딥러닝 자연어처리 이해하기! - 기계번역편(NMT), seq2seq란?
딥러닝이 핫한 지금 영상처리 분야뿐 아니라 자연어 처리 분야도 엄청 핫합니다.
특히 일반적인 문서 분류(text classification)를 넘어서 이제 번역기나 문장 생성, 텍스트 생성에도 포커스가 맞춰지고 있죠
이번 포스팅은 seq2seq에 대해서 자세히 알아보려고 합니다.
제 블로그에 seq2seq 내용을 다루긴 했지만 이론적인 내용이 부실했었습니다.
그래서 최근 제가 모두의 연구소에서 자연어처리 기초반(NLP)을 운영하면서 진행했던 발표 자료를 가지고 다시 정리해보려고 합니다.
기계 번역의 역사부터 현재까지 어떻게 진행되는지 전반적인 내용을 보려고 합니다.
그리고 이 자료는 허훈님의 자료를 조금 참고해서 만들었었습니다.
그럼 시작하죠!

먼저 기계 번역의 역사입니다.
기계 번역의 역사는 사실 좀 되었습니다. 예전에는 rule based 기반으로 했죠. 말 그대로 규칙 기반으로 했습니다.
하지만 역시 성능이 좋지 않았겠죠 ㅎㅎ 언어마다 룰이 다르고 이 룰을 전부 적용시키는 것은 쉽지 않으니까요

다음으로 확률과 통계 기반의 기계 번역입니다.
이 Machine Translation은 꽤나 인기가 많았습니다. 실제로 구글도 이 기반으로 번역기를 돌렸었으니까요
확률과 통계 기반에선 많은 데이터가 필요합니다. 많은 데이터에서 확률적 방법을 적용시키기 때문인데요
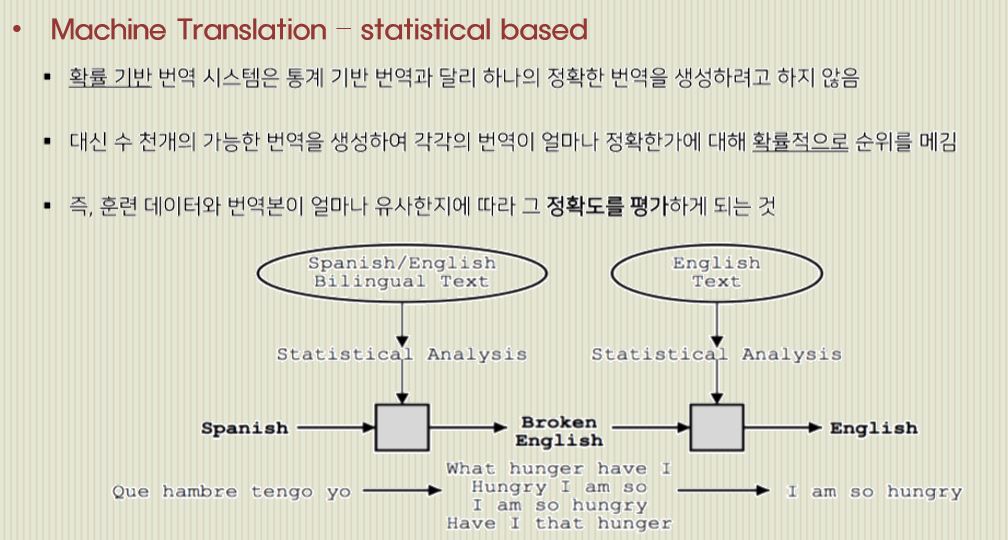
번역이 가능한 수 천개의 번역을 생성하고 그 번역에 대해서 얼마나 정확한가를 평가하고 순위를 매깁니다.
즉, 훈련 데이터와 번역본이 얼마나 유사한지에 따라 정확도를 평가하는 것이죠

