
포스팅 개요
해당 글에 대한 코드는 아래 github 링크에 전부 올려두었습니다.
lsjsj92/recommender_system_with_Python
recommender system with Python. Contribute to lsjsj92/recommender_system_with_Python development by creating an account on GitHub.
github.com
이번 포스팅은 파이썬(Python)을 활용해서 추천 시스템(recommender system)을 구현해보는 포스팅입니다.
이번 포스팅은 "정말 단순한 아이디어"를 가지고 네이버 뉴스를 추천해주는 것을 구현해보려고 합니다.
이번 포스팅에서 구현하는 추천 시스템은 아래와 같은 개념을 사용합니다.
- 파이썬(Python) gensim 패키지에서 doc2vec을 사용
- 사용자 히스토리(user history)를 기반으로 추천
- 구글에서 찾을 수 있는 네이버 뉴스 기사 활용
즉, Python doc2vec을 이용해서 단순한 네이버 뉴스 추천 시스템(news recommender system)을 구현합니다.
참고 자료
포스팅 본문
포스팅 시작에 앞서, 제가 구현하려는 "정말 단순한 아이디어" 기반의 추천 시스템 아이디어를 먼저 소개하겠습니다.
말 그대로 단순한 아이디어입니다. 그렇기 때문에 정확하지 않을 수도 있고 필요에 따라서 고도화를 할 수 있습니다.
고도화 하는 방법은 포스팅 마지막에 간단하게 작성해놓겠습니다.
아이디어
제가 만드려는 네이버 뉴스 추천 시스템의 기본적인 아이디어는 아래 사진과 같습니다.
먼저, 가변 길이의 콘텐츠를 고정 길이의 벡터(vector)로 만들어줍니다. 저는 128차원의 벡터로 만들 것입니다.

