
포스팅 개요
이번 포스팅은 대규모 언어 모델(Large Language Models, LLM)을 쉽고 빠르게 배포(deploy), 추론(inference) 및 서빙(serving)할 수 있는 vLLM 라이브러리에 대해서 알아봅니다. vLLM이란 무엇이고, vLLM을 사용해서 어떻게 LLM을 배포하고 실행하는지 예제(example) 형태로 정리합니다. 결과적으로 vLLM을 사용하면 빠른 속도로 LLM들을 API 형태로 서빙 및 배포할 수 있습니다.
이번 포스팅을 작성하면서 참고한 자료는 아래와 같습니다.
- https://docs.vllm.ai/en/latest/
- https://github.com/vllm-project/vllm?tab=readme-ov-file
- https://python.langchain.com/docs/integrations/document_loaders/web_base/
- https://huggingface.co/yanolja/EEVE-Korean-Instruct-10.8B-v1.0
- https://arxiv.org/pdf/2309.06180

포스팅 본문
포스팅 개요에서도 언급하였듯이, 이번 포스팅은 vLLM을 이용해 쉽고 빠르게 대규모 언어 모델(LLM)을 배포하고 서빙할 수 있는 과정을 예제(example) 형태로 정리합니다. 본 포스팅의 순서는 다음과 같습니다.
1. vLLM이란? vLLM이 무엇일까?
2. vLLM 사용법
2-1. vLLM 설치 방법
2-2. vLLM 실행 예제 - 간단한 방법
2-3. vLLM 실행 예제 - API 형태로 서빙 및 배포하기
2-4. vLLM 실행 예제 - 채팅 템플릿으로 chatbot 포멧 구성
2-5. vLLM 실행 예제 - 랭체인(LangChain)과 결합해 RAG 구성
1. vLLM이란?
공식 문서에 보면 vLLM에 대해서 다음과 같이 소개하고 있습니다.
vLLM is a fast and easy-to-user library for LLM inference and serving
즉, vLLM은 LLM 추론(inference) 및 서빙(serving)을 쉽고 빠르게 도와주는 라이브러리라는 것이죠. vLLM의 주요 특징을 정리하자면 다음과 같습니다.
- state-of-the-art serving throughput을 보여줌. 즉, 서빙 처리 속도가 좋음
- 페이지 어텐션(page attention) 방법으로 key, value 메모리를 효과적으로 관리
- 입력으로 들어오는 요청(request)에 대해서 지속적인 배치(Continuous batching) 처리 가능
- 양자화(Quantization) : GPTQ, AWQ, FP8 KV Cache 등
- 허깅페이스(huggingface)와의 원할한 통합으로 인기 있는 LLM 모델을 사용할 수 있음
- 분산 추론(distributed inference) 지원
등등 다양한 장점과 특징을 가지고 있는 라이브러리입니다. 이러한 vLLM을 사용한다면, LLM을 정말 빠르고 간단하게 추론 및 서빙할 수 있죠. vLLM은 논문도 나와있습니다. 주요 기법인 page attention 방법에 대해서 작성한 논문인데요. page attention 방법에 대해서 더 자세히 알고 싶으신 분들은 해당 논문을 참고하시면 되겠습니다. 포스팅 개요의 참고 자료에 arxiv 링크를 올려두었습니다.
이번 포스팅은 vLLM의 page attention 방법보다, 라이브러리를 사용해 LLM을 배포하는 과정에 대해서 집중하겠습니다.
2. vLLM 사용법(vLLM example)
이제 본격적으로 vLLM 사용 방법에 대해서 예제를 살펴보겠습니다. 설치 방법부터 API 형태로 LLM을 서빙하는 예제를 하나씩 살펴보겠습니다.
2-1. vLLM 설치 방법(vLLM install)
vLLM을 사용하는 방법은 간단합니다. 단순히 pip install로 설치하면 됩니다. 다만, 주의할 점이 있습니다. 바로 아래 사진과 같은 주의사항인데요.

