
포스팅 개요
이번 포스팅은 대규모 언어 모델(Large Language Model, LLM)을 개인 로컬 환경에서 실행하고 배포하기 위한 Ollama 사용법을 정리하는 포스팅입니다. Ollama를 사용하면 유명한 모델들인 LLaMA나 Mistral와 같은 LLM 모델들을 쉽게 사용할 수 있도록 로컬에서 서버 형식으로 구성할 수 있는데요. Ollama가 무엇인지, 어떻게 설치하고 사용하는지를 정리해보고자 합니다.
본 포스팅은 아래 사이트를 참고해서 작성했습니다.
- https://github.com/ollama/ollama
- https://github.com/ollama/ollama-python
- https://ollama.com/
- https://github.com/ollama/ollama/blob/main/docs/modelfile.md
Ollama
Get up and running with large language models.
ollama.com

포스팅 본문
포스팅 개요에서 언급하였듯, 본 포스팅은 Ollama를 이용해 대규모 언어 모델(LLM)을 로컬 환경에서 서버를 구성하고 배포하는 과정을 예제(example) 형식으로 다음과 같은 순서로 정리합니다.
1. Ollama란? Ollama란 무엇일까?
2. Ollama 설치 방법 및 Python Ollama 연동 방법
3. Ollama 실행 및 API 실행 방법
4. Modelfile을 활용해 GGUF 파일 연동 방법
Ollama란?
Ollama를 소개하고 있습니다.
Get up and running with large language models locally
즉, Ollama란 Llama 2, Llama 3, Phi, Mistral, Solar와 같은 대규모 언어 모델(LLM)을 로컬 환경에서 실행할 수 있는 프레임워크입니다. 사용하는 방법도 쉬워, 누구나 손쉽게 Ollama를 이용해 LLM을 로컬 환경에서 실행하고 서버 형태로도 배포할 수 있죠.
Ollama 설치 및 Python Ollama 설치
그럼 Ollama를 실행해볼까요? 먼저, 실행하기 전에 Ollama를 설치해줘야 합니다. 설치 방법은 Ollama github나 공식 홈페이지에 나와있습니다. 먼저, github에 내용을 보면 아래와 같이 구성되어 있습니다.
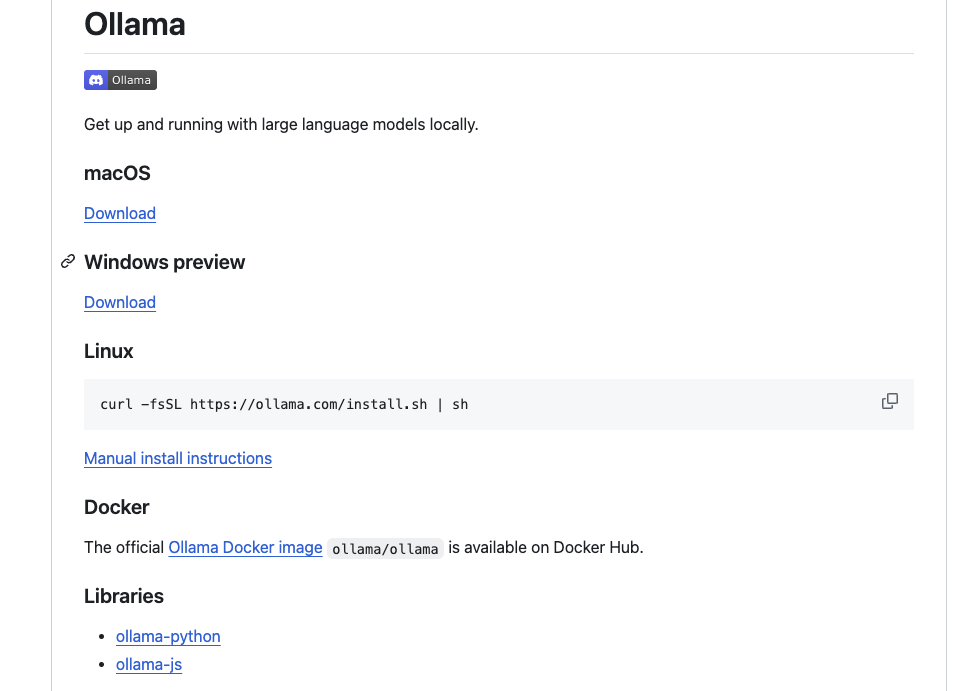
MacOS의 경우 다운로드 링크를 들어가서 Ollama를 다운받도록 되어있습니다. Linux 환경 같은 경우에는 curl 명령어(curl -fsSL https://ollama.com/install.sh | sh)를 통해 다운을 받을 수 있습니다. 윈도우도 마찬가지로 다운로드 링크가 제공되지만, 글을 쓰는 시점 기준(24.4.25) preview 상태이기 때문에 불안정할 수 있습니다.


