kubeflow pipeline 예제(example) - pipeline metrics 출력과 condition 체크하기
포스팅 개요
이번 포스팅은 kubeflow 예제(kubeflow example)를 주제로 다룹니다. 지난 포스팅에 이어서 이번에는 kubeflow에서 실행시킨 machine learning 혹은 deep learning 모델에서 나온 metrics를 ( evaluation 값) 출력하는 방법에 대해서 알아봅니다. 또한, kubeflow에서 Condition이라는 것을 통해 어떤 조건을 체크하고 조건에 따라 분기가 일어나는 방법에 대해서 알아보려고 합니다.
저의 kubeflow 관련 지난 포스팅은 아래 링크와 같습니다. 참고 하실 분들은 참고하시면 되겠습니다.
- kubeflow install 방법 : https://lsjsj92.tistory.com/580
- kubeflow example with iris : https://lsjsj92.tistory.com/581
- kubeflow와 AWS with titanic data : https://lsjsj92.tistory.com/586
또한, kubeflow 시리즈 글에서 사용한 모든 코드들은 아래 github에 전부 올려두었습니다. 편하게 사용하시면 되겠습니다.
해당 글을 작성하면서 참고한 자료입니다.
포스팅 본문
이제 kubeflow에서 metrics를 사용하는 방법과 condition check 하는 방법을 살펴보겠습니다. 여기서 사용한 data는 이미 지난 포스팅에서 다룬 적이 있는 iris data를 사용해서 진행합니다.
kubeflow 전체구조
이전 포스팅과 마찬가지로, 먼저 본 포스팅에서 작성한 kubeflow의 전체구조를 한 번 살펴보고 세부적인 설명으로 포스팅을 진행하겠습니다.

이번 포스팅에서 사용한 kubeflow 구조는 지난 kubeflow 2편, kubeflow pipeline example with iris 때와 똑같습니다. 다시 한 번 간단하게 설명하면 아래와 같습니다.
- 2개의 디렉토리와 하나의 파일 존재
- 디렉토리 : data_load 및 model_training
- kubeflow pipeline에서 각 step에 따른 로직을 분리시켜 놓은 것입니다.
- 파일 : pipeline.py
- kubeflow pipeline에서 사용되는 pipeline을 구축할 코드입니다.
- 디렉토리 : data_load 및 model_training
- 각 디렉토리 안에는 아래와 같은 파일이 존재
- Dockerfile : kubeflow는 kubernetes 환경에서 동작합니다. 이때 Docker container를 사용하게 되는데요. 이 container의 전신인 image를 만들기 위한 파일입니다.
- ~.py : 각 container 단계에서 (즉, kubeflow pipeline 단계) 실행할 코드가 담겨있습니다.
- requirements.txt : 각 container 환경이 실행될 때 필요한 라이브러리를 모아둔 파일입니다.
kubeflow 각 파일 설명
전체적인 구조를 살펴보았습니다. 이제는 좀 더 상세하게 각각의 파일을 볼까요? step 1 단계인 data_load부터 model_training 까지 순차적으로 살펴보겠습니다.
step 1: data_load의 파일들
load_data.py

파이썬 파일 이름은 여러분들이 자유롭게 지으셔도 됩니다. kubeflow pipeline step 1 단계에서는 단순히 iris.csv 파일을 load 하는 역할을 수행하도록 했습니다. 여기서 눈 여겨 보셔야 할 것은 argument_parser 부분인데요. 여기서 --data_path로 iris 데이터가 있는 경로를 받도록 설정합니다. 그리고 이렇게 가져온 iris data를 단순히 shape를 찍어보고 kubeflow 환경에서 사용할 수 있도록 / 경로에 iris.csv를 저장하도록 하였습니다. 이렇게 저장된 iris.csv는 나중에 pipeline.py를 통해 사용할 수 있도록 핸들링합니다.
여기서는 굉장히 단순하게 data를 load하고 shape를 찍는 형태로 갖추었는데요. 여러분들은 상황에 따라 각자 가지고 있는 데이터를 자유롭게 핸들링 하시면 될 것 같습니다. 예를 들어 전처리를 하고 저장한다던가요!
Dockerfile

위에서도 말씀드렸듯이 kubeflow는 kubernetes 환경에서 동작합니다. 그렇기 때문에 Docker container가 필요한데요. 해당 Dockerfile은 step 1인 load_data부분을 docker image로 만들어주기 위한 파일입니다.
Python:3 이라는 이미 만들어진 이미지 환경에서 pip install -r requrements.txt를 통해 필요한 라이브러리를 설치하고 해당 환경에 존재하는 load_data.py를 실행하도록 설정해놨습니다.
