인공지능 윤리(AI Ethics)란 무엇일까? AI개발자가 바라본 AI윤리(Feat. AI 기획자 Day 발표)
포스팅 개요
이번 포스팅은 시간이 지날수록 중요성이 부각되고 있는 인공지능 윤리(AI 윤리, AI Ethics)에 대해서 AI 개발자의 입장에서 정리해본 생각을 작성한 포스팅입니다. 본 포스팅은 지극히 개인적인 생각과 입장을 정리한 포스팅이니, 부족한 점이 있으면 양해 부탁드리면서 피드백 주시면 좋을 것 같습니다.
또한, 본 포스팅의 내용은 당근대장(당근=당연히 대장님)님께서 주최하시는 AI 기획자 Day에서 발표한 자료를 기반으로 작성하였습니다.
전체 발표 자료는 포스팅 하단에 첨부하였습니다.
포스팅 본문
포스팅 개요에서도 언급하였듯, 본 포스팅은 AI 윤리에 대해서 AI 개발자의 입장에서 간단하게 생각을 정리한 포스팅입니다.
부족한 한 개발자가 가지고 있는 생각을 정리한 포스팅이니, 가벼운 마음으로 봐주시면 감사하겠습니다.
AI 기술이 지속적으로 발전하면서, AI 윤리에 대한 이야기가 계속 강조되고 있습니다.


가령 왼쪽 사진은 생성형 AI가 만든 가짜 이미지인데요. AI가 만든 펜타곤 근처 폭발 사고 이미지 때문에 미국 증시도 하락한 사건이 있었습니다. 또한, 오른쪽은 요즘 우리나라 뿐만 아니라 각 나라에서 집중하고 있는 선거 때문에 만들어진 영상입니다. 이도 AI가 만들었으며, 이를 통해 허위 정보를 전달할 수 있는 가능성이 보여지는 것이죠.

좀 옛날이긴 하지만, 구글 포토(Google Photo)가 만든 윤리적 이슈도 있었습니다. 어떤 사람이 가지고 있는 사진 중 흑인 친구를 구글 포토가 고릴라로 인식한 사건입니다. 이렇게 AI의 사소한 실수로 인해 자칫 사회적 문제나, 기업의 문제, 서비스의 문제가 발생할 수 있습니다.
이런 상황에서 과연 우리의 서비스는 안전할 수 있을까요?

그것 외에도 다양한 AI윤리적 문제가 발생할 수 있습니다. 남녀차별, 인종, 세대, 소득 등 다양한 방면에서 윤리적 문제가 발생할 수 있죠.
이런 문제는 왜 발생하게 될까요? 다양한 문제가 발생할 수 있지만, AI개발자의 시각에서 정리를 한 번 해보려고 합니다.

요즘 다양한 AI 서비스들이 나오고 있습니다. ChatGPT나 Gemini 등 다양한 LLM 모델들을 활용한 서비스가 나오고 있죠. AI 서비스들은 LLM 뿐만 아니라 멀티모달(Multi Modal) 등 다양한 모델들이 존재하지만 우리에게 친숙한 것은 LLM이니 먼저 LLM 기준으로 살펴보겠습니다. 최근 LLM의 근간이 되는 것은 2017년에 나온 Attnention is all you need라는 논문의 Transformer 구조입니다. 이 구조에서 BERT, GPT 등 다양한 모델들이 탄생하게 되었죠.


결국 이 NLP 모델들, LLM 모델들은 이 단어 다음에 어떤 단어가 나올 지 확률적으로 생성하는 모델들입니다. 그 확률적으로 나오도록 학습된 모델들이 자신의 task에 맞게 점점 더 고도화 되는 것이죠. 그 고도화 과정은 어떻게 이루어질까요?

먼저, Pretrain이라는 사전 학습 이라는 과정이 있습니다. 사전 학습이라는 것은 많은 데이터를 통해서 일반적인 언어를 사전에 학습하는 것을 의미합니다. 즉, 사전 모델을 미리 훈련하는 것이죠. 다음은 Fine-tuning 과정이 있습니다. 대화를 하는 언어 모델을 기준으로 생각해보면 fine-tuning 과정은 방대한 지식을 학습한 pretrain 모델을 사용해서 대화 방식을 배우는 과정이라고 보면 될 것 같습니다. 그 다음 RLHF라는 방법도 소개되는데요. 이는 대화 수준 향상을 위한 더 조리있게 학습하는 방법이라고 보면 됩니다. 이 과정에서는 보상 모델(강화 학습)을 활용해 사람의 피드백을 반영하는 과정입니다. 모델이 생성한 문장이 좋을수록 더 보상을 주어서 좋은 문장이 나오도록 하는 것이죠.

