
OpenAI GPT Fine-Tuning(파인튜닝) 방법 정리 - 나만의 GPT 모델 만들기
포스팅 개요
최근 OpenAI의 ChatGPT가 각광을 받으면서 대규모 언어 모델(LLM, Large Language Model)이 주목 받고 있습니다. 이전 포스팅에서는 이러한 LLM 모델, 그 중 chatgpt의 전신이 되는 gpt3.5를 활용하기 위해서 openai의 api를 활용해 간단한 파이썬 예제(Python example)을 살펴보았는데요. 하지만, 모델을 사용하는 입장으로 파인튜닝(Fine-tuning) 과정이 필요할 때가 있습니다. 이번 포스팅에서는 OpenAI의 GPT 계열 모델을 어떻게 Fine-tuning해서 사용하는지 정리해봅니다.
ChatGPT API가 공개 되었습니다!
해당 포스팅을 작성한 지 1주가 지난, 3월 2일 chatgpt api가 공개 되었습니다. 본 포스팅은 gpt3.5 기준이므로, 꼭 참고해주세요!
chatgpt api 소개 : https://openai.com/blog/introducing-chatgpt-and-whisper-apis
이전 포스팅은 아래와 같습니다.
Python OpenAI API를 활용해 GPT3(GPT3.5) 사용하기(Feat. ChatGPT)
포스팅 개요 최근 OpenAI chatGPT가 각광을 받으면서, 저도 ChatGPT에 대해서 관심이 많아졌습니다. 이미 OpenAI에서 GPT 계열의 모델들은 API를 제공해주고 있고 그 중 ChatGPT의 전신이 되는 GPT3.5의 버전의
lsjsj92.tistory.com
chatgpt와 추천 시스템을 결합한 포스팅도 추가했으니, 관심 있으신 분들께서는 참고바랍니다
제가 본 포스팅을 작성하면서 참고한 자료는 다음과 같습니다.
- https://beta.openai.com/docs/models/gpt-3
- https://openai.com/blog/gpt-3-apps/
- https://platform.openai.com/docs/guides/fine-tuning
본 포스팅에 있는 코드들은 아래 github repository에서 확인할 수 있습니다.
GitHub - lsjsj92/openai-tutorial: openai-tutorial
openai-tutorial. Contribute to lsjsj92/openai-tutorial development by creating an account on GitHub.
github.com
포스팅 본문
이번 포스팅은 OpenAI에서 제공해주는 GPT 모델을 제가 원하는 형식 또는 데이터에 맞게 Fine-Tuning하여 나만의 GPT model을 구성하는 과정을 정리합니다. 위에서도 언급하였지만, 글 작성후 OpenAI에서 ChatGPT API를 공개하였습니다. 본 포스팅은 ChatGPT가 아닌, GPT3 기준으로 작성되는 것을 다시 명시합니다!
Fine-tuning을 진행하는 본격적인 본문에 앞서, 왜 Fine-tuning 과정이 필요한지 예시를 살펴보면서 글을 시작해보겠습니다.
1. 일반적인 GPT Model에서의 예시 - 왜 Fine-tuning이 필요한가?
지금도 충분히 ChatGPT가 각광 받고 있는 모습을 보면 이미 GPT 계열의 모델 성능은 매우 뛰어난 것이라고 말할 수 있습니다. 그런데, 그럼에도 일반적으로 파인튜닝(Fine-tuning)이라는 과정을 종종 활용하게 되는데요. 왜 이 Fine tuning 과정이 필요할까요? 아래 사진을 먼저 보겠습니다.

지난 포스팅에서 작성한 GPT3.5 모델, text-davinci-003 모델을 기준으로 위와 같이 테스트를 해보았습니다. text-davinci-003 모델은 chatgpt의 전신인 gpt3.5를 기준으로 만들어진 모델입니다. 이 모델에게 " 웃으면서 말해줘. 너의 이름은? " 이라고 물으면 그냥 이름만 답하는 것을 볼 수 있습니다.
한 가지 예시를 더 볼까요?
