RoBERTa 논문 정리(논문 리뷰) - A Robustly Optimized BERT Pretraining Approach (RoBERTa)
포스팅 개요
이번 포스팅은 자연어처리(NLP) 논문 중 A Robustly Optimized BERT Pretraining Approach라는 논문을 리뷰하는 포스팅입니다. 해당 자연어처리 논문은 흔히 RoBERTa라고 많이 언급되는 논문인데요. 앞서 GPT-1, GPT-2, BERT 논문 리뷰에 이어서 자연어처리 논문 시리즈 네 번째 포스팅입니다.
추가로 해당 포스팅의 내용은 제가 진행하는 사내 자연어 처리 스터디에서 발표한 자료를 블로그로 정리한 자료임을 알려드립니다.
자연어 처리 논문 리뷰는 아래와 같은 순서로 할 예정이며 이번 포스팅은 그 네 번째 RoBERTa 논문입니다. (순서는 바뀔 수 있습니다.)
- GPT-1 (https://lsjsj92.tistory.com/617)
- BERT (https://lsjsj92.tistory.com/618)
- GPT-2 (https://lsjsj92.tistory.com/620)
- RoBERTa ( 이번 포스팅 )
- ALBERT ( https://lsjsj92.tistory.com/628 )
- ELECTRA ( https://lsjsj92.tistory.com/629 )
참고한 자료는 아래와 같습니다.
- RoBERTa 논문

포스팅 본문
RoBERTa 논문 리뷰는 아래와 같은 순서로 진행합니다.
1. RoBERTa 핵심 요약
2. 논문 리뷰
RoBERTa 핵심 요약
RoBERTA는 BERT의 replication study
• 아직 BERT는 under fit 되어 있음
• 이전에 간과된 설계의 중요성을 강조함
• 여러가지 tuning을 진행
• Training the model longer with bigger batch, over more data
• NSP loss 제거
• Longer sequence를 넣어줌
• Dynamic Masking 적용
결과
• 기존 BERT 보다 더 우월한 성능을 보임
• BERT 이후에 나온 후속 모델(XLNet 등) 보다도 더 좋은 성능을 보여줌
• 이전에 간과되었던 설계의 중요성 대두
RoBERTa는 위처럼 핵심을 요약할 수 있습니다.
RoBERTa 논문 리뷰 및 요약
이제 RoBERTa 논문을 리뷰해봅니다.
Abstract

• BERT가 상당히 undertrained된 것을 발견함
• BERT로도 BERT이후에 나온 모델들을 이길 수 있음
• 실제로 SOTA를 GLUE, RACE, SQuAD 등에서 달성함
• 이 결과는 설계의 중요성을 강조함
Introduction

BERT의 복제 연구를 진행함
• Careful evaluation을 포함
• Hyperparameter tuning, training set size
• RoBERTa 모델을 제안
• BERT는 undertrained되어 있음
• BERT 모델을 개선하기 위한 recipe 제안
Simple modifications
1. Training the model longer with bigger batches
2. removing the NSP(next sentence prediction) objective
3. Training on longer sequences
4. Dynamically changing the masking pattern
5. Collect a large new dataset
Task 성능
• SQuAD, RACE, GLUE( 4/9 ) SOTA 달성
• BERT model이 경쟁력을 가지고 있음을 확인
• 최근에 제안된 다른 모델과 함께
본 논문의 기여
• BERT의 design choice과 training 전략 등의 중요성을 보여줌
• 새로운 dataset 사용
• Masked Language Model pretraining이 올바른 설계를 가정하고 경쟁력이 있다는 것을 보여줌
BERT에 대한 설명
BERT에 대한 설명은 이전 제 포스팅을 참고해주세요! 여기서는 간단하게만 리뷰하고 넘어가겠습니다.(https://lsjsj92.tistory.com/618)
• Masked Language Model(MLM)
• Original에서는 초기에 한번 시행되고 저장
• Next Sentence Prediction(NSP)
• Positive : 연속된 문장
• Negative : 다른 문서의 segment
Experimental Setup
Hyperparameter
• 기본적으로 BERT를 따름
• Adam epsilon term이 민감한 것을 발견해서 바꾸는 등 약간의 설정을 조금씩 바꿈
• Sequence를 512로 맞춤
• Data
• 더 많은 데이터 수집
• 160GB 데이터 수집
• BOOKCORPUS + English WIKIPEDIA
• CC-News
• CommonCrawl News dataset
• OpenWebText
• Open source recreation of the WebText
• STORIES
Training Procedure Analysis
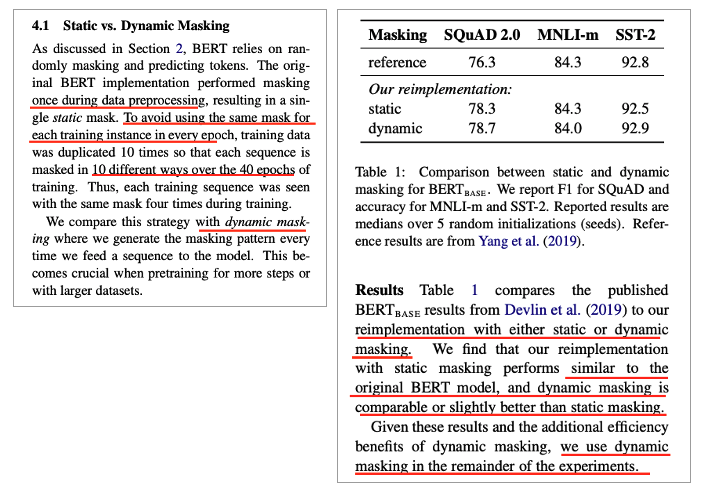
Static vs Dynamic Masking
• Original BERT는 mask를 한 번만 하고 고정 (static mask)
• Each training instance in every epoch에서 same mask를 avoid
• Training data를 10배로 복사 ( 10개의 다른 mask 적용 )
• 40 epochs
• 즉, 똑같은 것을 4번만 봄
• Dynamic Masking
• Dynamic Masking의 성능
• 기존과 비슷하거나 조금 더 좋음
• 이후 실험도 이걸로 진행