Ollama 홈페이지를 가도 친절하게 설명이 나와있습니다. github에서 설명한 것과 마찬가지로 MacOS와 Linux 등 나눠서 다운로드 받을 수 있도록 안내 되어져 있습니다.
해당 파일을 다운받고 실행만하면 정말 간편하게 금방 설치할 수 있습니다.
Ollama 실행 방법
자! 이제 Ollama를 설치했다면 실행을 해보겠습니다. 본 포스팅에서의 예제는 제 PC 환경이 MacOS라서 mac을 기준으로 설명이 된다는 것 이점 참고해서 봐주시면 될 것 같습니다.
Ollama 자체 실행 방법
Ollama가 정상적으로 설치가 되었다면 ollama 라는 명령어가 동작이 될 것입니다. 먼저, ollama list를 입력을 해봅시다.
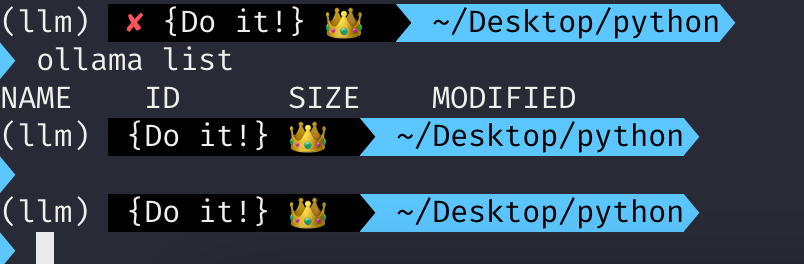
아마, 위처럼 ollama list를 입력하면 NAME ID SIZE 등만 나오고 아무것도 나오지 않을겁니다. 이유는 아직 로컬에 ollama 환경으로 설치된 LLM 모델들이 없기 때문입니다.
자, 그러면 맨 처음으로 LLM 모델을 하나 받아서, 실행해보겠습니다. 본 예제에서는 mistral 모델로 진행하겠습니다. 아래와 같은 명령어를 입력해봅니다.
ollama run mistral
그러면, 현재 제 PC 환경에는 mistral 모델이 없기 때문에 다운로드가 시작될 것입니다.
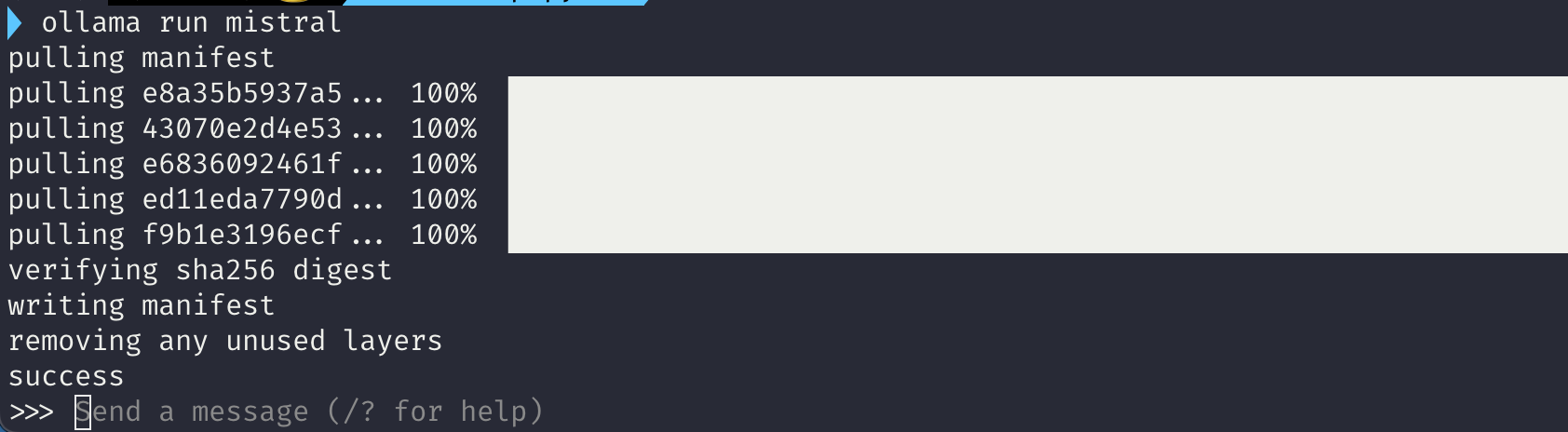
그리고 다운로드가 완료되면 verifying이라는 메세지가 뜨면서 마지막에 success가 나올겁니다. 이후 >>> 커멘드 라인 옆에 send a message가 보이게 됩니다.

