TALLRec 논문 리뷰 - LLM 기반 추천 시스템 (An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation)
포스팅 개요
본 포스팅은 LLM을 활용한 추천 시스템 논문인 TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation이라는 논문을 리뷰한 포스팅입니다. 글을 쓰고 있는 시점으로 300회가 넘는 인용이 있고 LLM을 추천(Recommendation) 테스크로 파인튜닝(Fine-tuning)을 한 방법을 제안하는 논문입니다. 이를 위해 LoRA 방법을 채택하였고 기존에 대규모 언어 모델(Large Language Model, LLM)이 추천 시스템 영역에 Alignment가 부족했는데, 이를 보완하여 LLM이 추천 시스템 영역으로 확장된 Large Recommendation Language Model을 제안합니다.
본 논문은 아래 링크에서 확인할 수 있습니다.

포스팅 본문
포스팅 개요에서도 언급하였듯 본 포스팅은 LLM을 활용한 추천 시스템 논문인 TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation 논문을 리뷰하는 포스팅입니다.
이번 리뷰 포스팅은 논문의 핵심 요약부터 사전 지식, TALLRec 방법론, 실험 결과 그리고 결론 순으로 정리하겠습니다.
1. 논문의 핵심 요약
대규모 언어 모델(Large Language Models, LLM)은 자연어 처리(NLP), 정보 검색 등 다양한 분야에서 뛰어난 성능을 보여주며 빠르게 발전하고 있습니다. 그러나, 이러한 LLM의 능력을 추천 시스템에 적용하는 초기 시도들은 한계에 부딪혔는데요. 기존 연구들은 LLM의 풍부한 지식과 일반화 능력을 활용해 추천 작업을 In-contexst learning 방식으로 접근했지만, 이는 전통적인 추천 시스템과 비교해 큰 성과를 거두지 못했습니다. 이는 본질적으로 LLM의 학습 과정과 추천 작업 간의 데이터 차이가 부족하기 때문이죠.
이러한 한계를 극복하기 위해 저자들은 ALLRec(Tuning Framework to Aligning LLMs with Recommendation)을 제안했습니다. TALLRec은 LLM을 추천 task에 효과적으로 Align하기 위한 효율적인 튜닝 방법입니다. 이 프레임워크는 두 가지 주요 단계로 구성되어 있습니다. 첫 번째는 Self-instruct 데이터를 활용한 Alpaca Tuning으로 LLM의 일반화 능력을 강화합니다. 두 번째는 실제 추천 데이터를 Instruction tuning 방식으로 구성하여 LLM을 추가로 튜닝하는 Rec-tuning입니다.
이때, 저자들은 LoRA(Low-Rank Adaptation)을 적용하여 경량화(Lightweight)된 튜닝을 구현함으로써 적은 자원으로도 충분히 높은 성능을 달성할 수 있도록 진행했습니다.
2. Introduction
대규모 언어 모델(LLM)은 다양한 분야에서 뛰어난 성능을 보여주고 있지만, 추천 시스템 분야에서는 아직 충분히 능력이 발휘되지 못하였습니다. 추천 시스템은 사용자의 선호도를 기반으로 개인화된 콘텐츠를 제공하는 방법으로, 사용자에 대한 선호 지식이 필요합니다. 그러나, LLM은 이러한 요구를 충분히 충족시키지 못하고 있죠.
기존의 연구들은 LLM의 추천 시스템에 적용하기 위해 In-context learning 방식을 사용했습니다. 이 방법은 기존 전통적인 추천 모델(CF, MF, LightGCN 등)에서 필터링된 후보 아이템을 LLM이 재정렬 하는 정도의 역할로 사용했었죠. 하지만, 이런 접근 방법은 전통적인 추천 방법과 성능면에서 큰 차이가 없거나, 경우에 따라서는 추천을 거절하거나 항상 긍정적인 답변만 제공하는 형태도 보였습니다(Figure 1).