위 예시에서는 " 2022년 롤드컵 우승 팀은? "이라고 물어봤습니다. 그리고 모델의 결과는 '잘 모르겠습니다." 라는 답이 나오죠. ChatGPT에서 사용한 데이터는 2021년까지라고 들어보셨을겁니다. 즉, GPT3.5 davinci-003 모델은 2021년까지의 데이터만 학습되어 있는 상태입니다. 그래서 2022년도에 대한 답을 하지 못하는 겁니다.
그래서! 우리는 fine-tuning 과정이 필요합니다. 해당 답을 알려주기도 하고, 아니면 내가 원하는 format으로 답이 나오도록 유도할 수 있도록 말이죠.
2. OpenAI GPT Fine-tuning 진행하기
본 포스팅에서는 제가 원하는 format으로 gpt 모델이 응답할 수 있도록 모델을 fine-tuning하겠습니다. OpenAI에서 제공해주는 GPT 모델을 Fine-tuning 하려면 다음과 같은 프로세스가 필요합니다.
1. 데이터 준비 (format 맞추기)
2. 모델 생성
3. 모델 활용
2-1. 데이터 준비
가장 먼저, 모델을 파인튜닝 하기 위해 데이터를 준비해줘야 합니다. Openai의 Fine-tuning 공식 document를 보면 아래 사진과 같이 설명이 되어 있습니다.
즉, Fine-tuning을 위해 다음과 같이 데이터를 준비합니다.
- JSONL 형태의 데이터
- 파일 안에는 prompt, completion의 형태로 구성
- prompt에는 원하는 프롬프트 구성
- completion은 원하는 답 형태 구성
저는 Fine-tuning을 위해 데이터를 다음과 같이 구성해 준비했습니다.
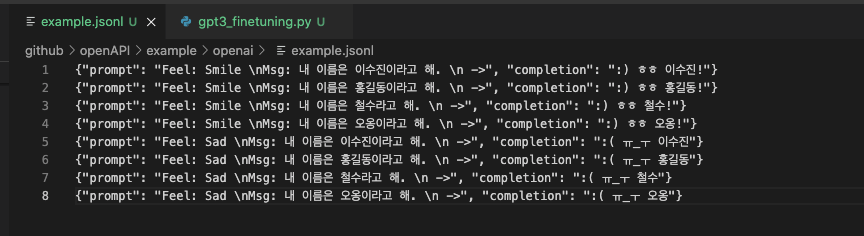
example.jsonl이라는 파일을 만들고 그 안에 위 사진과 같이 데이터를 구성했습니다. 그 특징은 다음과 같습니다.
- prompt에는 Feel : 로 시작하게 하였고 그 뒤에 바로 감정이 나오도록 설정
- Msg에는 내 이름은~ 으로 나오도록 설정
- prompt의 끝은 -> 로 끝나도록 설정
- completion은 각 감정에 따라 " :) " 또는 " :( "이 나오도록 하고 이름이 나오도록 설정
즉, 제가 처음에 보여드렸던 GPT3 모델이 응답하지 못한 예제의 형태가 나오도록 데이터를 구성하였습니다.
이렇게 생성한 데이터를 이제 다음과 같은 명령어로 Fine-tuning 할 수 있도록 데이터를 생성해줍니다.