글을 작성하고 있는 현재(24.5월 초) vLLM은 linux에서만 설치가 가능합니다. 즉, mac과 같은 OS에서는 지원을 해주지가 않습니다. 따라서 저도 리눅스 환경에서 vLLM을 배포했는데요. 만약 Mac에서 설치하려고 하면 다음과 같이 에러 메세지를 마주하게 됩니다.
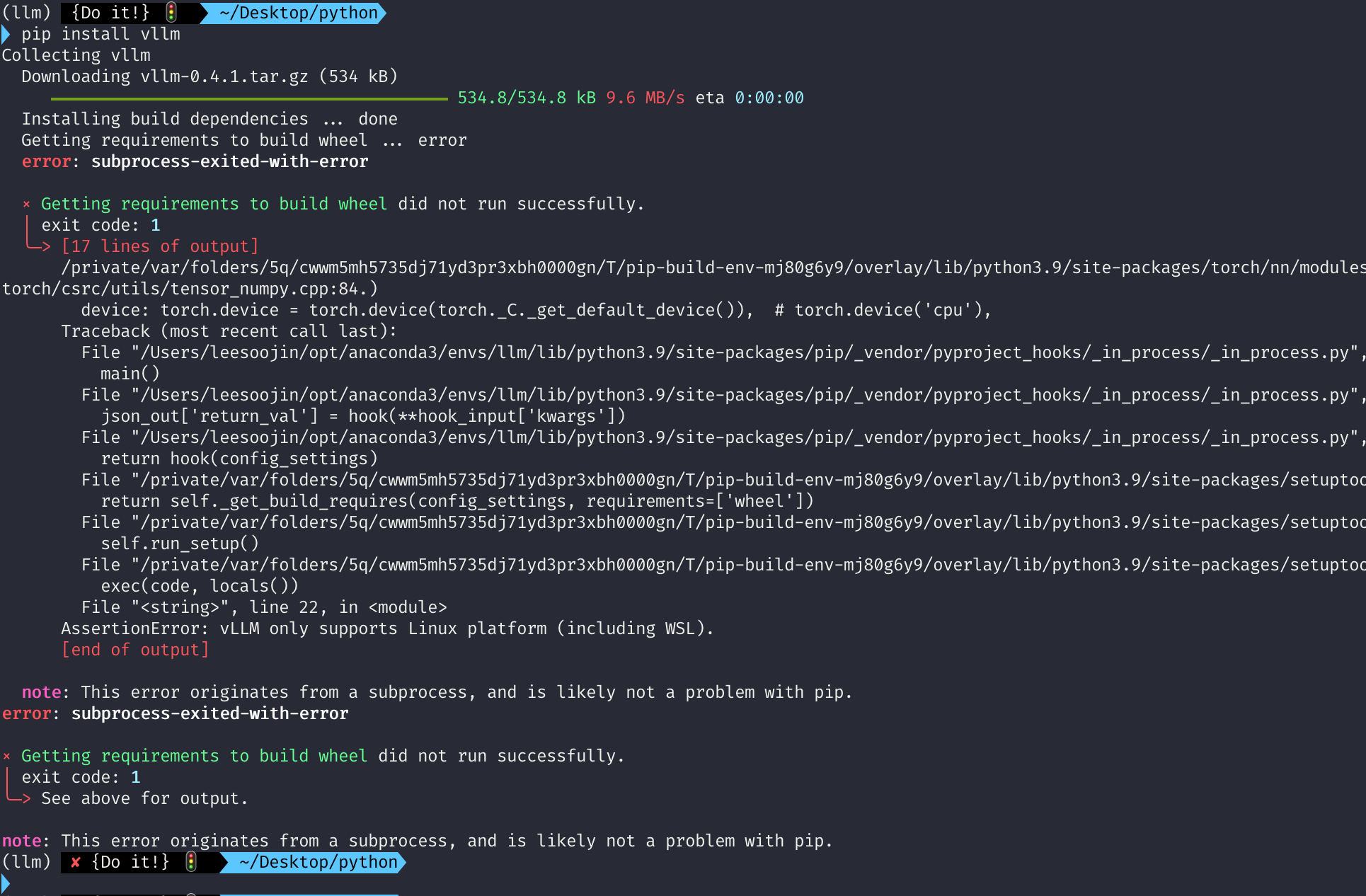
에러 메세지는 vLLM only supports Linux platform (including WSL)이라고 나오죠.