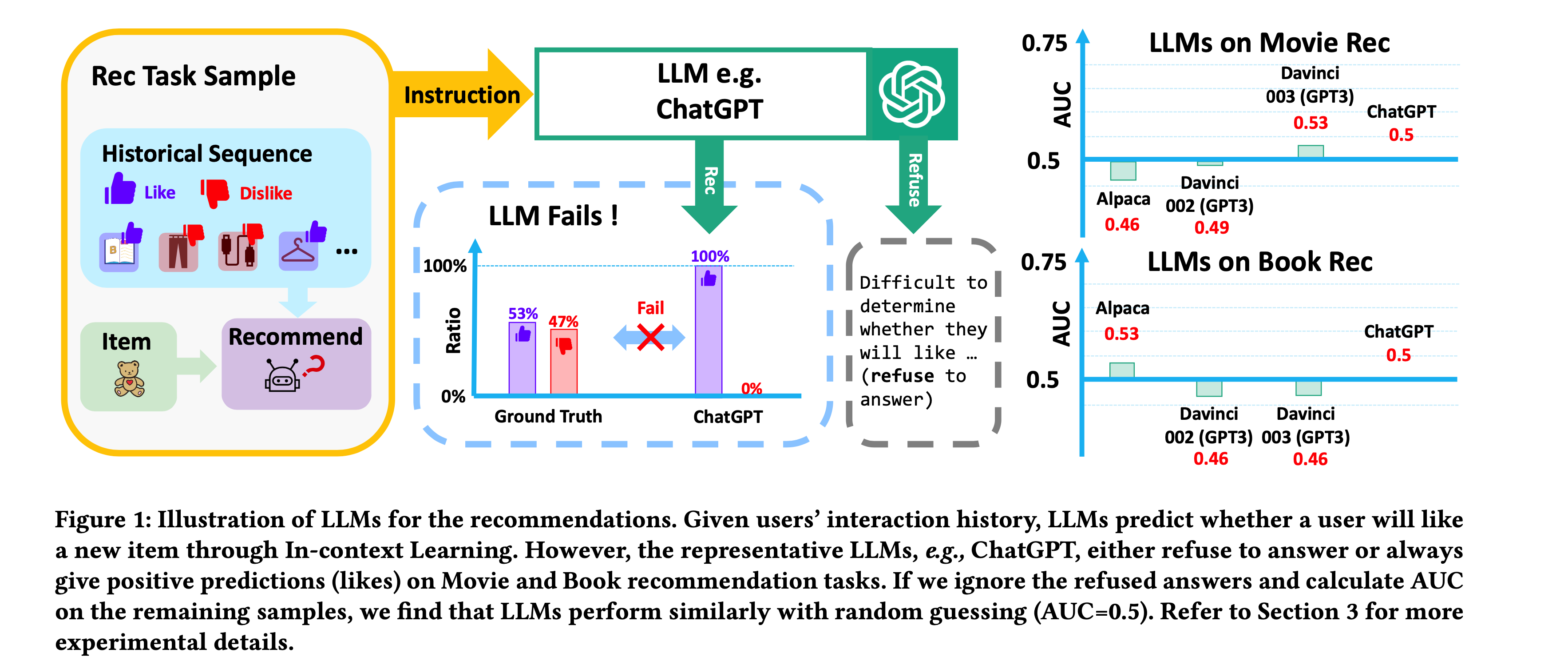
저자들은 이에 대한 원인을
1) 첫째 LLM의 훈련 과정과 추천 task 간의 차이로 인해 적합하지 않은 문제가 있었고
2) 둘째 LLM이 학습하는 데이터에 추천과 관련된 데이터가 부족하다는 것
3) 셋째 기본 추천 모델에 의해 효과가 제한되는 것
이라고 이야기합니다. 이에 저자들은 LLM을 추천 작업에 최적화하기 위해 대규모 추천 언어 모델(Large Recommendation Language Model)의 구축이 필요하다고 이야기 하면서 TALLRec 프레임워크에 대한 배경을 설명합니다.
TALLRec은 뒷 부분에서 더 자세히 설명드리겠지만, 두 가지 튜닝 과정을 거치게 됩니다. 1) 알파카 튜닝(Alpaca Tuning) 과정에서 LLM의 일반화 능력을 강화하고 2) Rec-Tuning 단계에서 추천 task에 최적화를 진행합니다. 이때 경량화(Lightweight) 전략을 위해 LoRA를 활용하여 튜닝을 진행했으며 NVIDIA RTX 3090 GPU에서도 튜닝을 실행할 수 있었다고 합니다. 또한, 적은 수의 학습 데이터로도 우수한 성능을 보이며, 도메인 간 일반화 능력 또한 뛰어나다고 설명합니다.
3. 사전 지식(Preliminary)
LLM을 추천 시스템에 적용하기 위해서는 기존의 자연어 처리와는 다른 접근 방식이 필요합니다. 이를 위해 저자들은 Instruction Tuning과 Rec-Tuning이라는 개념을 도입했습니다.
TALLRec 논문에서 말하는 Instruction Tuning이란?
TALLRec 저자들은 Instruction tuning을 LLM이 특정 작업을 이해하고 수행할 수 있도록 자연어로 된 지시문과 입력 데이터를 학습시키는 방식을 의미한다고 이야기합니다. 예를 들어, "이 영어 문장을 중국어로 번역하세요"와 같은 지시문과 함께 번역할 문장을 제공하고, 이에 대한 번역 결과를 학습하도록 하는 것이죠. 즉, LLM의 일반화를 강화하는 과정으로 일반적인 LLM 튜닝 과정과 유사하다고 보시면 될 것 같습니다. 저자들은 Instruction Tuning에서 총 4단계의 과정이 있다고 말합니다.