openai tools fine_tunes.prepare_data -f example.jsonl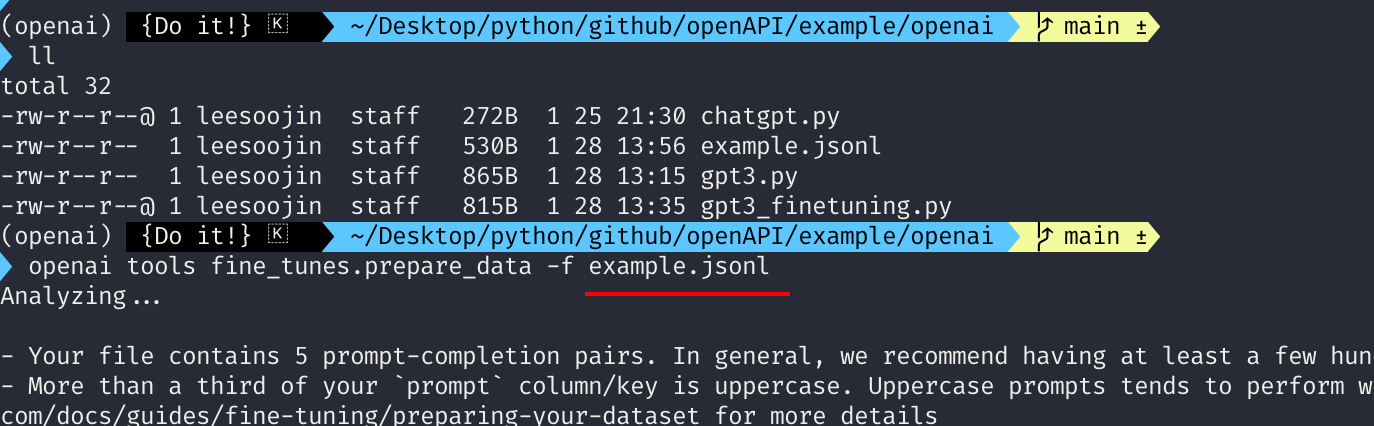
이렇게 명령어를 입력하면, 위처럼 example.jsonl 파일을 읽어서 fine-tuning을 위한 데이터 생성 준비에 들어갑니다. 이때 나오는 설명 텍스틀 살펴보면 아래와 같이 특징을 살펴볼 수 있습니다.
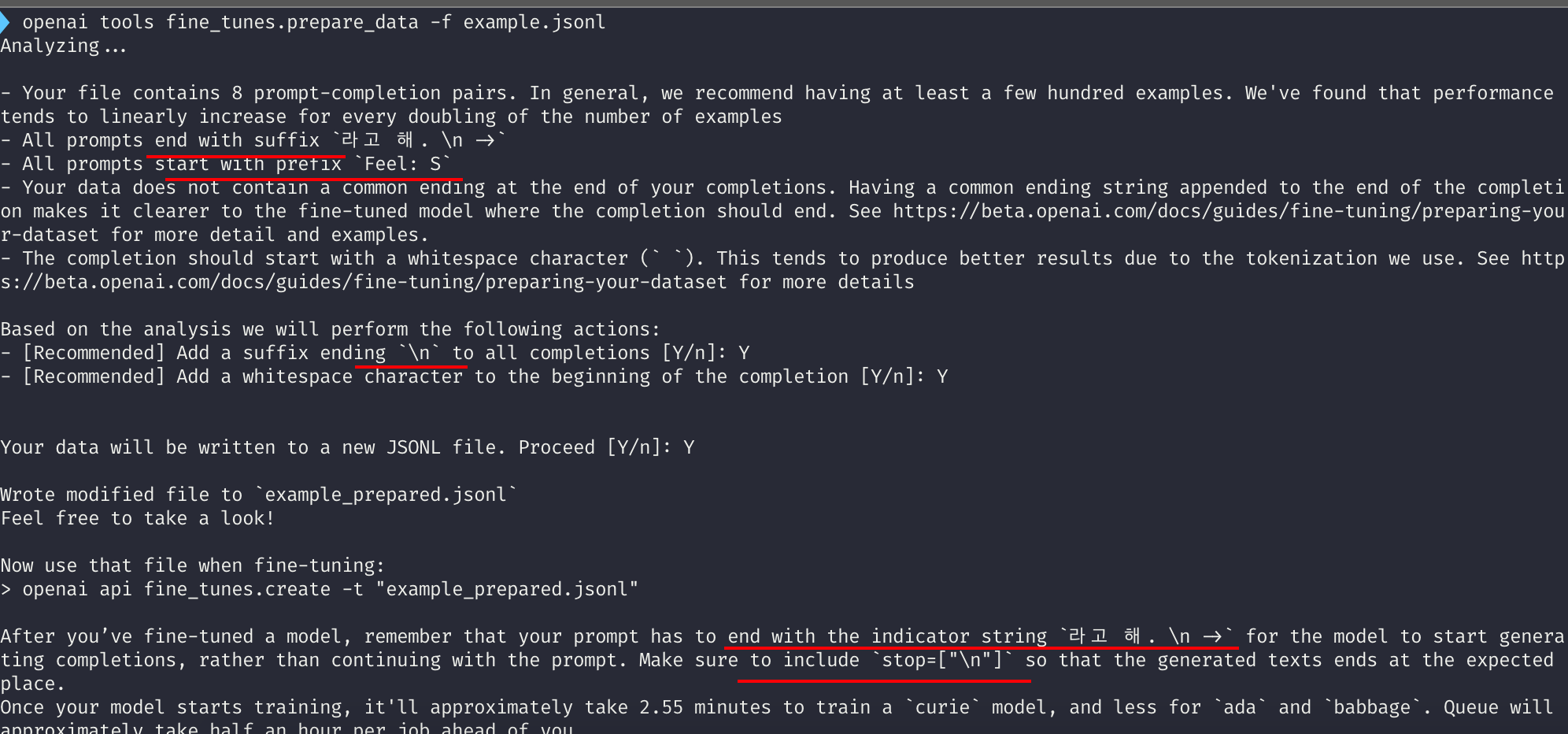
- All prompts는 " 라고 해. \n -> "로 끝난다
- 모든 prompts는 " Feel : " 로 시작한다.