실제 이러한 statistical based Machine Translation은 충분한 데이터가 있으면 꽤나 나쁘지 않은 성능을 보인다고 합니다.
실제 구글 번역기도 이와 같은 방법으로 제공해주고 있었다고 합니다. 그러나 역시 성능이 그렇게 좋지도 않았을 뿐더러 여러 손이 많이 가기도 하는 작업이기도 해서 빛을 내진 못했습니다.
하지만! deep learning의 NLP 기술이 나오고 나서 machine translation은 엄청나게 발전했죠
NMT라고도 하죠. 이제 내용은 밑바닥부터 시작하는 딥러닝2에 나오는 내용을 기반으로 이어갑니다.
이제, Machine Translation 방법인 seq2seq에 대해서 다룹니다. seq2seq는 기계 번역에서 많이 사용하는 방법이죠

기존 LSTM 기반의 번역은 한계가 있었습니다. 왜냐하면 LSTM은 하나가 들어오면 바로 하나의 output을 낼 수가 있는데요. 이것이 문제가 됩니다.
흔히 한국어는 끝까지 들어봐야 안다! 라고 말하죠 ㅎㅎ
만약, input이 오늘 날씨는 좋지만 나는 슬퍼 가 들어오게 된다면
LSTM 모델은 '오늘', '날씨', '좋다' 만 보고 '긍정적이구나!' 라고 생각할 수 있다는 것입니다.
하지만 뒤에 '나는 슬퍼'가 오게 되면 LSTM 모델을 말 그대로 멍청한 모델이 되어 버리는 것이죠
그렇기 때문에 이런 단점을 보완하고자 seq2seq 모델이 나오게 됩니다.

seq2seq를 보기 전에 먼저 생성 모델을 봅시다.
생성 모델은 단어를 생성해주는 모델을 말합니다. 즉, i라는 값이 들어오면 그 뒤에 단어가 무엇이 나오게 될 지 생성하는 것이죠. 이 과정은 sofrtmax를 이용해서 확률적 기반으로 접근합니다.
왜 softmax를 기반으로 확률로 접근할까요? why?
왜냐하면 그렇게 해야 다양한 문장을 생성할 수 있기 때문입니다.
i 다음에 say가 나올 수도 있고 like가 나올 수도 있고 등등 무조건 'i 다음엔 say야!' 라고 하면 다양한 문장이 나올 수 없겠죠? 그래서 softmax를 이용해서 다양한 문장이 나올 수 있도록 확률적 방법으로 진행을 하는 것입니다.

