
포스팅 개요
이번 포스팅은 지난 글(kubeflow pipeline iris data)에 이어 kubeflow 예제(kubeflow example)에 대해서 작성합니다. 지난 글은 kubeflow 설치하는 방법과 kubeflow를 간단하게 사용할 수 있는 방법에 대해서 알아보았는데요. 이번 포스팅은 kubeflow 예제를 타이타닉(titanic data)데이터와 함께 예제를 작성합니다. 특히, AWS 서비스들과 연동하여 머신러닝 파이프라인(machine learning pipeline)을 구축해 보려고 합니다.
지난 포스팅은 아래 링크이므로 혹시 kubeflow가 설치되어 있지 않거나, 간단한 kubeflow 예제를 보고 싶으신 분들은 참조하시길 바랍니다.
- kubeflow 설치 : https://lsjsj92.tistory.com/580
- kubeflow example with iris data : https://lsjsj92.tistory.com/581
kubeflow 설치하기 - Machine Learning pipeline kubeflow install
포스팅 개요 이번 포스팅은 지난 글인 머신러닝 파이프라인이란?(Machine Learning pipeline) 글에 이어서 머신러닝 파이프라인인 kubeflow를 설치(kubeflow install)하는 방법에 대해서 작성합니다. 지난 글 ��
lsjsj92.tistory.com
kubeflow pipeline 사용해보기 - kubeflow pipeline example with iris data
포스팅 개요 이번 포스팅은 kubeflow 예제(kubeflow example)에 대해서 작성합니다. 지난 포스팅에서 kubeflow 설치하는 방법에 대해서 알아보았는데요. kubeflow 설치 후 kubeflow pipeline을 이용해서 kubeflow..
lsjsj92.tistory.com
또한, 해당 글에서 작성하는 kubeflow pipeline example은 kaggle에 올라와 있는 타이타닉(titanic) 데이터를 활용합니다. kaggle 등에서 쉽게 제공 받을 수 있으니 참고 바랍니다. 본 글에서 사용하는 코드 및 관련 파일들은 아래 github repo에 올려두었습니다. 참고하시면 되겠습니다.
https://github.com/lsjsj92/kubeflow_example
lsjsj92/kubeflow_example
kubeflow example. Contribute to lsjsj92/kubeflow_example development by creating an account on GitHub.
github.com
포스팅 본문
이제 kubeflow를 활용해 titanic 데이터에서 타이타닉 탑승객들이 생존 할 지, 생존을 못 할지 예측하는 머신러닝 모델을 만들어보려고 합니다. 특히, 이번 포스팅에서 다루는 kubeflow 예제는 AWS 서비스(AWS s3 등)와 연동하여 사용하는 것에 초점을 맞추어서 진행합니다.
전체 구조
본격적인 본문에 들어가기에 앞서서, 해당 포스팅에서 다루는 kubeflow 예제의 전체 구조를 살펴보고 가겠습니다. 전체 구조는 아래 사진과 같습니다.

아마, 지난 포스팅을 읽어보신 분들은 쉽게 이해가 가실 것 같은데요. 포스팅을 읽지 않으시고 바로 이것부터 보러 오신 분들도 있을 수 있기 때문에 다시 간단하게 설명하고 넘어가려고 합니다.
- 현재 저의 kubeflow example에서는 2개의 디렉토리와 각 디렉토리에 2개의 파일이 존재합니다. 그리고 pipelines.py 파일이 있습니다 .
- 디렉토리 : preprocessing, train_model : kubeflow의 각 단계에 해당되는 디렉토리 입니다.
- 디렉토리에 있는 파일 ~.py : kubeflow each step에 해당되는 동작 코드입니다. 파이썬으로 동작합니다.
- 디렉토리에 있는 파일 Dockerfile : kubeflow는 kubernetes 환경에서 동작합니다. 그렇기 때문에 docker container를 기반으로 동작이 됩니다. 그에 필요한 docker image를 만들어주는 파일입니다.
- pipelines.py : kubeflow에서 사용할 pipeline을 구축할 코드입니다. 파이썬(Python) 기반으로 되어 있습니다.
- 디렉토리 : preprocessing, train_model : kubeflow의 각 단계에 해당되는 디렉토리 입니다.
kubeflow 각 단계(step)에 대한 설명
이제 세부적으로 각 kubeflow step에 대해서 설명하겠습니다. 먼저, 전처리를 해야하죠? 그래서 preprocessing 단계에 대해서 설명하겠습니다.