저는 >>> 프롬프트에 Hello, I'm soojin! 이라고 입력해보았습니다. 그러니, mistral 모델이 저에게 인사를 하면서 어떻게 도와줄까?부터 시작해 쭉쭉 메시지를 생성하기 시작합니다. 신기하죠? 이렇게 쉽고 간단하게 LLM 모델을 제 local 환경에서 사용할 수 있게 되었습니다.
이 프롬프트에서 빠져나가고 싶다면 /bye 를 입력하면 빠져나갈 수 있습니다.
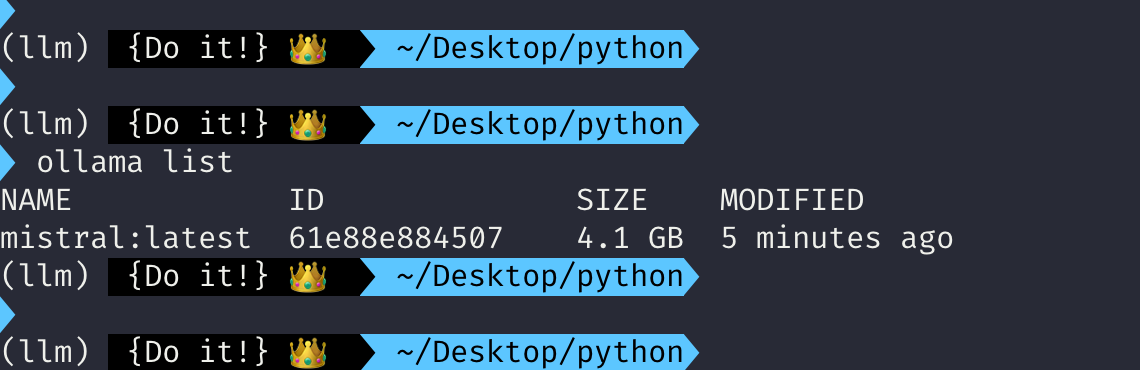
그리고 ollama list를 입력하면 방금 받아놓은 mistral 모델이 latest 태그로 보여지는 것을 확인할 수 있습니다.
( 아마, Docker에 익숙하신 분들이라면, 위 출력 등이 굉장히 Docker와 유사하다는 것을 느낄 수도 있을 것 같습니다. )
Ollama API 실행 방법
이렇게 실행된 ollama 모델은 API 형식으로도 불러올 수 있습니다. 본 포스팅의 ollama 튜토리얼을 따라오셨다면 ollama가 실행중이실거고 mistral 모델을 다운 받아졌을 겁니다. 그리고 위에서 실행했던 프롬프트는 빠져나와 아래와 같이 python을 실행해 Ollama API 통신 테스트를 진행해보겠습니다. 이를 위해, 먼저 python에서 ollama를 실행시키기 위해 패키지를 하나 설치해줍니다.
pip install ollama
그러면 파이썬에서 ollama와 통신하기 위한 패키지 설치가 완료될겁니다.
또한, ollama가 실행중이시다면, localhost:11434와 같이 url을 입력해 웹 브라우저에서 들어가면 ollama is running을 볼 수 있을겁니다.

