해도 안되고요. 하지만 이 커널은 정말 명확하더라구요! 시작하겠습니다. 맨 위에 커널 주소가 나와있습니다. 저 주소로 진행했습니다.먼저 필요한 라이브러리를 import 합니다. Numpy, pandas는 기본이고, sklearn에서 model_sel..
 [3주차] 새벽 5시 캐글(kaggle) 필사하기 - porto 데이터 편 - 1
[3주차] 새벽 5시 캐글(kaggle) 필사하기 - porto 데이터 편 - 1
안녕하세요.새벽 5시 캐글 필사하기 3주차입니다.사실 캐글 필사는 계속 하고 있는데 블로그에 올리기가 너무 힘드네요요즘 바빠서 퇴근 시간이 늦다 보니(집오면 10시 ㅠ) 블로그에 올릴 시간이 없네요 ㅠ 3주차 주제는 porto 데이터 셋으로 진행합니다. 안전하게 운전을 하는 운전자를 예측하는 데이터입니다.데이터는 https://www.kaggle.com/c/porto-seguro-safe-driver-prediction 에 있습니다. 이번 주제도 1, 2주차에 걸쳐서 진행합니다. 1주차는 먼저 머신러닝 탐구생활이라는 책의 EDA 과정을 볼 것이고, 좀 이해하기 힘든 커널을 1개 필사했습니다.(아직도 이해가 안갑니다…) 시작해봅니다! 머신러닝 탐구생활 책을 기준으로 진행합니다. 역시 데이터부터 살펴보기 위..
 캐글을 하면서 겪은 이슈들(kernel stopping, timeout error)
캐글을 하면서 겪은 이슈들(kernel stopping, timeout error)
최근 캐글을 자주하고 있습니다.(새벽 5시 시리즈를 올려야하는데.. 블로그 글 쓸 시간이 만만치 않아서 못올리고 있습니다 ㅠ)근데 캐글을 하면서 알 수 없는 에러를 자주 겪었습니다.그것에 대해서 몇 개 정리해보려고 합니다. 먼저 아래와 같은 사진 이슈입니다. timeout waiting for IOPub output 이라는 warning이 나옵니다.음 그렇게 치명적인 오류는 아닌 것 같은데요. 저는 이게 나오면서 커널이 멈추는 현상이 나왔습니다(kernel stopping)알고보니 이게 모델을 훈련 하는 등의 과정에서 output이 나오는데요.예를 들어 verbose값이 1이거나 이런 상황에서요. 이런 출력이 좀 무리?가 되는 것이 있나봅니다.verbose = 0으로 하면 별 문제없이 해결됩니다. 그리고..
 [2주차] 새벽 5시 캐글(kaggle) 필사하기 - 타이타닉 편_2
[2주차] 새벽 5시 캐글(kaggle) 필사하기 - 타이타닉 편_2
어느덧 새벽 5시 캐글(kaggle) 2주차이다!지난 게시글에서 타이타닉(titanic) 캐글 커널을 필사했었다하지만 결과는 그리 좋지 못했었는데 오늘은 그것을 보완하는 작업을 한다 이번 필사 작업의 참조 커널은 https://www.kaggle.com/yassineghouzam/titanic-top-4-with-ensemble-modeling/notebook 에서 참고하였다! 이것을 필사? 참고 후 현재 나의 캐글 상태이다.캐글 코리아에서 주최한 2019 1st ML month with KaKR 대회 성적은 별로지만밑에 titanic : machine learning 부분의 대회는 상위 6% 성적을 보였다. 이 글은 주로 seaborn의 factorplot을 자주 이용했다.factorplot을 사용하면..
 [1주차] 새벽 5시 캐글(kaggle) 필사하기 - 타이타닉(titanic) 편
[1주차] 새벽 5시 캐글(kaggle) 필사하기 - 타이타닉(titanic) 편
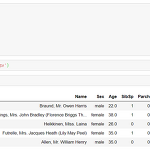
새해 첫 목표를 두고 있는 새벽 5시 캐글 필사 편 1주차 내용이다. 사실 원래 다른 데이터로 진행하려고 했는데 어쩌다 보니 타이타닉으로 넘어왔다. 머신러닝 탐구생활이라는 책으로 시작하려고 했지만 쉽지 않았기 때문이다. 또한, 데이터 분석을 한동안 안했더니 감을 잃은 것도 컸다. 그리고 마침 페이스북 그룹인 캐글 코리아(kaggle korea)에서 대회를 타이타닉을 주제로 하고 있기에 타이타닉으로 진행했다. 이 과정에서 1주일이 날라갔다 ㅠ 그래서 타이타닉 편으로 시작! 이 필사는 다양한 커널을 참조했다. 타이타닉 커널을 보면 open되어 있는 커널 중 인기 많은 커널 2개와 약간의 내 아이디어? 를 짬뽕시켜서 진행했다. 많이 참조한 대표적인 커널은 https://www.kaggle.com/ash316/..
 도커(docker)에 하둡, 스파크 설치 후 제플린(zeppelin) 설치 및 배포 - 3
도커(docker)에 하둡, 스파크 설치 후 제플린(zeppelin) 설치 및 배포 - 3
지난 포스팅에서 도커(docker)환경에 빅데이터 솔루션인 하둡(apache hadoop)과 스파크(apache spark)를 설치했습니다.https://lsjsj92.tistory.com/422해당 글을 참조하시면 되겠습니다. 오늘은 세번째 포스팅입니다. 제플린을 설치해보도록 하겠습니다.제플린은 스파크 개발 시 편리하게 도와주는 일종의 파이썬 주피터 노트북(jupyter notebook)과 같은 역할을 합니다.https://zeppelin.apache.org/해당 사이트에서 다운로드를 받으시면 됩니다.저는 하둡과 스파크가 설치되어 있는 centos7에서 wget으로 다운 받았습니다. 이렇게요!그리고 압축을 풀어주시면 됩니다. 먼저 동작이 잘 되는지 테스트를 해봅니다.아직 설정은 하지 않고 그냥 화면이 ..