1. preprocessing : AWS s3에서 데이터를 가져오고 데이터 전처리 후 다시 AWS S3에 저장
preprocessing 단계에서는 말 그대로 전처리 작업을 진행합니다. 위에서도 말씀드렸듯이 여기서는 kaggle의 타이타닉 데이터(titanic)를 활용합니다. 하지만, 이전 포스팅에서는 단순히 local에 데이터를 저장하고 이를 공유하는 방식을 사용했었는데요. 이번에는 이 타이타닉 데이터가 AWS S3에 저장되어 있다고 가정하고 진행합니다. 보통 실무에서는 이렇게 어떤 저장소에 데이터를 올려놓고 활용하지 local에 데이터를 저장하는 방법을 잘 사용하지 않습니다. 그렇기에 그런 방법적인 것을 정리하고자 합니다.
먼저 AWS S3에서 데이터를 가져오려면 아래와 같이 준비해야 합니다.
- python의 boto3 패키지를 활용
- AWS S3 bucket name 입력
- AWS ACCESS KEY 입력
- AWS SECRET KEY 입력
- AWS region 입력
- AWS S3 KEY 입력
따라서, 전처리 단계에서는 해당 정보를 입력 받을 수 있도록 argument를 준비해둡니다.

뭔가 굉장히 많지만, 전부 AWS S3를 활용하기 위한 argument입니다. 특히, 아래에 data_key와 save_key 2개로 key가 나뉘어 지는데요. 그것에 대한 설명은 아래와 같습니다.
- data_key : 타이타닉 데이터가 저장되어 있는 s3 key
- save_key : 전처리 후 타이타닉 데이터를 저장할 s3 key
그리고 나서 이제 titanice kubeflow example의 preprocessing 단계에서의 코드가 시작이 되는데요. 그 코드는 아래와 같습니다.

코드는 정말 단순합니다. (여기서는 일부러 전처리를 단순하게 처리했습니다. 전처리가 목적이 아닌, kubeflow example이 목적이니까요)
- get_data : AWS S3에서 데이터를 받아옵니다.
- upload_data : 전처리 후 데이터를 AWS S3에 저장합니다. 이 파일은 추후 machine learning model training 단계에서 사용합니다.
- preprocessing : 전처리 코드입니다. 여기서는 굉장히 단순하게 처리했습니다. 목적이 kubeflow example 설명이기 때문입니다. 만약, 더 활용하고 싶으시면 여기에서 전처리 코드를 더 추가하시면 됩니다.
이제 해당 파일을 kubeflow에서 사용할 수 있도록 Dockerfile을 만들어주면 됩니다. Dockerfile 내용은 아래와 같습니다.

이미 Python 기반의 machine learning 환경이 만들어진 alpine-python-machinelearning 이미지를 기본으로 사용합니다. 하지만, 저 docker 환경에는 boto3가 설치되어 있지 않기 때문에 dockerfile을 만들 때 해당 환경에 boto3를 설치하도록 합니다. 혹은, 더 필요한 환경이 있다고 하면 requirements.txt를 넣어줘서 RUN pip install -r requirements.txt를 실행하도록 넣어주시면 됩니다.
2. 전처리 된 titanic data를 가져와서 machine learning model training 하기
이번 kubeflow 예제의 다음 step은 전처리 된 데이터를 가져와서 machine learning model을 만드는 것입니다. 코드는 아래와 같습니다.
