

포스팅 개요
이번 포스팅은 딥러닝(Deep Learning)을 활용해 추천 시스템(Recommender system)을 구현하는 포스팅입니다.
그 중 개인화 된 추천 시스템(personalized recommendation system)을 한 번 만들어보겠습니다.
파이썬(Python)을 활용했으며 라이브러리는 케라스(Keras)를 사용했습니다.
고급진 기술보다 기초적인 수준에 가까운 글이니 참고 부탁드리겠습니다.
이번 추천 시스템의 목적은 뉴스 추천 시스템입니다.
==참고 사항==
본 글에 나오는 Dataset은 제가 임의로 만든 Dataset입니다.
그래서 현실적인 면에서 조금 동떨어질 수 있습니다.
부디 참고 부탁드리며 Insight만 얻어 가시길 바랍니다.
또한, 본 포스팅 글은 지난 번에 작성한 추천 시스템 구현의 연장이 되는 글입니다. 지난 글은 아래와 같습니다.
https://lsjsj92.tistory.com/571
파이썬(Python)으로 간단한 뉴스 추천 시스템(recommender system) 구현해보기
포스팅 개요 이번 포스팅은 파이썬(Python)을 활용해서 추천 시스템(recommender system)을 구현해보는 포스팅입니다. 이번 포스팅은 "정말 단순한 아이디어"를 가지고 네이버 뉴스를 추천해주는 것을 구현해보려..
lsjsj92.tistory.com
포스팅 본문
앞서 말씀드렸듯이 이번 포스팅은 딥러닝 기반으로 추천 시스템을 만들어보는 포스팅입니다.
Python언어를 사용하며 사용에 필요한 파이썬 라이브러리는 아래와 같습니다.
- Keras
- Pandas
- Numpy
- Gensim(Doc2vec)
1. Dataset
제가 이번 포스팅에서 작성하는 추천 시스템은 뉴스 추천 시스템(News recommender system)입니다. 뉴스 데이터는 구글에서 검색하면 나오는 오픈된 데이터를 활용했습니다.
이 데이터는 5개의 카테고리를 가지고 있으며, 총 53만여개 정도 되는 데이터입니다.

정확히 532772개의 데이터를 가지고 있고 정치, 경제, IT 등 카테고리가 5개 카테고리를 가지고 있습니다.
또한, 저는 이 뉴스 데이터를 은전한닢(Mecab)을 사용해서 형태소 분석을 미리 진행했습니다. Mecab 형태소 분석기를 이용해서 진행한 형태소 분석의 결과는 tok 이라는 컬럼에 넣어 놓았습니다.
2. News embedding
recommender system을 만들기전에 먼저 이 뉴스 데이터를 embedding 해야합니다. embedding의 종류에는 상황에 따라 다양한 방법이 있을 것입니다. 저는 단순하게 doc2vec을 사용했습니다. 여기서 doc2vec의 개념은 설명하지 않겠습니다. 이미 훌륭하신 분들의 글에서 자세히 설명된 것이 있기 때문입니다. 저는 단순히 doc2vec을 사용해 text 데이터를 embedding 했습니다. 이때 doc2vec 차원은 128 차원입니다.

