
포스팅 개요
본 포스팅은 최근 RAG(Retrieval-Augmented Generation)의 한계를 극복하기 위해 제안된 CRAG(Corrective Retrieval Augmented Generation)라는 논문을 리뷰하는 포스팅입니다.
LLM(Large Language Model)이 환각(Hallucination) 현상을 겪는다는 것은 이제 널리 알려진 사실입니다. 이를 해결하기 위해 외부 지식을 검색해 오는 RAG 기술이 필수적으로 사용되고 있죠. 하지만, 만약 "검색해 온 문서 자체가 틀렸거나 관련이 없다면" 어떻게 될까요? 기존 RAG는 검색된 문서를 맹목적으로 신뢰하다 보니, 잘못된 정보를 바탕으로 더 그럴듯한 거짓말을 만들어내곤 합니다.
CRAG는 바로 이 지점에서 출발합니다. 검색된 문서의 품질을 스스로 평가(Self-correct)하고, 그 결과에 따라 지식을 정제하거나 아예 웹 검색(Web Search)을 통해 외부 정보를 다시 찾아오는 능동적인 방법을 제안합니다. 특히 검색 실패 시에도 시스템이 무너지지 않고 강건하게(Robust) 답변을 생성할 수 있도록 설계된 것이 특징입니다.
본 논문의 아카이브 링크는 아래와 같습니다.
- https://arxiv.org/abs/2401.15884 (Corrective Retrieval Augmented Generation)

포스팅 본문
포스팅 개요에서도 언급했듯, 이제 RAG는 단순히 '검색해서 보여주는' 단계를 넘어 '검색된 내용이 맞는지 검증하는' 단계로 진화하고 있습니다. 본 포스팅은 논문의 흐름을 따라가되, 제가 깊이 고민했던 부분과 해결 전략(Deep Thinking)을 함께 다루겠습니다.
[1]. Abstract & Introduction
논문의 저자들은 RAG가 LLM의 훌륭한 보완책임은 인정하지만, "검색 실패(Retrieval Failure)"에 너무 취약하다는 점을 꼬집습니다. 검색기가 부정확한 문서를 가져오면, 생성기(Generator)는 이를 걸러내지 못하고 오답을 생성하게 되죠. 이를 해결하기 위해 저자들은 Retrieval Evaluator(검색 평가기)를 도입하여 검색된 문서의 신뢰도를 계산하고, 이에 따라 다른 행동(Action)을 취하는 CRAG를 제안합니다.

위 사진인 논문의 Figure 1은 이 문제를 아주 직관적으로 보여줍니다.
왼쪽 그림처럼 정확한 문서가 검색되면 "정치인"이라는 정답을 잘 맞히지만, 오른쪽 그림처럼 엉뚱한 문서(배트맨 영화 관련)가 검색되면 LLM은 그 안에 있는 "Hamm"이라는 단어를 보고 엉뚱한 답을 내놓습니다. 즉, 낮은 품질의 검색은 오히려 독이 된다는 것이죠.
[2]. CRAG (Corrective RAG) 방법론 상세
그렇다면 CRAG는 어떻게 검색 실패를 바로잡을까요? 핵심은 "평가하고, 행동한다"입니다. 논문의 Figure 2와 Algorithm 1은 이 과정을 상세히 설명하고 있습니다.
