AI 팀, 추천 시스템 프로젝트로 마무리하는 2020년 회고와 2021년 목표
2020년을 마치며
어느덧 2020년이 끝났다. 전반적으로 굉장히 많은 일이 있었고 그 중심에는 코로나 바이러스가 있었던 한 해였다. 하지만, 개인적으로는 코로나에 영향을 크게 안 받은 것 같고 안 좋은 것보단 득을 많이 봤던 한 해였던 것 같다.
2020년은 AI팀원으로 마무리를 지었고, 12월 28일 다니고 있던 회사를 퇴사했다. 그래서 이번 회고 제목에 AI팀 이라는 키워드를 넣었고 메인 프로젝트가 추천 시스템 프로젝트이었기에 추천 시스템 프로젝트로 마무리하는 2020년이라고 지었다. (작년 회고를 보니까 Data Science로 마무리하는 ~ 이었는데 1년이 지난 지금은 AI팀으로 바뀌었다)
나의 2020년을 요약하면 아래와 같이 될 것 같다. (기술적인 면을 위주로 적었다. 개인적으로 일어난 일들은 최대한 제외했다)
- 2020년 초, 처음으로 추천 시스템 프로젝트 시작 및 프로젝트 중단
- 임시 팀장 역할과 팀 매니저 역할 병행
- 부서이동 및 AI 팀으로 최종이동
- 하반기에 다시 한 번 추천 시스템 프로젝트 진행 ( 2020년 초에 진행한 추천 시스템 프로젝트보다 더 규모가 있고 적절한 프로젝트 ) 및 마무리
- 모두의연구소에서 풀잎스쿨 추천 시스템 스터디 리더 진행(12기, 13기 총 22주) 및 마무리
- 여러 발표 기회
- 퇴사 및 이직
- 야간대학원
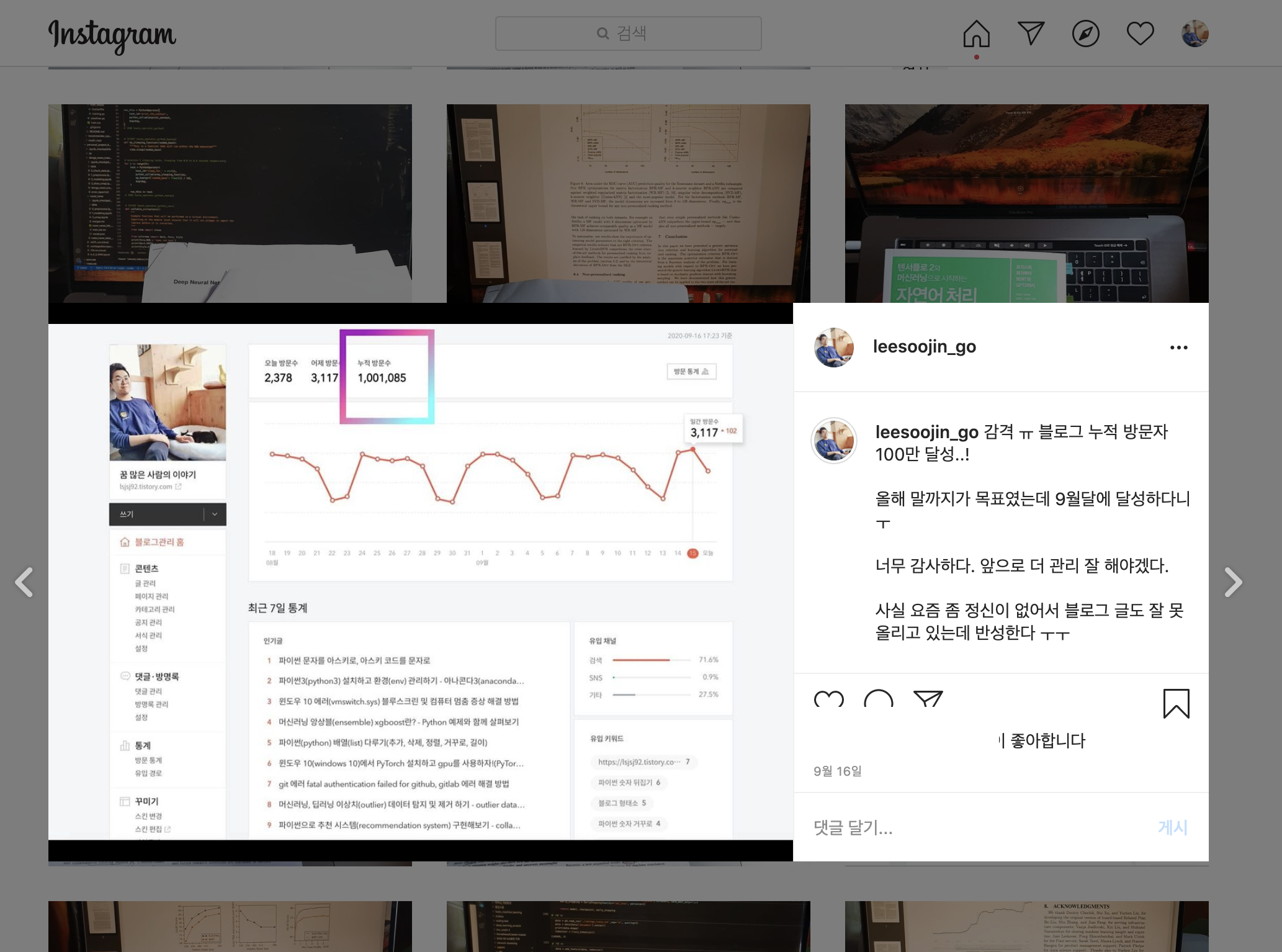
- 블로그 누적 방문자 수 100만 달성블로그 일 방문자수 3천명 이상 달성
어떤 것을 배울 수 있었나?
2020년도에는 다양한 것을 배울 수 있었다. 많은 것을 보고 느꼈다. 그 중 올 한해 아래와 같은 것을 많이 배운 것 같다.
- Data 조직이 실패하는 이유와 Data 조직이 어떻게 성장해야 하는가?에 대한 고민