그리고 그 embedding 값은 미리 저장했었고 이제 사용해야 하니까 load했습니다.
3. user history data
추천 시스템을 만드려면 사용자에게 맞춤형 콘텐츠를 추천할 수 있는 추천 시스템을 만들어야 합니다.
저는 여기서 어떻게 하면 사용자 맞춤형 추천 시스템을 만들 수 있을까?를 고민했습니다. 한 2~3주 고민한 것 같네요..
사용자 맞춤형 추천 시스템은 personalized recommendation system이라고도 부를 수 있습니다.
즉, 개인화 된 추천 시스템인 것이죠. 그래서 사용자 히스토리(user history) 데이터가 필요했습니다.
하지만 저는 개인적으로 여러가지 테스트 해보는 것인데 사용자 히스토리 데이터.. 그런 것은 절대 없었습니다. 제가 할 수 있는 방법은 '임의'로 만드는 것이었습니다.
포스팅 개요에서도 말씀드렸듯이, 이건 제가 '임의로'만든 사용자 히스토리 데이터 셋입니다. 그래서 정확하지 않은 추천 시스템이 만들어질 수 있음을 다시 말씀드립니다 ㅠㅠ
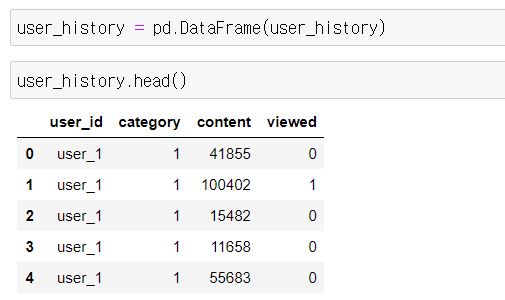
제가 만든 사용자 데이터셋은 아래와 같은 기준으로 만들었습니다.
- 1000여명의 유저라고 가정
- 유저당 최근 본 100개의 콘텐츠를 기준으로 삼았다고 가정
- 유저 당 콘텐츠를 보았는지(1), 보지 않았는지(0)을 체크
- 본 데이터(1)과 보지 않은 데이터(0)의 비율은 3:7
그래서 데이터는 총 10여만개의 데이터가 만들어졌습니다.
4. Deep Learning model
이제 데이터 셋이 만들어졌으니 딥러닝을 활용해서 추천 시스템을 만들어보겠습니다.
하지만, 아직 완벽한 데이터 셋이 만들어진 것이 아닙니다. 왜냐하면, 이거는 사용자가 본 콘텐츠(content)를 기준으로 합니다. 그리고 저는 콘텐츠를 doc2vec을 이용해서 embedding 했구요.
즉, 사용자 히스토리 데이터를 content id에 대응되는 doc2vec embedding 값을 가지고와서 그걸로 input 데이터를 만들어주어야 합니다. 저는 doc2vec embedding을 128차원으로 만들었습니다.
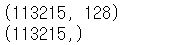
그래서 shape는 위와 같은 형태로 나오게 됩니다. y 값은 봤다(1), 보지 않았다(0)의 값을 띄게됩니다.
또한, user vector는 view history를 기준으로 mean을 한것으로 만들었습니다.
이제 추천 시스템을 위한 딥러닝 모델을 만들어줍니다.
딥러닝 모델은 저는 파이썬의 Keras(Python Keras)를 사용했습니다. 그리고 그 모델의 형태는 아래와 같습니다.

단순히 Dense layer만 쌓은 형태의 딥러닝 추천 시스템입니다. 처음에는 128개의 input을 받고 점점 작아져서 마지막은 sigmoid로 0, 1을 판단하도록 하였습니다.
자! 이제 이 모델에 아까 만들었던 data를 활용해서 모델을 훈련시켜줍니다.
빠른 학습과 시간 조절을 위해서 저는 checkpoint도 두어서 callback에 넣었습니다.

이제 본격적으로 추천 시스템 모델을 훈련시켜줍니다!
아래와 같이 말이죠.

임의로 만든 dataset인데도 불구하고 loss가 어느정도 떨어지는 것을 볼 수 있습니다.
이제 최종적으로 얼만큼 추천 시스템 모델의 성능이 나오는지 확인해봅니다.

딥러닝 기반 추천 시스템의 최종 결과는 아래와 같습니다. (혹은 위 사진과 같습니다.)
- f1-score : 71%
- precision : 57%
- recall : 91%
- acc : 80%
마무리
성능은 썩 좋지 않았습니다. 성능이 좋지 않은 이유는 아무래도 임의로 만든 데이터 셋이라서 더욱 그럴 것입니다.
만약, 충분한 데이터 셋과 real dataset이었다면 성능이 잘 나왔을까요?? ㅎㅎ 그건 잘 모르겠습니다.
부디 insight만 얻어가시길 바랍니다.