이 Dockerfile은 뒤에서 Image로 변환하게 됩니다. 뒷부분에서 설명드리겠습니다.
step 2: model_training 파일들
training_model.py
kubeflow pipeline Step 2는 데이터를 훈련시키는 단계입니다. 따라서 step 1에서 저장한 data를 load하고 해당 데이터를 가지고 머신러닝이나 딥러닝을 활용해 훈련하는 코드를 담고 있습니다. 여기서는 deep learning 코드까지 가지는 않고 단순히 kubeflow pipeline environment에서 machine learning으로 iris data를 훈련하도록 하였습니다.
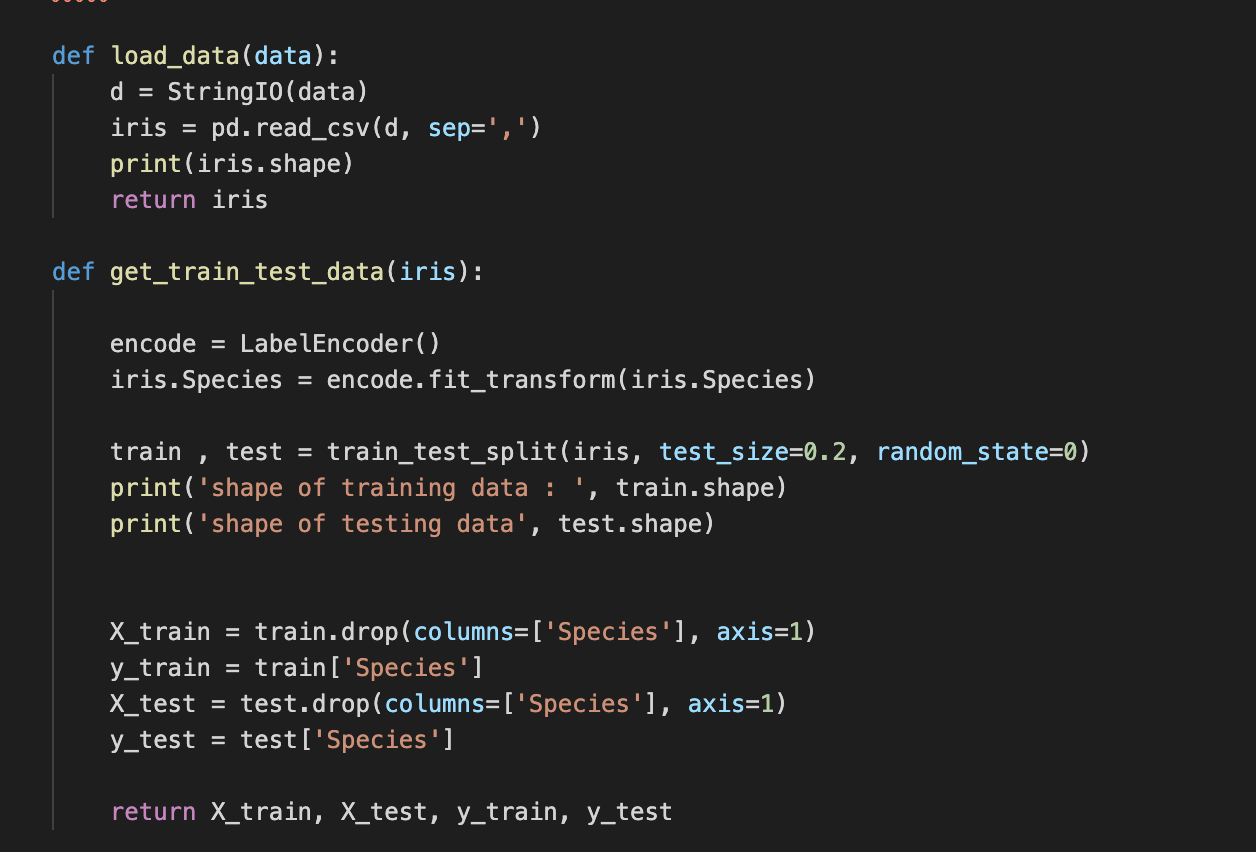
정말 단순한 코드라, 자세한 코드 설명은 하지 않겠습니다.
- load_data : 데이터를 가져옴
- get_train_test_data : data를 train과 test set으로 나누어서 데이터를 return

이 evaluation 함수가 이번 포스팅의 주 목적입니다. 아마 이전 2편 글인 kubeflow example with iris data를 보신 분들은 아시겠지만, 이 evaluation 코드를 제외하고 모든 코드가 전부 동일합니다. 하지만 이 부분이 다르죠.