Input format & Next Sentence Prediction(NSP)
• 최근 연구에서 NSP loss에 대한 의문이 제기되고 있음
• Input format setting
• SEGMENT-PAIR + NSP
• BERT와 동일한 구조
• SENTENCE-PAIR + NSP
• 하나의 Document 또는 분리된 Document에서 하나의 문장으로
• 기존 BERT는 natural sentence인 반면 이것은 진짜 문장을 말하는 것 같음
• 512 token보다 훨씬 작음
• FULL-SENTENCE
• 연속된 문장
• Document가 경계를 넘을 수 있음
• 경계를 넘을 경우 구분 토큰을 넣어 줌
• Most 512 token
• DOC-SENTENCES
• FULL-SENTECE와 기본적으로 동일
• 하나의 문서가 끝나면 다음 문서로 넘어가지 않음
• Shorter than 512 token -> dynamically increase batch size
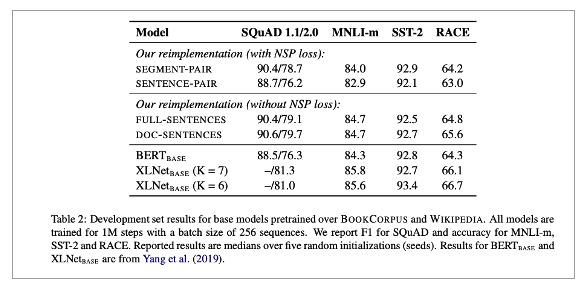
Input format & Next Sentence Prediction(NSP)
• 1, 2번 중에서는 1번이 좋음
• 2번은 long range 의존성을 학습할 수 없기 때문
• NSP를 제거하니까 더 좋은 성능
• 특히, 3번과 4번 중 4번이 더 좋음
• 그러나, 4번은 Dynamic이 들어가기 때문에 3번으로 진행
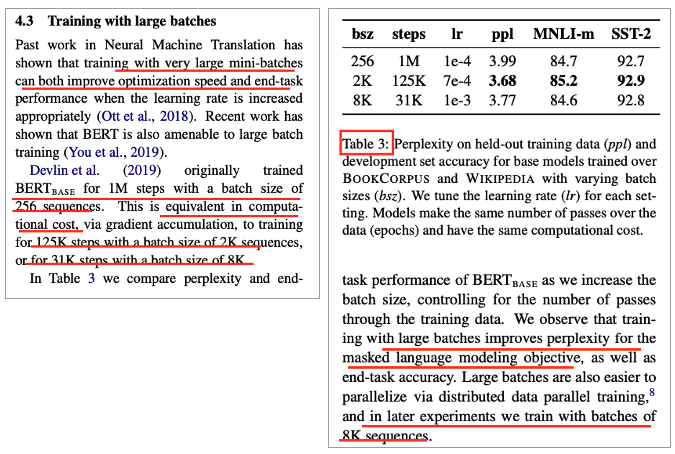
Training with large batches
• Large mini-batches의 장점
• Optimization speed
• end-task performance 향상
• Equivalent computational cost
• 125K step with a batch size of 2K sequence
• 31K step with a batch size of 8K
• BERT base
• 1M step batch size of 256 sequence
• 더 큰 Batch size가 좋은 성능을 보여줌
• 이후 실험은 8K로
Text Encoding
• Byte-Pair Encoding (BPE) 사용
• 기존 BERT는 전처리 하고 BPE
• Character-level BPE 사용
• GPT-2와 동일하게 진행
• 전처리도 진행하지 않음
• Byte-level로 진행
• 몇 task에서 안 좋은 성능
• 그럼에도 범용 인코딩 체계 장점 기대
RoBERTa 소개