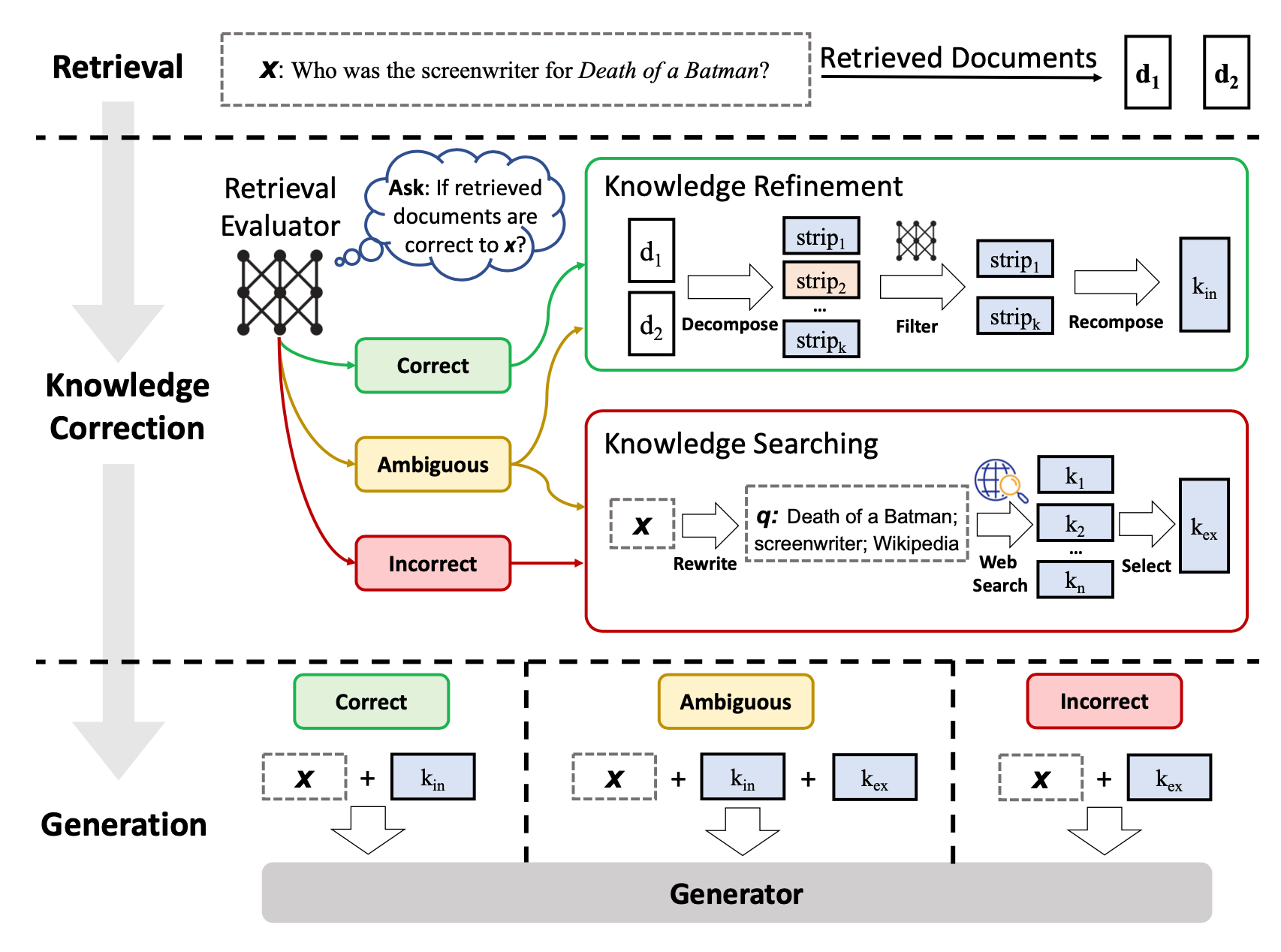
[2-1]. Retrieval Evaluator (검색 평가기)
가장 먼저, 입력된 질문(Query)과 검색된 문서(Document)가 얼마나 관련이 있는지 평가합니다. 저자들은 이를 위해 T5-large 모델을 Fine-tuning하여 사용했습니다. 이 평가기는 각 문서에 점수를 매기고, 전체적인 신뢰도(Confidence)를 산출합니다.
[2-2]. Action Trigger (행동 트리거)
계산된 신뢰도 점수에 따라 CRAG는 다음 세 가지 중 하나의 행동을 취합니다. 이 부분이 CRAG의 가장 큰 매력 포인트입니다.
- Correct (정확): 검색된 문서의 신뢰도가 높습니다. 문서를 그대로 쓰지 않고 지식 정제(Knowledge Refinement)를 거쳐 핵심만 추출합니다.
- Incorrect (부정확): 검색된 문서가 모두 엉터리입니다. 과감히 버리고 웹 검색(Web Search)을 수행하여 외부 지식을 가져옵니다.
- Ambiguous (모호): 긴가민가한 경우입니다. 내부 지식을 정제해서 사용함과 동시에 웹 검색도 수행하여 정보를 보완합니다.