포스팅 개요에서도 말씀드렸듯이 해당 포스팅은 kubeflow에서 metrics를 평가하는 방법과 Condition check하는 것에 대해서 작성한다고 하였습니다. 그 metrics를 평가하기 위해(출력하기 위해) evaluation 함수를 도입했습니다. 이 함수의 기능은 아래와 같습니다.
- machine learning model의 accuracy를 평가 (꼭 accuarcy가 아니여도 됩니다. f1-scoer, precision, recall 다양하게 활용 가능합니다. 여기서는 정확도를 기준으로 진행했습니다.)
- metrics 이라는 dict를 선언하고 그 안에 key 값으로 metrics를 생성
- value로는 list가 들어가는데 list안에 name, numberValue, format을 설정
- name : 구분하는 이름
- numberValue : metrics 값
- format : percentage, raw, not set 등을 선택해서 사용 가능. 여기서는 %로!
- 여기서는 accuracy만 넣었지만, 만약 f1-score, recall 등을 다양하게 넣고 싶으면 배열 안에 똑같은 포멧으로 넣어주면 됩니다. 즉, 배열->dict(accuracy)으로 되어 있는데 배열 -> dict(accuracy), dict(f1-score)와 같은 구성으로 넣어주면 됩니다.
- value로는 list가 들어가는데 list안에 name, numberValue, format을 설정
- 파일을 저장
- accuarcy.json : pipeline 코드에서 kubeflow Condition 체크 용도로 사용합니다.
- mlpipeline-metrics.json : kubeflow pipeline에서 위에서 선언한 metrics를 출력하도록 하는 파일입니다.
- 주의 사항 : 반드시! 파일 이름이 mlpipeline-metrics.json 이어야 kubeflow 상에서 인식합니다.
Docker file

step 1 단계에서와 가능이 동일합니다. 기본 베이스로 사용한 docker image만 다를뿐 똑같습니다.
kubeflow에서 사용될 Docker image 생성하기
이제 kubeflow 환경에서 사용할 Python 코드와 Dockerfile에 대한 설명을 끝냈습니다. 이제 저렇게 열심히 만든 코드가 kubeflow pipeline 환경에서 동작되도록 docker image를 생성합니다.
여기서는 아래와 같은 단계를 거칩니다.
- Docker image 생성
- 생성한 image에 tag 설정
- tag된 이미지를 hub에 배포
1. Docker image 생성
Docker image를 만들어주는 것은 간단합니다. Dockerfile이 있는 경로에 들어가서 아래와 같은 명령어를 입력해주면 됩니다.
- 예시 : docker build -t soojin-iris-load_data .
맨 마지막에 . 는 오타가 아닙니다. 꼭 주의해주세요!
이렇게 진행해서 맨 마지막에 successfully ~ 가 뜨면 성공한 것입니다. 터미널 상에서 docker image를 입력하면 생성된 도커 이미지를 볼 수 있습니다.
2. 생성한 image에 tag 달기 + 3. docker hub에 배포
두 단계를 한 번에 진행합니다. 생성된 이미지에 tag 작업을 하고 docker hub에 배포합니다. 이렇게 배포된 image를 kubeflow에서 사용할 것입니다.

위는 data_load 부분에 대한 예시였습니다. training하는 부분도 똑같이 해줍니다.

똑같이 진행하므로 자세한 설명은 생략하겠습니다.
kubeflow pipeline 작성
이제 kubeflow 환경에서 pipeline을 활용해 동작되도록 kubeflow pipeline 코드를 만들어줍니다. kubeflow pipeline을 사용하기 위해선 kfp 라는 패키지를 사용해야 합니다. 관련 패키지를 설치하는 방법 등은 참고한 kubeflow document를 참고해주세요.
일단, 제가 이번에 동작시킬 kubeflow pipeline 코드는 아래와 같습니다.


위 2개의 사진은 kubeflow pipeline의 전체 코드입니다. 각 코드를 설명하면 아래와 같습니다.
- print_op : 메세지를 출력하기 위해 사용합니다.
- add_p = dsl.ContainerOp 단계 : 제일 처음 만들었던 load_data를 실행시키는 step 1 단계입니다.
- docker hub에 저정한 lsjsj92/soojin-iris-load:0.7 이미지를 사용해서 동작시킵니다.
- arguments로 --data_path를 전달합니다. 이것은 load_data.py에서 만들 때 argument로 받았던 부분입니다.
- step 1 단계가 끝나면 iris.csv 파일이 output으로 나오게 됩니다.