RoBERTa는!
• Robustly optimized BERT approach에서 RoBERTa
• 아래와 같은 것들을 적용
• Dynamic Masking
• FULL SENTECE without NSP
• Large mini-batches
• Larger byte-level BPE
• 이전 연구에서 강조되지 않은 두가지 중요 요소도 조사
• Pretraining에 사용된 data
• Data로 훈련하는 횟수
• 예를 들어 XLNet
• Original보다 10배 큰 데이터
• 8배 큰 batch size
• BERT보다 4배 더 많은 시퀀스를 볼 수 있음
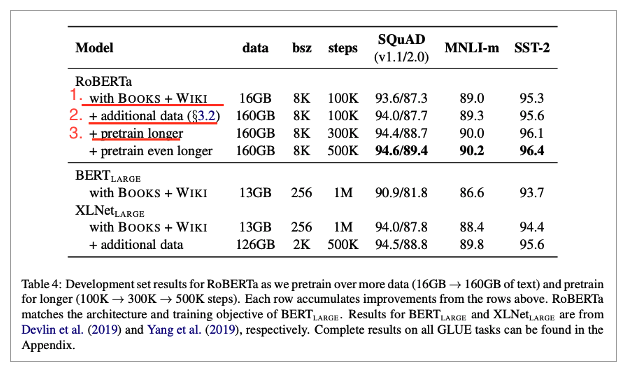
비교
1. BERT large아키텍처와 동일하게 구성
• Dataset도 똑같이 구성
• Importance of the design choices를 확인할 수 있었음
2. 3개의 dataset 추가
• Training step은 1번과 동일
• 성능 향상을 보임
• Data size와 diversity의 중요성을 확인할 수 있었음
3. Training step 증가
• XLNet보다 더 좋은 성능을 보여줌
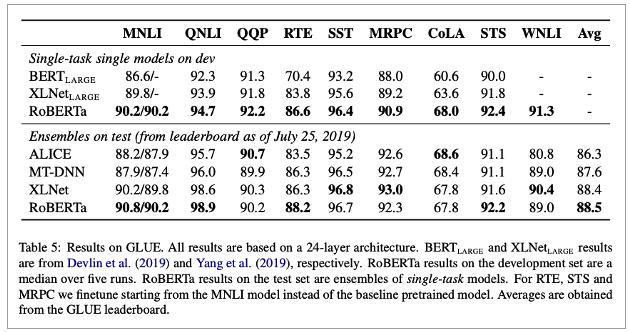
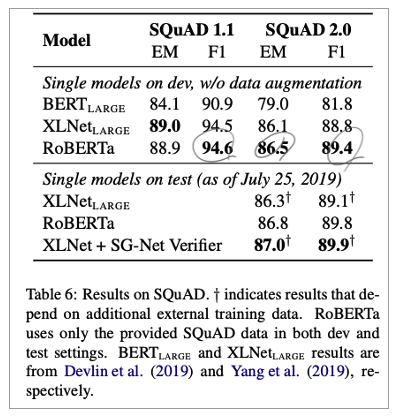
Result
• GLUE
• 2개의 셋팅
• 1. single-task, dev
• Fintune separately for each of the GLUE task
• Using only the training data for the corresponding task
• 전부 SOTA 달성
• 2. ensembles, test
• GLUE leaderboard는 multi task finetuning에 의존
• 그러나 RoBERTa는 single-task finetuning만 진행함
• 9개 중 4개에서 SOTA
• SQuAD
• BERT와 XLNET은 augment their training data with additional QA dataset
• 그러나 RoBERTa에서는 provided SQuAD training data로만 finetune
• V2.0
• BERT와 XLNet은 외부 추가 data에 의존함
• RoBERTa는 이러한 additional data를 사용하지 않음
• SOTA 달성
•RACE
• SOTA 달성
RoBERTa 결론
아래와 같은 것들로 BERT 성능을 향상 시킬 수 있었음
• Training the model longer with bigger batches over more data
• Removing next sentence prediction(NSP) objective
• Training on longer sequence
• Dynamically changing the masking pattern
SOTA를 달성
• Multi-task finetuning과 같은걸 하지 않아도 달성함
설계의 중요성
• 이전에 간과 되었던 부분을 보여줌
• BERT pretraining objective는 경쟁력을 유지하고 있음을 제안