이제, python ollama도 설치했고 ollama도 실행중이니 아래와 같이 코드를 입력해볼까요?
import ollama
response = ollama.chat(model=‘mistral’, messages=[
{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
print(response['message']['content'])
위 코드는 ollama의 chat 기능을 유도하는 함수입니다. 이때, 사용하는 모델은 저희가 방금 위에서 사용했던 mistral 모델을 지정합니다. 또한, role을 user로 정하고 content에 우리가 원하는 질문을 하나 입력합니다. 그러면 어떤 결과가 나올까요?

Ollama가 대답한 결과가 출력이 됩니다! 만약에, stream 형식으로 출력하고 싶다면 코드를 다음과 같이 수정하시면 됩니다.
stream = ollama.chat(
model=‘mistral’,
messages=[{'role': 'user', 'content': 'Why is the sky blue?'}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)

그러면 위에는 사진이라 정적으로 보이지만, 실제로 스트리밍(streamlng) 형식으로 문자열이 출력되는 것을 확인할 수 있을겁니다.
굳이 파이썬 ollama를 설치하지 않고 curl로도 ollama API를 호출할 수 있습니다.
curl http://localhost:11434/api/generate -d '{
"model": “mistral”,
"prompt":"Why is the sky blue?"
}'
curl http://localhost:11434/api/chat -d '{
"model": "mistral",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
첫 번째 curl은 localhost:11434에 떠있는 ollama의 API를 호출하면서 generate 하도록 호출합니다. 이때 모델은 mistral을 사용하도록 하죠. 두 번째 curl은 마찬가지로 ollama의 API를 호출하는데 chat 형식으로 호출합니다. 마찬가지로 LLM 모델은 mistral을 사용하도록 지정했습니다. 그 결과는 다음과 같습니다.