- Step 1: Task 정의 및 지시문 작성을 진행합니다. 수행할 task를 정의하고 이 작업을 자연어로 설명하는 지시문(Task Instruction)을 작성하는 것이죠. "이 영어 문장을 한국어로 번역하세요"와 같은 문장이 그 예시가 되겠습니다.
- Step 2: 입력 및 출력 데이터를 구성합니다. 작업에 사용할 input과 예상되는 출력(task output)을 자연어 형래토 구성합니다. 예를 들어, 입력이 : "Who am I"?면 출력(output)은 "내가 누구인가요"가 될 수 있겠죠.
- Step 3: Instruction input을 통합합니다. 작성한 지시문(Task Instruction)과 입력(Task Input)을 결합해 Instruction input을 구성한다고 합니다. 이때 출력(Task output)은 Instruction output으로 설정합니다.
- Step 4: 튜닝을 수행합니다. Instruction input과 output을 쌍으로 사용해서 LLM을 튜닝합니다.
TALLRec 논문에서 말하는 Rec-Tuning이란?
저자들은 Instruction Tuning된 LLM에 Rec-tuning 작업을 진행합니다. Rec-Tuning은 추천 시스템 작업에 특화된 LLM을 학습시키는 과정을 의미합니다. 이 과정은 아래 Table 2와 같은 과정으로 진행이 되는데요.
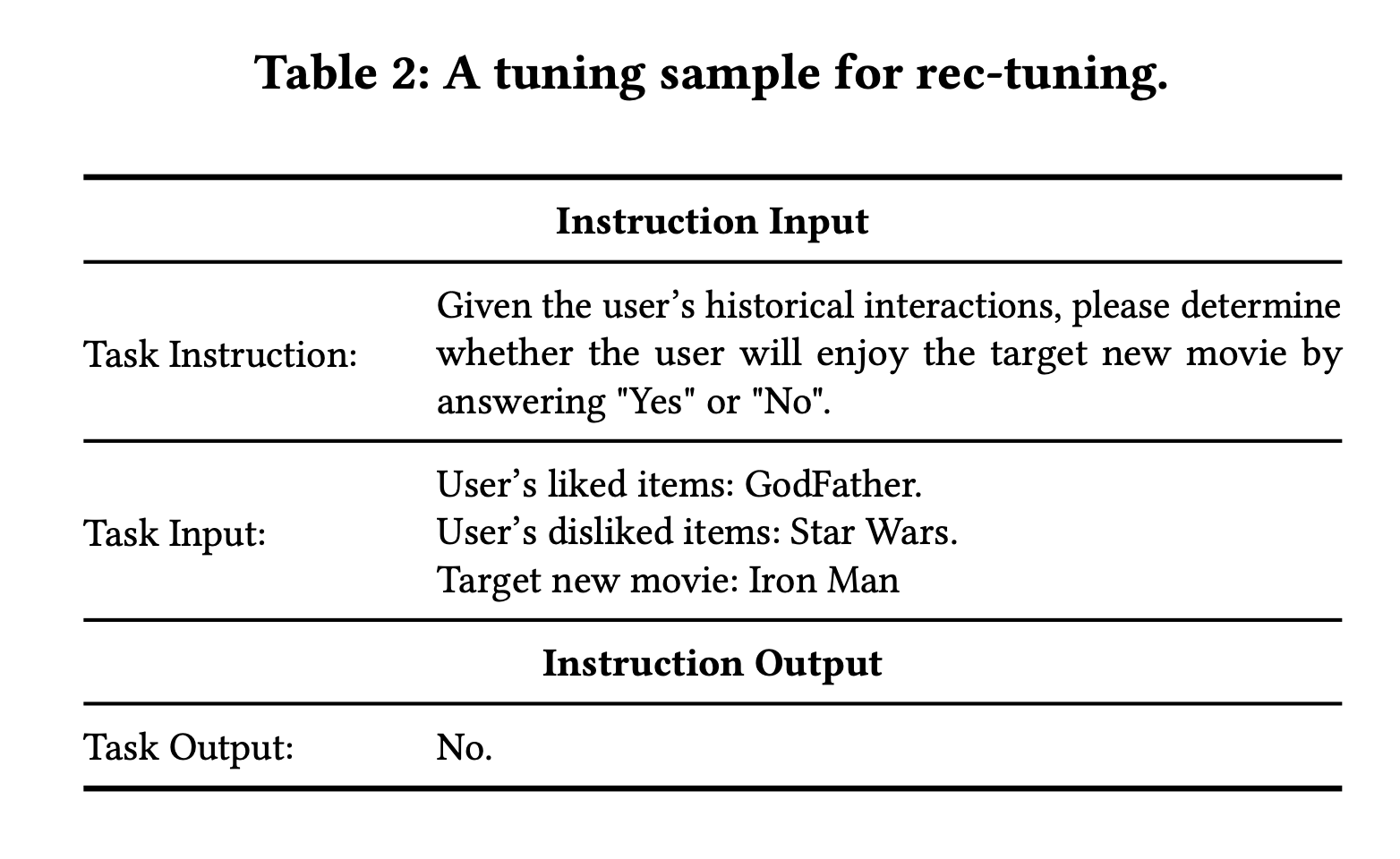
- Task Instruction은 사용자의 상호작용을 바탕으로 대상 항목을 좋아하는지, "예" 또는 "아니오"로 대답하도록 모델에게 지시하는 Instruction 요소라고 보시면 됩니다.