그렇기에 vLLM은 linux에서 설치하고 실행할 수 있다는 점 참고해주시면 좋을 것 같습니다. 글을 작성한 이후에 언젠가는 mac 등 에서도 가능하도록 지원해주지 않을까 기대하고 있습니다.
저는 ubuntu 20.04에서 vLLM을 설치한 후 진행했습니다.
2-2. vLLM 실행 예제 - 간단한 사용법
이제 본격적으로 vLLM을 사용해봅시다. 저는 vLLM을 활용해 huggingface 모델을 inference 및 서빙에 사용하려고 합니다. 제가 사용한 모델은 야놀자에서 제공해주신 EEVE instruct 10b 모델입니다. EEVE 모델은 뛰어난 한국어 성능을 가지고 있는 모델인데요. 이런 훌륭한 모델을 연구하고 올려주신 야놀차 측에 감사한 말씀드립니다.
저는 허깅페이스에서 EEVE-Korean-Insstruct-10.8b-v1.0 모델을 제 ubuntu 환경 로컬에 다운로드 받아놨습니다. 제가 다운로드 받은 경로는 /home/lsjsj92/models 입니다. 이 경로는 여러분들이 원하시는 경로로 바꾸시면 됩니다.
간단한 사용법을 먼저 살펴보겠습니다. 여기서 간단하게 vLLM을 사용하는 것은 API 형태로 serving 하는 것이 아니라, python 환경에서 vLLM을 사용해 LLM 모델을 로드하고 사용하는 방법입니다.
vLLM으로 모델을 불러오는 것은 아래와 같은 코드 1줄이면 됩니다.
from vllm import LLM
llm = LLM(model="/home/lsjsj92/models/EEVE-Korean-Instruct-10.8B-v1.0", max_model_len=2048, tensor_parallel_size=2)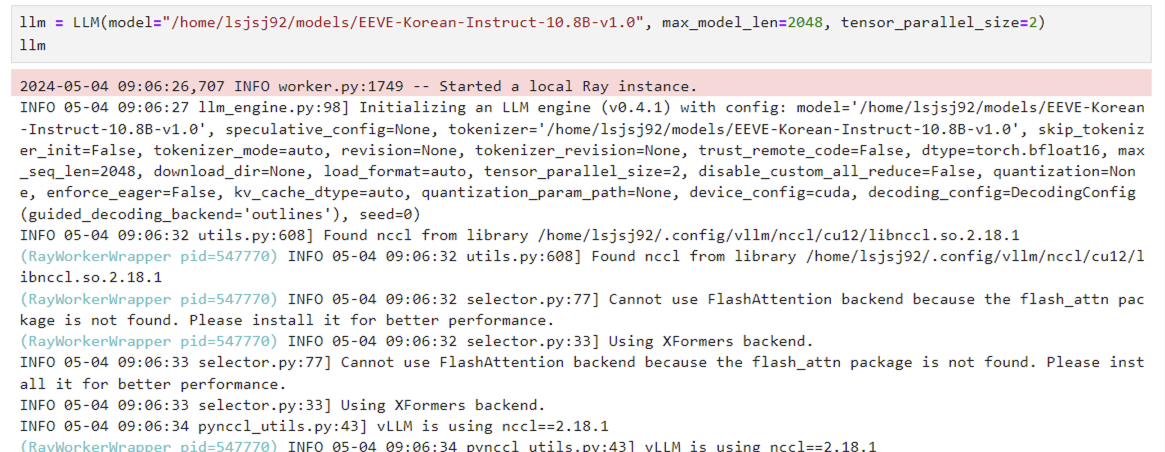
위 코드를 실행하면 사진과 같이 어떤 실행 메세지가 나오면서 vLLM이 구동되는 것을 확인할 수 있습니다. 저는 vLLM을 호출할 때 max_model_len과 tensor_parallel_size를 사용했는데요. 각각의 의미는 다음과 같습니다.