- train_and_eval = dsl.CotainerOp 단계 : 머신러닝 모델을 훈련하고 평가하는 단계입니다.
- training_model.py에서 코드를 구현해놨듯이 accuarcy.json과 mlpipeline-metrics.json 파일이 결과로 나오게 됩니다.
- 주의사항 : mlpipeline-metrics : '/mlpipeline-metrics.json' 의 이름이 바뀌지 않아야 kubeflow에서 인식합니다.
- baseline = 0.7로 둡니다.(이 부분이 kubeflow pipeline에서의 Condition check 입니다)
- 이 baseline을 사용해 아래에서 dsl.Condition으로 condition 체크를 진행합니다.
- training 단계에서 나온 accuracy를 기준으로 baseline보다 낮냐? 높냐?에 따라 분기처리를 진행해줍니다.
- training_model.py에서 코드를 구현해놨듯이 accuarcy.json과 mlpipeline-metrics.json 파일이 결과로 나오게 됩니다.
이제 이렇게 만든 pipeline.py를 아래와 같은 명령어로 tar.gz로 빼줍니다.

- dsl-compile --py [pipeline py] --output [name.tar.gz]
위 명령어를 실행하면 tar.gz 파일이 만들어지게 됩니다
이로써 모든 준비가 다 끝났습니다!
kubeflow machine learning pipeline 실행시키기
이제 모든 준비가 끝났으니 kubeflow 환경에서 위 machine learning pipeline 코드를 동작시켜 보겠습니다. kubeflow 환경에 접속하셔서 아래와 같은 순서로 진행합니다.
- pipelines 생성
- 실험 생성 및 시작
- 결과 확인
1. pipeline 생성
먼저, pipeline을 생성해줍니다. 방금전에 만든 pipeline.tar.gz를 kubeflow 환경에 upload만 해주고 이름만 설졍해주면 끝입니다

pipelines가 잘 업로드 되었다면 아래 사진과 같이 pipeline 순서와 함께 pipeline 단계를 보여줄 것입니다. 여기서 create experiment를 눌러서 실험을 동작시켜보겠습니다.
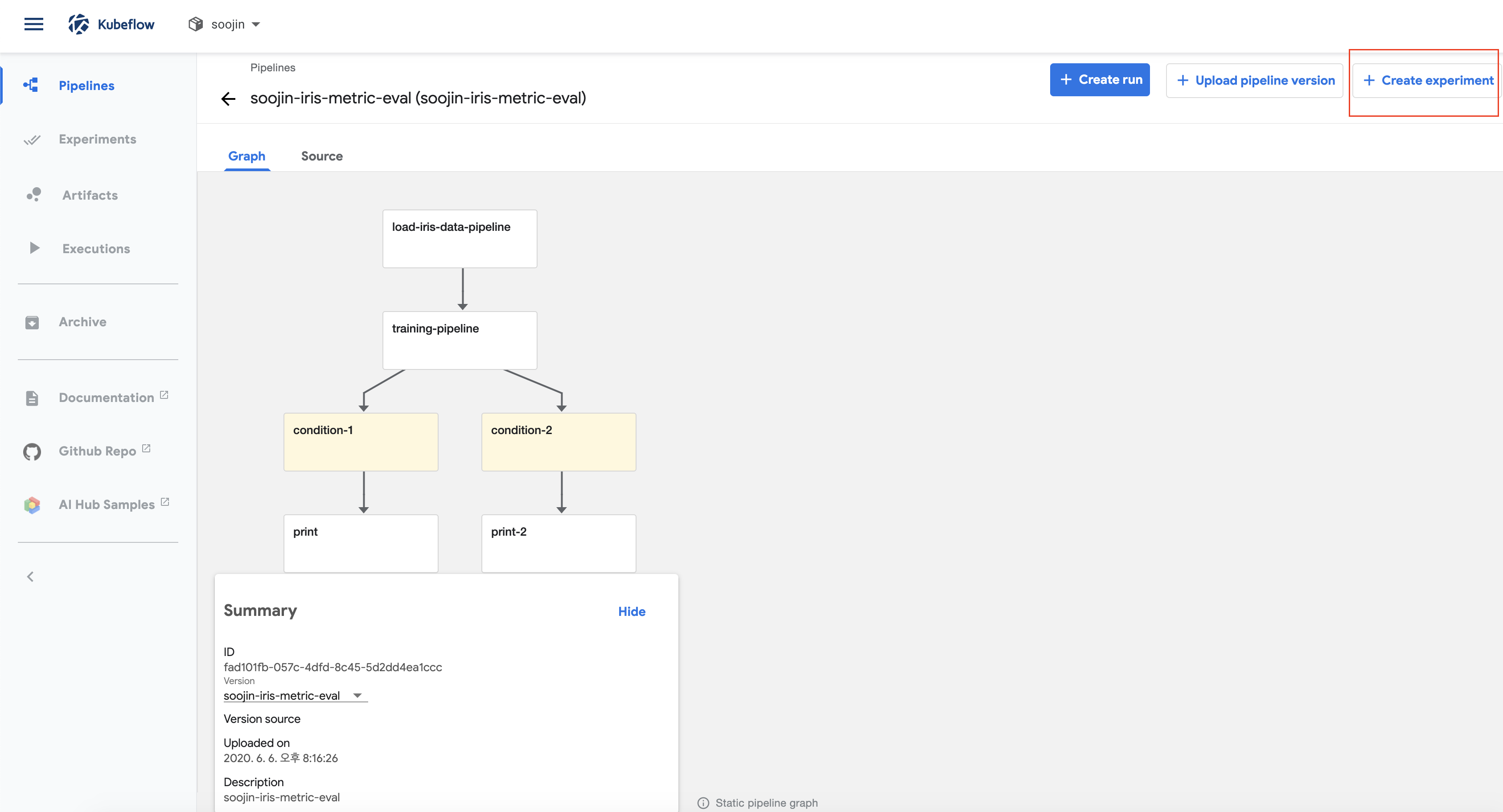
2. kubeflow pipeline experiment 생성 및 시작
해당 포스팅에서의 experiment는 굉장히 간단합니다. 단순히 experiment 이름과 설명을 작성해주면 됩니다.
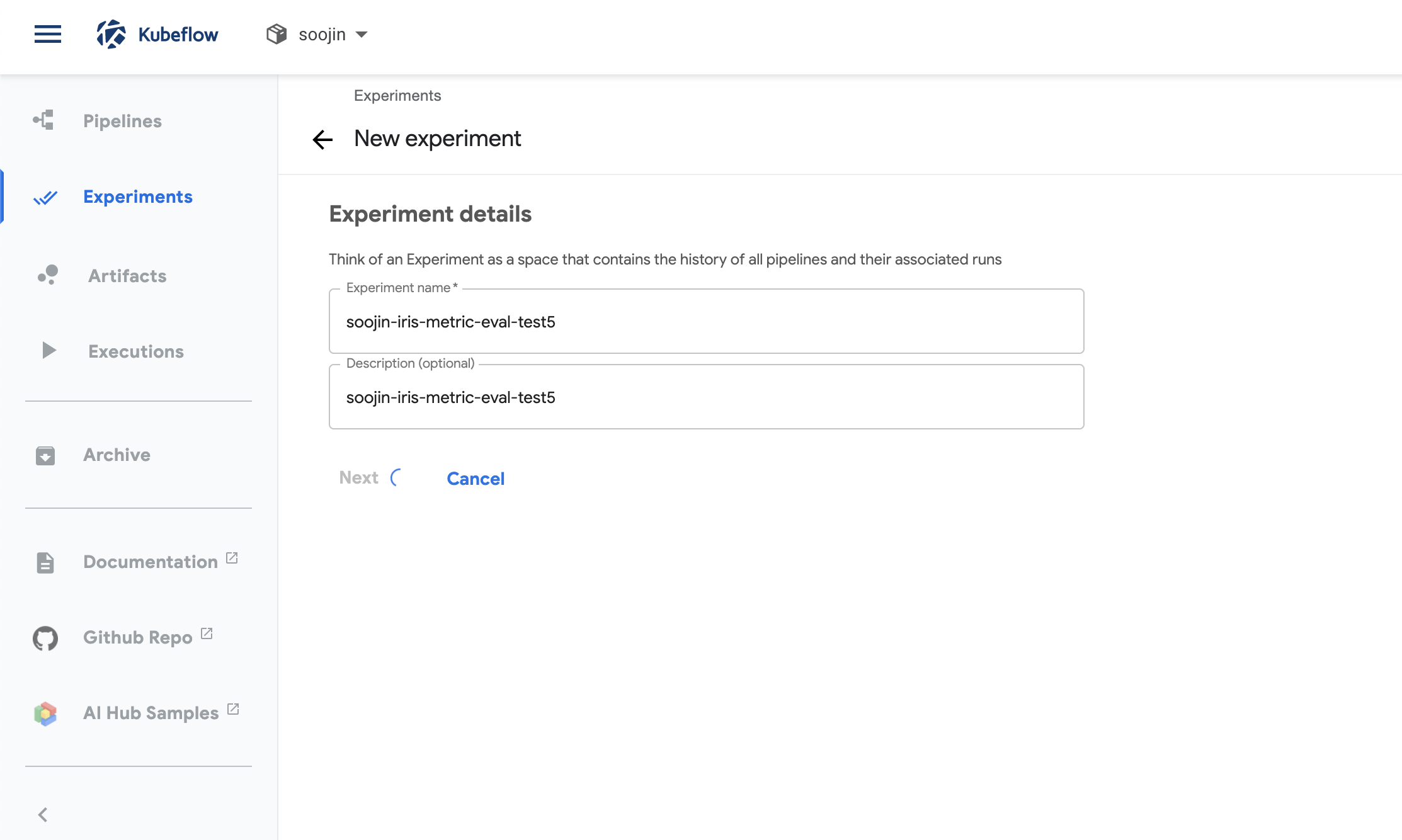
그리고 paramerter를 설정할 것이 없기 때문에 그냥 start를 눌러주면 끝!