자 이제 다시 seq2seq 모델로 넘어옵니다. seq2seq는 흔히 encoder decoder 모델이라고도 합니다.
encoder는 정보를 변화해주고 decoder는 다시 정보를 되돌려주죠.
그리고 encoder에는 input의 정보가 응축되어 있고 이것을 decoder에게 넘겨줌으로써 이것을 활용해 단어를 뽑아내게 됩니다!
자 ! 그러면 seq2seq에 대해서 자세히 알아봅시다.
먼저 Encoder 부분입니다.
Encoder
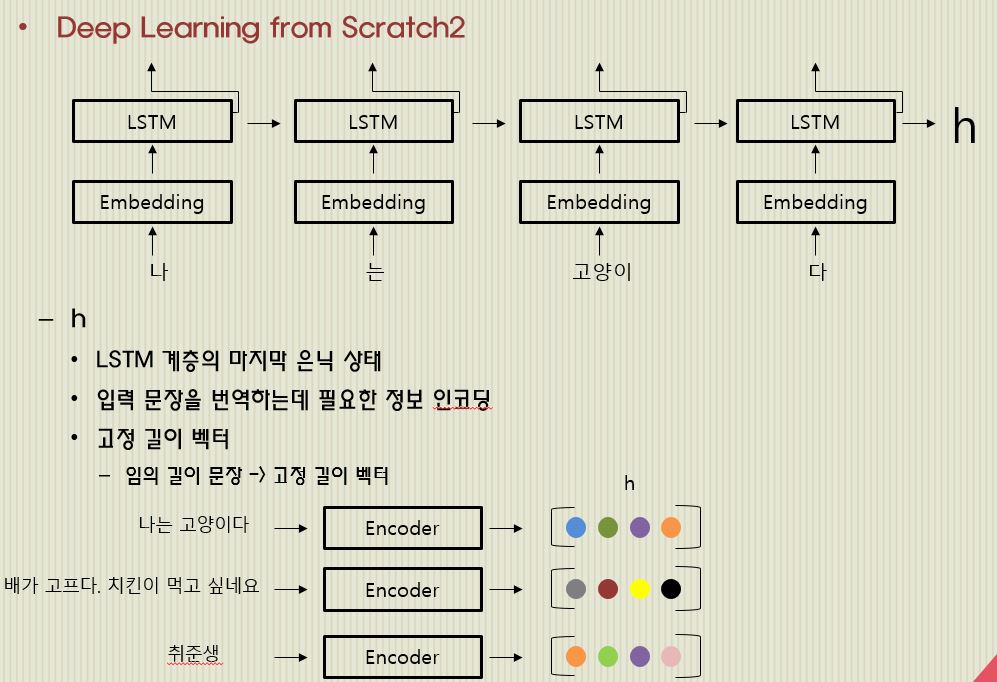
encoder는 위와 같이 생겼습니다. 각 embedding에 단어가 들어오면 LSTM이 이것을 받습니다. 그리고 다음 단어를 차례대로 받게 되고 최종적으로 h라는 벡터를 뽑아내게 되죠.
그러면 이 h 벡터에는 '나는 고양이다' 라는 단어에 대한 정보가 전부 담겨있게 됩니다.
h는 LSTM 계층의 마지막 은닉 상태를 말합니다. 입력 문장을 번역하는데 필요한 모든 정보가 담겨져 있죠.
그리고 큰 특징은 고정 길이 벡터라는 것입니다. 이는 input으로 들어오는 문장의 길이가 전부 다르기 때문에 고정 길이로 만들어서 정보를 담아두는 것입니다.
인코더는 이게 끝입니다. 간단하죠? 다음은 디코더 입니다.
Decoder

디코더는 앞에서 Encoder와 동일한 구조입니다. 단, 다른 것이 2가지 정도 보이네요
아까 생성 모델에서 사용한 softmax가 사용됩니다. 그리고 앞에 Encoder로 부터 받은 h 벡터를 받습니다.
LSTM에 이 h를 받고, <eos> 토큰을 받아 처음에 시작합니다. 그래서 맨 처음 단어를 softmax를 통해 뽑아내고
이 단어가 다음 Embedding에 들어가는 것입니다.
그리고 나선 완전 Encoder와 똑같습니다. h벡터 받는 것만 사실 다르다고 봐야겠죠 ㅎㅎ
그래서 Encoder의 정보 h를 활용해서 생성 모델을 적용시켜 단어를 뽑아내주면 번역기가 완성 되는 것입니다!
seq2seq의 모델은 이렇게 흘러갑니다.
자! 그러면 Toy problem을 보면서 더 이해를 해봅시다
Toy problem은 말 그대로 장난감 예시입니다. 여기서는 seq2seq 모델에게 '덧셈'을 학습시켜 보려고 합니다.
여기서 알아두셔야 할 것이
input이 String 즉, 문자열이라는 것입니다.
우리가 생각하는 숫자 3+3이 아니라, "3+3", "6" 이렇게 문자가 들어간다는 것입니다.
seq2seq 모델은 이런 패턴을 학습을 하는 것입니다. seq2seq 모델은 '덧셈'이 뭔지도 모릅니다.
단순히 패턴을 학습해 보는 것입니다.

자! 위와 같은 더하기 예시를 해보죠! seq2seq는 앞서 설명 드린것 처럼 '더하기'라는 개념을 모릅니다.
패턴을 학습하는 것이죠

실제 데이터는 위와 같이 되어 있습니다. 문자열로 들어오죠 ㅎㅎ
그리고 여기서는 <eos>가 _ 로 되어 있는 것입니다!