[2-3]. Knowledge Refinement & Web Search
Knowledge Refinement는 'Decompose-then-Recompose' 방식을 사용합니다. 문서를 세밀한 단위(strip)로 쪼개고(Decompose), 다시 평가하여 불필요한 내용을 걸러낸 뒤(Filter), 핵심 내용만 다시 합치는(Recompose) 과정이죠. 이는 문서 내에 섞여 있는 노이즈(Noise)를 제거하는 데 탁월합니다.
Web Search는 내부 DB에 답이 없을 때, 질문을 검색 엔진에 맞는 키워드로 변환(Query Rewriting)하여 구글 검색 등을 수행하는 과정입니다. "우물 안 개구리"가 되지 않도록 시스템을 확장하는 것이죠.
[3]. Experiment (실험 결과)
실험 결과는 꽤 인상적입니다. PopQA, Biography 등 다양한 데이터셋에서 기존 RAG는 물론 최신 기법인 Self-RAG보다도 높은 성능을 보였습니다. 특히 Figure 3의 결과가 눈에 띄는데요.
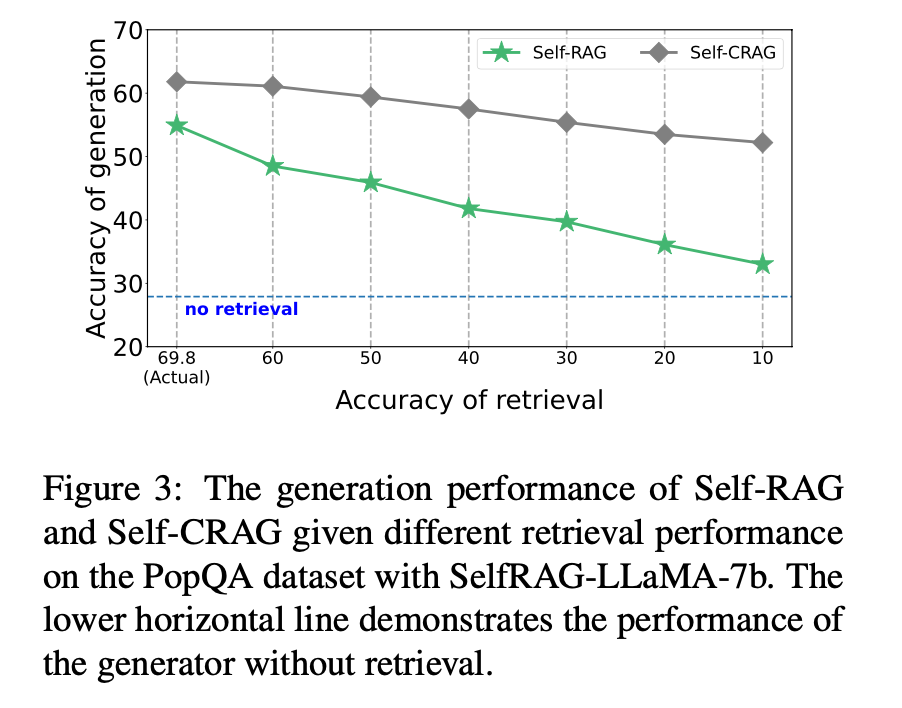
검색 성능을 일부러 떨어뜨려도(X축이 오른쪽으로 갈수록 검색 품질 저하), CRAG(회색 선)는 성능이 급격히 떨어지지 않고 잘 버티는 것을 볼 수 있습니다. 반면 기존 Self-RAG(초록색 선)는 검색 품질에 따라 성능이 출렁입니다. 이는 CRAG가 확실히 Robustness(강건성) 측면에서 우수하다는 것을 증명합니다.
실무 적용 전략에서의 고민
논문을 읽으면서 내용은 훌륭하지만, "이걸 실제 서비스에 적용하려면 비용과 효율성은 어떻게 하지?"라는 의문이 들었습니다. 특히 논문에서는 2024년 기준으로 작성되었다 보니, 2025년 현재의 최신 기술 트렌드와 접목했을 때 더 나은 방법이 있지 않을까 고민해 보았습니다.