- 추천 시스템의 전반적인 기술적인 개요와 시장 상황
- 자연어처리에 대한 이론 및 기술적인 이해(ELECTRA, GPT-3까지 읽었다)
- 논문을 어떻게 읽어야하고 왜 읽어야 하는지
이번 회고는 크게 위 4가지로만 정리하고자 한다.
Data 조직이 실패하는 이유와 어떻게 성장해야 하는가에 대한 고민
이 고민은 프로젝트가 두 번 정도 실패하는 모습을 보면서 그리고 옆의 AI Research 팀의 모습과 내가 속해있던 Data Science팀의 모습을 보면서 다양한 관점으로 고민해 볼 수 있었다. 그리고 외부에서 사업가 마인드의 가진 분들과의 대화를 통해서 그 분들의 생각과 사고 방식이 우리 엔지니어들과 어떻게 다른지 1%나마 느낄 수 있었다.
Data 조직이 어떻게 해야 성장할 수 있는가? 참 어려운 이야기이다. 그리고 해답이 있다라고 말하기도 어려울 것 같다. 하지만 데이터가 점점 더 중요해지고 이 Data를 활용해 회사를 더 발전시키위해 Data를 활용하는 조직은 수동적인 조직이 아닌 능동적인(더 나아가서 공격적인) 조직이 되어야 할 것임을 많이 느꼈다.
무엇보다 비즈니스 임팩트를 어떻게 보여줄 것인가에 대해서도 깊게 고민해볼 필요가 있을 것 같다. 자세한 것은 블로그에 적을 수 없는 내용이지만, 이런 여러가지 요인들을 고민하면서 Data 조직이 왜 실패하게 되는지 그리고 어떻게 성장해야 하는지를 많이 고민해봤던 것 같다.
추천 시스템의 전반적인 기술적 개요와 시장 상황
아마 가장 많이 배웠던 부분이지 않을까 싶다. 무엇을 하며 많이 배울 수 있었나?
- 추천 시스템 프로젝트를 3번가량(프로젝트는 2개이지만, Phase로 따지면 3개) 진행하면서 자연스럽게 배울 수 있었다.
- 추천 시스템 스터디 리더를 5~6개월 동안 진행하면서 특히 많이 배웠다. 특히 다양한 분들과 논의와 질의응답을 하면서 다양한 도메인과 상황에 따른 이야기를 많이 들을 수 있었다.