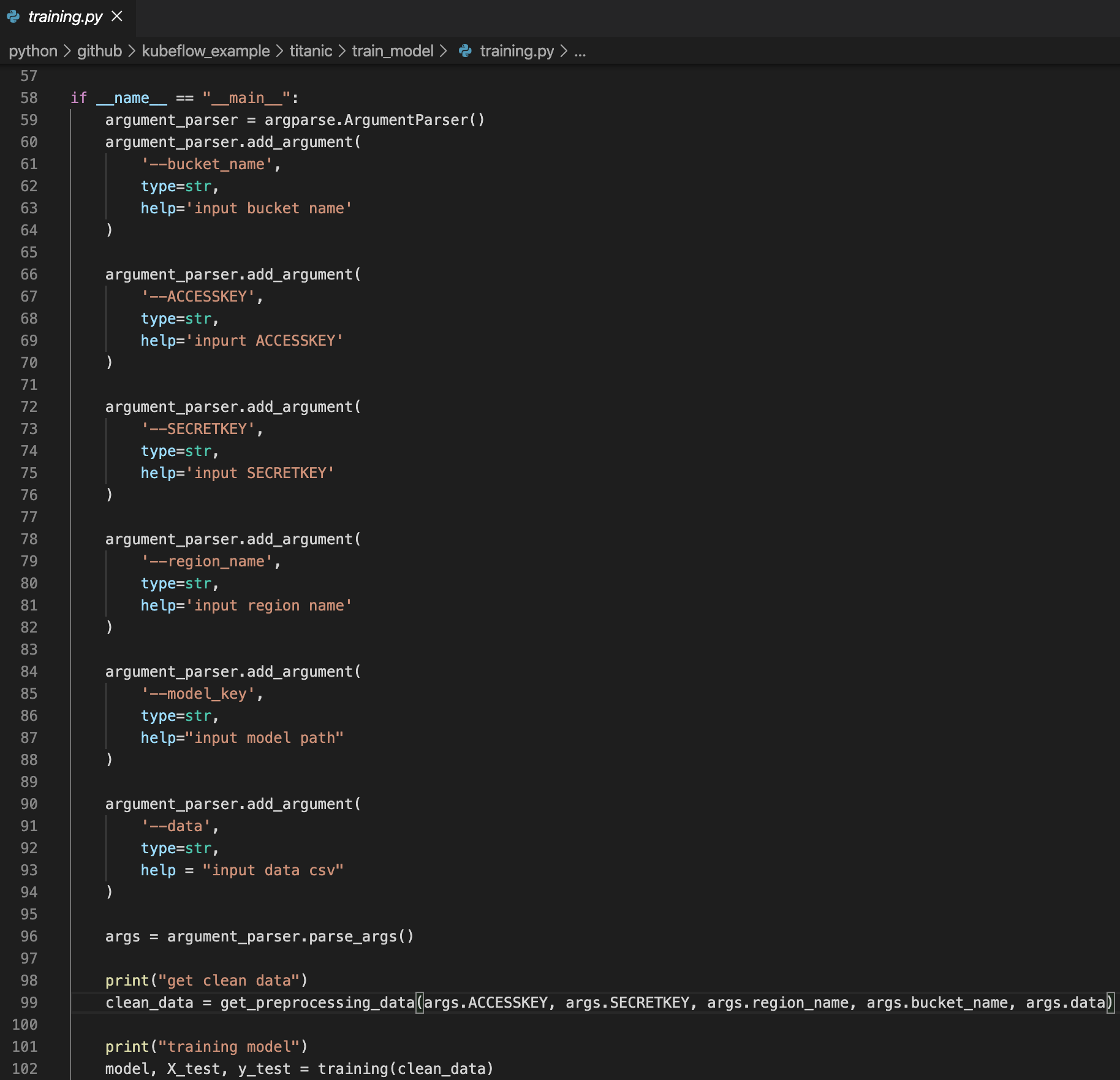
여기서도 preprocessing step과 동일하게 AWS 정보를 필요로 합니다. 단, preprocessing 때와 동일한 argument 이름을 가지고 받도록 하면 kubeflow 실행 시 한 번만 정보를 입력 받으면 되므로 argument 이름을 똑같이 해주면 편합니다.
여기서는 다음과 같은 순서로 진행합니다.
- preprocessing 된 데이터를 받아온다.
- machine learning model을 training
- model evaluation(모델 평가)
- S3에 machine learning model 업로드
각 단계에 대한 코드는 아래와 같습니다.

여기서도 굉장히 간단하게 동작되도록 코드를 작성했습니다. 각 단계는 아래와 같습니다.
- get_preprocessing_data : 전처리 된 데이터를 가져옵니다. 전처리 된 데이터를 받아올 때는 AWS S3에 대한 정보가 필요합니다. 해당 정보를 이용해서 preprocessing 단계에서 전처리된 데이터를 가지고 옵니다.
- training : 해당 데이터를 활용해서 machine learning model을 훈련 시켜줍니다. 여기서는 굉장히 간단하게 진행했습니다. preprocessing 때와 마찬가지로 kubeflow example 설명을 위한 목적이지, model 고도화의 목적이 아니기 때문입니다. 만약, 더 고도화 된 model을 만들고 싶으시면 training 함수를 더 멋지게 만들어주시면 됩니다.
- upload_model_to_s3 : 잘 훈련된 model을 AWS S3에 올려줍니다. 결국, 이 model을 활용하는 것이 목적이기 때문에 model을 다른 곳에서 활용할 수 있도록 S3에 올려줍니다.