- suffix ending을 \n으로 하려고 하는데(추천) 동의? -> Y
- stop=["\n"]으로 해두세요
등등 다양한 정보를 알려줍니다. 이것만 봐도 나중에 생성된 모델을 어떻게 사용하면 될 지 충분한 힌트를 얻을 수 있습니다.
이제 위 명령어가 끝나면 아래와 같이 하나의 파일이 더 생성되는 것을 확인할 수 있습니다.
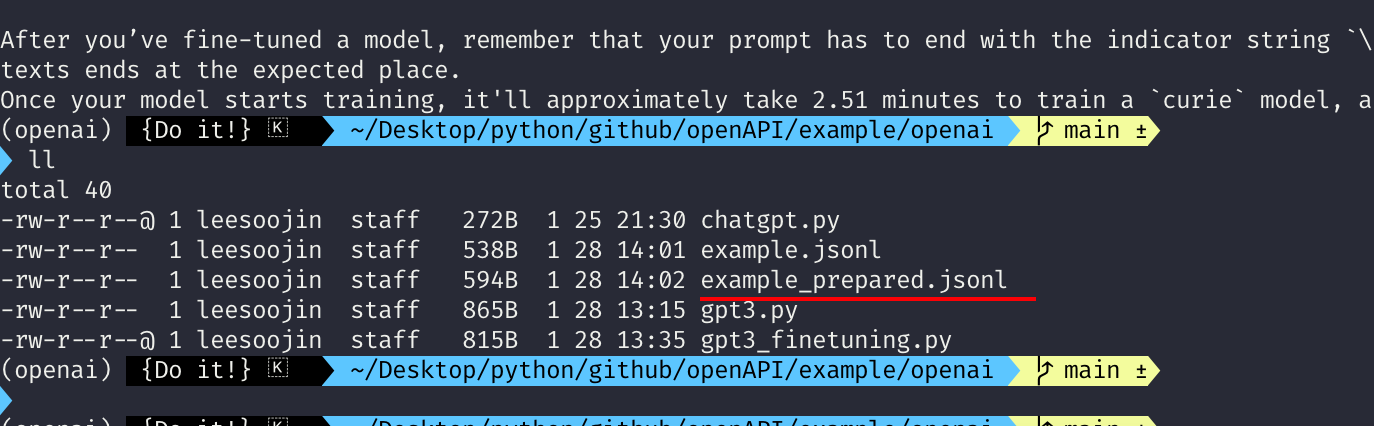
파일명은 prepared.jsonl 이며 fine-tuning에 활용할 수 있도록 준비된 데이터라고 볼 수 있습니다.
2-2. Fine-tuning 모델 생성
Base model
이제, 본격적으로 Fine-tuning을 진행합니다. Fine-tuning을 할 수 있는 모델은 openai에서 제공하는 base model을 활용할 수 있습니다. base model은 아래와 같이 소개되고 있습니다.

즉, ada, babbage, curie, davinci 모델을 활용해야합니다. davinci-003과 같은 형태가 아닌, davinci 그 자체를 활용해야하죠. 만약, 이 모델을 활용하지 않고 davinci-003과 같은 모델을 사용하겠다고 구성하면 아래와 같은 에러 메세지를 받게 됩니다.