- Task Input은 사용자가 과거에 상호작용한 아이템들을 평점에 따라 분류해서 제공합니다. 평점에 따라 분류한다는 것은 사용자가 좋아했던 아이템과 싫어했던 아이템에 대한 분류입니다. 이때, 아이템들은 상호작용한 시간에 따라 순차적으로 순위가 매겨지고 제목이나 간단한 소개(brief introduction)으로 표현된다고 합니다.
- 이렇게 Task Instruction과 Task Input을 합쳐서 Instruction Input으로 설정합니다.
- 마지막으로 Instruction output에는 모델이 예상하는 출력값으로 Yes or No로 나오도록 설정합니다.
4. TALL-Rec Framework에 대해서
TALLRec 저자들이 주장하는 것은 대규모 언어 모델(LLM)을 추천 시스템 영역에 활용하는 것입니다. 즉, LLM을 추천 시스템에 최적화하기 위해 설계된 프레임워크이므로, 저자들은 두 가지 주요 튜닝 단계를 소개합니다. 바로 알파카 튜닝(Alpaca-Tuning)과 추천 튜닝(Rec-Tuning)입니다. 이 프로세스에 대한 설명은 Figure 2에 잘 나와있습니다.
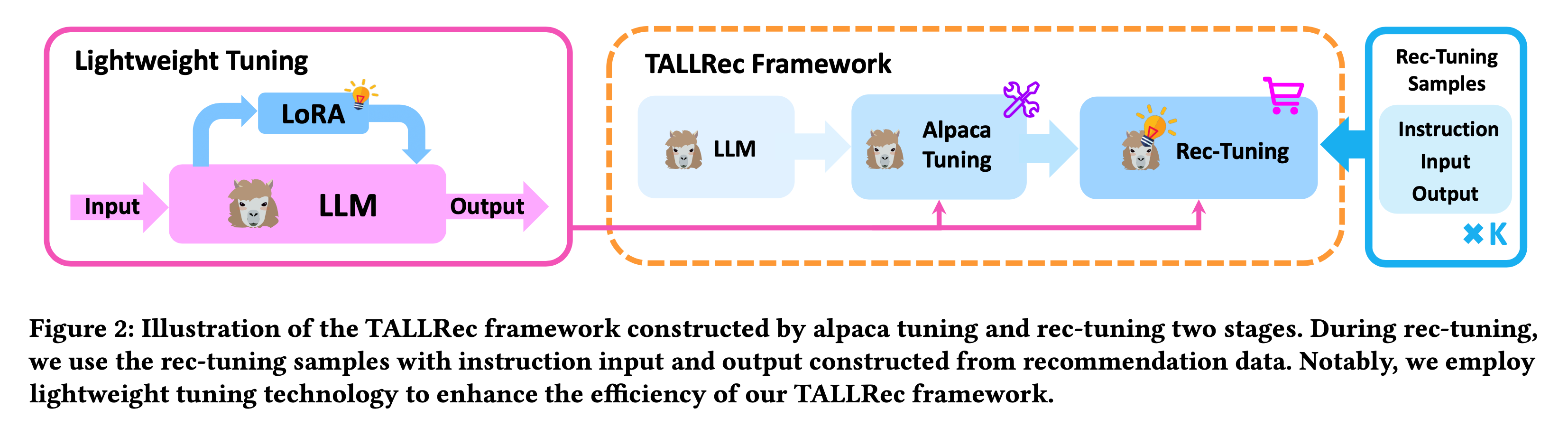
알파카 튜닝(Alpaca Tuning)은 LLM의 일반적인 문제 해결 능력을 강화하는 과정입니다. 즉, 일반화 능력을 향상시키는 과정이라고 보시면 됩니다. 이 과정은 위에서 소개한 것과 같이 self-instruction 데이터를 기반해 수행됩니다. 수식으로 표현하면 수식(1)과 같습니다.