마찬가지로 여기서도 kubeflow 환경에서 동작할 수 있도록 docker image를 만들어주어야 합니다. 그래서 Dockerfile 내용을 아래와 같이 채워줍니다.

첫 번째 step인 preprocessing과 별 차이점이 없기 때문에 설명은 넘어가겠습니다.
kubeflow에서 사용할 수 있도록 docker image 생성
자! 이제 준비가 거의 끝났습니다. 이제 kubeflow에서 사용할 수 있도록 docker image를 생성해 주어야 합니다. 그리고 이 docker image를 hub에 배포해서 사용할 수 있도록 만들어둡니다.
Dockerfile이 있는 경로에 들어가서 아래와 같은 명령어를 입력해주면 됩니다.
- 예시
- docker build -t soojin-titanic-preprocessing .
- docker build -t soojin-titanic-training .
맨 마지막에 . 는 오타가 아닙니다! 꼭 같이 입력해주세요. 이렇게 진행하시면 docker image가 만들어질 것입니다. 이제 이 docker image를 사용할 수 있도록 docker hub에 배포합니다.
배포하는 과정은 지난 kubeflow iris example 때와 동일합니다. docker image 이름 등만 다르고 전부 동일 하기 때문에 글의 서두에 올려두었던 해당 글을 참조해주시면 감사하겠습니다.
kubeflow 사용을 위한 pipeline 코드 작성
이제 kubeflow에 활용되는 각 step 따른 코드와 각 step의 정보를 담은 docker image를 전부 생성했습니다. 이제 kubeflow에서 위에 정보를 활용해서 동작될 수 있도록 pipeline 코드를 작성합니다.
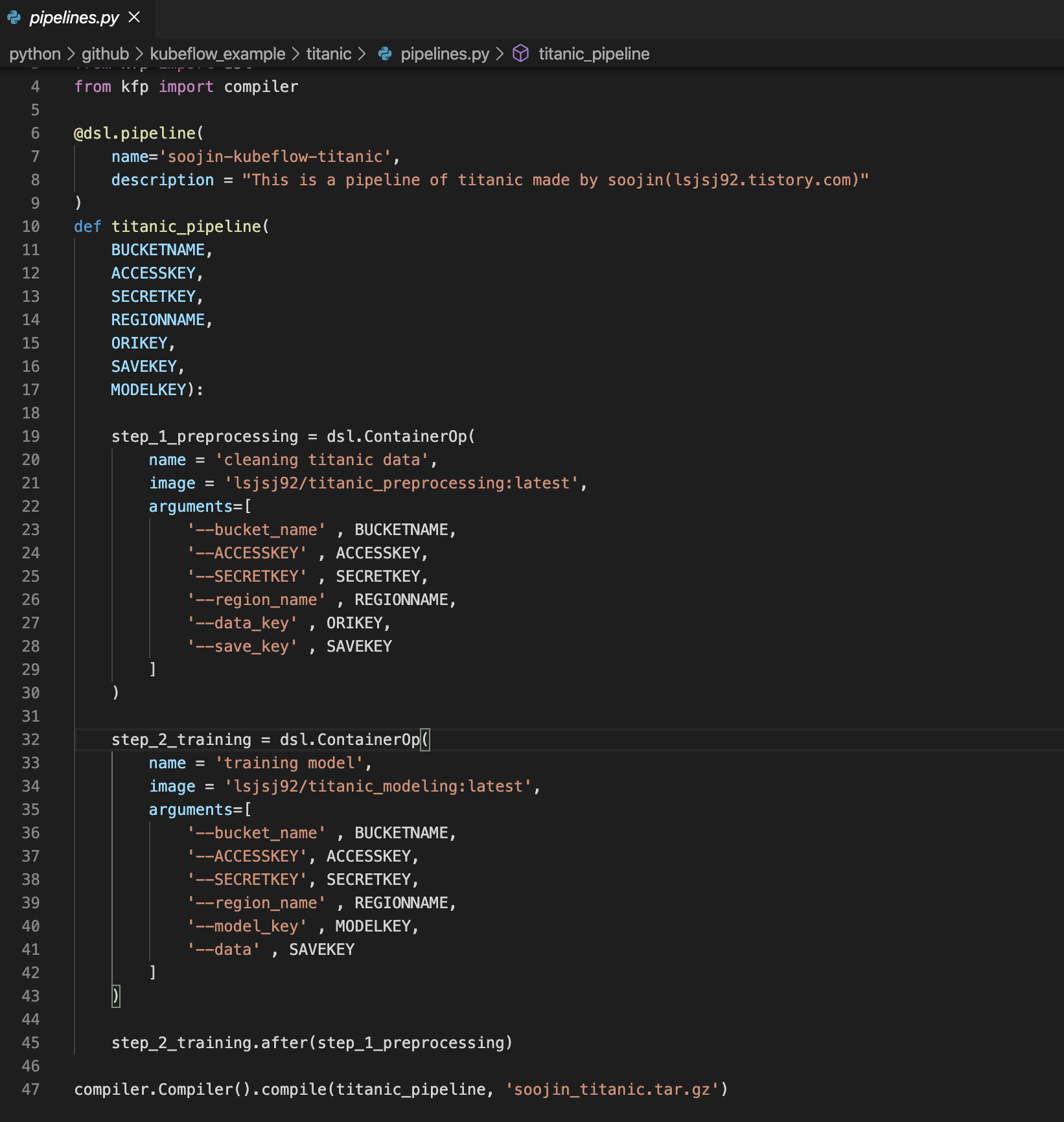
pipeline 코드는 위와 같습니다. 여기서 눈 여겨 보셔야 할 것이 AWS에 대한 정보인데요. 아까 training 단계에서 preprocessing 단계에서의 argument를 동일하게 입력하면 AWS 정보를 한 번만 입력해도 된다고 말씀드렸습니다. 여기서 보시면 step_1과 step_2로 나뉘어 지는데 arugment 부분이 있습니다. 이때 받는 인자가 전부 동일함을 알 수 있습니다.