- max_model_len : 모델이 지원해주는 최대 시퀀스 길이입니다. 더 짧게도 가능하며, 모델이 지원해주는 가장 큰 값으로도 가능합니다. 저는 2048로 임의로 셋팅했습니다.
- tensor_parallel_size : 앞서 vLLM을 소개할 때 vLLM은 분산 추론(distrubuted inference)를 지원한다고 언급했는데요. 더 자세히 말하면 분산 텐서 병렬(distributed tenwor parallel)기반 inference 및 serving을 지원하는 것입니다. 이때 vLLM은 Ray를 활용해 분산 런타임을 지원합니다. 따라서 Python Ray가 설치되어 있어야하며, 이를 활용하면 쉽고 간단하게 gpu 등을 병렬로 처리할 수 있습니다. 저는 2라고 셋팅해서 2개의 gpu를 사용하도록 설정했습니다.
이렇게 올라온 모델을 사용해 이제 텍스트를 생성하는 text generate를 실행해보겠습니다. 다음과 같이 실행하면 됩니다.
output = llm.generate("쓰고 싶으신 말")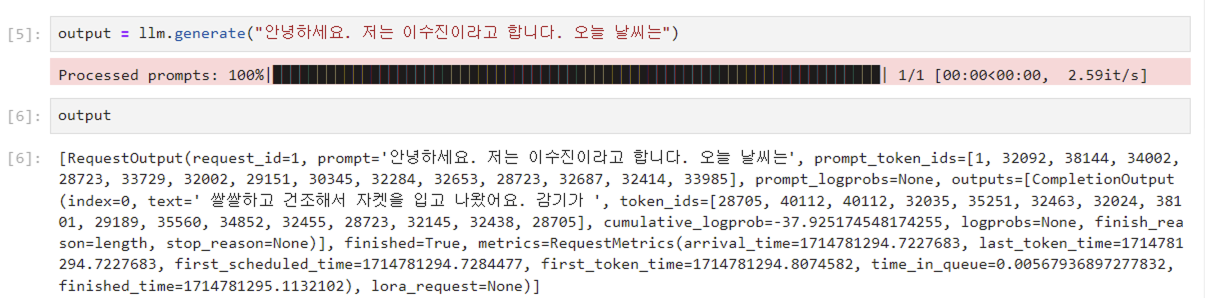
저는 llm.generate("안녕하세요. 저는 이수진이라고 합니다. 오늘 날씨는")까지 입력해두었습니다. 그리고 뒷 부분은 vLLM이 띄운 EEVE 10b 모델이 생성하도록 둔 것이죠. LLM은 저의 입력을 받고 "쌀쌀하고 건조해서 자켓을 입고 나왔어요"라는 문장을 생성해줍니다.
어떤가요? 정말 간단하지 않나요? 단 코드 2~3줄로 LLM 추론(inference)에 성공했습니다.
2-3. vLLM 실행 예제 - API 형태로 배포하기
위처럼 간단하게 vLLM을 사용할 수 있지만, 사실 API 형태로 serving 및 배포해야 RAG 구성이나 실제 사용자, 개발자들이 사용하기 용이할 것입니다. vLLM의 큰 장점은 API 형태로 쉽고 간편하게 LLM을 서빙해서 inference할 수 있다는 것인데요. vLLM이 설치된 환경에서 CLI에 다음과 같이 명령어를 입력하면 LLM api server 형태로 serving 할 수 있습니다.
python -m vllm.entrypoints.api_server \
--model /home/lsjsj92/models/EEVE-Korean-Instruct-10.8B-v1.0 \
--max-model-len=2048 \
--tensor-parallel-size 2
위 명령어는 다음과 같이 해석할 수 있을 것입니다.