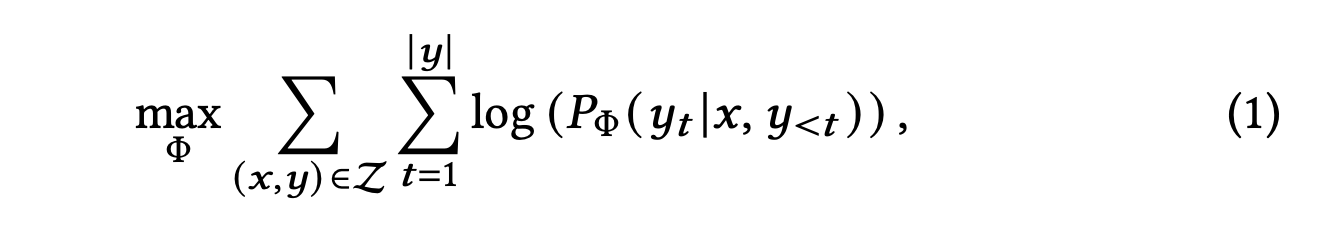
수식 (1)을 보면 \(y_t\)는 \(t\)번째 토큰이라고 보시면 됩니다. \(y_{<t}\)는 \(y_t\)전까지의 토큰을 의미합니다. 즉, 주어진 입력 \(x\)와 이전 토큰들을 기반으로 \(y_t\)가 나올 확률을 학습하는 것이죠.
그러나 LLM을 그냥 이대로 학습시키는 것은 매우 계산 비용이 높은 작업입니다. 따라서, 논문의 저자들은 LoRA 방법을 채택해서 효율적으로 LLM 튜팅을 진행하도록 합니다. 그 수식은 수식 (2)와 같습니다.
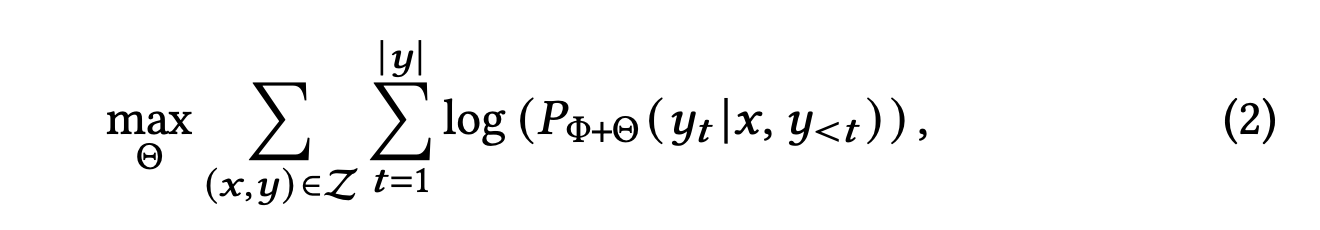
\(\theta\)는 LoRA 파라미터이고 저자들은 오직 LoRA 파라미터만 학습 프로세스 때 업데이트 하는 방식으로 진행했다고 합니다.
Rec-tuning 단계는 LLM이 추천 시스템 task를 잘 수행할 수 있도록 튜닝하는 과정입니다. Rec-tuning도 마찬가지로 LoRA 기반으로 진행되었다고 합니다.
또한, 저자들은 Backbone으로 LLaMA 7b 모델을 활용했다고 합니다. 학습 데이터와 연구 결과 등이 모두 공개되어 있어 활용하기 유용하기에 LLaMA를 활용했다고 말합니다.
5. 실험(Experiments)
5-1. Experiments 환경 구성
저자들은 TALLRec Framework의 성능을 평가하기 위해 다양한 실험을 진행했습니다. 특히, 실험의 주요 목표는 아래와 같은 질문에 답하는 것이라고 합니다.
- RQ1. TALLRec이 기존의 LLM 기반 추천 시스템과 전통적인 추천(Traditional recommendation) 방법과 비교해서 좋은 성능을 보이는가?
- RQ2. TALLRec의 구성 요소들이 모델 성능에 미치는 영향은 무엇인가?
- RQ3. TALLRec이 cross domain 추천에서 얼마나 좋은 일반화 성능을 보여주는가?
TALLRec의 데이터 셋 & Few-shot 학습 설정
TALLRec에서는 MovieLens100K 데이터 셋, BookCrossing 데이터 셋 총 2가지 데이터를 사용했습니다. MovieLens100K 데이터 셋에서는 최근 10,000개의 interaction을 샘플링했고 학습:검증:테스트를 8:1:1 비율로 셋팅하였습니다. 또한, 사용자의 선호와 비선호를 구분하기 위해서 평점(rating)이 3점 이상이면 선호, 아니면 비선호로 표현했습니다. 그리고 영화의 제목이나 감독을 텍스트 설명으로 포함하였습니다. BookCrossing 데이터의 경우 사용자 평점이 1~10점 분포로 구성되어 있습니다. 또한, 책 제목이나 저자 정보를 텍스트 설명으로 포함하였으며, 평점 5점을 기준으로 선호, 비선호를 구분하였습니다. BookCrossing 데이터는 상호작용(interaction)의 타임스템프가 부족하기 때문에 random sampling 형식으로 사용자마다 무작위로 선태하여 히스토리컬 데이터를 구성하였다고 저자들은 말합니다.