- step 1 : preprocessing
- preprocessing 단계에서 올려둔 docker image를 활용
- AWS S3를 활용하기 위한 BUCKET NAME, ACCESS KEY, SECRET KEY, region name, data key, save key를 설정
- step 2 : training
- preprocessing이 끝난 이후에 동작 (step_2_training.after(step_1_preprocessing))
- 여기서 data를 입력 받는데, preprocessing 단계에서 사용한 save key를 활용하면 됌
- 결국, 전처리가 끝난 데이터를 활용하기 때문!
이렇게 pipeline.py가 구성되었으면 이제 아래와 같은 명령어로 tar.gz 파일로 만들어줍니다.
- dsl-compile --py pipeline.py --output soojin-titanic-pipeline.tar.gz
dsl-compile --py 파이프라인코드이름.py --output 파이프라인이름.tar.gz
그러면, 이제 kubeflow에서 사용할 수 있는 pipeline.tar.gz가 만들어지게 됩니다!
자! 이제 모든 준비는 끝났습니다. 이제 pipeline을 동작시키면 됩니다.
kubeflow example 실행시키기 - training machine learning model with titanic data
이전 글에서 kubeflow를 잘 설치하셨다면 kubeflow 환경에 접속하시면 됩니다. 그러면 웹 환경을 볼 수 있는데요. 거기서 pipelines를 클릭하신 다음 upload pipeline에 들어가서 위에 만들었던 tar.gz를 올려줍니다. 그러면 새로운 pipeline이 잘 올라가는데요! 이제 여기서 create experiment를 클릭하셔서 실험 화면에 들어갑니다. 그러면 아래와 같은 화면이 나오고, 아까 우리가 지정했던 argument 값들을 채워주시면 되겠습니다.