모델은 위와 같이 흘러가겠죠? Encoder 부분입니다. 아까랑 똑같죠?
단순히 input의 정보만 다른 것입니다. 그리고 h 벡터가 나오구요

그리고 decoder는 이 h를 받아서 단어를 생성해줍니다. 대신 여기는 아까와 다르게 argmax를 사용합니다. 아까는 softmax였죠? 왜냐하면 이거는 다양성을 제공하는 문자 생성이 아니라 덧셈, 즉 답을 확정 시켜야 하기 때문입니다.
아무튼 그렇게 진행을 해서 최종 loss를 측정하면서 훈련을 합니다.
자! 이제 훈련을 해봅니다. seq2seq는 3가지 모델이 있습니다. 점차 보시죠 ㅎㅎ
첫 번째 모델

먼저 일반적인 모델을 진행해보겠습니다.
에폭이 19인데 77+85는 164라고 나오게 했네요. T는 실제 값이고 X는 모델이 내놓은 예측값입니다.

모든 에포크가 끝났을 때 8+155는 162라고 예측을 하는 등
위 그래프를 보면 성능이 그렇게 좋지 않음을 알 수 있습니다.
다소 실망스럽죠? 하지만 여기서부터 이야기가 달라집니다.
두 번째 모델

두 번째 모델은 바로 reverse한다는 것입니다. 이렇게 반전을 하게 되면 예를 들어 '나는 고양이다' -> 'i am a cat' 이
'고양이다 나는' -> 'i am a cat' 즉, '나는'과 'i am'이 가까워지죠? 이런 효과를 노렸다고 합니다.
논문에서조차 잘 모른다고 합니다.

위 그래프를 보시면 실제로 정확도가 확 늘어난 것이 보이시죠?
그리고 옆에 보면 8+155는 아까 틀렸는데 이젠 맞췄네요!
별 것 아닌 것 같은데 ㅋㅋㅋㅋ 성능이 갑자기 향상 됩니다.
세 번째 모델

세 번째 모델은 위와 같은 그림을 가지고 있습니다. peeky 모델, 엿보기? 뭐 그런 뜻이라고 하는데요
아까 입력 벡터 h를 처음 LSTM에만 넣었었는데 이제 다른 LSTM 모델 에게도 h를 주는 것입니다.
집단 지성을 이용하는 것이죠
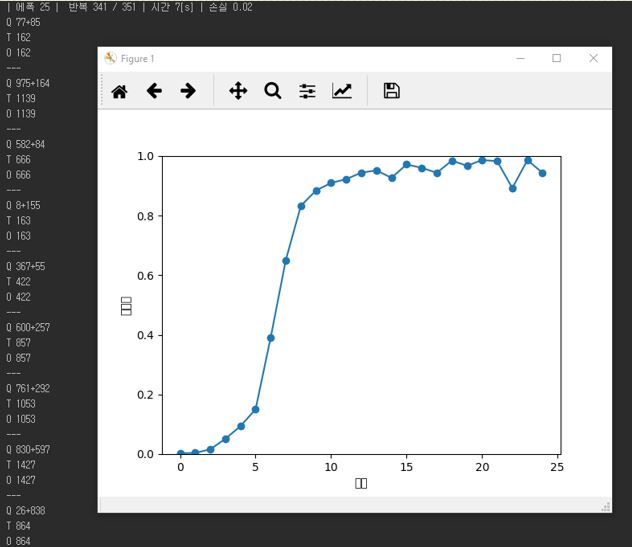
실제 성능을 보면 거의 100%에 가깝습니다.
옆에 숫자들도 보시면 거의 다 맞은 것을 볼 수 있죠
어떠신가요? 재밌지 않나요 ㅎㅎ
다음엔 seq2seq 모델에 어텐션 메커니즘을 적용시킨 포스팅을 작성하겠습니다.