저자들은 few-shot 학습 설정이라는 것을 진행하는데요. 이는 학습 데이터셋에서 임의로 선택한 소량의 샘플(k개)만 사용하여 모델을 학습하는 과정을 진행하는 것입니다. 이렇게 제한된 수의 샘플로 훈련을 진행한 이유는 TALLRec 모델이 제한된 데이터만으로도 추천 시스템 task를 효과적으로 수행할 수 있는지 평가하기 위해서였다고 하네요.
베이스라인 모델(Baseline model), 평가 지표(Evaluation Metric)와 구현 세부사항(Implementation Details)
TALLRec에서 베이스라인 모델은 LLM 기반 모델과 전통적인 추천 시스템 방법 2가지고 구분하였습니다. LLM 기반 모델은 In-context learning을 활용하고 Alpaca-LoRA, Text-Davinci-002, Text-Davinci-003, ChatGPT를 활용했다고 합니다. 전통적인 추천 시스템 방법은 GRU4Rec, Caser, SASRec, GRU-BERT 등을 활용했습니다.
평가 지표는 AUC를 활용했고 구현 세부사항은 Adam 등을 사용한 것인데 본 포스팅에서 자세한 것은 생략하며, 궁금하신 분들은 논문을 확인해주시면 되겠습니다.
5-2. Performance comparison(RQ1)
먼저 저자들은 TALLRec Framework의 성능을 평가하기 위해 기존의 전통적인 추천 시스템 방법과 LLM 기반 추천 시스템 방법과 성능을 비교하였습니다. 이때, 제한된 데이터(few-shot) 환경에서도 TALLRec이 얼마나 우수한 성능을 보여주는지 확인합니다. Table 3는 다양한 Few-shot 설정(16 또는 64 또는 256)에서 기존 전통 추천 방법들과 비교한 결과를 보여줍니다.
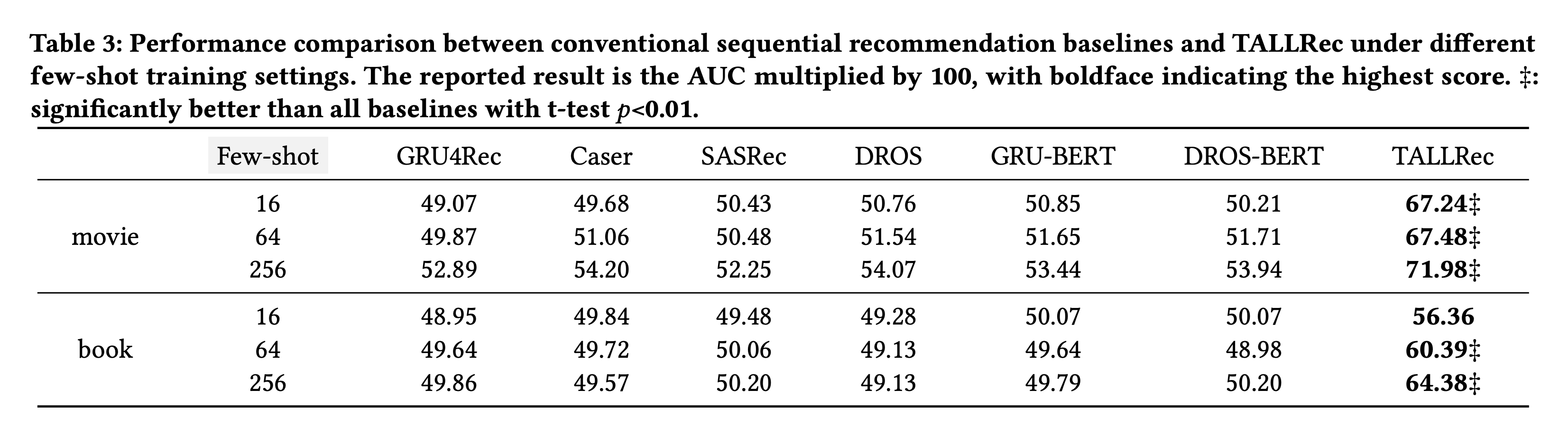
Movie 데이터셋과 Book 데이터셋 모두의 경우 TALLRec이 더 좋은 성능을 보여주었습니다. 이때, few-shot이 증가할수록 모델의 성능 또한 증가하는 것을 확인할 수 있습니다.
Figure 3의 왼쪽 그림인 (a)영역에서는 TALLRec과 LLM 기반 모델들의 성능을 비교한 결과를 보여줍니다.