- vllm entropoint로 api server를 사용할 것
- model : 내가 사용하고자 하는 모델. 저는 현재 local에 받아놓은 EEVE-korean-instruct-10.8B-v1.0을 사용합니다.
- max-model-len : 간단한 예제에서 살펴본 max_model_len과 동일한 기능
- tensor-parallel-size : 간단한 예제에서 살펴본 분산 텐서 병렬(distributed tenwor parallel)기반 inference 환경

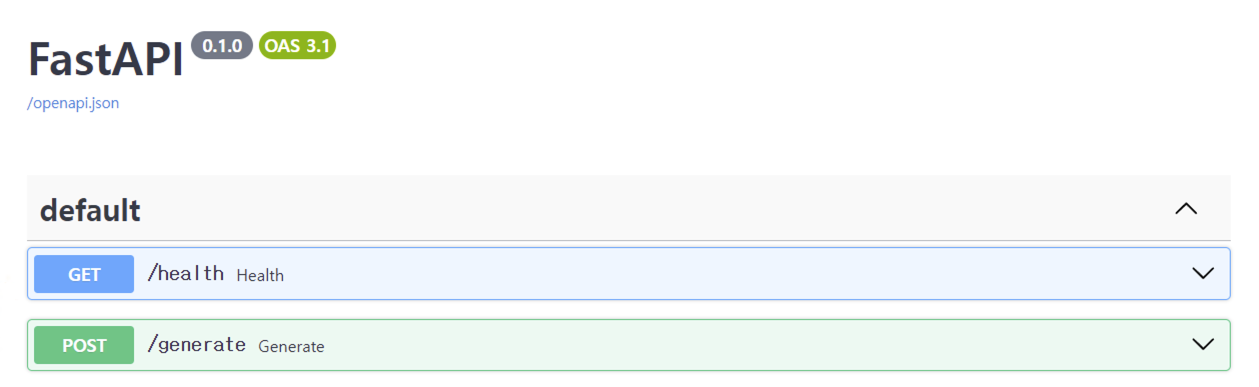
명령어 입력이 잘 실행되었다면, 위 사진과 같이 FastAPI 형태로 vLLM serving 환경이 구성되어질 것입니다. 즉, vLLM을 사용하면 간단하게 LLM 모델들을 API 형태로 서빙이 가능하게 되는 것이죠. 이제 이 API를 호출해서 결과를 받아오면 됩니다. 만약 다음과 같이 입력을 넣었다면, vLLM으로 API serving한 콘솔에 아래 사진과 같은 로그가 남는 것을 확인할 수 있을겁니다.
vllm_host = "http://localhost:8000"
url = f"{vllm_host}/generate"
headers = {"Content-Type": "application/json"}
data = {
"prompt": "안녕하세요. 나는 이수진입니다. 당신은 누구인가요?",
"max_tokens": 2048,
"temperature": 0
}
API 서버에서 사용자가 입력한 값을 받고 generation하는 과정을 볼 수 있습니다. 위 사진에서는 throughput으로 token이 어떻게 되고 있는지 running 상태를 확인할 수 있죠. 그러면 어떻게 실행했는지 궁금하실 겁니다. 아래 코드를 통해 vLLM을 통해 serving되고 있는 LLM의 결과를 받아올 수 있습니다.