그리고 사용자 히스토리(user history)를 만들어야 합니다. 사용자는 네이버 뉴스 기사를 여러 개 봤다고 가정합니다.
그러면, 가변 길이의 콘텐츠를 활용해 만든 고정 길이의 벡터를 기반으로 이를 평균화합니다.
최종적으로 평균화 된 벡터 값을 활용해 각 content끼리의 코사인 유사도(cosine similarity)를 구하고 가장 유사한 뉴스 기사를 추천해줍니다.
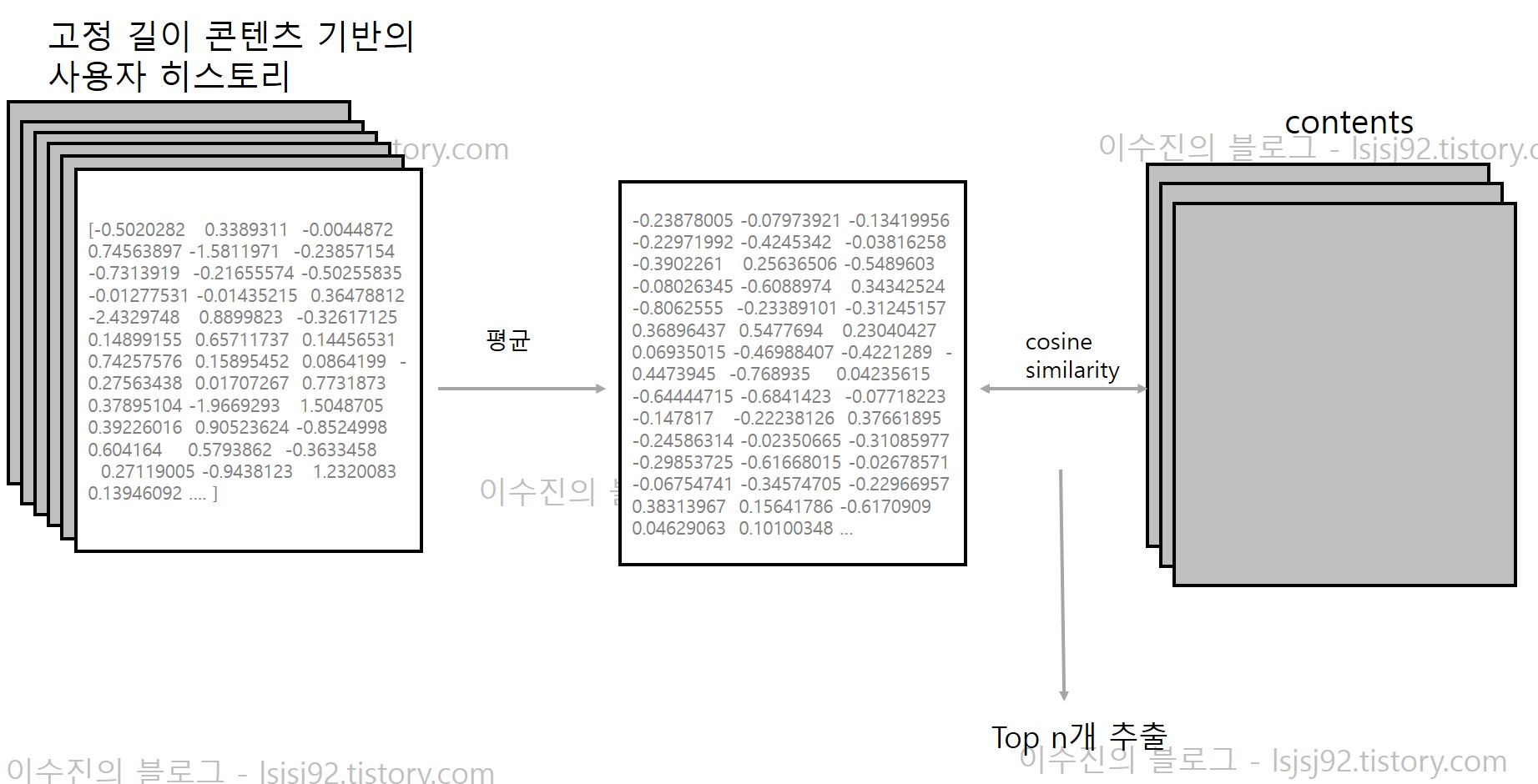
매우 단순하게 접근하는 방법입니다.
자! 그럼 바로 파이썬 코드로 넘어가겠습니다.
파이썬 코드
먼저, 6개의 함수를 만들 것입니다. 각 함수의 기능은 아래와 같습니다.
- make_doc2vec_models - Python doc2vec model 학습 및 저장
- get_preprocessing_data - 데이터 전처리
- make_doc2vec_data - doc2vec에서 사용할 수 있는 데이터 생성
- get_recommended_contents - 추천 결과 반환
- make_user_embedding - user embedding 생성
- view_user_history - 사용자 히스토리 출력
먼저, doc2vec model을 학습하고 저장하는 함수입니다.

앞서 아이디어 그림에서 소개해드린대로 저는 가변 길이의 뉴스 콘텐츠를 고정 길이의 뉴스 콘텐츠로 만들었습니다.
이를 Python의 doc2vec을 활용해 만들었습니다. 가변 길이의 네이버 뉴스를 128차원의 고정 길이의 벡터로 만듭니다.
그리고 그 모델을 저장합니다. tok 이라는 매개변수는 형태소 분석기를 적용한 모델이냐, 아니냐의 bool 값입니다.
다음은 get_preprocessing_data입니다. 데이터 전처리를 담당합니다.

제가 구글링에서 구한 네이버 뉴스 기사에는 경제, 정치, IT과학 주제의 뉴스 데이터가 총 1만개 정도 있습니다.
그 category 값을 mapping 해주며, 제목과 본문을 합쳐서 하나의 feature로 사용합니다.
또한, 불필요한 컬럼을 제거합니다.
다음은 make_doc2ved_data 함수입니다. doc2vec에 필요한 데이터를 만들어줍니다.