Error: Invalid base model: text-davinci-003 (model must be one of ada, babbage, curie, davinci) or a fine-tuned model created by your organization: o (HTTP status code: 400)
Key setting
또한, Fine-tuning은 OpenAI의 Key를 이용해서 진행해야하고 Fine-tuning 과정을 거치면 요금이 부과됩니다. 따라서, 시스템적으로 OpenAI key를 셋팅해야 합니다. 만약, 셋팅을 하지 않으면 다음과 같은 에러를 겪게 됩니다.
Error: No API key provided. You can set your API key in code using 'openai.api_key = <API-KEY>'
Error: No API key provided. You can set your API key in code using 'openai.api_key = <API-KEY>' 즉, openai.api_key에 API key를 셋팅하라는 메세지입니다. 먼저, 기본적으로 Fine-tuning을 위해 다음과 같이 명령어를 입력해야 하는데요.
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>이 상태 그대로 입력하게 되면 위 에러 메세지를 받게 될 것입니다. 따라서, OpenAI의 GPT Fine-tuning을 위해서는 아래와 같이 명령어를 구성해서 보내야 합니다.
openai --api-key YOUR_KEY api fine_tunes.create -t example_prepared.jsonl -m davinci즉, --api-key에 여러분들의 OpenAI api key를 넣어주고 fine_tunes.create -t 옵션에 만들었던 jsonl 파일 그리고 -m 옵션에 base model을 넣어줍니다. 저는 davinci로 계속 base model로써 활용하겠습니다. 위 명령어를 입력하면 다음과 같이 결과가 나오는 것을 확인할 수 있습니다.
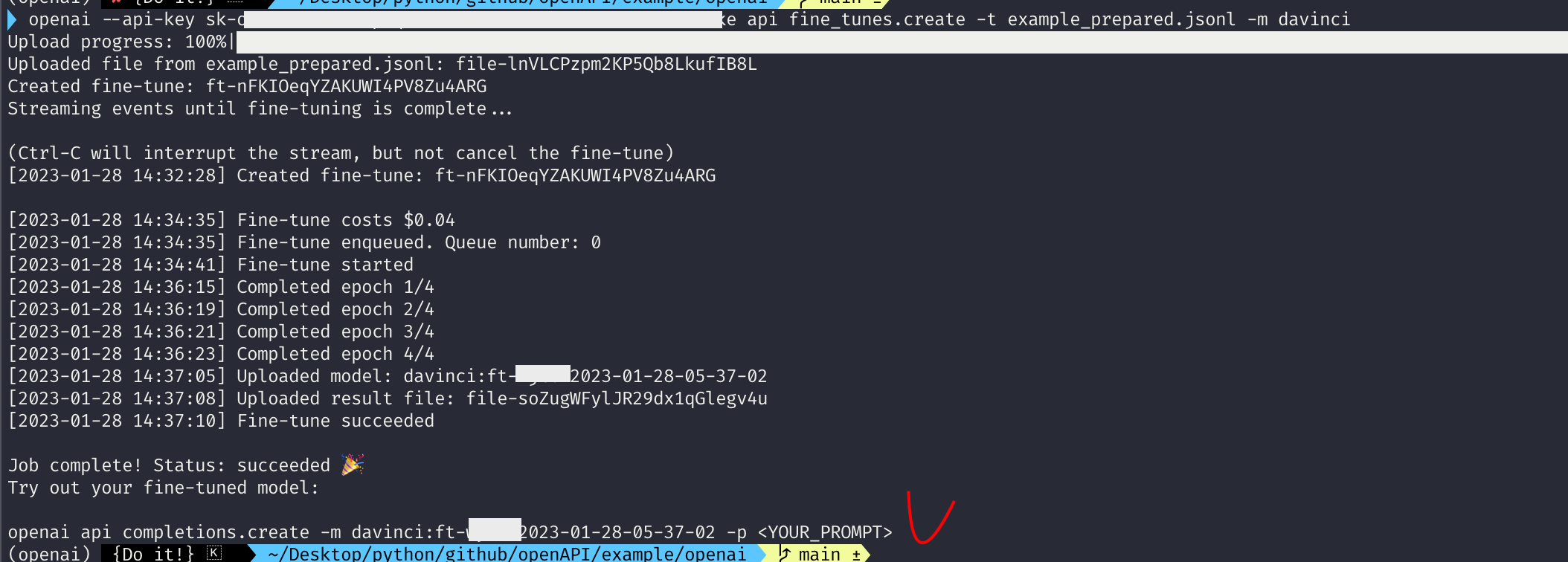
위 결과를 자세히 보면 fine-tune costs 도 나오는 것을 확인할 수 있습니다. 즉, 파인튜닝 할 때 가격 값도 나오게 되죠. 이상없이 fine-tuning이 잘 되면 마지막에 openai api completions.create 라고 나오면서 모델 이름이 나오는 것을 확인할 수 있습니다.