import requests
import json
# 호스트는 변경 가능합니다.
vllm_host = "http://localhost:8000"
url = f"{vllm_host}/generate"
headers = {"Content-Type": "application/json"}
data = {
"prompt": "안녕하세요. 나는 이수진입니다. 당신은 누구인가요?",
"max_tokens": 2048,
"temperature": 0
}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response)
print(response.json())
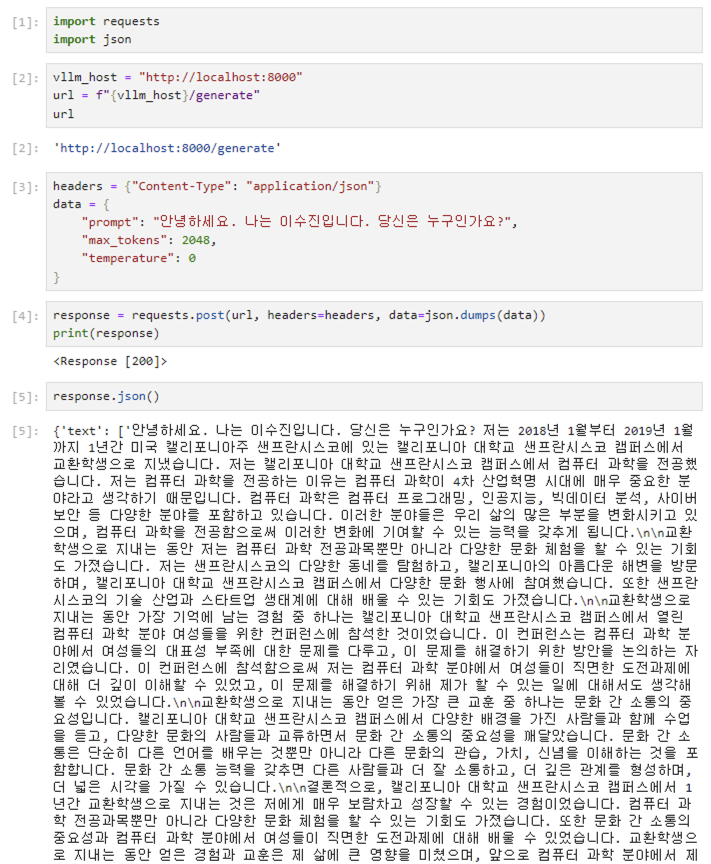
저는 시각적으로 잘 보여드리기 위해서 주피터 노트북 환경에서 실행해봤습니다. API 요청(request)에 필요한 헤더와 데이터를 넣어주는데요. 이때 데이터로는 vLLM serving으로 배포되어진 host와 입력하고 싶은 prompt 등이 있습니다. 제가 입력한 값은 다음과 같습니다.
- url : 본 예제애서는 localhost(127.0.0.1)로 해두었습니다. 이 값은 IP 주소로도 접근이 가능합니다.
- data : prompt에 원하는 메세지를 입력하시면 됩니다. 그리고 토큰과 temperature와 같은 요소를 지정할 수도 있습니다.
그 결과는 request.post 함수를 실행해 받아올 수 있는데요. 정상적이라면 http 200 코드가 나올 것입니다. 또한, 모델이 생성한(본 예제에서는 EEVE 모델) 결과는 response.json()으로 볼 수 있습니다. 본 예제에서는 제가 입력한 "안녕하세요. 나는 이수진입니다. 당신은 누구인가요?"라는 말 이후로 LLM 모델이 생성한 텍스트를 확인할 수 있습니다.
2-4. vLLM 실행 예제 - 채팅(chat) 템플릿으로 chatbot 포멧 구성
본 예제에서는 vLLM을 통해 서빙된 모델이 huggingface 모델을 사용합니다. 그렇기 때문에 transformers 라이브러리에서 지원해주는 토크나이저(tokenizer)를 사용할 수 있는데요. 토크나이저에서 지원해주는 채팅 템플릿(chat template)을 사용하면 성능 좋은 채팅 형태의 LLM 결과를 받아올 수 있습니다. 이를 위해 필요한 핵심 코드는 다음과 같습니다.
