
머신러닝에서는 앙상블(ensemble)을 정말 많이 사용합니다.
그 효과가 매우매우 강력하기 때문인데요.
이 앙상블에는 배깅(bagging), 부스팅(boosting) 등의 종류가 나뉘어져 있습니다.
지난 포스팅 때는 ensemble bagging에 대해서 설명했었고 random forest에 대해서도 설명했습니다.
https://lsjsj92.tistory.com/542
머신러닝 bagging 앙상블 랜덤 포레스트(random forest)란?
머신러닝 앙상블에는 배깅(bagging), 보팅(voting), 부스팅(boosting)이 있습니다. 그 중 앙상블 bagging에 속한 랜덤 포레스트를 이번 포스팅에서 소개할까합니다. 이 random forest는 빠른 속도와 높은 예측 성..
lsjsj92.tistory.com
이번 포스팅은 ensemble 중의 boosting에 대해서 알아봅니다.
머신러닝 앙상블 부스팅이란? - ensemble boosting
먼저 앙상블 부스팅에 대해서 알아야겠죠?
배깅 같은 경우는 여러 개의 단일 모델을 만들고 booststrap 과정으로 데이터를 랜덤으로 추출한 뒤 모델을 훈련시켰습니다. 그리고 그 모델에 대해서 최종적으로 voting 과정을 통해 데이터를 예측했습니다.
하지만 부스팅은 조금 이야기가 다릅니다.
앙상블 부스팅은 앞에서 예측한 분류기가 틀린 부분에 있어 가중치를 부여합니다.
가중치를 부여해서 틀린 부분을 더 잘 맞출 수 있도록 하는 것입니다.
부스팅(boosting)은 bagging과 유사하기 초기 샘플 데이터를 뽑아내고 다수의 분류기를 생성한다는 것에서 상당히 비슷합니다. 하지만, 훈련 과정에서 앞 모델이 틀렸던 부분을 가중치를 부여하며 진행한다는 것이 다르죠
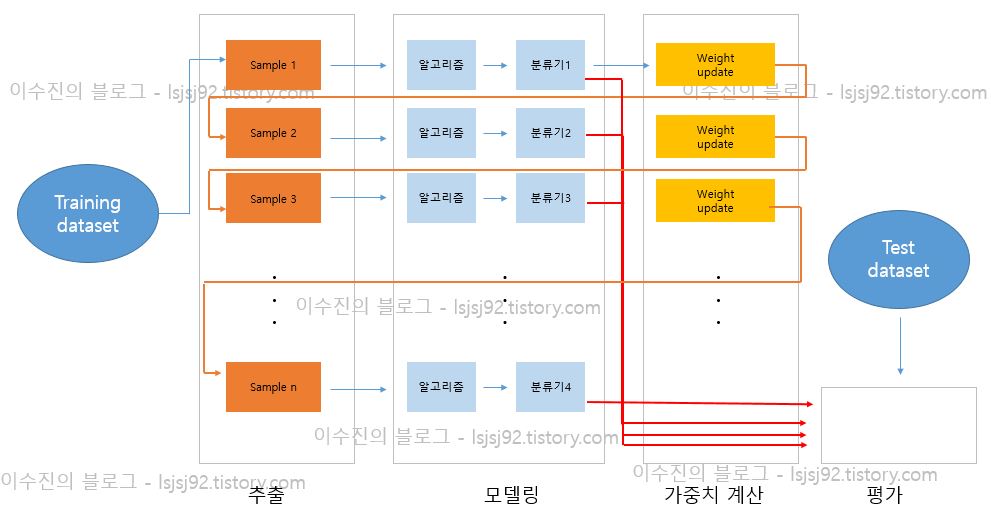
이러한 부스팅은 약검출기(week classifier)들을 여러 개 모아 강검출기(strong classifier)를 생성하는 방법입니다.
즉, 다음 단계의 week classifier는 이전 단계의 weak classifier의 영향을 받게 되고 이전의 양상을 본 뒤 잘 맞출 수 있는 방향으로 다음 단계를 진행하며 weight 등을 업데이트 합니다.
그래서 최종적으로 strong classifier를 생성하게 되는 것이죠
앙상블 배깅(bagging)과 부스팅(boosting)의 비교
일반적인 bagging은 일반적인 모델을 만드는데 집중되어 있다면, boosting은 맞추기 어려운 문제를 맞추려고 노력을 합니다.

그리고 위 그림은 배깅과 부스팅의 차이점을 명확하게 보여주고 있습니다.
다음 포스팅에서 기본적인 부스팅 방법인 Adaboost와 Gradient Boosting에 대해서 작성합니다.
'인공지능(AI) > machine learning(머신러닝)' 카테고리의 다른 글
| 윈도우10에 xgboost 설치하기 - ensemble xgboost install (4) | 2019.11.18 |
|---|---|
| 머신러닝, 딥러닝에서 데이터를 나누는 이유 - X_train, X_test, y_train, y_test이란? (32) | 2019.11.17 |
| 머신러닝 앙상블 부스팅(boosting) - Adaboost, Gradient Boosting (2) | 2019.11.16 |
| 머신러닝 bagging 앙상블 랜덤 포레스트(random forest)란? (2) | 2019.11.15 |
| 머신러닝 프로젝트는 어떻게 관리할까? - ML 프로젝트 관리 방법에 대해서 (2) | 2019.10.16 |



