머신러닝 스태킹 앙상블(stacking ensemble) 이란? - 스태킹 앙상블 기본편(stacking ensemble basic)
포스팅 개요
머신러닝과 딥러닝에서 자주 사용하는 알고리즘이 있습니다.
특히, 머신러닝쪽에서 많이 사용하는데 그것은 앙상블(ensemble)이라는 방법입니다. 앙상블(ensemble)은 크게 보팅(voting), 배깅(bagging), 부스팅(boosting)으로 나뉘어지는데 추가로 스태킹(stacking)이라는 방법도 있습니다.
스태킹 앙상블(stacking ensemble)은 캐글(kaggle)에서 점수를 조금이라도 더 높이고자 할 때 사용하는 앙상블 방법입니다.
이번 포스팅은 이러한 머신러닝 스태킹 앙상블(stacking ensemble)에 대해서 기본적인 구조를 알아보는 포스팅입니다.
참고 출처는 아래와 같습니다.
- https://www.kaggle.com/getting-started/18153
- https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205
- https://mlwave.com/kaggle-ensembling-guide/
그 외 open 되어 있는 캐글 코드를 사용했습니다.
본문에 나와있는 코드는 아래 github에 올려두었습니다.
github.com/lsjsj92/machine_learning_basic
lsjsj92/machine_learning_basic
Repo for everyone who wants a machine learning basic - lsjsj92/machine_learning_basic
github.com
포스팅 본문
스태킹 앙상블은 개별적인 여러 알고리즘을 사용하는 형태라서 일종의 앙상블(ensemble)로 불립니다.
하지만, 기존의 머신러닝 앙상블 방법과 조금 차이점이 있습니다.
먼저, 기존의 방식을 알아야 합니다.
기존의 머신러닝 모델 훈련 방법
기존의 머신러닝 훈련 방법은 아래 사진과 같습니다.
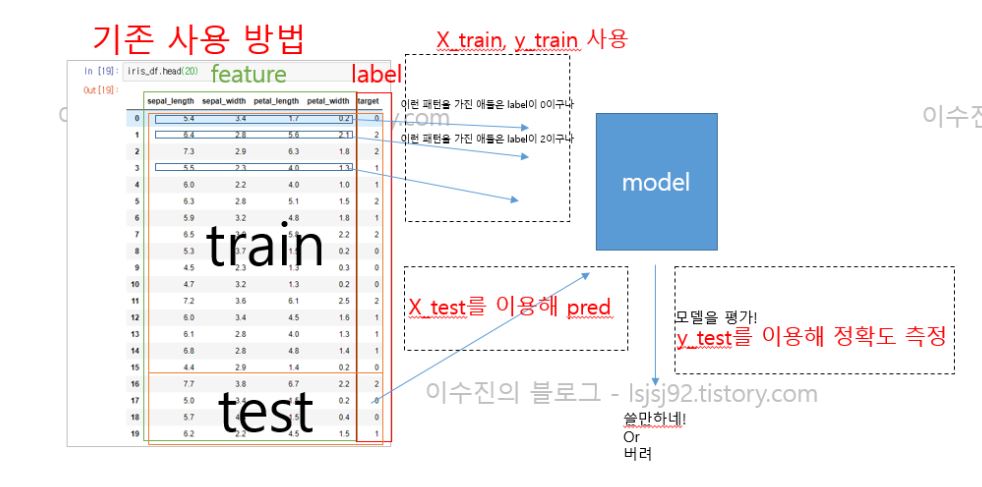
그림을 간단하게 설명하면
- X_train, y_train을 사용하여 model training
- validation이 있다면 중간중간 평가
- X_test를 이용해 최종 예측 -> predict 값 get
- y_test와 predict 값을 이용해 최종 평가
와 같이 됩니다.
스태킹 앙상블의 훈련 방법 - 기본편
그러나 스태킹 앙상블(stacking ensemble)은 조금 구조가 다릅니다.
바로, 개별 모델이 예측한 데이터를 다시 training set으로 사용해서 학습한다는 것입니다.
즉, 100% 예시가 맞지는 않지만 간단하게 설명하면 아래와 같습니다.
(참고로 스태킹 앙상블의 기본적인 구조를 설명합니다. CV 기반은 다음 포스팅에서 다룹니다.)
- 원본 데이터의 train, test가 존재
- 원본 training data를 3개의 머신러닝 모델이 학습
- 각 모델마다 X_test를 넣어서 예측 후 predict를 뽑아냄 (3개의 predict된 값)
- 3개의 predict를 다시 학습 데이터로 사용
- 최종 model을 하나 선정해 학습
- 최종 평가
따라서 stacking ensemble을 할 때는 2가지 개념의 모델이 필요합니다.
1. 개별 모델들(복수)
2. 최종 모델(하나)
단순하게 생각한 stacking ensemble basic 구조는 아래와 같습니다.
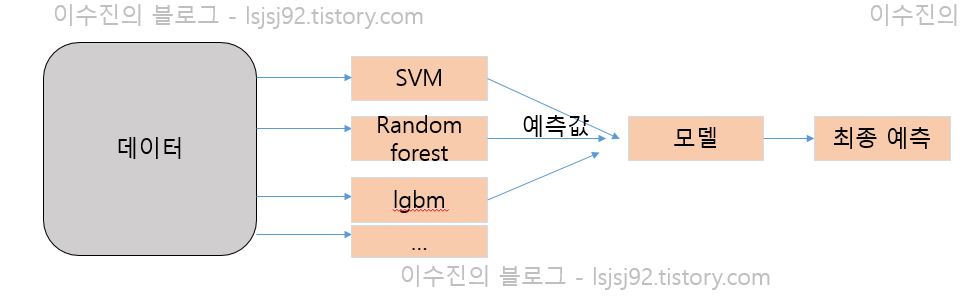
조금 더 자세히 보았을 때 스태킹 앙상블의 기본 구조는 아래와 같습니다.