# huggingface 모델에서 토크나이저를 가져옴
tokenizer = AutoTokenizer.from_pretrained("/home/lsjsj92/models/EEVE-Korean-Instruct-10.8B-v1.0")
# 토크나이저에서 지원해주는 채팅 탬플릿 사용
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# vLLM으로 서빙되고 있는 모델 호출
headers = {"Content-Type": "application/json"}
data = {
"prompt": text,
"max_tokens": 2048,
"temperature": 0
}
response = requests.post(url, headers=headers, data=json.dumps(data))
먼저, transformers 라이브러리에서 지원해주는 AutoTokenzier를 통해 huggingface 모델에서 사용된 토크나이저를 가지고 옵니다. 이 토크나이저는 apply_chat_template라는 함수를 제공해주는데요. apply_chat_template를 사용하면 본 모델에 적합한 채팅 형태의 포멧을 구성해줍니다. 이 포멧이 중요한 이유는 start와 end를 정확히 잡아내, 모델이 불필요한 말을 생성하지 않도록 구성할 수 있습니다. 이렇게 구성된 채팅 템플릿을 vLLM으로 서빙중인 LLM API로 보내면 LLM은 그에 맞은 답을 생성해줍니다.
전체 코드는 다음과 같습니다.
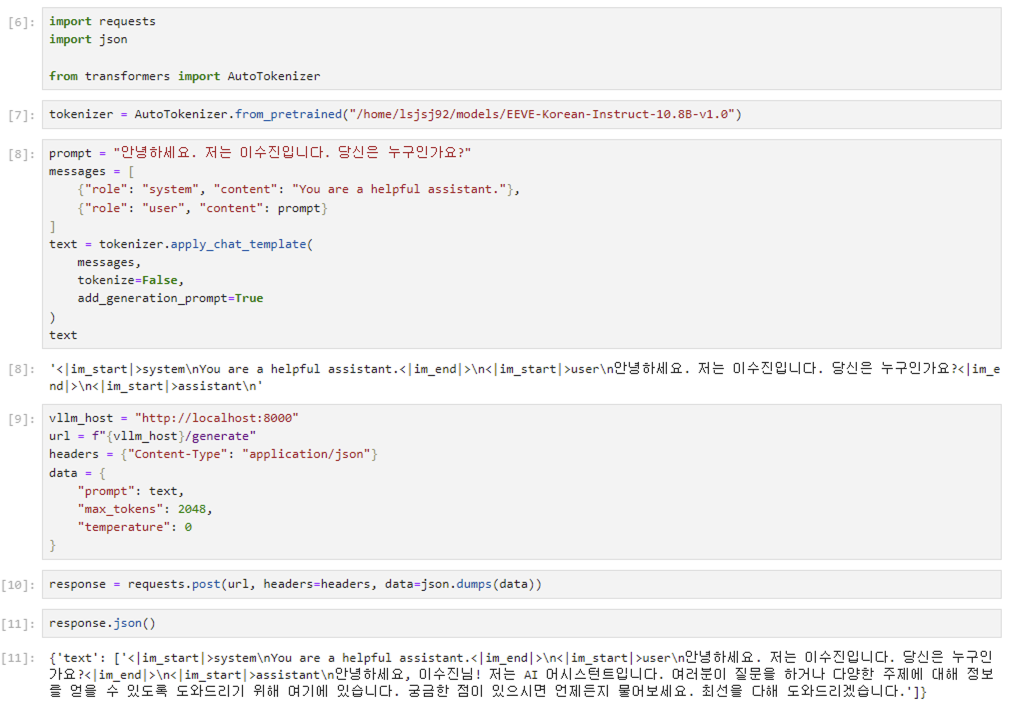
토크나이저를 생성한 뒤 apply_chat_template으로 채팅 탬플릿을 구성합니다. 채팅 탬플릿을 보면 im_start, im_end와 같이 어떤 포멧을 구성해준 것을 확인할 수 있습니다. 이렇게 구성된 템플릿을 vllm host에 API request를 보낼 때 data prompt로 보내주면 됩니다. 그 결과는 사진 아래쪽에 나와있는데요. 2-3에서 봤던 결과와 확연하게 차이가 나는 것을 보실 수 있을겁니다. 즉, 채팅 탬플릿을 적용했더니 결과가 채팅 형식으로 결과가 나오는 것을 확인할 수 있죠.