자연어 처리 모델은 위 사진과 같이 예전에 정말 많이 사용했던(저도 많이 사용했었던) word2vec, FastText부터 시작해 BERT 계열은 BERT, RoBERTa, ALBERT, DilstilBERT 등이 연구가 되었었습니다. GPT 계열은 GPT-1, GPT-2, GPT-3, InstructGPT, ChatGPT등으로 확장되었고 요즘 핫하고 3.1까지 나온 Meta의 LLaMA 모델들, 구글의 PaLM 모델 등 다양한 모델이 확장되고 연구되고 있습니다.
근데 AI 윤리 얘기하는데 도대체 이 모델의 진화와 발전을 왜 얘기하냐구요? 바로 이 모델을 훈련하는 것이 AI 윤리적인 관점에서 주목해야 할 지점이라고 생각하기 때문입니다.
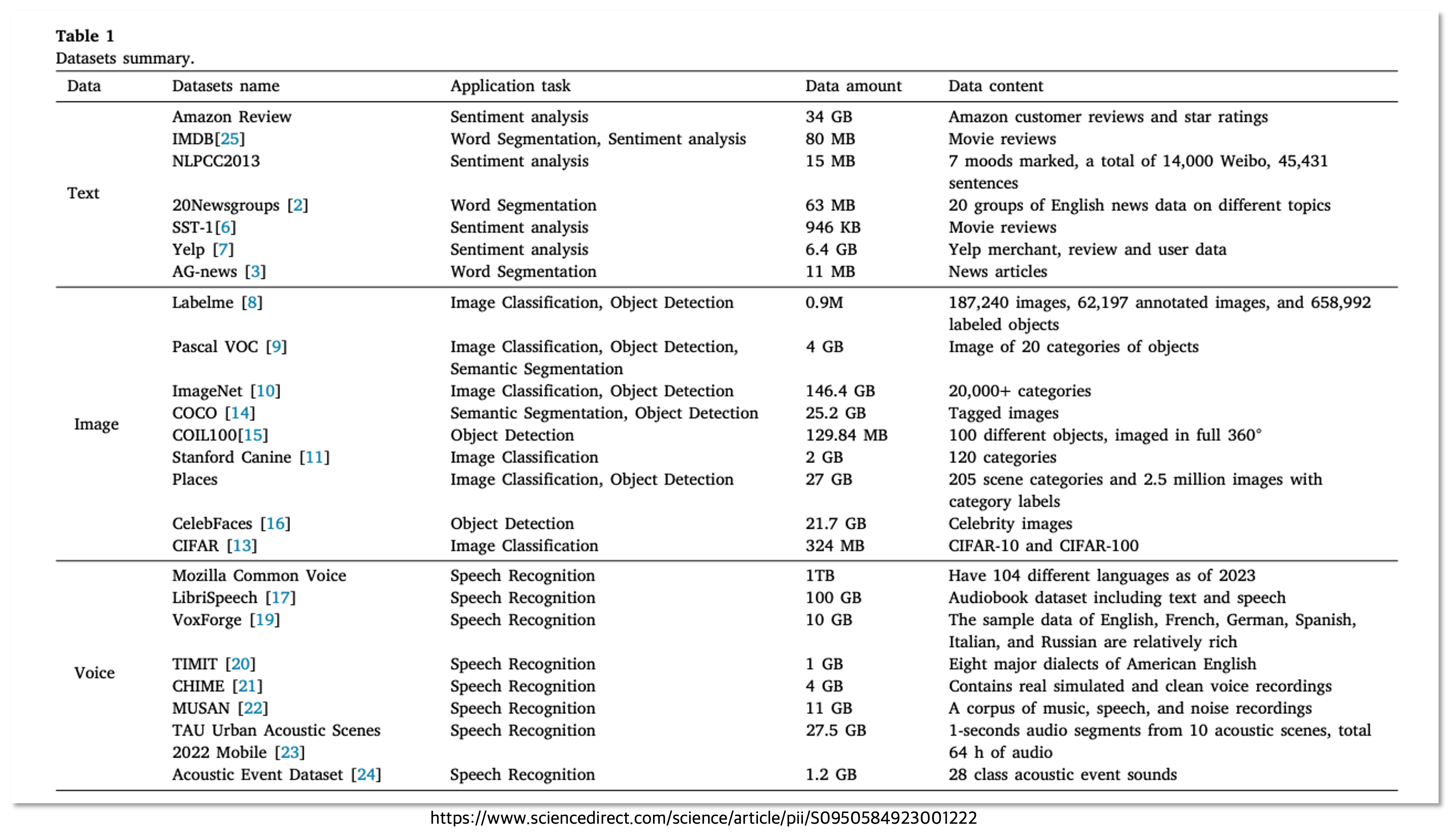
AI 모델은 결국 데이터로 훈련합니다. 근데, 이 데이터는 어떤 데이터일까요? 위 표에서 보면 Amazon review, IMDB 와 같은 데이터를 사용한 것을 알 수 있습니다. 이것 뿐만 아니라 다양한 데이터를 LLM이 학습하게 됩니다. 근데 이 데이터가 과연 정제되어 있는 깔끔한 데이터일까요? 과연 밸런스가 갖추어진 데이터일까요?