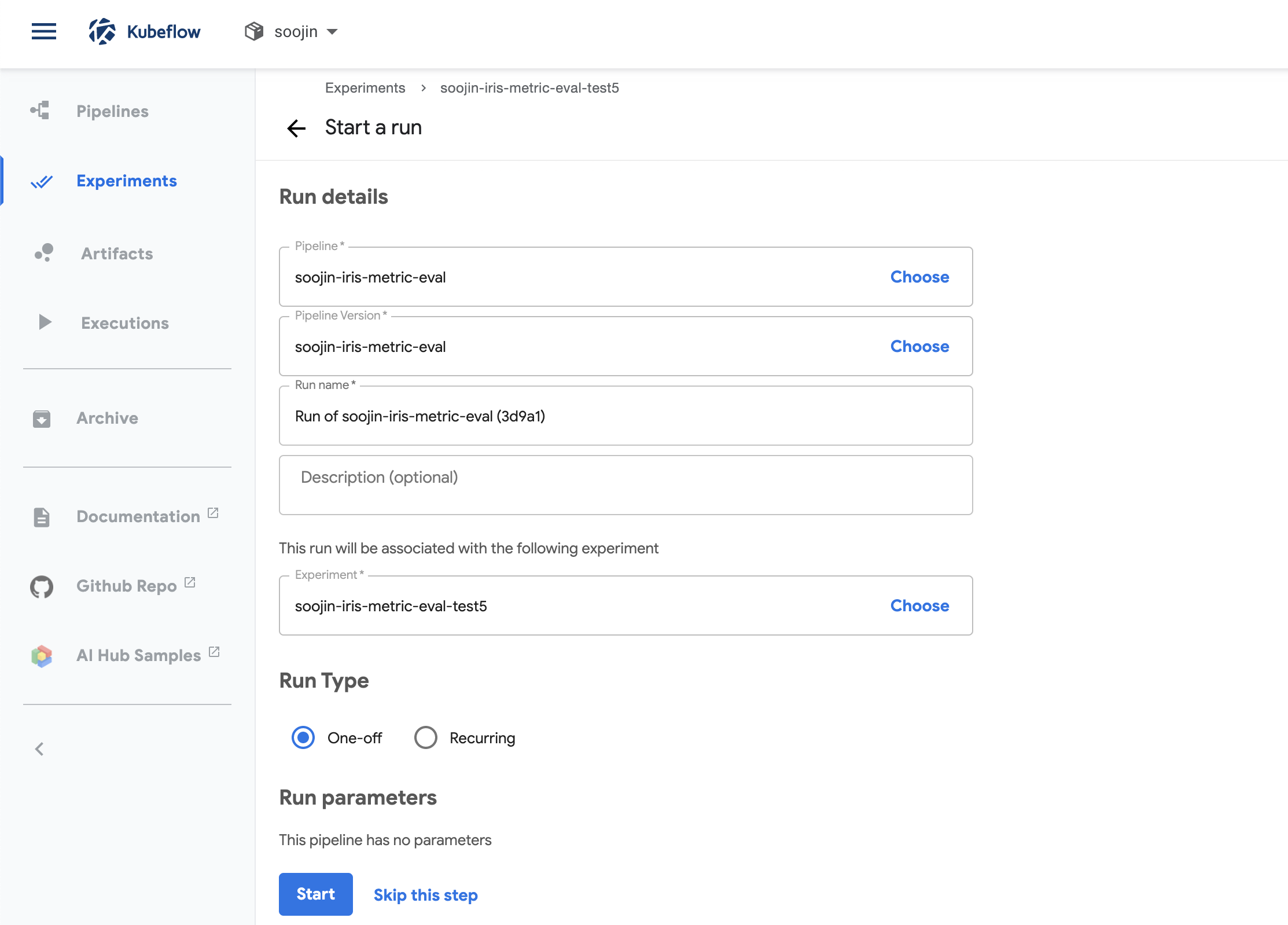
그러면 아래 사진과 같이 kubeflow pipelines experiment의 status를 볼 수 있으며 각 단계가 실행되는 것을 눈으로 볼 수 있습니다.