- 추천 시스템 논문들 리딩


- 추천 시스템과 관련된 각종 아티클들 읽고 생각 공유해보기
이런 전반적인 것들을 진행하다보니까 자연스럽게 추천 시스템의 기술적 개요와 시장 상황에 대해서 이해할 수 있게 되었다. 이제 추천 시스템과 관련된 기초를 땐 것 같다.
자연어처리에 대한 공부
자연어처리 공부는 내가 따로 공부하고 싶어서 진행한 것이다. 추천 시스템은 프로젝트 + 내가 하고 싶어서 진행한 것이지만 자연어처리는 정말 순수하게 내가 해보고 싶어서 공부를 했다. 사실 공부하게 된 계기가 맨날 LSTM, RNN만 공부하고 그만두는 내 모습이 너무 싫어서 시작했다. Bert니 Transformer니 이런 모델과 이론들이 계속 나오고 발전해가고 있는데 나는 멈춰있는 것 같았다.
그래서 ELMo부터 논문을 읽기 시작했다. ELMo부터 Seq2seq, Transformer, BERT, GPT, RoBERTa, ALBERT, ELECTRA 까지 등 다양한 논문을 읽어보았다. 그리고 그 후기를 블로그에도 올려놓았었다.
왜 나는 자연어처리(NLP) 논문을 읽게 되었는가? - ELMO, Transformer, BERT부터 XLNet, ALBERT, RoBERTa, ELECTRA
포스팅 개요 이번 포스팅은 최근에 제가 읽게되었던 딥러닝 분야의 자연어 처리(NLP) 논문을 읽고난 후기입니다. 어떠한 계기로 자연어처리 논문을 읽게 되었는지, 무엇을 배울 수 있었고 목표를
lsjsj92.tistory.com
논문을 왜 읽어야하고 어떻게 읽어야 하는가?
이 부분은 회사에서 많이 느끼고 배웠던 부분이다. 그 전까지는 논문을 읽기는 했지만 목적성 없이 많이 읽었던 것 같다. 정확하게는 왜? 어떤 관점으로? 읽어야 하는가에 대한 의문이었다. 그래서 당시 리더를 맡아주신 분께 논문 읽는 것에 대해서 상담도 해보았고 AI Research 팀에 있던 팀원들에게도 많이 상담을 받았다.
솔직히 저렇게 상담을 받았는데도 왜 논문을 읽어야하는지에 대해서 정확히 답을 못찾았다. 그래서 직접 실천해보기로 했다. 한 번 읽어보고 내가 어떻게 변화하는지를. 그래서 자연어처리 논문도 읽어보기 시작했고 추천 시스템도 논문을 기반으로 읽어보기 시작했었다. 그리고 5개월~6개월정도 지나고나서 스스로 어렴풋한 답을 찾은 것 같다. 왜 논문을 읽어야 하는지 그리고 어떻게 읽어야 하는지를.
2021년엔 무엇을 이루고 싶은가?
2021년엔 아래와 같은 것들을 이루고 또 진행해보고 싶다. (계획대로 되던 안되던간에!)
- 건강(다이어트 및 체력 키우기)
- 영어
- 수학(선대, 통계)
- 블로그 누적 방문자 200만 달성하기
- 일방문자 3천명 이상 유지하기
- 석사 1년차 잘 마무리 하기
- 추천 시스템 사이드 프로젝트 진행하기
돌아보니 2020년엔 스스로와 대화를 많이 해본 시간이었던 것 같다. 그래서 뭐가 부족한 지, 무엇을 해야하는지, 무엇을 하고 싶은지를 과거와는 다르게 비교적 명확하게 느끼는 것 같다.
그래서 나는 스스로 코로나가 해보단 득이 된 것 같다고 생각한다. 코로나가 아니었으면 이렇게 스스로에게 사색하는 시간이 있었을까? (그렇다고 코로나가 좋다는 것은 절대 아니다. 너무 싫다..)
보통은 한 살 먹는다고 생각하면 싫어했었는데 이번 년도는 좀 다른 것 같다. 오히려 2020년도에 이것저것 시도를 해보면서, 많은 것들을 경험하면서, 생각하면서 2021년을 준비하게 될 수 있었던 것 같다. 2021년은 정말 기대된다. 내년이 기대되는 연말은 처음인 것 같다.
2020년 고생 많으셨습니다.