이렇게 하면 fine-tuning 과정은 종료됩니다.
2-3. Fine-tuning 모델 사용
위처럼 Fine-tuning 과정이 종료되면, OpenAI 내 계정 정보에 다음과 같이 Fine-tune training 정보가 나오는 것을 확인할 수 있습니다.
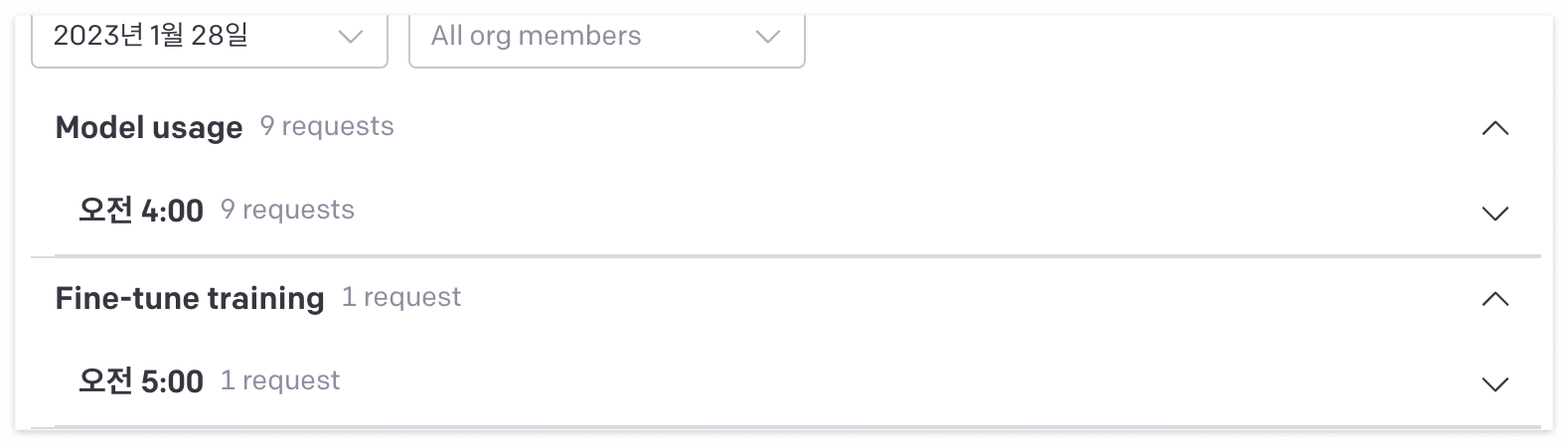
또한, OpenAI의 playground에 들어가게 되면 제가 만든 Fine-tuning model도 확인할 수 있고 이 모델을 직접 사용해볼 수도 있습니다.