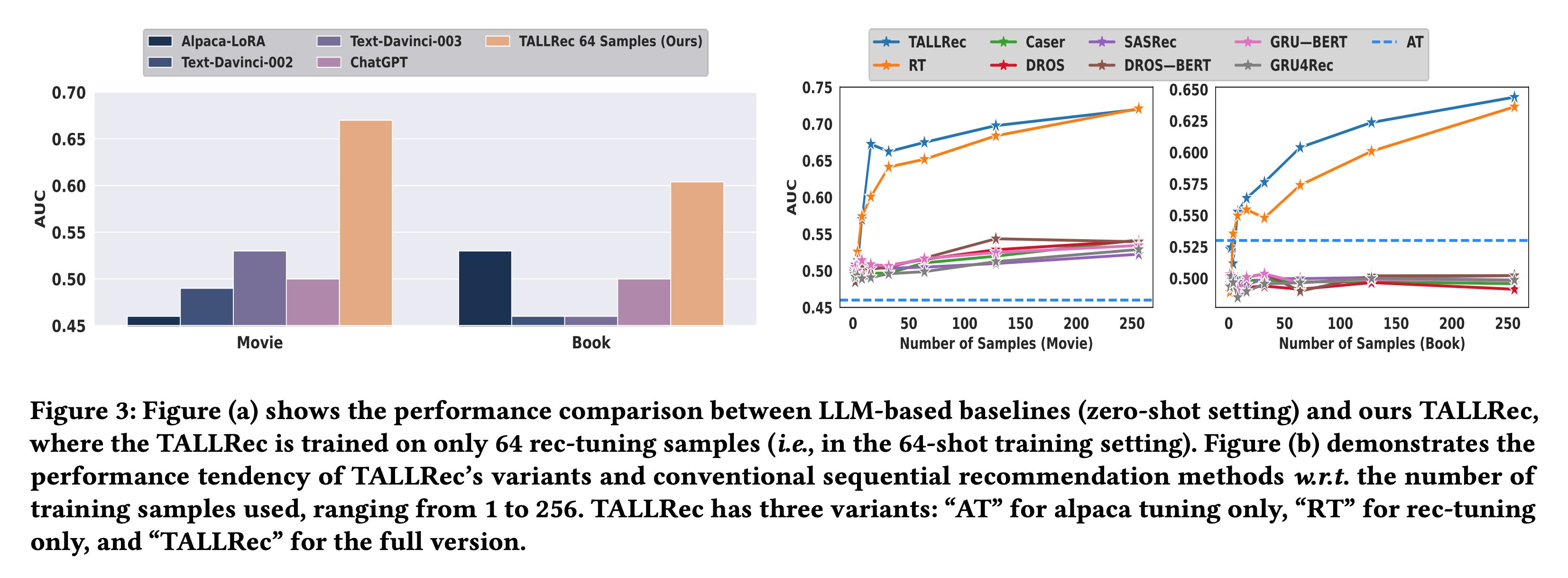
비교된 모델은 앞서 설명드렸던 Alpaca-LoRA, Text-Davinci-002, Text-Davinci-003, ChatGPT인데요. 모든 결과에서 저자들이 제시한 TALLRec이 좋은 성능을 보여주었습니다. 특히, 저자들은 Alpaca-LoRA와 Text-Davinci 계열 모델들은 random guessing 정도의 수준이라면서 한계가 있음을 언급하였고 이는 추천 시스템 task와 언어 모델의 task 사이의 상당한 차이가 있음을 언급하였습니다. 그와 반면에 TALLRec은 우수한 성능을 보여주면서 LLM을 rec-tuning하는 과정이 중요하다는 것을 언급합니다.
5-3. Ablation study(RQ2)
저자들은 alpaca-tuning과 rec-tuning이 TALLRec 성능에 미치는 영향을 평가하기 위해 추가 Ablation study를 논문 3.2 섹션에서 진행합니다. 이때, AT는 Alpaca-tuning만 진행한 모델로 일반화 능력은 강화하지만, 추천 시스템 task에 훈련을 진행하지 않은 모델입니다. 또한, RT는 Rec-tuning만 수행한 모델로 Alpaca-tuning 없이 추천 시스템 task에 튜닝된 모델입니다. 동시에 few-shot sample 수에 따른 성능 평가를 진행하였습니다.
Ablation 실험 결과는 Figure 3의 오른쪽 그림인 (b)에 실험 결과가 나와있습니다. 이 실험 결과를 정리하자면 아래와 같습니다.
1. Alpaca 튜닝(AT)는 AUC가 매우 낮게 나오고 있습니다. 이는 일반화된 능력을 강화하더라도 추천 시스템 task에 기여하지 못하는 것을 보여주는 결과입니다.
2. Rec 튜닝(RT)는 AT보다 더 좋은 결과가 나왔고 sample 수가 증가할 때마다 TALLRec에 버금가는 성능을 보여주었습니다. 다만, RT는 적은 샘플 수에서는 TALLRec보다 성능이 떨어지는 결과가 나왔습니다. 이는 Alpaca-tuning이 new task에서 LLM의 일반화 능력을 향상시킬 수 있음을 확인할 수 있다고 저자들은 주장합니다. 특히, new task의 학습 데이터가 충분하지 않을 때 더욱 그럴 것이라고 이야기합니다. 그리고 샘플의 수가 증가함에 따라 TALLRec에 가까워지는 것은 학습 데이터가 충분할 때 다른 task에서 도출된 일반화 능력이 감소하기 때문에 이는 합리적이라고 저자들은 말합니다.