위는 Python doc2vec에 필요한 데이터 형식으로 바꿔주는 역할을 합니다.
t_document가 True이면 TaggedDocument로 바꿔주게 되고 이 데이터는 doc2vec model 학습에 사용됩니다.
Doc2vec 사용이 궁금하시다면 맨 처음 소개의 참고 자료 링크인 lovit님의 자료를 보시면 좋습니다.
다음 함수는 get_recommend_contents입니다. cosine similarity를 구해 top n개 (여기선 5개)를 추천해줍니다.

argsort로 cosine similarity가 높은 인덱스를 추출해서 가져옵니다.
다음은 make_user_embedding입니다. content vector 기반의 user history를 평균해서 user embedding을 만들어주는 함수입니다.
또 view_user_history 함수는 사용자의 히스토리 내역을 보여주는 함수입니다.

자! 이제 필요한 함수 설명은 끝났습니다. 본격적으로 진행해봅니다.
먼저, 데이터를 가지고 옵니다.
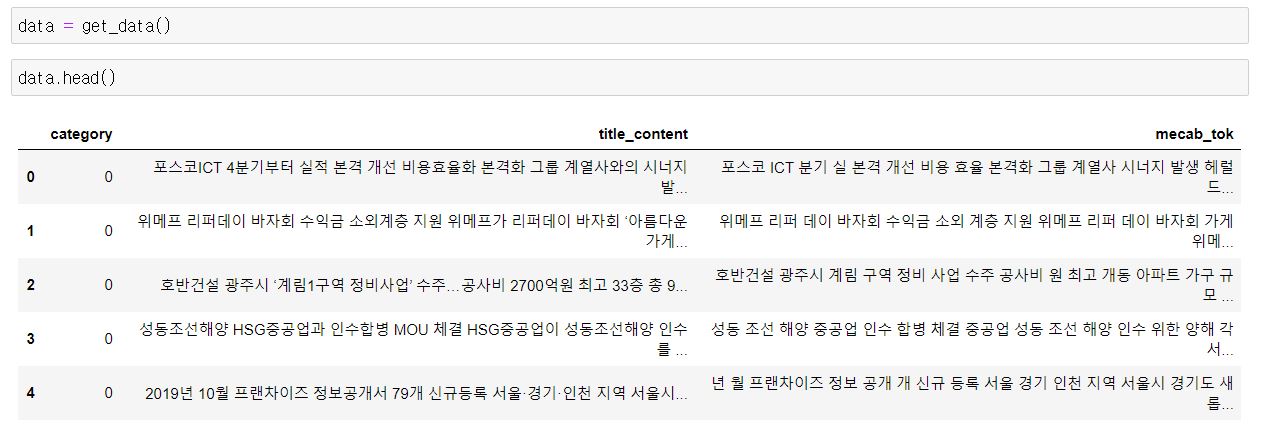
데이터를 보면 category가 있는데요. category는 0번은 경제, 1번은 정치, 2번은 IT과학입니다.
그리고 title_content는 뉴스 기사의 제목과 본문을 합친 결과이며 mecab_tok은 mecab을 이용해 형태소 분석한 결과입니다.
이제 이 데이터를 활용해서 doc2vec model을 만듭니다. 그러면 doc2vec에 활용될 수 있도록 데이터를 전처리 해주어야겠죠? 아까 만들었던 make_doc2vec_data 함수를 활용해서 만들어줍니다.

tag가 붙은 데이터는doc2vec model 학습에 사용되며, 없는 데이터는 user embedding, cosine similarity를 구할 때 사용됩니다.
이제 doc2vec model을 학습합니다. 만들어두었던 함수 make_doc2vec_models를 사용합니다.

형태소 분석기 결과 데이터는 tok=True로 보냅니다. 그러면 각각 데이터에 맞게 doc2vec 모델이 저장됩니다.
이 모델 중 그냥 title + content를 합친 데이터의 doc2vec 모델을 활용하겠습니다.
다음으로 사용자 히스토리를 만들어줍니다. 여기서는 각 카테고리 별로 user history를 만들어주겠습니다.

그리고 view_user_history 함수를 사용해 각각 사용자가 어느 뉴스 기사를 보았는지 출력해줍니다.
카테고리 별 데이터는 random을 사용해서 랜덤하게 뽑았습니다.
자! 이제 저렇게 나온 사용자 히스토리(user viewed history)를 가지고 user embedding을 합니다.