3. 결과 확인
자! 이렇게 모든 결과가 나오면 아래 사진과 같은 초록색으로 이쁘장한 모습이 나올 것입니다. 여기까지 되셨으면 성공입니다.
하지만, 여기서 아까 제가 만든 metrics에 대한 부분과 condition에 대한 부분을 확인해야합니다.
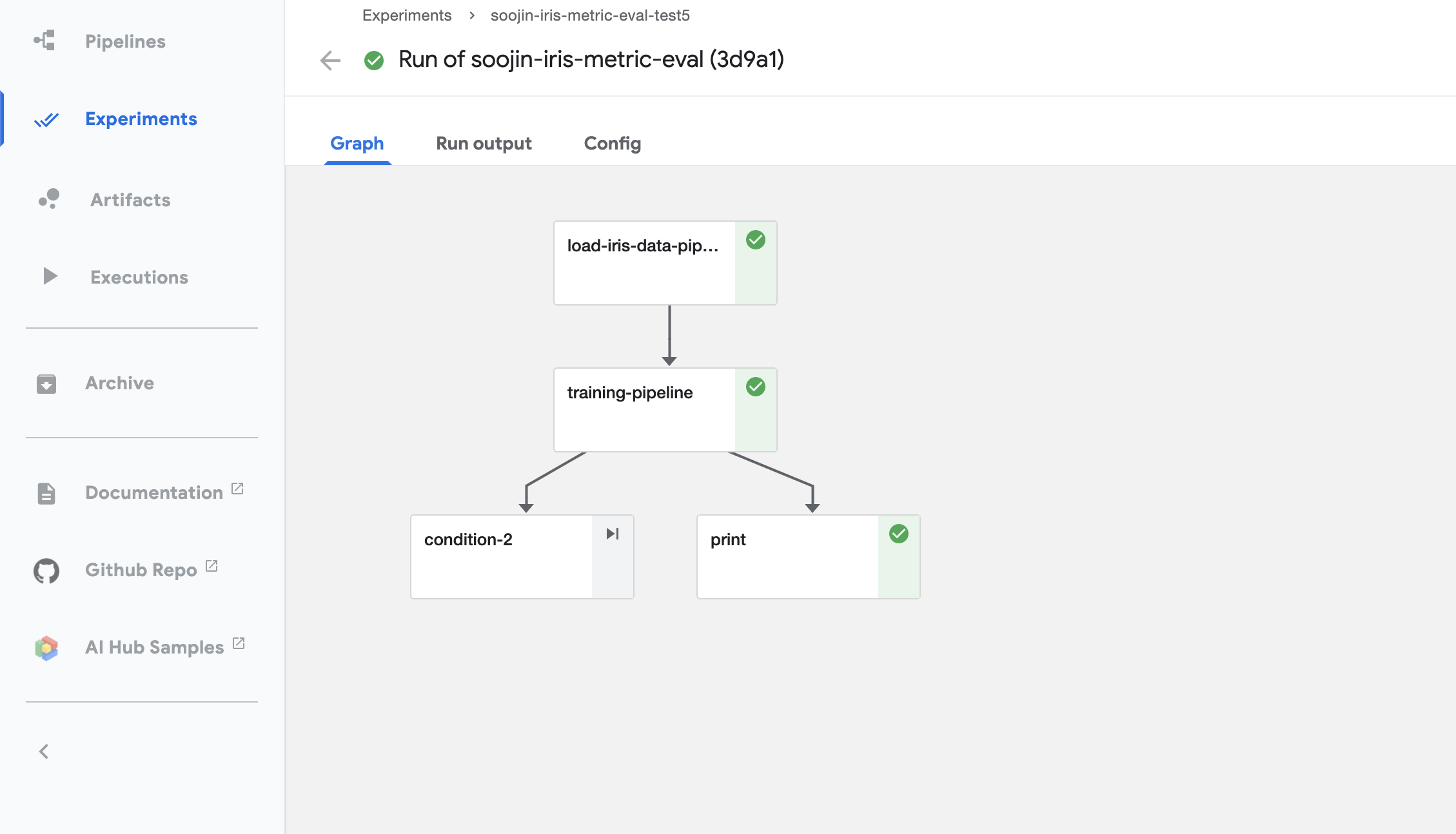
조건에 따른 분기로 나온 초록색 print를 클릭하면 오른쪽 상단에 logs가 있습니다.