전통적인 데이터나 소셜 데이터, 글로벌 관점에서 보았을 때 밸런스가 잘 갖추어지지 않았거나, 정제되어 있지 않은 데이터가 반영될 수 있습니다. 요즘 시대는 굉장히 빠르게 변화하고 있습니다. 그렇기에 불과 몇 년전에 만들어진 데이터와 지금의 데이터는 관점이 많이 바뀔 수 있는 것이죠. 그러므로 세대갈등, 남녀갈등, 비윤리적 용어 등이 섞여져 있을 가능성이 높다고 생각합니다.(계속 언급하듯, 이것은 지극히 개인적인 생각입니다.) 만약, 이런 데이터를 사용해서 LLM 모델들이 학습을 하게 된다면, 당연히 윤리적인 이슈가 발생할 수 있을 것입니다.
물론 요즘 이런 데이터를 굉장히 잘 관리하려고 노력도 많이하고 데이터의 중요성에 대한 강조도 오래되어서 계속 발전할 것이라고 생각합니다.
그런데 이게 과연 LLM에서만 문제점이 될까요? 멀티 모달을 사용하게 되면 음성, 이미지 등으로 데이터 확장될탠데 이럴 때는 어떻게 될까요? 그리고 다른 AI 서비스들은 어떨까요?

저는 추천 시스템, 개인화 시스템을 많이 연구했습니다. 추천 시스템에서도 이런 윤리적인 문제가 발생할 수 있습니다. 제가 2023년도에 진행한 유데미 큐레이션 프로젝트를 진행할 때도(이때 기획 리딩을 해주신 분이 AI 기획자 Day를 주최하신 대장님이십니다.) 이런 고민을 정말 많이 했었습니다.
추천 시스템 입장에서는 고객이 좋아하는 것을 계속 노출시켜서 클릭이 많이 발생하도록 하는게 좋습니다. 그러나, 이게 AI 서비스를 개발하는 제 입장에서는 과연 이게 UX 관점에서 좋을까?라는 고민을 많이 했었죠. 고객이 선호하는 것만 제공하면 편향(bias)가 생길거니까요. 그래서 제가 이 자료를 발표한 AI 기획자 Day를 주최하신 리더님과 당시 이 고민에 대해 많이 이야기 나눴었습니다.

유데미 큐레이션 프로젝트에서는 크게 5가지 스텝으로 동작되었습니다. 1. 사용자 이력을 수집하고 2. 사용자 선호도 및 AI를 활용한 각종 메타 추출 3. 선호도 기반 후보 아이템 추출 4. 다양한 관점의 데이터 셋 추가 추출 5. Re-Ranking 작업입니다.