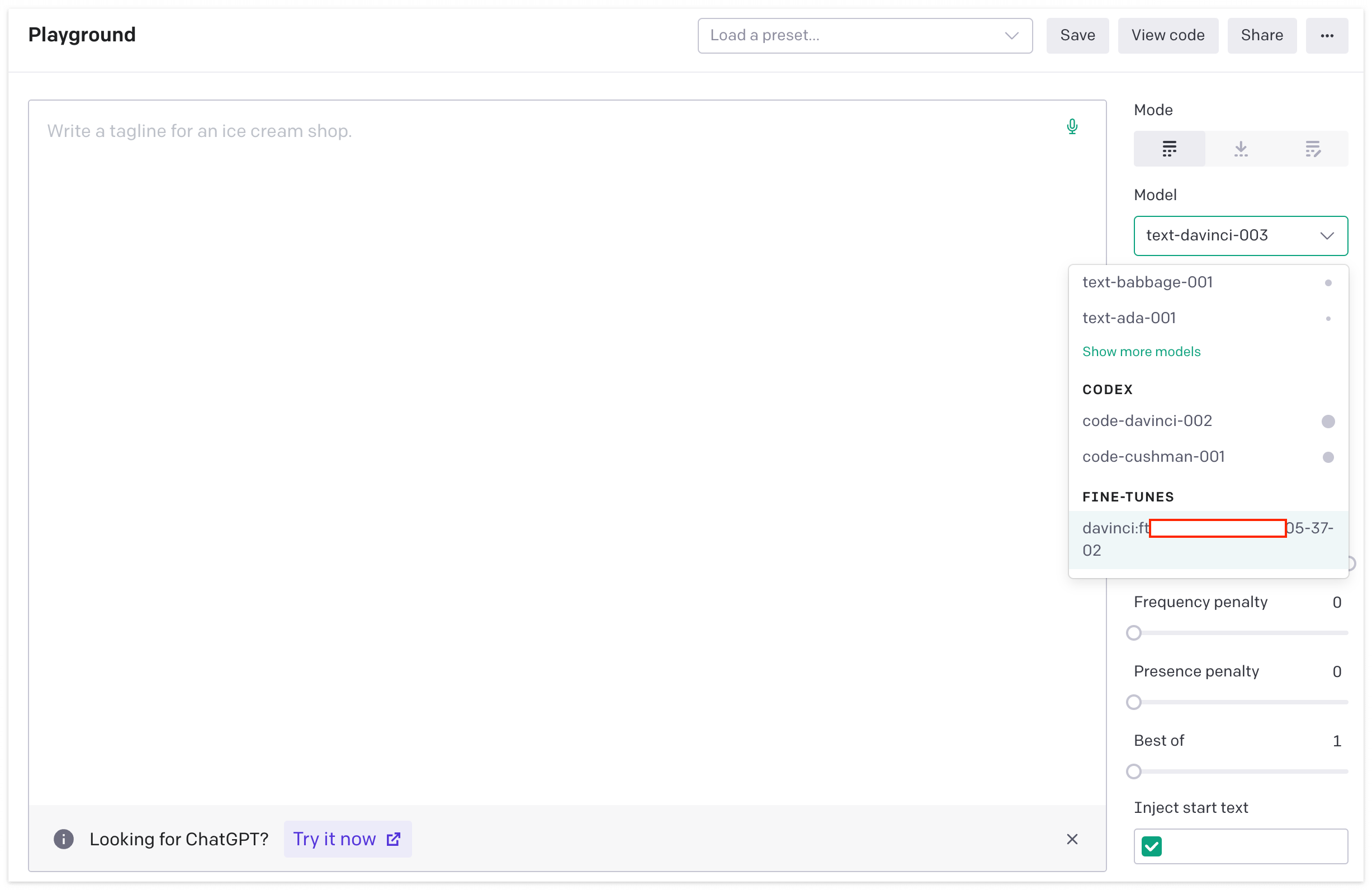
그럼 실제로 Fine-tuning 과정이 잘 되었는지 결과를 살펴볼까요?
이전 포스팅에서 작성한 Python 코드를 모델 명만 바꿔서 진행해봤고 Playground에서도 fine-tuning 모델을 직접 활용해봤습니다.