아마도 코드로 보면 좀 더 명확히 보일 것 같습니다.
파이썬으로 스태킹 앙상블 기본 코드를 구현해보죠
파이썬으로 구현한 스태킹 앙상블 기본 코드 - Python stacking ensemble
파이썬으로 스태킹 앙상블 기본 코드를 구현합니다.
sklearn에서 제공해주는 암(cancer) 데이터를 활용합니다.
데이터를 가지고와서 train_test_split으로 데이터를 구분하겠습니다.

여기까지는 전통적인 머신러닝 방법입니다. 데이터를 train과 test로 나누는 것이니까요
이제 여러 머신러닝 모델들을 생성해봅니다.
스태킹 앙상블에서는 2가지 개념의 머신러닝 모델이 필요하다고 말씀드렸습니다.
저는 개별 모델은 SVM, 랜덤 포레스트(random forest), 로지스틱 회귀(logistic regression)을 사용했습니다.
최종 모델은 LightGBM을 사용했습니다.
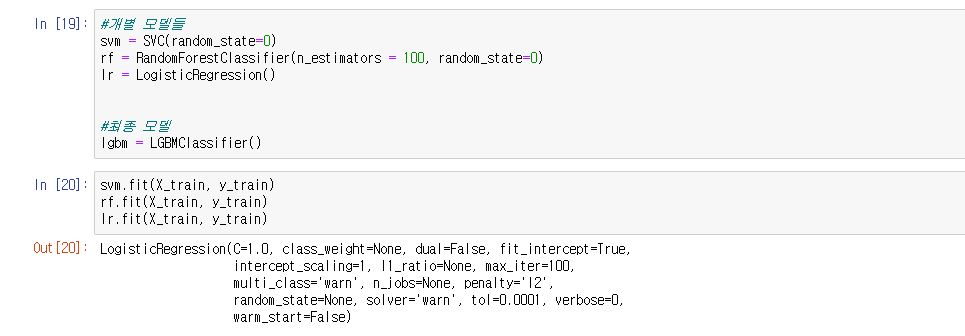
위 사진과 같이 개별 모델들과 최종 모델을 만들어줍니다.
그리고 각각 fit을 통해 X_train값과 y_train 값을 훈련시켜줍니다.
훈련을 했으면 이제 predict을 해야겠죠?
predict를 수행합니다. 개별 모델들의 predict를 다 따로 저장해야 합니다.
즉, svm의 predict와 random forest의 predict 등을 모두 저장해야합니다.

이렇게 변수에 저장하면됩니다
자! 이제 이것을 합쳐주어야 합니다.
이 합쳐주는 과정이 데이터를 쌓는 듯한 모습(stacking)이라서 stacking ensemble이라고 불리우는 것 같더군요
new_data = np.array([svm_pred, rf_pred, lr_pred])와 같이 쌓으시면 됩니다.
아니면 np.concatenate를 사용하셔도 되구요.

단, stacking을 할 때 데이터의 shape에 주의해야 합니다.
3개의 모델을 stacking 하고, 이 값은 predict로 나온 값이기 때문에 row는 X_test와 일치해야 합니다.
즉, 여기서 X_test의 row는 114개입니다. 이 114개의 데이터가 다시 새로운 훈련(training) 데이터가 됩니다.
따라서 (114, 3)의 모양이 되어야 합니다.

데이터를 살펴보면 위와 같이 될 것입니다.
이제 마지막 최종 모델을 사용해서 훈련만 하면 끝!

이렇게 하면 스태킹 앙상블의 기본적인 방법을 활용하여 모델을 구현한 것입니다.
여기까지 이해가 되셨을까요?
스태킹 앙상블(stacking ensemble)은 캐글(kaggle) 대회에서 많이 사용하는 방법 중 하나입니다.
그리고 계속 설명드렸듯이 기존 방법과는 살~짝 다릅니다.
맨 처음 보여드렸던 사진에서는 기존의 머신러닝, 딥러닝 훈련 방법을 그림으로 표현했는데요
스태킹 앙상블의 기본 구조를 활용하면 아래 그림처럼 됩니다.

이렇게 말이죠!
결론
스태킹 앙상블(stacking ensemble)은 기존의 머신러닝, 딥러닝 훈련 방법과 조금 다른 구조를 가지고 있습니다.
또한, 주로 kaggle과 같은 대회에서 많이 사용하는 방법입니다.
하지만, 여기서 문제점이 있습니다.
위의 글은 계속 강조 드렸지만 스태킹 앙상블의 기본적인 방법을 설명드린 것입니다.
이러한 기본적인 스태킹 앙상블은 과적합(overfitting)의 문제점이 있어 사용하지 않습니다. 보통 CV 기반(KFold 등)의 stacking ensemble을 사용합니다.
다음 포스팅에서는 저 CV 기반의 stacking ensemble에 대해서 알아보겠습니다.