이 logs를 확인해보니 accuarcy는 1.0으로 baseline인 0.7보다 크게 나왔다고 출력되고 있습니다.
즉, 아까 pipeline에서 만든 condition에 따라 분기가 되었고, 그에따른 출력도 잘 되어 있는 것을 확인할 수 있습니다.
그리고 mlpipeline-metrics.json으로 만들었던 결과도 kubeflow 환경에서 확인할 수 있습니다.

이렇게 Run output을 확인하면 metrics가 어떻게 나왔는지 확인할 수 있습니다.
여기서는 accuarcy만 사용했기 때문에 정확도만 덩그러니 나오지만, f1-score, recall, precision 등을 사용했다면 해당 결과도 확인할 수 있습니다.
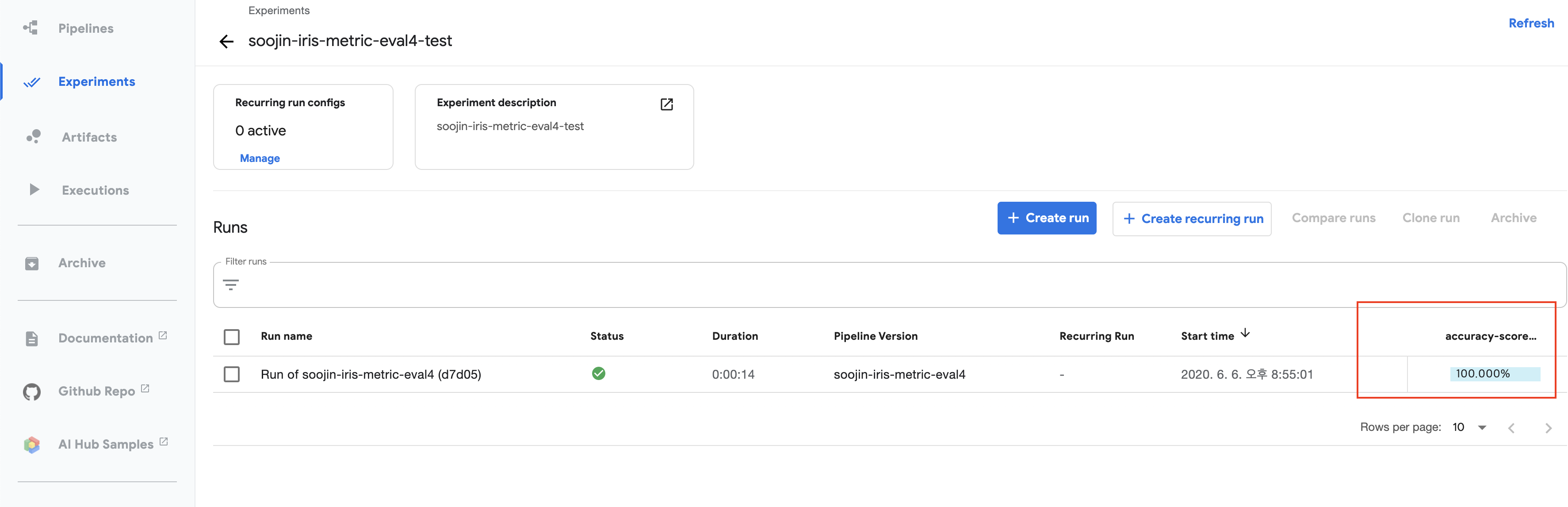
추가적으로 experiment가 끝난 뒤 이 experiment에 들어가면 오른쪽 구석에 metrics에 대한 결과를 확인할 수 있습니다.
맺음말
본 포스팅은 머신러닝 파이프라인(machine learning pipeline)을 구축할 수 있는 kubeflow 시리즈 중 4번째 글입니다.
제가 초기에 생각했던 "kubeflow으로 기술 블로그에 시리즈 형태로 올려야겠다"라고 생각한 모든 시리즈가 끝이 났습니다.
4월 5일에 작성한 설치부터 기본 예제, AWS 예제, metrics까지.. 짧다면 짧은 길다면 긴 시간이었습니다.
부디 이 시리즈 글이 누군가에게 도움이 되길 바랍니다.
추후에도 kubeflow 관련한 글을 기회가 된다면 꾸준히 올리겠습니다. 감사합니다.