제가 가졌던 의문점 두 가지와, 이를 해결하기 위한 전략을 정리해 봅니다.
[의문점 1] 데이터셋마다 Fine-tuning을 해야 하나? (비효율성 문제)
논문에서는 평가기(Evaluator)로 T5-large 모델을 Fine-tuning해서 사용합니다. 하지만 실무에서는 프로젝트마다, 도메인마다 매번 데이터를 모아서 튜닝하는 건 너무 비효율적이죠.
전략 1: Universal Reranker 활용 (No-Training)
2025년 현재는 굳이 튜닝할 필요가 없습니다. BGE-Reranker-v2나 Cohere Rerank v3 같은 범용 Cross-Encoder 모델들은 이미 수억 개의 데이터로 학습되어 있어, 튜닝 없이도(Zero-shot) 기가 막히게 관련성을 평가해 줍니다. 이를 API 형태로 가져다 쓰는 것이 훨씬 효율적이지 않을까 싶습니다.
전략 2: SLM-as-a-Judge (Agentic Approach)
최근 등장하는 Llama 3.2, Phi-3.5와 같은 소형 언어 모델(SLM)을 활용하는 것입니다. 모델을 학습시키는 대신, 프롬프트(Prompt)로 "이 문서가 질문에 적합한지 0~1점으로 평가해 줘"라고 에이전트에게 시키는 것이죠. 유지보수 측면에서 훨씬 유리한 전략입니다. 그리고 무료로 사용할 수도 있죠.
[의문점 2] 문서를 쪼개고 다시 평가하는 비용은? (비용 문제)
논문의 Knowledge Refinement 단계에서 문서를 쪼개고(Decompose), 다시 점수를 매겨 필터링(Filter)하는 과정은 사실상 Re-ranking 작업입니다. 문서 양이 많아지면 LLM 호출 비용이나 연산 비용이 만만치 않을 겁니다.
전략 1: ColBERT (Late Interaction) 도입
문서를 물리적으로 쪼개서 모델을 여러 번 돌리는 대신, ColBERT와 같은 Late Interaction 모델을 사용하는 것이 어떨까 싶었습니다. 이 방식은 한 번의 연산으로 문서 내의 어떤 토큰(단어)이 질문과 관련이 높은지 즉시 파악(Highlighting)할 수 있습니다. 관련 없는 부분은 자연스럽게 점수가 낮아져 필터링되므로, 비용은 줄이면서 효과는 동일하게 가져갈 수 있습니다.
전략 2: Contextual Compression (문맥 압축)
LLM에게 "필요 없는 거 지워줘"라고 시키면 비쌉니다. 대신, 임베딩 유사도나 Logit bias를 활용한 룰 베이스(Rule-based)로 관련 없는 문장을 즉시 날려버리는 Contextual Compression 기법을 사용하는 것도 방법이지 않을까 싶네요.
마무리
이번 포스팅에서는 검색 실패 상황을 스스로 인지하고 교정하는 CRAG(Corrective RAG) 논문을 리뷰하고, 실무에서는 어떻게 효율적으로 구현할 수 있을지 전략까지 고민해 보았습니다.
긴 글 읽어주셔서 감사합니다.
혹시라도 궁금한 점이 있거나 논의하고 싶은 부분이 있다면,
- Linkedin: https://www.linkedin.com/in/lsjsj92/
- 블로그 댓글 또는 방명록
으로 편하게 연락 남겨주세요!
'인공지능(AI) > LLM&RAG' 카테고리의 다른 글
| RAG 검색 품질의 핵심 '일관성(Coherence)' 높이기: Amazon AGI 연구 논문 리뷰 (0) | 2025.11.30 |
|---|---|
| 윈도우(windows)에서 PostgreSQL pgvector 설치 및 사용하기 (1) | 2025.11.19 |
| 업스테이지 문서 파싱(Document parsing) playground 서비스 개발기( 코드 공유 ) (1) | 2025.10.15 |
| ChatGPT GPT-5 프롬프트 가이드 정리 및 프롬프트 템플릿 예제(example) 공유 (0) | 2025.10.12 |
| AI 기반의 개인화된 교육과 맞춤형 학습 경험(Google: Towards an AI-Augmented Textbook) (1) | 2025.10.07 |