2-5. vLLM 실행 예제 - LangChain과 결합하여 RAG 구성
마지막으로 vLLM으로 배포된 LLM 모델을 활용해서 LangChain과 결합해 RAG를 간단하게 구성해보는 예제를 소개하겠습니다. 저는 langchain에서 지원해주는 webaseloader를 활용해 제 블로그 포스팅 자료를 벡터 DB(vectordb)로 구성하려고 합니다. 제가 webbaseloader로 가져오는 포스팅 글은, 이전에 작성한 LLM 기반 추천 시스템 논문인 LlamaRec 이라는 논문의 포스팅 글입니다.
저는 langchain을 이용해서 아래와 같이 데이터 셋팅을 진행했습니다.
loader = WebBaseLoader("https://lsjsj92.tistory.com/667")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=700, chunk_overlap=50)
texts = text_splitter.split_documents(data)
db = FAISS.from_documents(texts, embeddings)
db_retriever = db.as_retriever(search_kwargs={"k": 3})
1. loader : 블로그의 글을 가져오기 위해서 webbaseloader를 사용했습니다.
2. Text Split : Langchain에서 지원해주는 RecursiveCharacterTextSplitter를 사용했습니다.
3. embedding : openAI embedding 등 원하시는 임베딩을 사용하시면 됩니다. 본 포스팅은 OpenAI embedding을 사용했습니다.
4. vector database : Langchain에서 지원해주는 벡터 데이터베이스를 사용하시면 됩니다. 본 포스팅은 FAISS를 사용했습니다.
또한, 아래와 같이 사용자 질문이 발생하면 연관되어 있는 document를 가져오도록 했습니다. 이때, 가져온 document 내용을 하나의 문자열로 재구성하였습니다.
user_query = "Two-Stage Recommendation 방법이 뭐야?"
docs = db_retriever.get_relevant_documents(f"{user_query}")
temp_str = ""
for d in docs:
temp_str += f"내용 : {d.page_content}\n"
이제 vLLM으로 serving중인 LLM에 API request를 보내면 되는데요. 저는 여기서 프롬프트를 좀 더 자세히 작성해봤습니다. 제가 작성한 프롬프트는 다음과 같습니다.
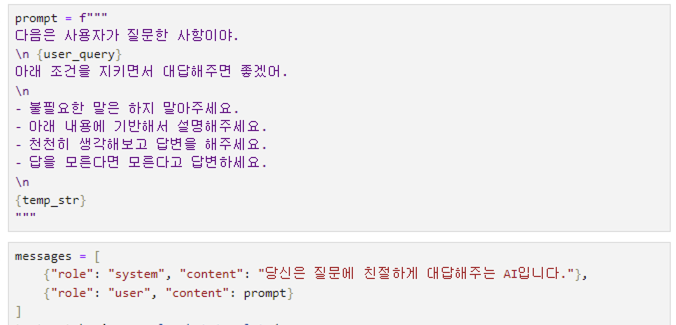
위에서 소개한 간단한 prompt가 아니라, 불필요한 말은 하지 말아달라, 아래 내용을 참고해서 말을 해주세요 등의 구체적인 지시를 설정했습니다.
이제 이 결과를 LLM API로 request를 보내면 됩니다.

답변이 잘 나오는 것을 확인할 수 있습니다.
마무리
이번 포스팅은 LLM 모델을 쉽고 빠르게 배포, 서빙(serving) 및 추론(inference)할 수 있는 vLLM 라이브러리 사용 방법에 대해서 알아보았습니다.
vLLM이 무엇인지, vLLM을 어떻게 사용하는지에 대한 예제(example)도 같이 작성해두었으니, vLLM을 사용하시는데 조금이라도 도움되시길 바랍니다. 감사합니다.
저에게 연락을 주시고 싶으신 것이 있으시다면
- Linkedin : https://www.linkedin.com/in/lsjsj92/
- github : https://github.com/lsjsj92
- 블로그 댓글 또는 방명록
으로 연락주세요!