이때, 가장 중요하게 생각한 것이 바로 사용자 이력 부분입니다. 이 사용자 이력에서 윤리적인 이슈가 발생하지 않도록 데이터 로깅 설계를 어떻게 할 것인가를 많이 고민했었죠.
어떤 데이터를 수집할까? 개인정보는 없을까? 편향된 데이터가 발생할 수 있는가? 등 다양한 관점에 대해서 고민하면서 데이터를 수집했습니다. 이 단계 뿐만 아니라 두 번째 단계에서도 사용자 선호도를 추출할 때 다시 재검토를 수행하는 방향으로 개발을 진행했었습니다. 그리고 AI를 활용한 데이터를 추출 할 때도 이상한 데이터가 생성되지 않는지 검토했었죠.
이렇게 제가 진행한 추천 시스템 영역에서도 AI 윤리적으로 문제가 발생할 수 있는지 데이터 레벨에서, 개발적인 관점에서 고민 또 고민했었습니다. 그래야 사용자에게도 우리 서비스에게도 피해가 발생하지 않은 안전한 AI 서비스가 될태니까요!


요즘 검생 증강 생성(Retrieval-Augmented Generation, RAG) 기술도 굉장히 핫합니다. RAG를 사용하는 다양한 이유가 있겠지만, 저는 AI 윤리적인 이슈를 고려하기 위함도 어느정도 있지 않을까 싶습니다. 그래야 LLM이 이상한 소리를 안하고(할루시네이션이 안 나오고) 올바른 대답을 할태니까요. RAG를 구축할 때 프롬프트(Prompt)를 CoT 방법으로 사용할까 등등도 성능을 올릴려는 측면도 있지만, 이렇게 함으로써 신뢰도를 향상시킬 수 있지 않을까 싶습니다.

그리고 Lost in the middle과 같은 연구를 보면 LLM은 아직 불완전성 요소가 많이 남아 있는 것 같습니다. 그러니 더더욱 AI 윤리적인 것을 고민해야겠죠. 만약, 우리가 fine-tuning 과정을 통해서 sLLM을 만들거나 할 때도 우리 데이터에 비윤리적인 데이터가 있는지 검토할 필요가 있는 것입니다. 그래야 LLM이 올바르게 동작할 확률이 높아지지 않을까요?

요즘 AI data에 보면 큰 특징이 하나 있습니다. 예전에는 빅데이터(Big data), 딥러닝(Deep Learning), 머신러닝(Machine Learning), 데이터 사이언스, 텍스트 분석, 피처 엔지니어링(Feature Engineering) 등이 크게 있었습니다. 하지만, 어느순간부터 Ai Ethics라는 것이 생겼습니다. 위 그림에서 왼쪽 상단에 보면 AI 윤리가 자리잡고 있죠. 그만큼 이제 AI와 데이터에서 AI 윤리도 하나의 중요한 측면으로 자리잡게 되었다는 것을 의미하는게 아닐까 생각합니다.