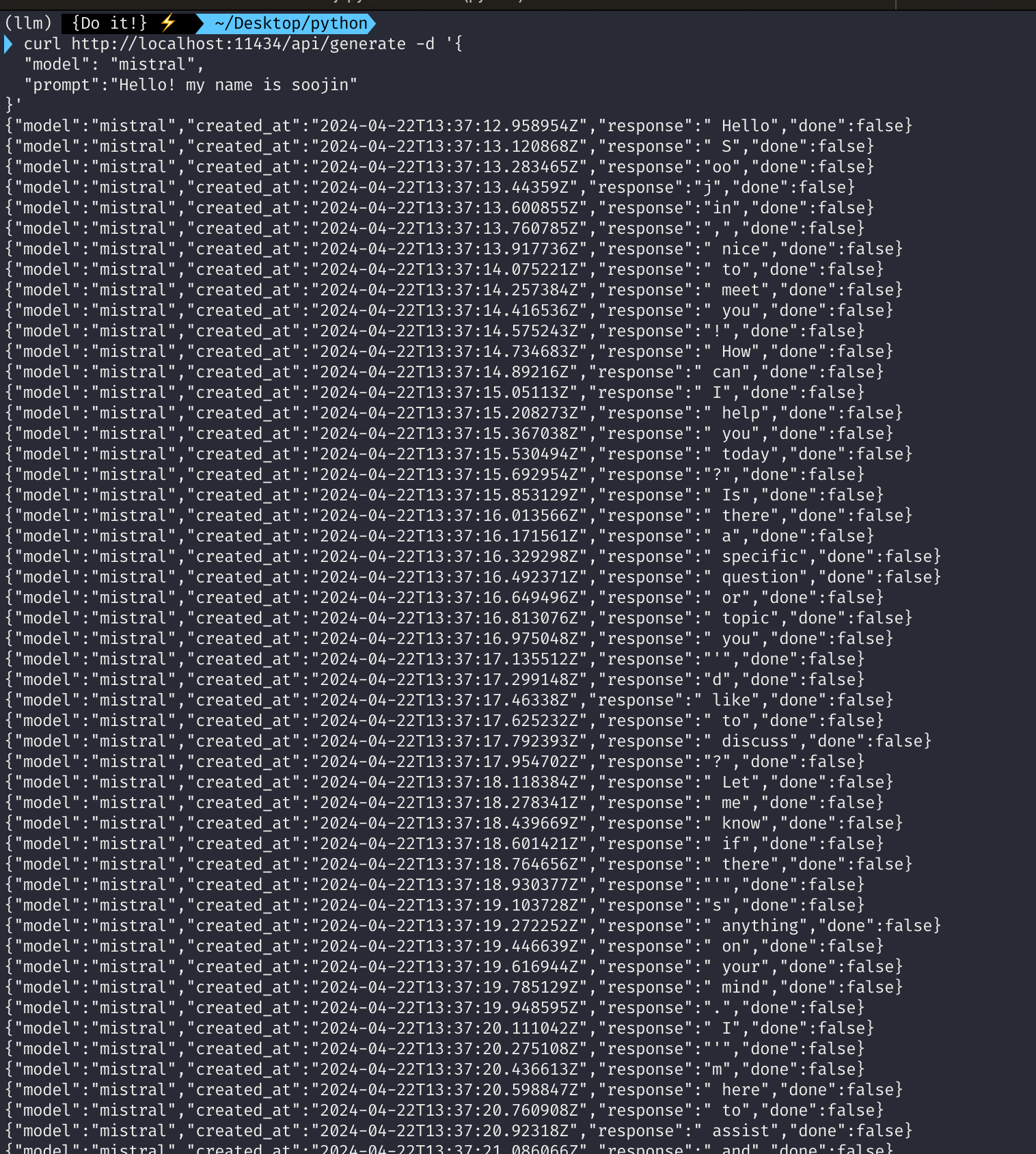

Modelfile을 활용해 Ollama에 모델 배포
이제 마지막으로 Modelfile을 활용해 ollama에 모델을 배포하는 예제를 살펴보겠습니다. Modelfile이란 Dockerfile과 유사하게 내가 어떤 모델을 사용할 것이고 탬플릿 형태는 어떠한지, 파라미터는 어떠한지 등을 지정해 모델을 셋팅할 수 있는 파일입니다. Modelfile를 통해 모델 구성을 간편하게 셋팅할 수 있는것이죠. 마찬가지로 mistrial 모델을 활용하되, 저는 mistral-7b-instruct-v0.2Q2_K.gguf 파일을 활용하겠습니다.

본 예제에서는 Modelfile을 이용해 gguf 파일의 모델을 ollama에 셋팅하기 때문에 Modelfile과 내가 사용하고자 하는 모델을 같은 경로의 디렉토리에 넣어줍니다. 그리고 저는 mistral 모델을 사용하기 위한 modelfile 내용으로 다음과 같이 구성하였습니다.
FROM mistral-7b-instruct-v0.2.Q2_K.gguf
TEMPLATE """[INST] {{ .System }} {{ .Prompt }} [/INST]"""
PARAMETER stop "[INST]"
PARAMETER stop "[/INST]"
Modelfile에 있는 위 내용은 어떤 모델을 사용할 것이며, 템플릿은 어떻게 되는지, 파라미터는 어떻게 구성되어 있는지로 내용이 구성되어 있습니다. Modelfile에 어떻게 내용을 넣으면 되는지는 huggingface에 있는 temple format 등을 참고하시면 됩니다.


이렇게 구성된 modelfile을 활용해 ollama 환경에 LLM 모델을 배포해보겠습니다. 명령어는 간단합니다.
ollama create mistral-7b -f Modelfile
ollama create는 생성하겠다는 명령어이고 그 다음 mistral-7b는 ollama에 지정할 이름이라고 보시면 됩니다. 그리고 이때 file을 Modelfile로 사용하겠다!라고 해석하시면 될 것 같습니다. 이렇게 명령어를 입력하면 다음과 같이 ollama에 모델이 새롭게 셋팅 및 배포가 될 것입니다.