3. TALLRec은 가장 좋은 성능을 보여주었습니다.
5-4. Cross-domain Generalization Analyses(RQ3)
저자들은 TALLRec Framework가 가지는 강점 중 하나가 다양한 도메인 간의 일반화 능력(cross domain generalization)이라고 합니다. 이를 평가하기 위해서 book 데이터만 학습한 모델, Movie 데이터로 학습한 모델, 두 데이터를 모두 학습한 모델을 활용해 두 가지 도메인 boo, movie에 대해서 평가를 진행했습니다. 그 결과는 Figure 4에 나와있습니다.
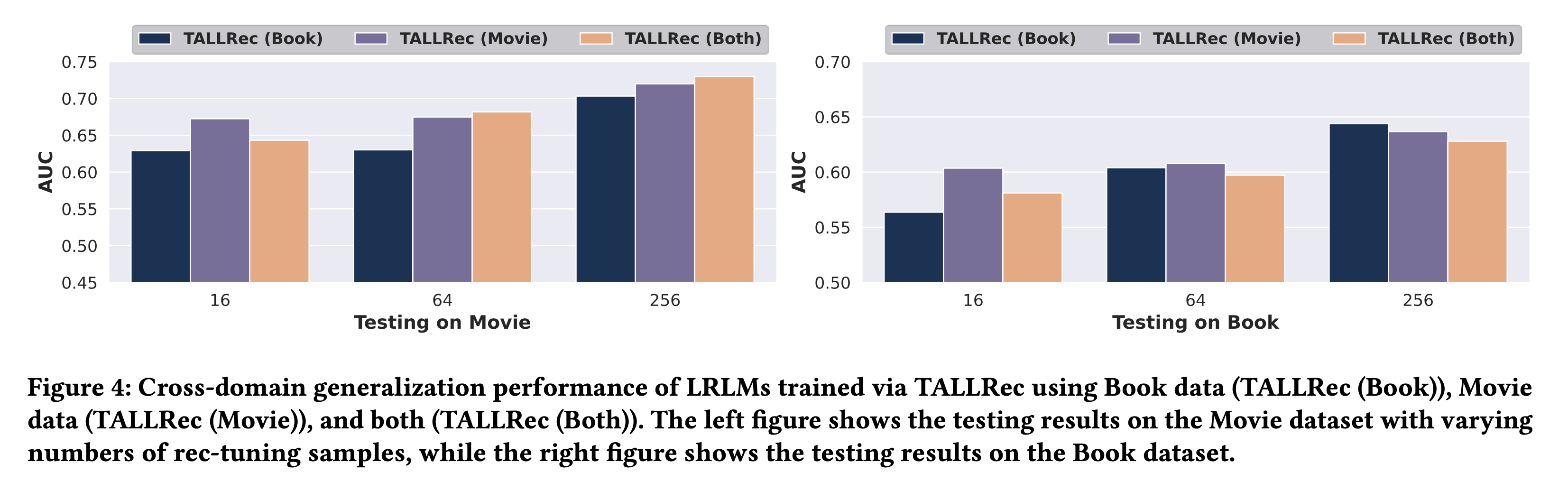
Movie 데이터에서 학습된 TALLRec(Movie)와 book 데이터에서 학습된 TALLRec(book)이 서로 다른 도메인에서 어느정도 성능이 나오고 있음을 확인할 수 있습니다. 이를 통해 저자들은 TALLRec이 cross-domain 일반화 능력을 보여주고 있다고 주장합니다.
(개인적으론 좀 받아드리기 어려운 주장입니다. 그 이유는, 이는 데이터 셋에 굉장히 민감할 것 같고 좀 더 다양한 테스트가 되어야 하지 않을까?싶습니다.)
마무리
본 포스팅은 LLM을 활용한 추천 시스템 논문인 TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation 논문을 읽고 리뷰한 포스팅입니다. 대규모 언어 모델(LLM)과 추천 시스템 task를 Alignment 하는 시도를 보여주는 논문입니다. LLM과 추천 시스템의 결합에 관심이 있으신 분들께 조금이나마 도움이 되기를 바라겠습니다.
긴 글 읽어주셔서 감사합니다.
저에게 연락을 주시고 싶으신 것이 있으시다면
- Linkedin : https://www.linkedin.com/in/lsjsj92/
- github : https://github.com/lsjsj92
- 블로그 댓글 또는 방명록
으로 연락주세요!