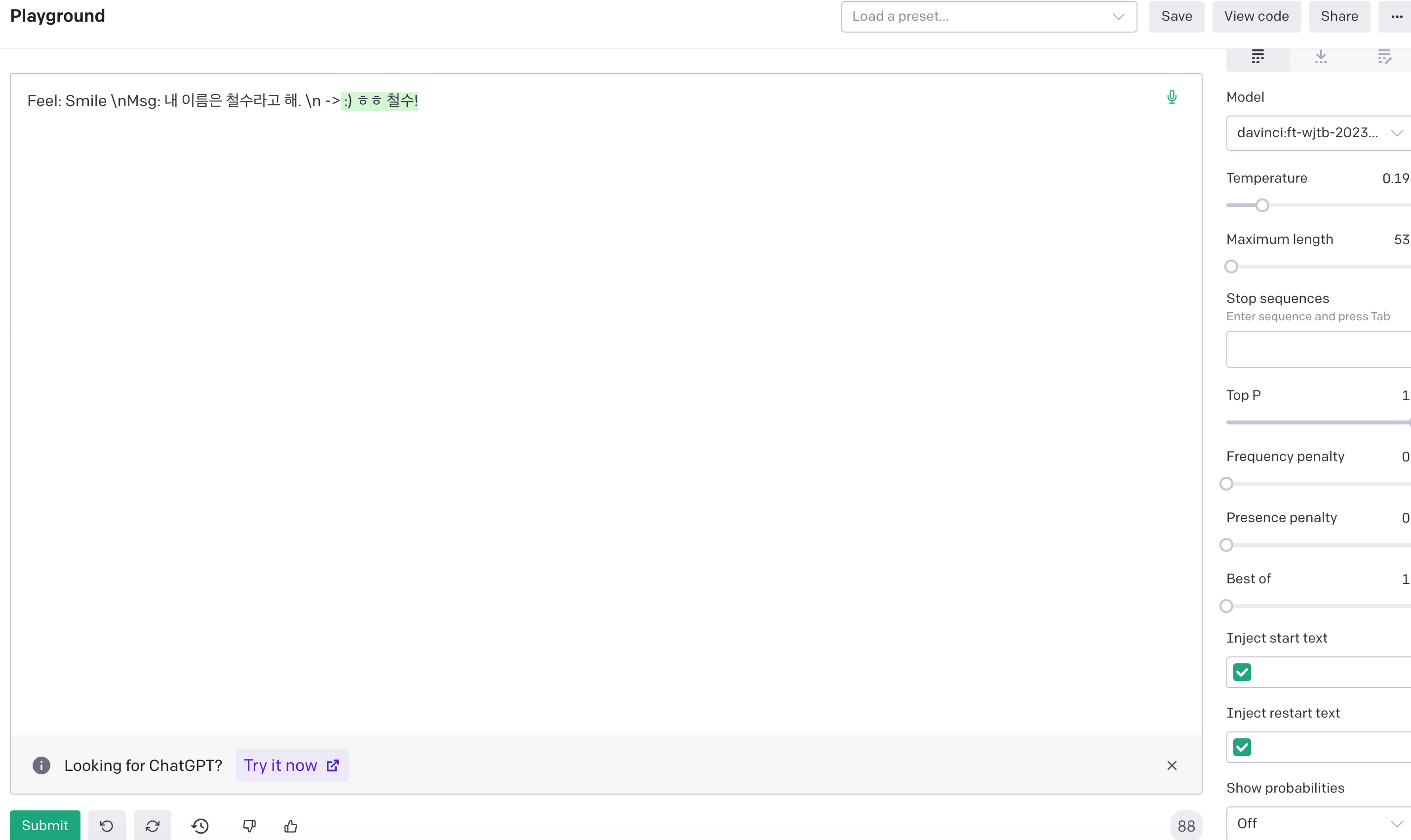
제가 훈련을 시켰던 형태로 나오는 것을 확인할 수 있습니다!
마무리
본 포스팅에서는 OpenAI GPT 모델을 활용해 나만의 Fine-tuning 모델을 만드는 과정을 정리하였습니다. Fine-tuning에 필요한 과정과 나올 수 있는 에러에 대한 대처 등을 정리하였고 의도되로 훈련이 되어 결과가 나오는 것도 확인하였습니다.
chatgpt가 대세인 요즘, 이런 fine-tuning 과정으로 내가 필요로한 model을 만들어보는 것은 어떨까요?
추후 OpenAI에서 공개한 ChatGPT도 여유가 될 때 올려보겠습니다.
---> 추천 시스템과 chatgpt를 결합한 내용을 올려두었습니다. ( https://lsjsj92.tistory.com/m/657 )
긴 글 읽어주셔서 감사합니다.
저에게 연락을 주시고 싶으신 것이 있으시다면
- Linkedin : https://www.linkedin.com/in/lsjsj92/
- github : https://github.com/lsjsj92
- 블로그 댓글 또는 방명록
으로 연락주시면 감사하겠습니다.