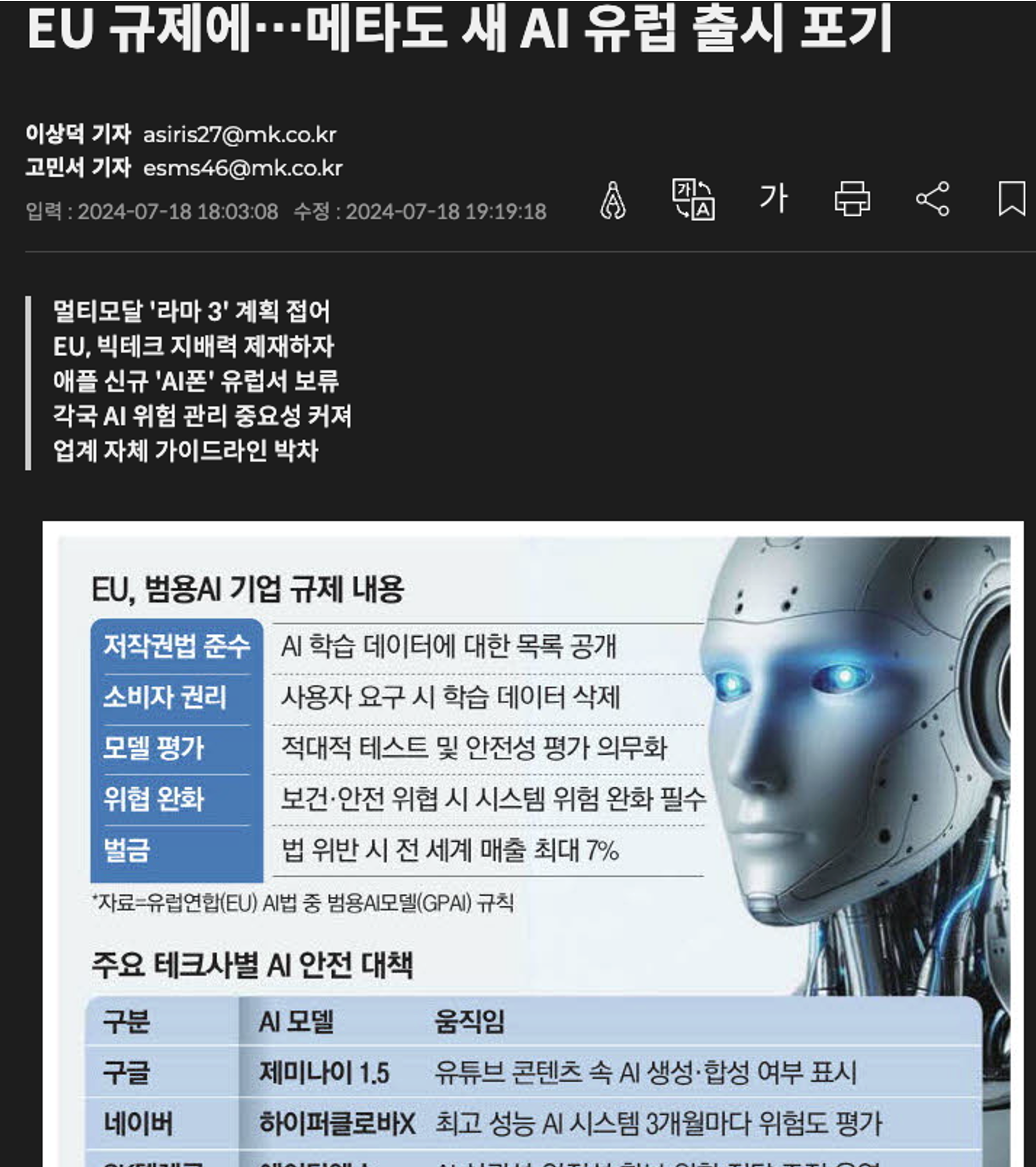
AI 윤리에 대해서 이제 각국의 규제나 표준이 만들어지고 있습니다. 우리나라 방송통신위원회에서도 생성형 AI 윤리 가이드라는 것이 나왔고 EU는 특히 정밀하게 윤리적인 것을 규정하고 있습니다. 이걸 지키지 못하면 서비스를 출시할 수도 없죠.

그럼 AI 윤리는 데이터에서만, 모델 관점에서만 주의해야할까요? 저는 그렇게 생각하지 않습니다. 아무리 데이터가 잘 정제되고 잘 서비스가 나가도 사용자들이 악용하면 문제가 발생하게 될 수 있습니다. 그리고 국가나 기관에서도 다양한 교육이나 표준화 작업 등을 통해서 AI 윤리에 대한 프로세스를 만들어야 할 것입니다.
그리고 저와 같은 개발자나, AI 기획자 Day에 참석해주셨던 분들과 같은 기획자 등 서비스에 기여하는 모든 사람이 AI윤리에 대해 같이 고민하고 힘써야 할 것입니다.
이 과정을 통해서 더 훌륭한 AI, 더 가치있는 AI 서비스가 나올 수 있지 않을까요? 저는 그렇게 기대하면서 포스팅 마무리 하겠습니다.
마무리
본 포스팅은 AI 기획자 Day에서 발표한 AI 윤리에 대해서 AI 개발자의 관점에서 정리해본 포스팅입니다.
지극히 개인적인 관점의 포스팅이니, 틀렸다면 피드백주시고 가르침을 주시면 감사하겠습니다.
그리고 이 날 발표한 전체 자료는 아래에 첨부합니다!
부디 도움이 되시길 바라겠습니다.
긴 글 읽어주셔서 감사합니다.
저에게 연락을 주시고 싶으신 것이 있으시다면
- Linkedin : https://www.linkedin.com/in/lsjsj92/
- github : https://github.com/lsjsj92
- 블로그 댓글 또는 방명록
으로 연락주세요!