만들어두었던 make_user_embedding 함수에 각 사용자가 본 뉴스 기사의 index list를 전달해줍니다.
그리고 doc2vec에서 사용되는 tag 데이터가 아닌 ([tag], doc) 데이터를 사용하고 model은 형태소 분석 모델이 아니라 제목 + 본문을 합친 모델을 보내줍니다.
그러면 user1, 2, 3 별로 embedding을 평균화해 (128, )의 결과가 나오게 됩니다.
자! 이제 최종적으로 추천을 받으면 됩니다!
get_recommended_contents 함수를 활용합니다. user embedding한 결과와 model, doc2vec data를 전달합니다.
각 추천 결과를 살펴보죠
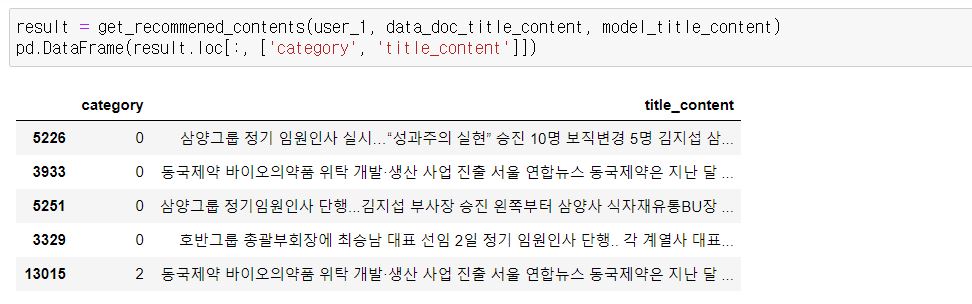
user 1은 경제 뉴스를 많이 본 사용자입니다. 추천 결과도 경제 뉴스와 관련되서 추천이 되었네요!
다음 user를 볼까요? user2는 정치 뉴스를 많이 본 사용자입니다.

실제 추천 결과는 정치 뉴스와 관련해서 추천이 되었습니다. 여기는 100% 정치로 추천이 되었네요!
마지막으로 user 3입니다. user 3은 네이버 뉴스 기사 중 IT과학을 많이 본 사용자입니다.

user 3의 추천 결과를 보니 category 2 즉, IT과학의 뉴스를 추천 받은 것을 볼 수 있습니다.
결론
서두에 말씀드렸다 싶이 이 추천 시스템은 매우 단순한 아이디어입니다. 그래서 추천 결과가 정확하지 않을 수도 있고 방법이 많이 부족한 것이 사실입니다.
왜 방법이 많이 부족한가? 그 이유는 아래와 같습니다. 아래 이유를 해결하면 이 추천 시스템을 고도화 할 수 있습니다.
(저도 해보고 싶지만 관련 데이터가 없네요 ㅠㅠ)
- 사용자가 봤다, 안봤다의 label 데이터가 없다.
- labeling 데이터가 있으면 머신러닝 모델을 활용할 수 있습니다.
- 보통, 뉴스 기사의 경우 가중치를 부여한다.
- 사용자는 뉴스를 보면서 '과거'의 뉴스를 보고 싶어 하지 않습니다.
- 즉, 뉴스는 시간이 중요합니다. 최근에 나온 뉴스를 보고 싶어합니다.
- 이것은 가중치를 부여할 수 있게 됩니다.
- Category * a + Content * b + Time * c 와 같이 가중치를 부여할 수 있게 되고 뉴스는 보통 Time에 해당되는 c에 비교적 많이 부여하는 것으로 알고 있습니다.
- 사용자 데이터가 부족하다
- 지금 사용자 데이터는 단순히 user history를 사용했습니다.
- 성별, 사는 지역 등등의 정보가 없습니다.
- 머신러닝, 딥러닝 모델을 사용하면 더욱 고도화가 가능하다.
위와 같은 이슈를 해결하면 더욱 고도화 된 뉴스 추천 시스템(news recommender system)을 만들 수 있을 것입니다.