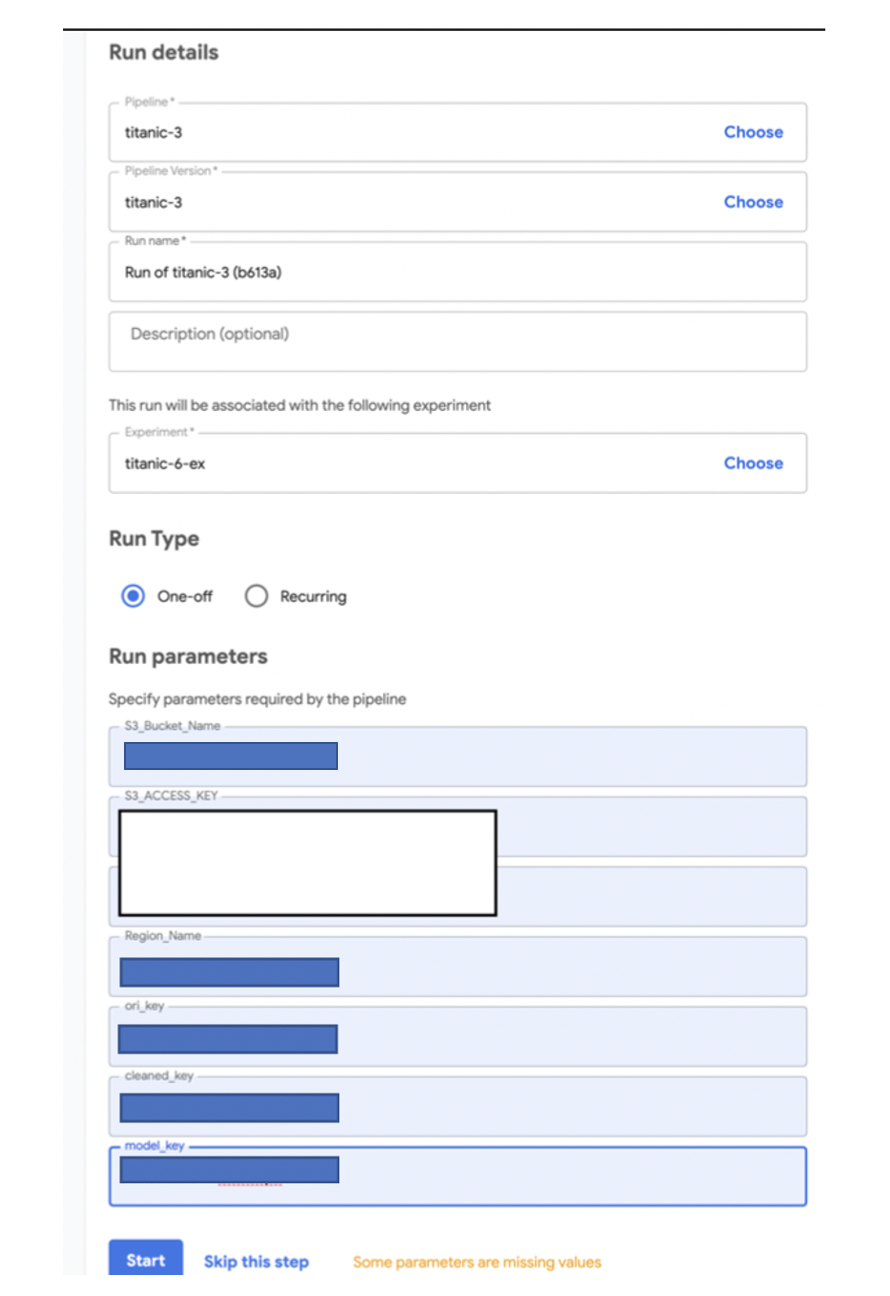
이렇게 argument 값들을 각각 잘 채워주고 start를 클릭하시면!

위와 같이 잘 실행되고 결과도 잘 나오는 것을 확인할 수 있습니다.
맺음말
사실, 이 글은 kubeflow iris example 예제를 올려둔 다음 바로 올리려고 했으나, 여러가지 일이 좀 있어 많이 늦어진 글입니다. 후속 글을 기다리셨던 분들께는 죄송한 마음입니다.
다음에는 kubeflow에서 model metric을 확인할 수 있는 방법에 대해서 작성할 것 같습니다. 그리고 metric에 따라서 model을 저장할 수 있도록 하는 방법도 작성할 것입니다.
다음글 : https://lsjsj92.tistory.com/589?category=891065
kubeflow pipeline 예제(example) - pipeline metrics 출력과 condition 체크하기
포스팅 개요 이번 포스팅은 kubeflow 예제(kubeflow example)를 주제로 다룹니다. 지난 포스팅에 이어서 이번에는 kubeflow에서 실행시킨 machine learning 혹은 deep learning 모델에서 나온 metrics를 ( evaluat..
lsjsj92.tistory.com
감사합니다.
'Data Engineering 및 Infra' 카테고리의 다른 글
| kubeflow pipeline cron job(batch) 설정하기 - kubeflow recurring job(scheduled workflows) (0) | 2020.07.22 |
|---|---|
| kubeflow pipeline 예제(example) - pipeline metrics 출력과 condition 체크하기 (8) | 2020.06.11 |
| 사용자 정의 kubernetes helm 생성 및 배포하기 - django helm으로 배포하기 (2) | 2020.04.19 |
| kubernetes helm 이란? - helm 사용법(kubernetes 배포/관리하기) (0) | 2020.04.15 |
| kubeflow pipeline 사용해보기 - kubeflow pipeline example with iris data (22) | 2020.04.07 |