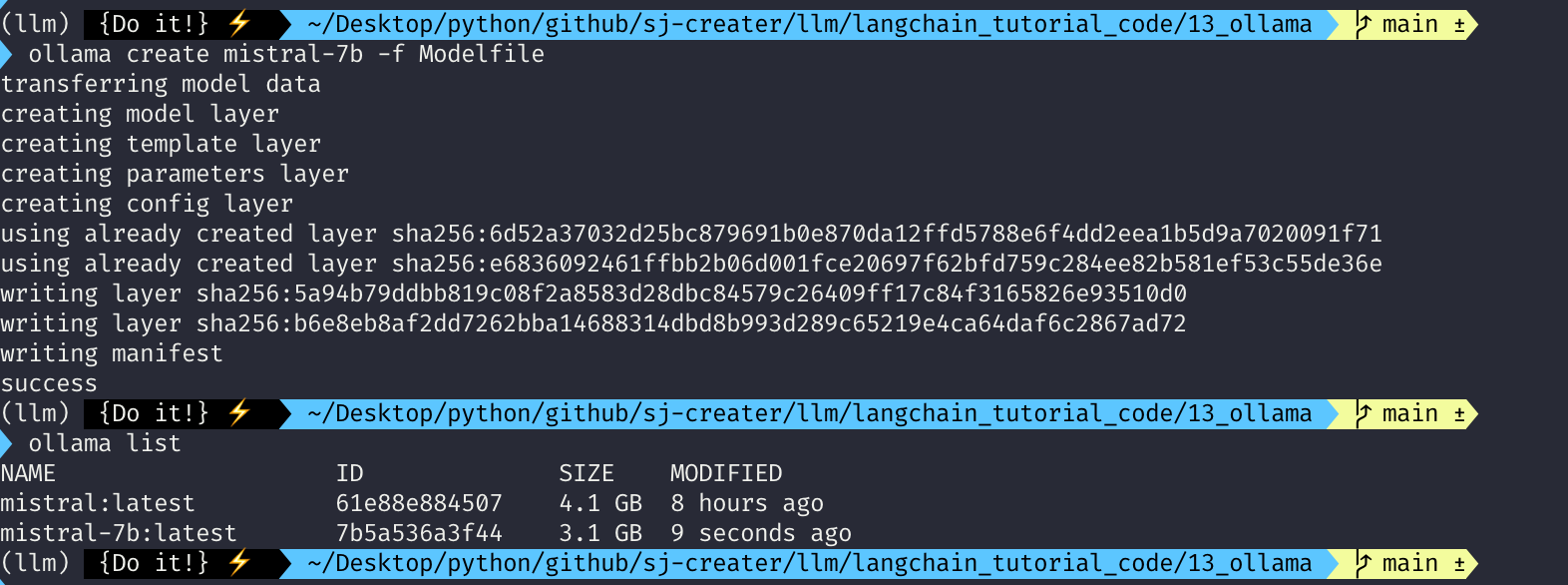
아까 설치했던 것은 mistral:latest였는데요. 이번에는 이름을 mistral-7b로 지정했기 때문에 mistrlal-7b:latest로 ollama list에 나오는 것을 확인할 수 있습니다. 마찬가지로 이렇게 구성된 모델을 run으로 실행하면

잘 동작되는 것을 확인할 수 있습니다.
마무리
본 포스팅은 대규모 언어 모델(LLM)을 로컬에서 쉽게 배포하고 실행할 수 있도록 도와주는 Ollama에 대해서 알아보았습니다. Ollama란 무엇인지, 어떻게 설치하는지, 어떻게 실행하는지에 대한 전반적인 내용을 확인해보았습니다.
부디 도움이 되시길 바랍니다.
감사합니다.
저에게 연락을 주시고 싶으신 것이 있으시다면
- Linkedin : https://www.linkedin.com/in/lsjsj92/
- github : https://github.com/lsjsj92
- 블로그 댓글 또는 방명록
으로 연락주세요!
'인공지능(AI) > LLM&RAG' 카테고리의 다른 글
| PostgreSQL PGVector 설치 및 사용하기(Feat. 벡터 데이터베이스(Vector Database) 구축) (2) | 2024.12.09 |
|---|---|
| vLLM OpenAI API 서버와 랭체인(LangChain) 연동하여 RAG 구축하기 (1) | 2024.11.02 |
| vLLM을 OpenAI API server(OpenAI-Compatible Server)로 배포하는 방법 및 예제(example) (3) | 2024.10.26 |
| vLLM 사용법 - LLM을 쉽고 빠르게 추론(inference) 및 API 서빙(serving)하기 (4) | 2024.05.06 |
| 논문 리뷰 - What Should Data Science Education Do with Large Language Models? (3) | 2024.04.02 |



